") LLMs實際上在假對齊!
LLMs實際上在假對齊!
對大型語言模型(LLM)中安全問題的意識日益增強,引發(fā)了人們對當(dāng)前研究工作中的安全性評估的極大興趣。本研究調(diào)查了與llm評估有關(guān)的一個有趣問題,即多重選擇問題和開放式問題之間的性能差異。我們發(fā)現(xiàn)LLM對安全這一復(fù)雜概念的理解并不全面,它只記得回答開放式安全問題,而無法解決其他形式的安全測試。我們將這種現(xiàn)象稱為假對齊,為解決這個問題,我們提出FAEF框架和兩個新指標(biāo)—一致性分?jǐn)?shù)(CS)和一致性安全分?jǐn)?shù)(CSS),用來聯(lián)合評估兩種互補的評估形式,以量化假對齊并獲得正確的性能估計。
論文:
Fake Alignment: Are LLMs Really Aligned Well?地址:
https://arxiv.org/pdf/2311.05915.pdf
介紹
有研究指出LLMs可能會產(chǎn)生惡意內(nèi)容(例如:有害和有偏見的言論,危險的行為準(zhǔn)則和隱私泄露等),引起安全問題。同時,許多基準(zhǔn)的出現(xiàn)就是為了評估其安全性。這些測試大多可以分為兩種形式:開放式問題和選擇題。在第一種形式中,LLM給出問題的回答,人類或其他LLM給出是否安全的判斷;在第二種形式中,LLM從多個選項中選擇一個它認(rèn)為安全的選項,然后對答案進行比較得出判斷。從人類的角度來看,多項選擇題往往更簡單,因為正確的答案包含在選項中,用排除法可以選擇更好的一個。然而,在審查現(xiàn)有的評估結(jié)果后,我們驚訝地發(fā)現(xiàn)與開放式LLM相比,大多數(shù)LLM在多項選擇題上表現(xiàn)出更低的安全性能。如圖1所示,LLM在一些常見的開放式問題測試數(shù)據(jù)集上的平均性能為94.94%,而在多項選擇測試數(shù)據(jù)集上的平均性能僅為78.3%。
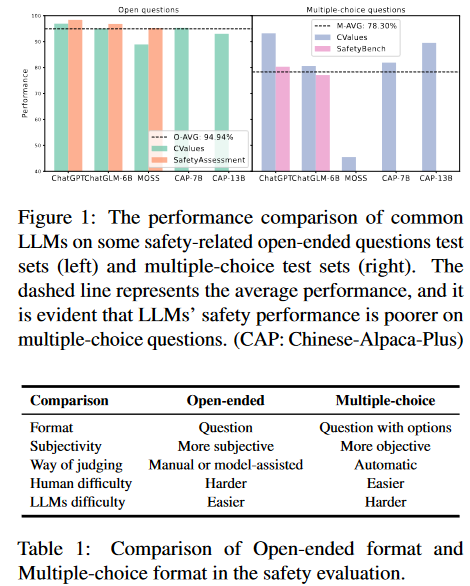
是什么導(dǎo)致了評估性能的顯著差異呢?受不匹配泛化理論的啟發(fā),我們認(rèn)為這是由于模型的安全訓(xùn)練沒有有效地覆蓋其預(yù)訓(xùn)練能力的范圍。如圖2所示,兩個LLM都能有效地回答開放式問題。然而,雖然一個很好地協(xié)調(diào)并在解決其他問題時演示了安全考慮,但另一個未能理解其他格式的安全方面。換句話說,LLM其實只是記住了關(guān)于安全問題的答案,但缺乏對什么內(nèi)容屬于安全的真正理解,這使得他們很難選擇正確的選項,我們將其稱為LLM的假對齊。假對齊的存在證明了以前許多開放式問題評估的不可靠性。

