") 使用自監(jiān)督學(xué)習(xí)重建動(dòng)態(tài)駕駛場景
使用自監(jiān)督學(xué)習(xí)重建動(dòng)態(tài)駕駛場景

無論是單調(diào)的高速行車,還是平日的短途出行,駕駛過程往往平淡無奇。因此,在現(xiàn)實(shí)世界中采集的用于開發(fā)自動(dòng)駕駛汽車(AV)的大部分訓(xùn)練數(shù)據(jù)都明顯偏向于簡單場景。
這給部署魯棒的感知模型帶來了挑戰(zhàn)。自動(dòng)駕駛汽車必須接受全面的訓(xùn)練、測試和驗(yàn)證,以便能夠應(yīng)對復(fù)雜的場景,而這需要大量涵蓋此類場景的數(shù)據(jù)。
在現(xiàn)實(shí)世界中,收集此類場景數(shù)據(jù)要耗費(fèi)大量時(shí)間和成本。而現(xiàn)在,仿真提供了另一個(gè)可選方案。但要大規(guī)模生成復(fù)雜動(dòng)態(tài)場景仍然困難重重。
在近期發(fā)布的一篇論文中,NVIDIA Research 展示了一種基于神經(jīng)輻射場(NeRF)的新方法——EmerNeRF 及其如何使用自監(jiān)督學(xué)習(xí)準(zhǔn)確生成動(dòng)態(tài)場景。通過自監(jiān)督方法訓(xùn)練,EmerNeRF 在動(dòng)靜態(tài)場景重建上的表現(xiàn)超越了之前其他 NeRF 方法。詳細(xì)情況請參見 EmerNeRF: Emergent Spatial-Temporal Scene Decomposition via Self-Supervision。



圖 1. EmerNeRF 重建動(dòng)態(tài)駕駛場景的示例
相比其他 NeRF 重建方法,EmerNeRF 的動(dòng)態(tài)場景重建準(zhǔn)確率高出 15%,靜態(tài)場景高出 11%。新視角合成的準(zhǔn)確率也高出 12%。
打破 NeRF 方法的局限性
NeRF 將一組靜態(tài)圖像重建成逼真的 3D 場景。這使得依據(jù)駕駛?cè)罩局亟ㄓ糜?DNN 訓(xùn)練、測試驗(yàn)證的高保真仿真環(huán)境成為可能。
然而,目前基于 NeRF 的重建方法在處理動(dòng)態(tài)物體時(shí)十分困難,而且實(shí)踐證明難以擴(kuò)展。例如有些方法可以生成靜態(tài)和動(dòng)態(tài)場景,但它們依賴真值(GT)標(biāo)簽。這就意味著必須使用自動(dòng)標(biāo)注或人工標(biāo)注員先來準(zhǔn)確標(biāo)注出駕駛?cè)罩局械拿總€(gè)物體。
其他 NeRF 方法則依賴于額外的模型來獲得完整的場景信息,例如光流。
為了打破這些局限性,EmerNeRF 使用自監(jiān)督學(xué)習(xí)將場景分解為靜態(tài)、動(dòng)態(tài)和流場(flow fields)。該模型從原始數(shù)據(jù)中學(xué)習(xí)前景、背景之間的關(guān)聯(lián)和結(jié)構(gòu),而不依賴人工標(biāo)注的 GT 標(biāo)簽。然后,對場景做時(shí)空渲染,并不依賴外部模型來彌補(bǔ)時(shí)空中的不完整區(qū)域,而且準(zhǔn)確性更高。

