 基于RGM的魯棒且通用的特征匹配
基于RGM的魯棒且通用的特征匹配
作者:泡椒味的口香糖
0. 筆者個人體會
特征匹配包括稀疏匹配和稠密匹配,這方面的深度模型這兩年很多了,效果也都很好。但是同時實現稀疏匹配和稠密匹配的通用模型還比較少,主要是因為聯合訓練會引入大量噪聲,模型架構不好設計。而且相關的訓練數據不好找,直接把幾個數據集堆一起訓練又會出現各種各樣的域問題。
最近,浙大就開源了一項工作,以一個通用模型同時實現稀疏匹配和稠密匹配。筆者認為,這篇文章的意義不是提出了一個最新的匹配模型,而在于通用模型的設計+訓練思路。學習了這種思路,就可以將這種框架泛化到其他任務上。
1. 效果展示
浙大最新發布的RGM實現了一個通用模型,具體效果是同時實現稠密匹配和稀疏匹配。這里面的稠密匹配也就是光流匹配,還可以根據匹配關系投影RGB圖像做兩視角重建。
與其他SOTA方法相比,RGM估計的光流更細膩,邊緣更完整。
目前這篇文章已經開放了github,但是暫時代碼還沒有開源,感興趣的小伙伴可以跟蹤一下。下面來看一下具體的論文信息。
2. 摘要
在一對圖像中尋找匹配的像素是具有各種應用的基本計算機視覺任務。由于光流估計和局部特征匹配等不同任務的特定要求,以前的工作主要分為稠密匹配和稀疏特征匹配,側重于特定的體系結構和特定任務的數據集,這可能在一定程度上阻礙了特定模型的泛化性能。在本文中,我們提出了一個稀疏和稠密匹配的深度模型,稱為RGM (魯棒通用匹配)。特別地,我們精心設計了一個級聯的GRU模塊,通過在多個尺度上迭代地探索幾何相似性來進行細化,然后使用一個附加的不確定性估計模塊來進行稀疏化。為了縮小合成訓練樣本和真實世界場景之間的差距,我們通過以更大的間隔生成光流監督,來構建具有稀疏匹配真值的新的大規模數據集。因此,我們能夠混合各種稠密和稀疏匹配數據集,顯著提高訓練多樣性。通過在大規模混合數據上以兩階段的方式學習匹配和不確定性估計,我們提出的RGM的泛化能力得到了極大的提高。跨多個數據集的zero-shot匹配和下游幾何估計實現了卓越的性能,大大超過了以前的方法。
3. 算法解析