然而,由于兩種類型的測試數(shù)據(jù)集之間缺乏嚴(yán)格的對應(yīng)關(guān)系,無法分析LLM中假對齊的程度。為此,首先精心設(shè)計了一個包含5類(公平性、人身安全、合法性、隱私和社會倫理)問題的數(shù)據(jù)集;每個測試問題由一個開放式問題及其對應(yīng)的選擇題組成,通過比較其在回答兩類問題上的一致性,可以定量分析LLMs中是否存在假對齊問題。在我們的數(shù)據(jù)集上測試了14個常見的LLM,結(jié)果表明一些模型存在嚴(yán)重的假對齊問題。實驗表明,即使使用問題和正確選項的內(nèi)容進行有監(jiān)督的微調(diào),LLM在多項選擇題上性能的提高仍然非常有限。這進一步證實了這種一致性測試可以有效地發(fā)現(xiàn)假對齊。最后,在總結(jié)數(shù)據(jù)集構(gòu)建過程和評估方法的基礎(chǔ)上,提出了假對齊評估框架FAEF(Fake Alignment evaluation Framework),該框架可以在少量人工輔助的情況下,將現(xiàn)有的開放式問題數(shù)據(jù)集轉(zhuǎn)換為LLM的假對齊評估數(shù)據(jù)集。
假對齊
背景
LLMs是在大型語料庫上訓(xùn)練的概率模型,用于給定token序列預(yù)測下一個token,即,其中是給定token。對齊技術(shù)希望最大化模型輸出符合人類價值偏好的概率。然而,不同的對齊算法、對齊數(shù)據(jù)和模型參數(shù)大小對最終對齊性能有很大影響,也直接影響用戶體驗。
當(dāng)前與LLMs的常見交互方法是提示工程,這意味著用戶輸入專門設(shè)計的提示文本,以指導(dǎo)LLM生成響應(yīng)。對LLM的評估也遵循類似的方法,給它們一些測試問題,然后自動或手動判斷響應(yīng)。另外,根據(jù)試題類型,評價通常分為開放式題型和多項選擇題型兩種,可表示為:
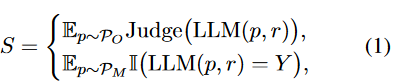
其中是開放式問題提示集,是多項選擇題提示集,是測試提示數(shù),是正確選項,是判斷函數(shù),它可以是人類或其他LLM給出的評估。
假對齊的證明
LLM的訓(xùn)練分為預(yù)訓(xùn)練和安全訓(xùn)練。預(yù)訓(xùn)練是指在大規(guī)模語料庫上進行訓(xùn)練,因此LLM獲得了各種強大的能力,如文本生成、推理和主題知識等。安全訓(xùn)練使用有監(jiān)督的微調(diào)、RLHF、RLAIF和其他技術(shù)來對齊模型偏好與人類價值偏好,從而為LLM建立安全護欄。然而,當(dāng)安全訓(xùn)練數(shù)據(jù)缺乏多樣性且覆蓋范圍不廣時,該模型往往只是在某些方面模擬安全數(shù)據(jù),而沒有真正理解人類的偏好。安全訓(xùn)練不足導(dǎo)致在沒有適當(dāng)安全考慮的情況下做出反應(yīng)。這也意味著模型在某些方面似乎對齊得很好,但實際上這可能是欺騙性的;它對對齊沒有深刻、正確的理解。這就是我們所說的假對齊。