圖 2. EmerNeRF 將圖 1 第一段視頻中的場景分解為動(dòng)態(tài)場、靜態(tài)場和流場
因此,其他模型往往會(huì)產(chǎn)生過于平滑的背景和精度較低的動(dòng)態(tài)物體(前景),而 EmerNeRF 則能重建高保真的背景及動(dòng)態(tài)物體(前景),同時(shí)保留場景的細(xì)節(jié)。
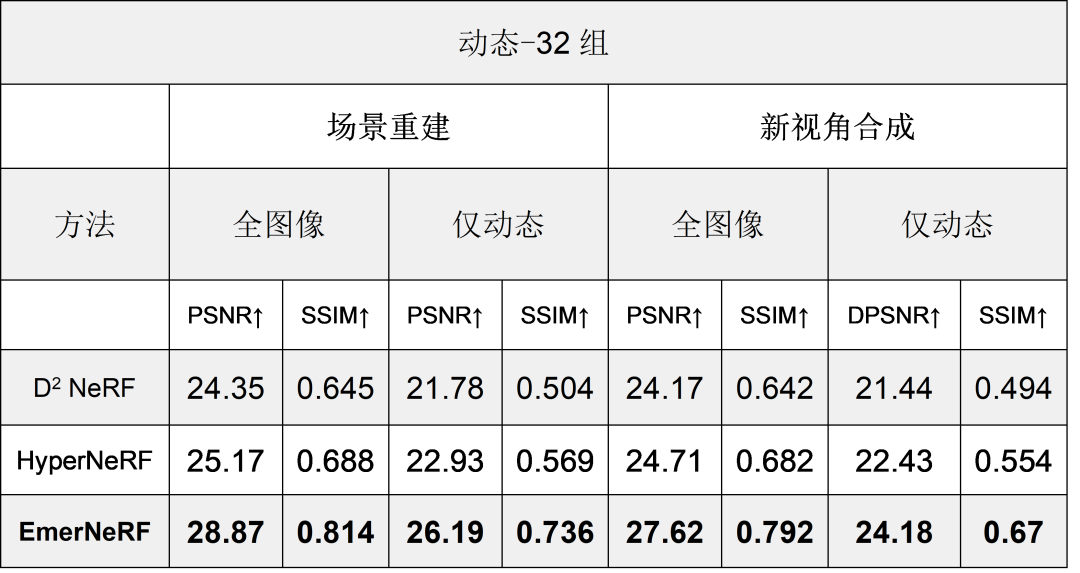
表 1. 將 EmerNeRF 與其他基于 NeRF 的動(dòng)態(tài)場景重建方法進(jìn)行比較后的評(píng)估結(jié)果,分為場景重建性能和新視角合成性能兩個(gè)類別
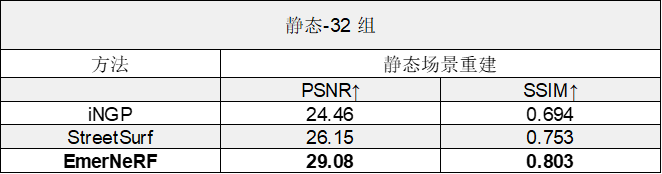
表 2. 將 EmerNeRF 與其他基于 NeRF 的靜態(tài)場景重建方法進(jìn)行比較后的評(píng)估結(jié)果
EmerNeRF 方法
EmerNeRF 使用的是自監(jiān)督學(xué)習(xí),而非人工注釋或外部模型,這使得它能夠避開之前方法所遇到的難題。
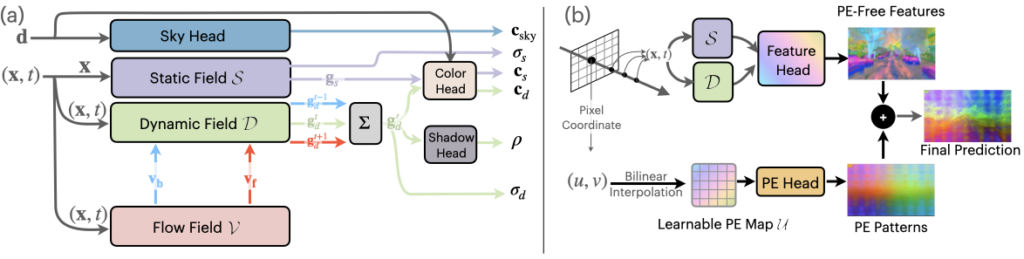
圖 3.EmerNeRF 分解和重建管線
EmerNeRF 將場景分解成動(dòng)態(tài)和靜態(tài)元素。在場景分解的同時(shí),EmerNeRF 還能估算出動(dòng)態(tài)物體(如汽車和行人)的流場,并通過聚合流場在不同時(shí)間的特征以進(jìn)一步提高重建質(zhì)量。其他方法會(huì)使用外部模型提供此類光流數(shù)據(jù),但通常會(huì)引入偏差。
通過將靜態(tài)場、動(dòng)態(tài)場和流場結(jié)合在一起,EmerNeRF 能夠充分表達(dá)高密度動(dòng)態(tài)場景,這不僅提高了重建精度,也方便擴(kuò)展到其他數(shù)據(jù)源。
使用基礎(chǔ)模型加強(qiáng)語義理解
EmerNeRF 對場景的語義理解,可通過(視覺)基礎(chǔ)大模型監(jiān)督進(jìn)一步增強(qiáng)。基礎(chǔ)大模型具有更通用的知識(shí)(例如特定類型的車輛或動(dòng)物)。EmerNeRF 使用視覺 Transformer(ViT)模型,例如 DINO, DINOv2,將語義特征整合到場景重建中。
這使 EmerNeRF 能夠更好地預(yù)測場景中的物體,并執(zhí)行自動(dòng)標(biāo)注等下游任務(wù)。

圖 4. EmerNeRF 使用 DINO 和 DINOv2 等基礎(chǔ)模型加強(qiáng)對場景的語義理解
不過,基于 Transformer 的基礎(chǔ)模型也帶來了新的挑戰(zhàn):語義特征可能會(huì)表現(xiàn)出與位置相關(guān)的噪聲,從而大大限制下游任務(wù)的性能。