RGM這篇文章的目的是要設計一個統一的框架來同時實現稠密匹配和稀疏匹配,但本身兩個任務的特性不同,直接設計多任務網絡效果不好。所以作者的思想就很巧妙,先設計一個光流稠密匹配網絡,再緊跟一個稀疏化網絡。
整個Pipeline很直觀,可以分成特征提取、稠密匹配、稀疏化三個部分。首先將輸入圖像利用CNN和Transformer提取特征金字塔,然后使用級聯GRU的網絡進行稠密匹配,之后通過不確定性估計來過濾得到稀疏匹配,匹配結果就可以直接用于位姿估計、兩視角重建等下游任務。
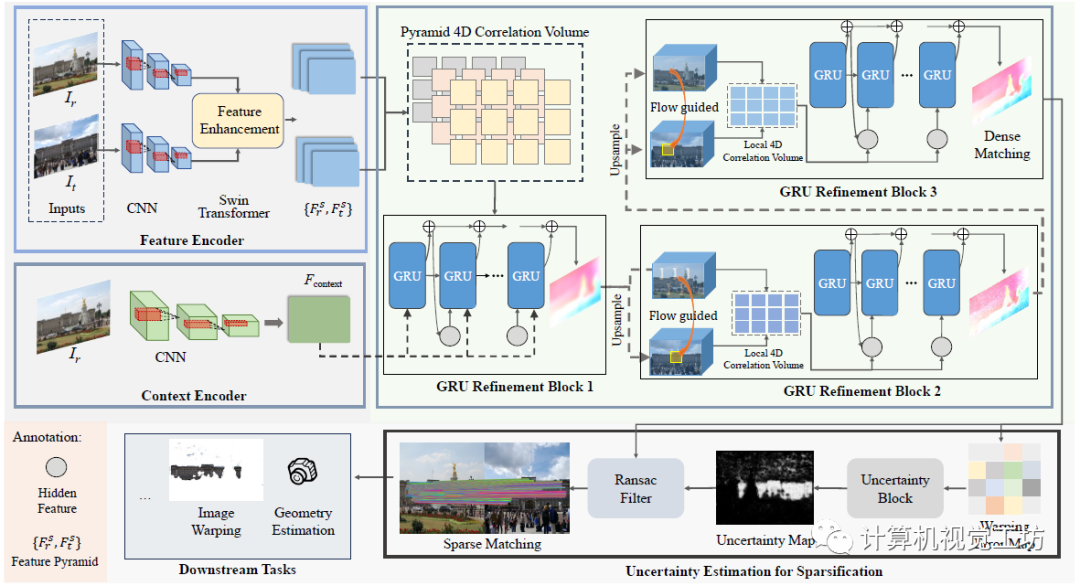
這里面還有幾個細節需要注意:
1、為什么要提取特征金字塔,而不是使用某個特征層?
雖然感受野更大,但在1/8分辨率下會損失很多細節。作者這里使用的是{1/8,1/4,1/2}分辨率的三層金字塔,其中前兩層使用Swin-Transformer的自我注意和交叉注意進行特征增強。
2、這個GRU模塊是啥?
這里也是一個trick,就是不在每個尺度上都建立圖像對的關聯,而在金字塔的兩個底層建立局部關聯。對于1/8的低分辨率層執行點積運算:
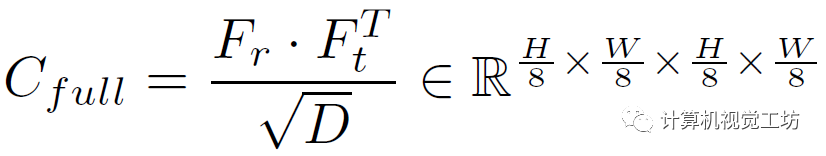
其中Fr和Ft是特征金字塔,D是維度。然后再用平均池化作為RAFT來構建相關金字塔,給定當前的光流估計f和半徑r,就可以構建兩個高分辨率的特征融合計算:
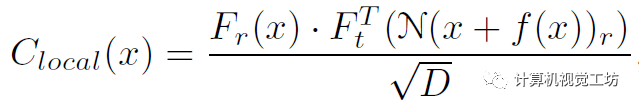
給定相關性和上下文信息,就可以估計運動信息并將其饋送給GRU優化光流殘差,然后迭代得優化光流:
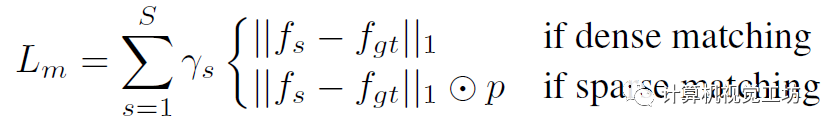
3、稀疏化如何實現?
在獲得稠密匹配之后,可以直接凍結匹配網絡并開始稀疏化。根據估計出的光流可以warp特征圖和RGB圖計算差異。然后將差值送給CNN計算損失,具體是根據mask真值計算的二進制交叉熵:
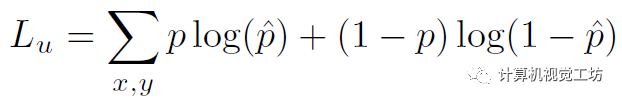
4、為什么要解耦訓練?
