") 多GPU訓(xùn)練大型模型:資源分配與優(yōu)化技巧|英偉達(dá)將推出面向中國(guó)的改良芯片HGX H20、L20 PCIe、L2 PCIe
多GPU訓(xùn)練大型模型:資源分配與優(yōu)化技巧|英偉達(dá)將推出面向中國(guó)的改良芯片HGX H20、L20 PCIe、L2 PCIe

在人工智能領(lǐng)域,大型模型因其強(qiáng)大的預(yù)測(cè)能力和泛化性能而備受矚目。然而,隨著模型規(guī)模的不斷擴(kuò)大,計(jì)算資源和訓(xùn)練時(shí)間成為制約其發(fā)展的重大挑戰(zhàn)。特別是在英偉達(dá)禁令之后,中國(guó)AI計(jì)算行業(yè)面臨前所未有的困境。為了解決這個(gè)問題,英偉達(dá)將針對(duì)中國(guó)市場(chǎng)推出新的AI芯片,以應(yīng)對(duì)美國(guó)出口限制。本文將探討如何在多個(gè)GPU上訓(xùn)練大型模型,并分析英偉達(dá)禁令對(duì)中國(guó)AI計(jì)算行業(yè)的影響。
如何在多個(gè) GPU 上訓(xùn)練大型模型?
神經(jīng)網(wǎng)絡(luò)的訓(xùn)練是一個(gè)反復(fù)迭代的過程。在每次迭代中,數(shù)據(jù)首先向前傳播,通過模型的各層,為每個(gè)訓(xùn)練樣本計(jì)算輸出。然后,梯度向后傳播,計(jì)算每個(gè)參數(shù)對(duì)最終輸出的影響程度。這些參數(shù)的平均梯度和優(yōu)化狀態(tài)被傳遞給優(yōu)化算法,如Adam,用于計(jì)算下一次迭代的參數(shù)和新的優(yōu)化狀態(tài)。隨著訓(xùn)練的進(jìn)行,模型逐漸發(fā)展以產(chǎn)生更準(zhǔn)確的輸出。
然而,隨著大模型的到來,單機(jī)難以完成訓(xùn)練。并行技術(shù)應(yīng)運(yùn)而生,基于數(shù)據(jù)并行性、管道并行性、張量并行性和混合專家等策略,將訓(xùn)練過程劃分為不同的維度。此外,由于機(jī)器和內(nèi)存資源的限制,還出現(xiàn)了混合精度訓(xùn)練、梯度累積、模型卸載CPU、重算、模型壓縮和內(nèi)存優(yōu)化版優(yōu)化器等策略。
為進(jìn)一步加速訓(xùn)練過程,可以從數(shù)據(jù)和模型兩個(gè)角度同時(shí)進(jìn)行并行處理。一種常見的方式是將數(shù)據(jù)切分,并將相同的模型復(fù)制到多個(gè)設(shè)備上,處理不同數(shù)據(jù)分片,這種方法也被稱為數(shù)據(jù)并行。另外一種方法是模型并行即將模型中的算子劃分到多個(gè)設(shè)備上分別完成(包括流水線并行和張量并行)。當(dāng)訓(xùn)練超大規(guī)模語言模型時(shí),需要對(duì)數(shù)據(jù)和模型同時(shí)進(jìn)行切分,以實(shí)現(xiàn)更高級(jí)別的并行,這種方法通常被稱為混合并行。通過這些并行策略,可以顯著提高神經(jīng)網(wǎng)絡(luò)的訓(xùn)練速度和效率。
一、數(shù)據(jù)并行