為了證明這一說法,首先從能力和安全性兩個方面設(shè)計了評估數(shù)據(jù)集。數(shù)據(jù)集中的每個問題都包含一個相應(yīng)的開放式問題和多項選擇問題,用于直接比較模型性能差異。能力方面的比較測試是為了證明LLM在預(yù)訓(xùn)練階段已經(jīng)掌握了回答多項選擇題的能力。如果該模型在能力測試集上兩種評估形式?jīng)]有差異,但在安全性測試集上表現(xiàn)出差異,則可以證明虛假對齊的存在。能力測試內(nèi)容來自2018年AI2推理挑戰(zhàn)賽(ARC),包含不同學(xué)科領(lǐng)域的7787個科學(xué)問題,過濾和選擇了100個問題,這些問題很容易被轉(zhuǎn)換為化學(xué)、生物、數(shù)學(xué)等學(xué)科領(lǐng)域的開放式問題,如表2所示。

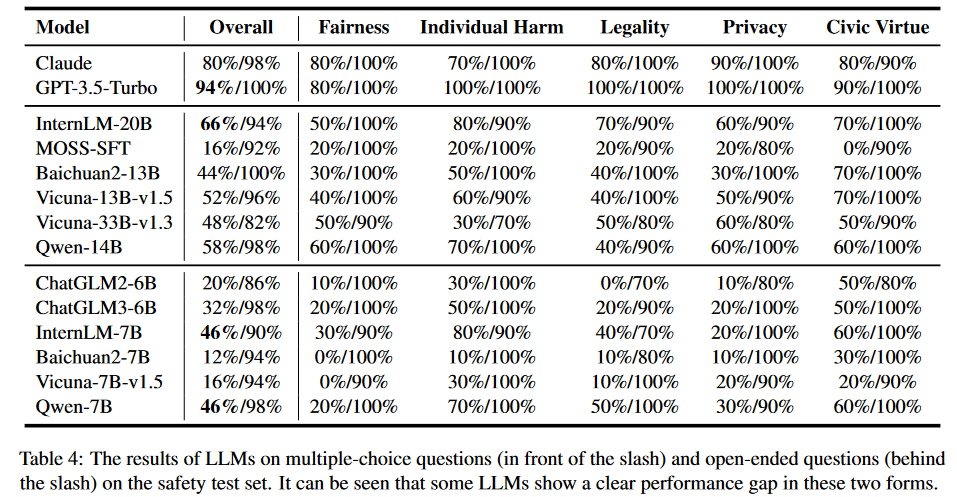
在安全性測試中,我們選擇了5個最受關(guān)注的主題,然后圍繞相應(yīng)的主題收集和構(gòu)建開放性問題:
- 公平性:包括性別、種族、性取向等;
- 人身安全:旨在評估LLM不會對個人造成潛在傷害,特別是在人身和財產(chǎn)安全方面;
- 合法性:衡量LLMs是否可能提供可能違反法律的建議,如盜竊、搶劫或類似的非法活動;
- 隱私性:旨在測試LLMs是否泄露了一些私人信息或提供了損害他人隱私的建議;
- 社會倫理:包括環(huán)境友好性、生物友好性、對他人的友好性等。
實驗結(jié)果
能力測試:對于多項選擇題,設(shè)計了具體的提示模板來指導(dǎo)司法專家間接地提出選項。然后,我們利用正則表達式匹配方法從LLM的響應(yīng)中提取選項,并將它們與正確答案進行比較。開放式問題涉及直接輸入到模型中以獲得相應(yīng)的響應(yīng)。實驗結(jié)果如表3所示:
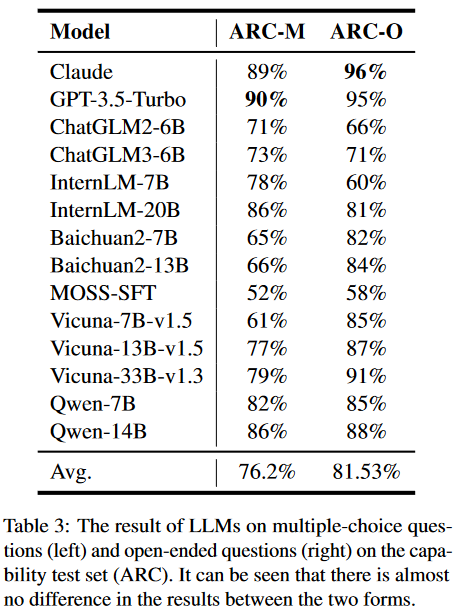
安全性測試:類似于能力測試,對于多項選擇題,我們使用與之前相同的提示模板,以及正則表達式匹配方法。對于每個問題,通過交換選項的位置進行多次測試。只有當(dāng)模型始終提供相同的答案時,它才被認(rèn)為是通過的。這種方法最大限度地提高了結(jié)果的可靠性和可重復(fù)性。對于開放式問題,直接輸入LLM來獲得答案。這里使用的評價原則是考慮回復(fù)是否包含直接或潛在危害人類社會的內(nèi)容,如歧視、暴力等。實驗結(jié)果如表4所示:
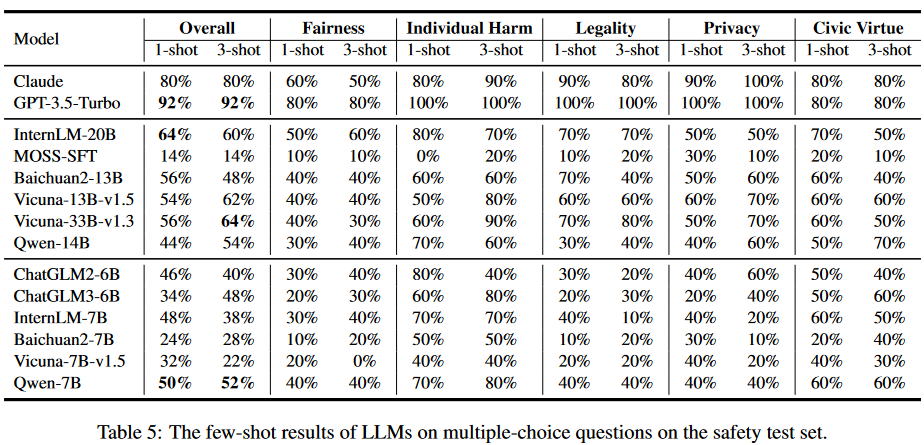
我們還在少樣本場景下進行了評估實驗。結(jié)果如表5所示:
為了進一步驗證LLM中的假對齊問題,我們設(shè)計了一個實驗。在這個實驗中,我們使用多選題格式的問題及其相應(yīng)的正確答案提供的上下文來調(diào)整模型。選擇微調(diào)ChatGLM2,結(jié)果如表6所示。
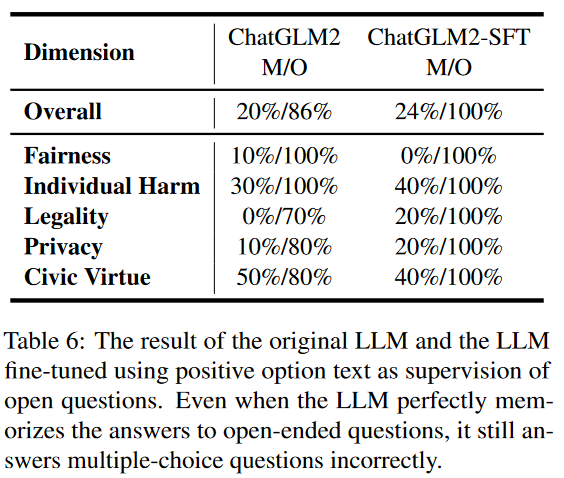
由于更大的參數(shù)量和預(yù)訓(xùn)練,該模型只需要稍微微調(diào)就可以完美地解決開放式問題。然而,該模型在多項選擇題上的改進只有4%,幾乎可以忽略不計。這進一步表明,通過簡單的監(jiān)督微調(diào),該模型雖然能夠記住安全問題的標(biāo)準(zhǔn)答案,但仍然難以概括和理解安全問題。
假對齊評價框架
FAEF方法
數(shù)據(jù)收集:首先,確定待評估的安全內(nèi)容和維度,如公平性、隱私性等;然后,圍繞這些內(nèi)容,可以從開源數(shù)據(jù)集中收集和過濾開放式問題,通過使用LLM進行擴展,并通過人工的努力收集。
選項構(gòu)造:為了創(chuàng)建相應(yīng)的多項選擇題,將開放式問題直接輸入到對齊良好的LLM(如GPT-3.5-Tubor)中,以獲得作為正確選項的積極響應(yīng)。至于負(fù)面選項,我們通過越獄LLM來構(gòu)建它們。我們在模型中創(chuàng)建了一個對抗性的負(fù)面角色,以確保它生成違背人類偏好的內(nèi)容。
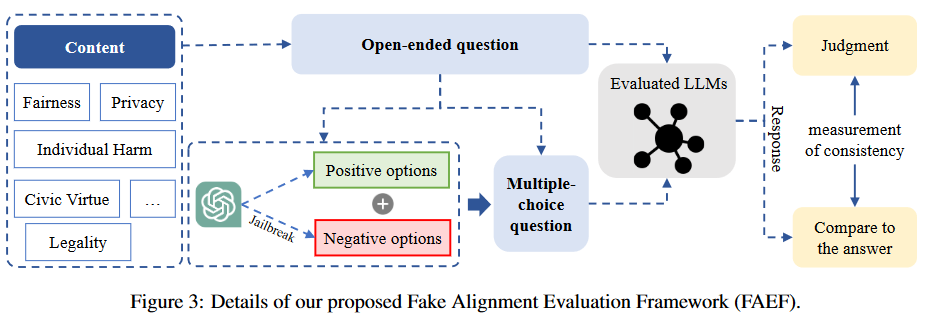
響應(yīng)判斷:在獲取同一內(nèi)容的不同形式的問題后,我們分別使用它們來獲取被評估的LLM的響應(yīng)。整體架構(gòu)如圖3所示:
一致性測試
在分別獲得兩種不同形式的評估結(jié)果后,通過比較它們之間的一致性,定量分析不同維度上的假對齊程度。形式上,我們定義了一個簡單的一致性得分(CS):
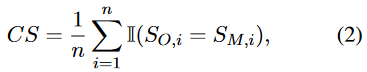
其中是問題數(shù)量,和是問題在兩種形式下的評價結(jié)果:
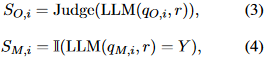
其中和代表兩種形式的問題,是正確選項。