具體訓練過程是先訓練匹配網絡,然后凍結這部分,再單獨訓練稀疏化網絡。作者認為直接聯合訓練的話,會引入大量噪聲,導致光流預測不準確。
4. 實驗
RGM的訓練分匹配學習+不確定學習兩階段進行,也就是所謂的解耦訓練。
在匹配學習階段,首先使用帶稀疏匹配真值的MegaDepth(1.4 M對圖像)來訓練(200k次迭代),然后使用ScanNet+FlyingThings3D+TartanAir+MegaDepth的混合數據集(4 M對圖像)進行增強學習(240k次迭代)。Batch size為16,學習率從2e-4余弦退火至1e-5。在不確定學習階段,直接凍結稠密匹配網絡的參數。在MegaDepth和ScanNet上訓練了2個epoch,batch size為4,學習率固定1e-4。注意,為了平衡不同數據集之間的差異,還對TartanAir進行了大間距采樣。
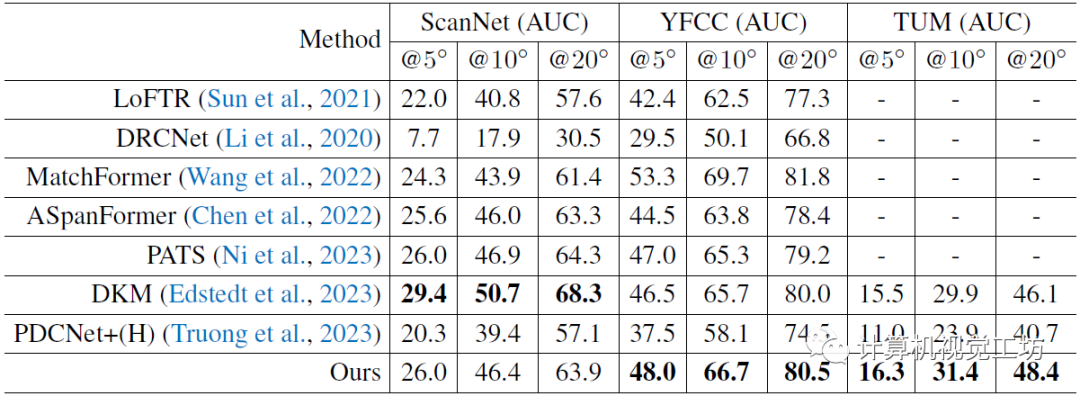
評估也是一個零樣本泛化實驗。匹配估計使用ETH3D+HPatches+KITTI+TUM數據集,位姿估計(下游任務)使用TUM+YFCC數據集,光流估計使用Sintel數據集。
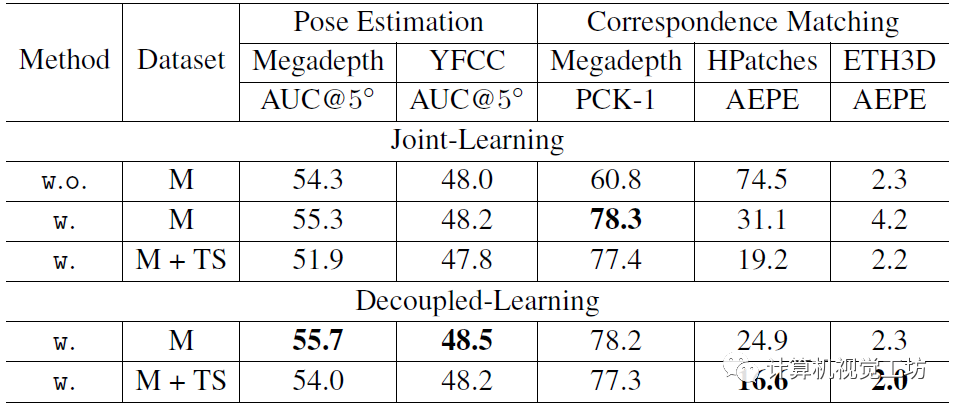
首先是解耦訓練和聯合訓練的對比,證明他們做提出的解耦訓練是有效的。看到這里筆者也有個疑問,有的模型是聯合訓練效果更好,有的模型卻是解耦訓練更好,希望有小伙伴能傳授一下經驗。
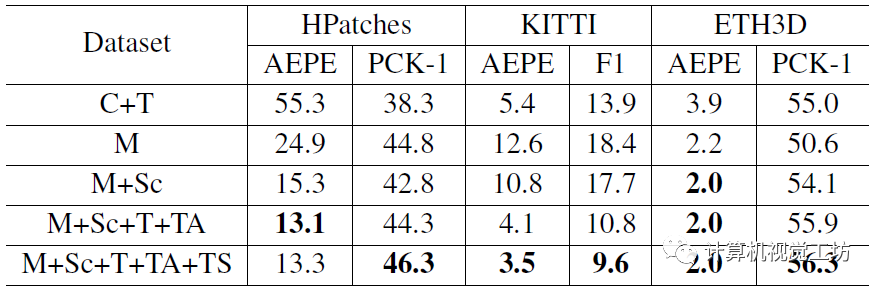
訓練使用數據集的對比,顯然使用的數據集越多效果越好。