在數(shù)據(jù)并行系統(tǒng)中,每個(gè)計(jì)算設(shè)備都有完整的神經(jīng)網(wǎng)絡(luò)模型副本,在進(jìn)行迭代時(shí),每個(gè)設(shè)備僅負(fù)責(zé)處理一批數(shù)據(jù)子集并基于該子集進(jìn)行前向計(jì)算。假設(shè)一批次的訓(xùn)練樣本數(shù)為N,使用M個(gè)設(shè)備并行計(jì)算,每個(gè)設(shè)備將處理N/M個(gè)樣本。完成前向計(jì)算后,每個(gè)設(shè)備將根據(jù)本地樣本計(jì)算誤差梯度Gi(i為加速卡編號(hào))并進(jìn)行廣播。所有設(shè)備需要聚合其他加速卡提供的梯度值,然后使用平均梯度(ΣN i=1Gi)/N來更新模型,完成該批次訓(xùn)練。

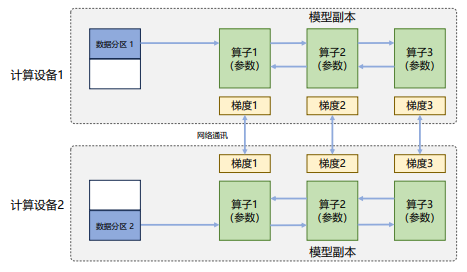
數(shù)據(jù)并行訓(xùn)練系統(tǒng)通過增加計(jì)算設(shè)備,可以顯著提高整體訓(xùn)練吞吐量和每秒全局批次數(shù)。與單計(jì)算設(shè)備訓(xùn)練相比,最主要的區(qū)別在于反向計(jì)算中梯度需要在所有計(jì)算設(shè)備中進(jìn)行同步,以確保每個(gè)計(jì)算設(shè)備上最終得到所有進(jìn)程上梯度平均值。
二、模型并行
模型并行可以從計(jì)算圖的角度出發(fā),采用流水線并行和張量并行兩種方式進(jìn)行切分。
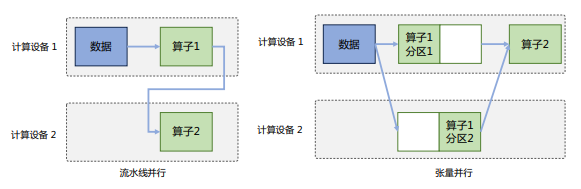
1、流水線并行
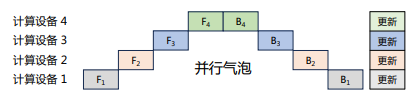
流水線并行(Pipeline Parallelism,PP)是一種計(jì)算策略,將模型的各層劃分為多個(gè)階段,并在不同計(jì)算設(shè)備上進(jìn)行處理,實(shí)現(xiàn)前后階段的連續(xù)工作。PP廣泛應(yīng)用于大規(guī)模模型的并行系統(tǒng),以解決單個(gè)設(shè)備內(nèi)存不足問題。下圖展示了由四個(gè)計(jì)算設(shè)備組成的PP系統(tǒng),包括前向計(jì)算和后向計(jì)算。其中F1、F2、F3、F4代表四個(gè)前向路徑,位于不同設(shè)備上;B4、B3、B2、B1代表逆序后向路徑,位于四個(gè)不同設(shè)備上。然而,下游設(shè)備需要等待上游設(shè)備計(jì)算完成才能開始計(jì)算任務(wù),導(dǎo)致設(shè)備平均使用率降低,形成模型并行氣泡或流水線氣泡。
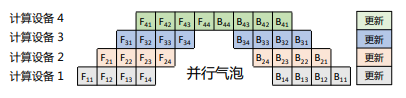
樸素流水線策略會(huì)導(dǎo)致并行氣泡,使系統(tǒng)無法充分利用計(jì)算資源,降低整體計(jì)算效率。為減少并行氣泡,可以將小批次進(jìn)一步劃分為更小的微批次,并利用流水線并行方案處理每個(gè)微批次數(shù)據(jù)。在完成當(dāng)前階段計(jì)算并得到結(jié)果后,將該微批次的結(jié)果發(fā)送給下游設(shè)備,同時(shí)開始處理下一微批次的數(shù)據(jù),在一定程度上減少并行氣泡。如下圖所示,前向F1計(jì)算被拆解為F11、F12、F13、F14,在計(jì)算設(shè)備1中完成F11計(jì)算后,會(huì)在計(jì)算設(shè)備2中開始進(jìn)行F21計(jì)算,同時(shí)計(jì)算設(shè)備1中并行開始F12的計(jì)算。與原始流水線并行方法相比,有效降低并行氣泡。