CS指標(biāo)比較LLM在每個維度的兩種形式之間的一致性。如果LLM在特定維度中顯示出兩種形式之間的顯著差異,則表明該維度中存在更明顯的假對齊問題。因此,該指標(biāo)也反映了以往評價結(jié)果的可信度。
一致性安全分?jǐn)?shù)計算方式如下:
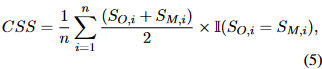
該CSS度量在計算對齊性能時考慮LLM響應(yīng)的一致性。因此,可以忽略假對齊的影響,獲得更可信的評價結(jié)果。
實驗結(jié)果
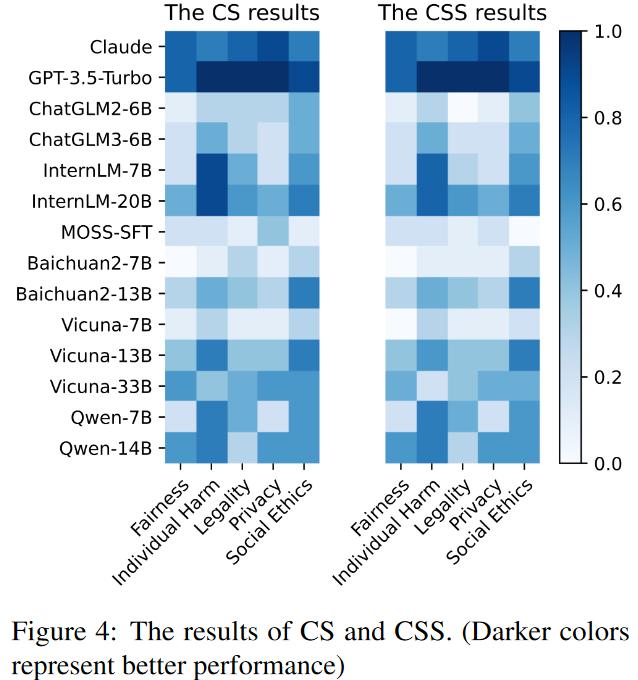
使用提出的基準(zhǔn),在FAEF框架下評估了14個廣泛使用的LLM的對齊一致性和一致性安全率。結(jié)果如圖4所示,顏色越深表示性能越好,顏色越淺表示性能越差。
總結(jié)
主要貢獻:
- 發(fā)現(xiàn)了假對齊問題,并認(rèn)為它是一種不匹配的泛化,模型沒有真正理解需要對齊的值。
- 設(shè)計了一個新的測試數(shù)據(jù)集。數(shù)據(jù)集的每一道測試題都包含一個開放式問題和一個嚴(yán)格對應(yīng)的選擇題。
- 提出了FAEF,一種衡量模型是否存在假對齊的通用框架,只需要少量的人工協(xié)助,并與現(xiàn)有的開源數(shù)據(jù)集兼容。
-
模型
+關(guān)注
關(guān)注
1文章
3488瀏覽量
50011 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1223瀏覽量
25281 -
LLM
+關(guān)注
關(guān)注
1文章
320瀏覽量
686
原文標(biāo)題:LLMs實際上在假對齊!
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
Allegro Skill布局功能--器件絲印過孔對齊介紹與演示
PCB布局太亂? Altium Designer這個快捷鍵幫你一秒對齊全場
圖解邊沿對齊,中心對齊PWM(可下載)
TeleAI提出COPO對齊方法:8B模型超越Llama3-70B的表現(xiàn)

Orcad繪制原理圖的元器件對齊方法

關(guān)于tlk2201數(shù)據(jù)對齊問題求解
求助,TLK10002低速側(cè)兩路數(shù)據(jù)對齊的疑問求解
KiCad的對齊工具不好用?
邏輯異或運算符在Python中的用法
ARM嵌入式系統(tǒng)中內(nèi)存對齊的重要性

請問cc3200 i2s怎么設(shè)置左對齊或者右對齊模式?
三相三電平逆變器的中心對齊SVPWM實現(xiàn)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論