特征匹配最直觀的定性對比,相同顏色代表預測的匹配關系。相較于之前的SOTA方法可以取得更多的匹配關系,而且語義預測也更好(大部分匹配關系都集中在摩托車和人上)。
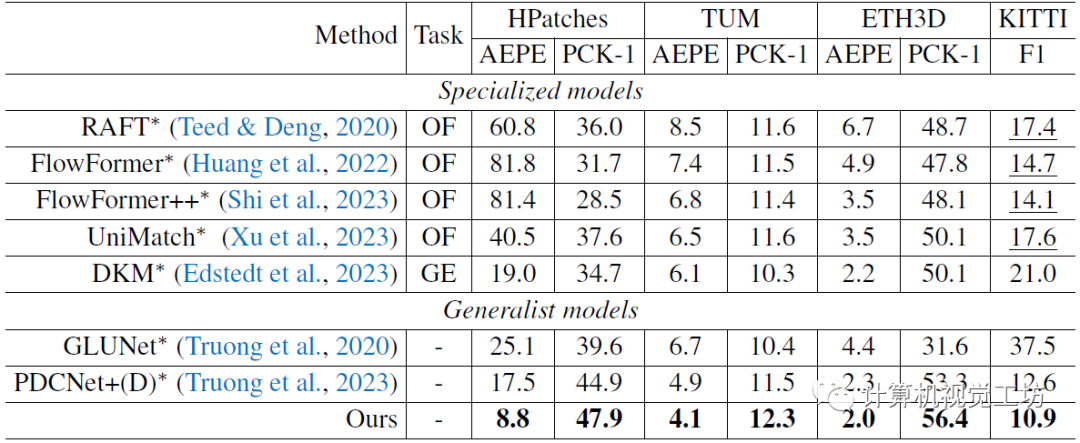
光流估計的對比,也是一個zero-shot實驗。對比方案包括光流專用模型、稠密幾何估計方法,還有通用匹配模型,RDM效果最優。這里也推薦「3D視覺工坊」新課程如何學習相機模型與標定?(代碼+實戰)》。
最后是一個在TUM和YFCC上進行位姿估計的zero-shot評估,也是匹配性能的進一步驗證。
5. 總結
一句話總結:RGM以一個通用模型同時實現了稀疏和稠密匹配。具體創新點是級聯GRU細化模塊+用于稀疏化的不確定性估計模塊+解耦訓練機制。除了評估特征匹配的精度,作者還做了很多下游任務的評估,比如位姿估計、兩視角重建。感覺這篇文章還在審稿中,后續應該會上傳新版本的文章和代碼。
審核編輯:黃飛
-
Gru
+關注
關注
0文章
12瀏覽量
7608 -
特征提取
+關注
關注
1文章
29瀏覽量
9931 -
匹配網絡
+關注
關注
0文章
13瀏覽量
9900
原文標題:浙大最新開源RGM | 魯棒且通用的特征匹配!
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
魯棒自適應控制綜述A survey of robust ad

Linux的魯棒性度量詳解及魯棒性關聯測試分析
基于偏最小二乘回歸的魯棒性特征選擇與分類算法

基于導彈視頻特征匹配

如何才能解決圖像匹配算法的光照變化敏感和匹配正確率低的問題
一種魯棒長時自適應目標跟蹤算法






 工商網監
工商網監
評論