2、張量并行
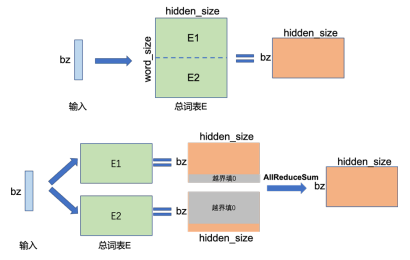
張量并行需要針對(duì)模型結(jié)構(gòu)和算子類型處理參數(shù)如何在不同設(shè)備上進(jìn)行切分,并確保切分后的數(shù)學(xué)一致性。大語言模型以Transformer結(jié)構(gòu)為基礎(chǔ),包含三種算子:嵌入表示、矩陣乘和交叉熵?fù)p失計(jì)算。這三種算子具有較大差異,因此需要設(shè)計(jì)相應(yīng)的張量并行策略,以便將參數(shù)分配到不同設(shè)備上。對(duì)于嵌入表示層參數(shù),可按照詞維度進(jìn)行劃分,每個(gè)計(jì)算設(shè)備只存儲(chǔ)部分詞向量,然后通過匯總各個(gè)設(shè)備上的部分詞向量來獲得完整的詞向量。
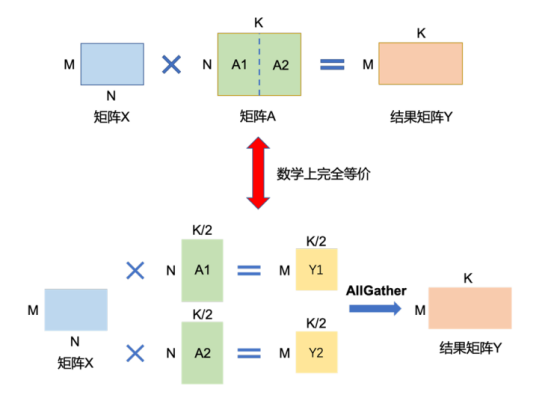
矩陣乘的張量并行可以利用矩陣分塊乘法原理來優(yōu)化計(jì)算。以矩陣乘法Y = X × A為例,其中X是M × N維的輸入矩陣,A是N × K維的參數(shù)矩陣,Y是M × K維的結(jié)果矩陣。當(dāng)參數(shù)矩陣A過大超出單張卡的顯存容量時(shí),可以將A切分到多張卡上,并通過集合通信匯集結(jié)果,確保最終結(jié)果的數(shù)學(xué)計(jì)算等價(jià)于單計(jì)算設(shè)備的計(jì)算結(jié)果。參數(shù)矩陣A有兩種切分方式:
1)按列切分
將矩陣A按列切成A1和A2,分別放置在兩個(gè)計(jì)算設(shè)備上。兩個(gè)計(jì)算設(shè)備分別計(jì)算Y1 = X × A1和Y2 = X × A2。計(jì)算完成后,多計(jì)算設(shè)備間進(jìn)行通信,拼接得到最終結(jié)果矩陣Y,其數(shù)學(xué)計(jì)算與單計(jì)算設(shè)備結(jié)果等價(jià)。
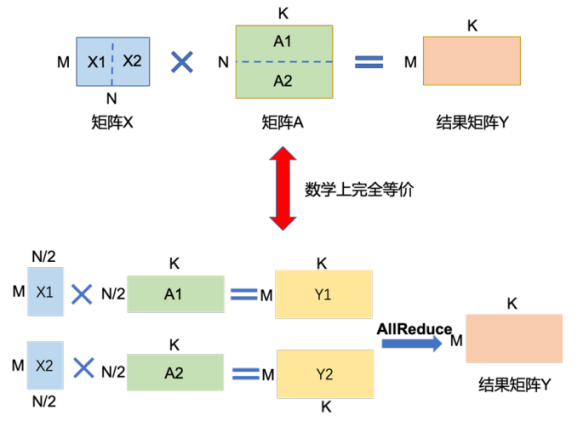
2)按行切分
將矩陣A按行切成B1,B2,...,Bn,每個(gè)Bi為N*(K/n)即(K/n)N維。將這n個(gè)切分后的矩陣分別放到n個(gè)GPU上,則可并行執(zhí)行矩陣乘法Y=XB1,Y=X*(B1+B2),...,Y=X*(B1+B2+...+Bn)。每步并行計(jì)算完成后,各GPU間進(jìn)行通信,拼接得到最終結(jié)果矩陣Y。
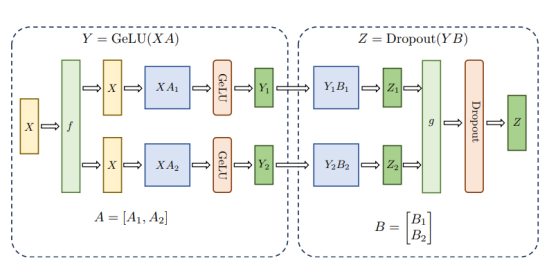
在Transformer中FFN結(jié)構(gòu)包含兩層全連接(FC)層,每層都涉及兩個(gè)矩陣乘法。這兩個(gè)矩陣乘法分別采用上述兩種切分方式。對(duì)于第一個(gè)FC層的參數(shù)矩陣,采用按列切塊方式,而對(duì)于第二個(gè)FC層參數(shù)矩陣,則采用按行切塊方式。這樣的切分方式使得第一個(gè)FC層輸出能夠直接滿足第二個(gè)FC層輸入要求(按列切分),從而省去了第一個(gè)FC層后匯總通信操作。