圖 5. EmerNeRF 使用位置嵌入消除基于 Transformer 的基礎(chǔ)模型所產(chǎn)生的噪聲
為了解決噪聲問題,EmerNeRF 通過位置編碼分解來恢復(fù)無噪聲的特征圖。如圖 5 所示,這樣就解鎖了基礎(chǔ)大模型在語義特征上全面、準(zhǔn)確的表征能力。
評(píng)估 EmerNeRF
正如 EmerNeRF: Emergent Spatial-Temporal Scene Decomposition via Self-Supervision 中所述,研究人員整理出了一個(gè)包含 120 個(gè)獨(dú)特場景的數(shù)據(jù)集來評(píng)估 EmerNeRF 的性能,這些場景分為 32 個(gè)靜態(tài)場景、32 個(gè)動(dòng)態(tài)場景和 56 個(gè)多樣化場景,覆蓋了高速、低光照等具有挑戰(zhàn)性的場景。
然后根據(jù)數(shù)據(jù)集的不同子集,評(píng)估每個(gè) NeRF 模型重建場景和合成新視角的能力。
如表 1 所示,據(jù)此,EmerNeRF 在場景重建和新視角合成方面的表現(xiàn)始終明顯優(yōu)于其他方法。
EmerNeRF 的表現(xiàn)還優(yōu)于專門用于靜態(tài)場景的方法,這表明將場景分解為靜態(tài)和動(dòng)態(tài)元素的自監(jiān)督分解既能夠改善靜態(tài)重建,還能夠改善動(dòng)態(tài)重建。
總結(jié)
自動(dòng)駕駛仿真只有在能夠準(zhǔn)確重建現(xiàn)實(shí)世界的情況下才會(huì)有效。隨著場景的日益動(dòng)態(tài)化和復(fù)雜化,對保真度的要求也越來越高,而且更難實(shí)現(xiàn)。
與以前的方法相比,EmerNeRF 能夠更準(zhǔn)確地表現(xiàn)和重建動(dòng)態(tài)場景,而且無需人工監(jiān)督或外部模型。這樣就能大規(guī)模地重建和編輯復(fù)雜的駕駛數(shù)據(jù),解決目前自動(dòng)駕駛汽車訓(xùn)練數(shù)據(jù)集的不平衡問題。
NVIDIA 正迫切希望研究 EmerNeRF 帶來的新功能,如端到端駕駛、自動(dòng)標(biāo)注和仿真等。
如要了解更多信息,請?jiān)L問 EmerNeRF 項(xiàng)目頁面并閱讀 EmerNeRF: Emergent Spatial-Temporal Scene Decomposition via Self-Supervision。
了解更多
-
適用于自動(dòng)駕駛汽車的解決方案
https://www.nvidia.cn/self-driving-cars/
-
EmerNeRF 項(xiàng)目頁面
https://emernerf.github.io/
-
閱讀 EmerNeRF: Emergent Spatial-Temporal Scene Decomposition via Self-Supervision.
https://arxiv.org/abs/2311.02077
GTC 2024 將于 2024 年 3 月 18 至 21 日在美國加州圣何塞會(huì)議中心舉行,線上大會(huì)也將同期開放。點(diǎn)擊“閱讀原文”或掃描下方海報(bào)二維碼,立即注冊 GTC 大會(huì)。
原文標(biāo)題:使用自監(jiān)督學(xué)習(xí)重建動(dòng)態(tài)駕駛場景
文章出處:【微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3922瀏覽量
93118
原文標(biāo)題:使用自監(jiān)督學(xué)習(xí)重建動(dòng)態(tài)駕駛場景
文章出處:【微信號(hào):NVIDIA-Enterprise,微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評(píng)論請先 登錄
使用MATLAB進(jìn)行無監(jiān)督學(xué)習(xí)

康謀分享 | 3DGS:革新自動(dòng)駕駛仿真場景重建的關(guān)鍵技術(shù)

汽車?yán)走_(dá)回波發(fā)生器的技術(shù)原理和應(yīng)用場景
時(shí)空引導(dǎo)下的時(shí)間序列自監(jiān)督學(xué)習(xí)框架

HarmonyOS NEXT應(yīng)用元服務(wù)開發(fā)內(nèi)容動(dòng)態(tài)變化場景
基于場景的自動(dòng)駕駛驗(yàn)證策略
自連數(shù)字化健康管理方案應(yīng)用全場景
神經(jīng)重建在自動(dòng)駕駛模擬中的應(yīng)用

【《大語言模型應(yīng)用指南》閱讀體驗(yàn)】+ 基礎(chǔ)知識(shí)學(xué)習(xí)
基于大模型的仿真系統(tǒng)研究一——三維重建大模型





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論