多頭自注意力機(jī)制張量并行與FFN類似,由于具有多個(gè)獨(dú)立的頭,因此相較于FFN更容易實(shí)現(xiàn)并行。其矩陣切分方式如圖所示。
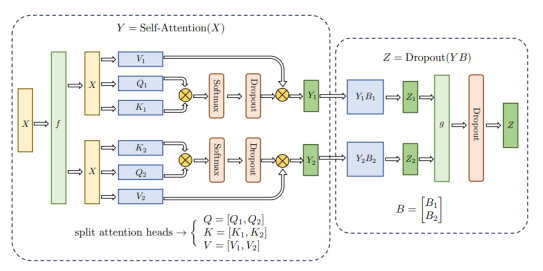
在分類網(wǎng)絡(luò)最后一層,通常會(huì)使用Softmax和Cross_entropy算子來計(jì)算交叉熵?fù)p失。然而,當(dāng)類別數(shù)量非常大時(shí),單計(jì)算設(shè)備內(nèi)存可能無法存儲(chǔ)和計(jì)算logit矩陣。針對(duì)這種情況,可以對(duì)這類算子進(jìn)行類別維度切分,并通過中間結(jié)果通信來獲得最終的全局交叉熵?fù)p失。首先計(jì)算的是softmax值,其公式如下:
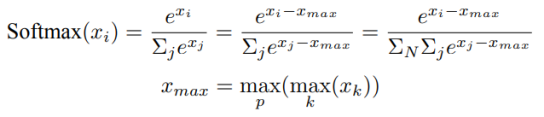
在計(jì)算交叉熵?fù)p失時(shí),可以采用張量并行的方式,按照類別維度對(duì)softmax值和目標(biāo)標(biāo)簽進(jìn)行切分,每個(gè)設(shè)備計(jì)算部分損失。最后再進(jìn)行一次通信,得到所有類別的損失。整個(gè)過程中,只需要進(jìn)行三次小量的通信,就可以完成交叉熵?fù)p失的計(jì)算。
3、管道并行
管道并行性將模型按層“垂直”分割。同時(shí),還可以“水平”分割層內(nèi)的某些操作,稱為張量并行訓(xùn)練。對(duì)于現(xiàn)代模型(如Transformer)的計(jì)算瓶頸,即將激活批矩陣與大權(quán)重矩陣相乘,可以在不同GPU上計(jì)算獨(dú)立的點(diǎn)積或每個(gè)點(diǎn)積的一部分并對(duì)結(jié)果求和。無論采用哪種策略,都可以將權(quán)重矩陣分割成均勻大小的分片,托管在不同的GPU上,并使用分片計(jì)算整個(gè)矩陣乘積的相關(guān)部分,再通過通信組合結(jié)果。Megatron-LM是一個(gè)例子,在Transformer自注意力層和MLP層中實(shí)現(xiàn)矩陣乘法的并行化。PTD-P結(jié)合張量、數(shù)據(jù)和管道并行性,通過為每個(gè)設(shè)備分配多個(gè)非連續(xù)層以減少氣泡開銷,但增加了網(wǎng)絡(luò)通信成本。有時(shí),輸入可以跨維度并行化,并通過更細(xì)粒度的示例進(jìn)行計(jì)算,以減少峰值內(nèi)存消耗。序列并行是一種思想,將輸入序列在時(shí)間上分割成多個(gè)子示例,從而按比例減少內(nèi)存消耗。
四、混合專家 (MoE)
隨著研究人員試圖突破模型大小限制,混合專家(MoE) 方法引起廣泛關(guān)注。其核心思想是集成學(xué)習(xí),即多個(gè)弱學(xué)習(xí)器組合可生強(qiáng)大的學(xué)習(xí)器。使用 MoE 方法時(shí),僅需使用網(wǎng)絡(luò)一小部分即可計(jì)算任何輸入的輸出。一種示例方法是擁有多組權(quán)重,網(wǎng)絡(luò)可以在推理時(shí)通過門控機(jī)制選擇使用哪一組權(quán)重。這可以在不增加計(jì)算成本的情況下啟用更多參數(shù)。每組權(quán)重都被稱為“專家”,希望網(wǎng)絡(luò)能夠?qū)W會(huì)為每個(gè)專家分配專門的計(jì)算和技能。不同專家可以托管在不同 GPU 上,從而提供一種清晰方法來擴(kuò)展模型所使用的 GPU 數(shù)量。恰好一層 MoE 包含作為專家前饋網(wǎng)絡(luò) {E_i}^n_{i=1} 和可訓(xùn)練門控網(wǎng)絡(luò) G 學(xué)習(xí)概率分布 n “專家”,以便將流量路由到少數(shù)選定的 “專家”。當(dāng) “專家” 數(shù)量過多時(shí),可以考慮使用兩級(jí)分層 MoE。
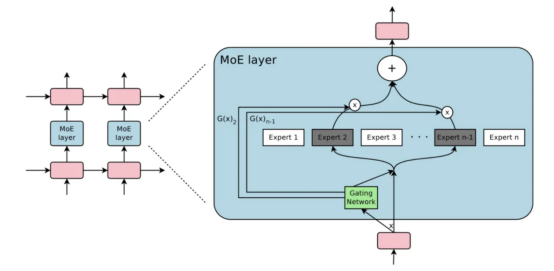
GShard(Google Brain團(tuán)隊(duì)開發(fā)的一款分布式訓(xùn)練框架
)通過分片將MoE變壓器模型擴(kuò)展至6000億個(gè)參數(shù)。MoE變壓器用MoE層替換所有其他前饋層。分片MoE變壓器僅具有跨多臺(tái)機(jī)器分片的MoE層,其他層只是簡(jiǎn)單地復(fù)制。Switch Transformer(Transformer類的萬億級(jí)別模型
)通過稀疏開關(guān)FFN層替換密集前饋層(其中每個(gè)輸入僅路由到一個(gè)專家網(wǎng)絡(luò)),將模型大小擴(kuò)展到數(shù)萬億個(gè)參數(shù),并具有更高的稀疏性。
五、其他節(jié)省內(nèi)存的設(shè)計(jì)
1、混合精度計(jì)算(Mixed Precision Training)
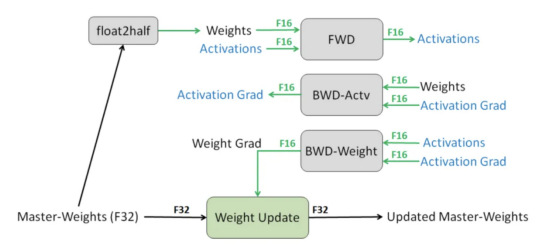
混合精度訓(xùn)練(Mixed Precision Training)是指在訓(xùn)練模型時(shí)同時(shí)使用16位和32位浮點(diǎn)類型,以加快運(yùn)算速度和減少內(nèi)存使用。在NVIDIA GPU上,使用float16進(jìn)行運(yùn)算比使用float32快一倍多,大大提高了算力的上限。然而,將模型的運(yùn)算轉(zhuǎn)換為FP16并不能完全解決問題,因?yàn)镕P16的數(shù)值范圍遠(yuǎn)小于FP32和TF32,限制模型的運(yùn)算能力。為確保模型能夠收斂到與FP32相同結(jié)果,需要采用額外的技巧。
1)權(quán)重備份(Weight Backup)
其中一種避免以半精度丟失關(guān)鍵信息的技術(shù)是權(quán)重備份。在訓(xùn)練時(shí),權(quán)重、激活值和梯度都使用FP16進(jìn)行計(jì)算,但會(huì)額外保存TF32的權(quán)重值。在進(jìn)行梯度更新時(shí),對(duì)TF32的權(quán)重進(jìn)行更新。在下一步訓(xùn)練時(shí),將TF32的權(quán)重值轉(zhuǎn)換為FP16,然后進(jìn)行前向和反向計(jì)算。
2)損失縮放(Loss Scaling)
在訓(xùn)練模型時(shí),由于梯度量級(jí)往往非常小,使用FP16格式可能會(huì)導(dǎo)致一些微小梯度直接被歸零。大部分非零梯度實(shí)際上并不在FP16表示范圍內(nèi)。由于FP16格式右側(cè)部分并未被充分利用,我們可以通過將梯度乘以一個(gè)較大系數(shù),使整個(gè)梯度分布向右移動(dòng)并完全落在FP16表示范圍內(nèi)。一種簡(jiǎn)單方法是在計(jì)算梯度之前先將損失乘以一個(gè)較大值,以此放大所有梯度。在進(jìn)行梯度更新時(shí),再將其縮小回原來的并使用TF32進(jìn)行更新。
3)精度累加(Precision Accumulation)
在FP16模型中,一些算術(shù)運(yùn)算如矩陣乘法需要用TF32來累加乘積結(jié)果,然后再轉(zhuǎn)換為FP16。例如,Nvidia GPU設(shè)備中的Tensor Core支持利用FP16混合精度加速,同時(shí)保持精度。Tensor Core主要用于實(shí)現(xiàn)FP16的矩陣相乘,并在累加階段使用TF32大幅減少混合精度訓(xùn)練的精度損失。
2、梯度累積(Gradient Accumulation)
梯度累積是一種神經(jīng)網(wǎng)絡(luò)訓(xùn)練技術(shù),通過將數(shù)據(jù)樣本按批次拆分為幾個(gè)小批次,并按順序計(jì)算。在每個(gè)小批次中,計(jì)算梯度并累積,在最后一個(gè)批次后求平均來更新模型參數(shù)。神經(jīng)網(wǎng)絡(luò)由許多相互連接的神經(jīng)網(wǎng)絡(luò)單元組成,樣本數(shù)據(jù)通過所有層并計(jì)算預(yù)測(cè)值,然后通過損失函數(shù)計(jì)算每個(gè)樣本的損失值(誤差)。神經(jīng)網(wǎng)絡(luò)通過反向傳播算法計(jì)算損失值相對(duì)于模型參數(shù)的梯度,并利用這些梯度信息來更新網(wǎng)絡(luò)參數(shù)。梯度累積每次獲取一個(gè)批次的數(shù)據(jù),計(jì)算一次梯度(前向),不斷累積梯度,累積一定次數(shù)后根據(jù)累積的梯度更新網(wǎng)絡(luò)參數(shù),然后清空所有梯度信息進(jìn)行下一次循環(huán)。
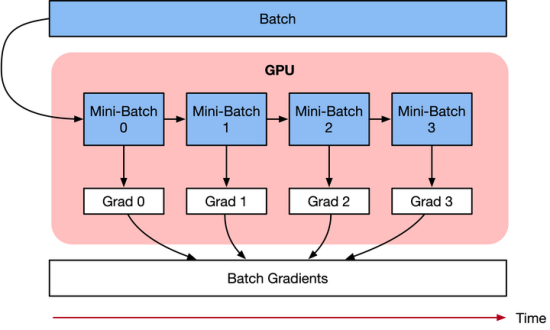
3、卸載CPU(CPU Offloading)
CPU Offloading是指將未使用的數(shù)據(jù)暫時(shí)卸載到CPU或不同的設(shè)備之間,并在需要時(shí)重新讀取回來。由于CPU存儲(chǔ)相比GPU存儲(chǔ)具有更大的空間和更低的價(jià)格,因此實(shí)現(xiàn)雙層存儲(chǔ)可以大大擴(kuò)展訓(xùn)練時(shí)的存儲(chǔ)空間。然而,簡(jiǎn)單的實(shí)現(xiàn)可能會(huì)導(dǎo)致訓(xùn)練速度降低,而復(fù)雜的實(shí)現(xiàn)需要實(shí)現(xiàn)預(yù)取數(shù)據(jù)以確保設(shè)備無需等待。ZeRO是一種實(shí)現(xiàn)這一想法的方式,它將參數(shù)、梯度和優(yōu)化器狀態(tài)分配到所有可用的硬件上,并根據(jù)需要進(jìn)行具體化。
4、激活重新計(jì)算(Activation Recomputation)
Recompute是一種在前向計(jì)算中釋放tensor,在反向傳播時(shí)需要重新計(jì)算的方法,適用于占用內(nèi)存大但重新計(jì)算量小的tensor。重新計(jì)算的方式有三種:
Speed Centric會(huì)保留計(jì)算出的tensor以備后續(xù)使用;
Memory Centric會(huì)在計(jì)算完成后釋放tensor,需要時(shí)再重新計(jì)算;
Cost Aware會(huì)在計(jì)算完成后判斷是否保留tensor,若可能導(dǎo)致內(nèi)存峰值則釋放。
可以將swap和recompute結(jié)合使用,針對(duì)特定op采用不同方式。還可以預(yù)先迭代幾次,收集內(nèi)存和運(yùn)行時(shí)間信息,判斷哪些tensor該swap,哪些該recompute。
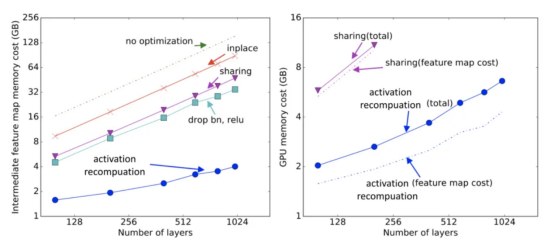
5、模型壓縮(Compression)
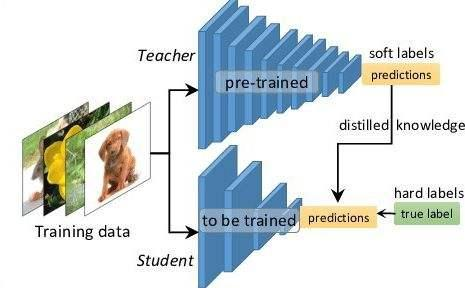
模型壓縮是通過裁剪、權(quán)重共享等方式處理大模型,以減少參數(shù)量。然而,這種方式容易降低模型精度,因此使用較少。常見的模型壓縮方法包括修剪、權(quán)重共享、低秩分解、二值化權(quán)重和知識(shí)蒸餾。
修剪可以采用對(duì)連接、kernel、channel進(jìn)行裁剪的方式;權(quán)重共享是通過共享模型參數(shù)來減少參數(shù)量;低秩分解將矩陣分解為低秩形式,從而減少參數(shù)量;二值化權(quán)重是將權(quán)重從32位降至8位或16位,實(shí)現(xiàn)混合精度訓(xùn)練;知識(shí)蒸餾是使用訓(xùn)練好的教師模型指導(dǎo)學(xué)生模型訓(xùn)練。
6、高效內(nèi)存優(yōu)化器(Memory Efficient Optimizer)
優(yōu)化器在模型訓(xùn)練中的內(nèi)存消耗是一個(gè)重要問題。以Adam優(yōu)化器為例,它需要存儲(chǔ)動(dòng)量和方差,與梯度和模型參數(shù)規(guī)模相同,內(nèi)存需求增加。為減少內(nèi)存占用,已經(jīng)提出了幾種優(yōu)化器,如Adafactor和SM3,采用不同的方法估計(jì)二階矩或大幅減少內(nèi)存使用。
ZeRO優(yōu)化器是一種針對(duì)大型模型訓(xùn)練的內(nèi)存優(yōu)化方法。通過觀察模型狀態(tài)和激活臨時(shí)緩沖區(qū)及不可用碎片內(nèi)存的消耗,采用兩種方法:ZeRO-DP和ZeRO-R。ZeRO-DP通過動(dòng)態(tài)通信調(diào)度來減少模型狀態(tài)上的冗余,而ZeRO-R則使用分區(qū)激活重新計(jì)算、恒定緩沖區(qū)大小和動(dòng)態(tài)內(nèi)存碎片整理來優(yōu)化殘留狀態(tài)的內(nèi)存消耗。
英偉達(dá)禁令之后,中國(guó)AI計(jì)算何去何從?
在10月17日,美國(guó)強(qiáng)化對(duì)中國(guó)市場(chǎng)的AI芯片禁令,將性能和密度作為出口管制標(biāo)準(zhǔn),禁止出口單芯片超過300teraflops算力、性能密度超過每平方毫米370gigaflops的芯片。由于限制AMD、英特爾等公司的高端AI芯片,尤其是英偉達(dá)的主流AI訓(xùn)練用GPU A100和H100,該禁令又被稱為“英偉達(dá)禁令”。
針對(duì)新的芯片禁令,AI產(chǎn)業(yè)議論紛紛,焦點(diǎn)主要集中在實(shí)施時(shí)間、緩沖地帶、涉及的GPU型號(hào)和禁令期限等方面。盡管存在爭(zhēng)議,但針對(duì)中國(guó)的高端AI芯片禁令仍在堅(jiān)定推行。
現(xiàn)在,AI行業(yè)必須形成共識(shí)應(yīng)對(duì)挑戰(zhàn)。與其過分關(guān)注被禁的GPU,我們應(yīng)更深入思考在芯片鐵幕時(shí)代下中國(guó)AI計(jì)算未來發(fā)展路徑。下面將探討當(dāng)前產(chǎn)業(yè)形勢(shì)并共同探討AI計(jì)算前行之路。
一、目前現(xiàn)狀
與之前情況相比,英偉達(dá)禁令出臺(tái)后大眾輿論與AI行業(yè)反應(yīng)似乎更為冷靜。僅在消費(fèi)級(jí)顯卡RTX 4090是否被禁問題上引發(fā)游戲玩家和商家爭(zhēng)論。盡管行業(yè)不希望看到高端AI芯片被禁售,但對(duì)此局面已有預(yù)期。美國(guó)對(duì)華芯片封鎖已持續(xù)多年,英偉達(dá)部分高端GPU已被禁止出售,產(chǎn)業(yè)界的反應(yīng)也從驚訝轉(zhuǎn)變?yōu)槔潇o應(yīng)對(duì)。加上ChatGPT的火爆導(dǎo)致全球高端GPU市場(chǎng)行情上漲,美國(guó)方面多次表示要推動(dòng)對(duì)華整體性的高端AI芯片禁售。
為應(yīng)對(duì)禁令并受到大模型發(fā)展的推動(dòng),去年年底到今年上半年,眾多中國(guó)科技、金融、汽車等企業(yè)集中購(gòu)買英偉達(dá)高端GPU,導(dǎo)致市場(chǎng)上GPU供不應(yīng)求。對(duì)于許多中國(guó)中小型科技企業(yè)和AI創(chuàng)業(yè)公司來說,原本就很難買到高端GPU,禁售并未帶來太大變化。實(shí)際上,國(guó)內(nèi)AI芯片產(chǎn)業(yè)在貿(mào)易摩擦初期便開始加速發(fā)展,雖然英偉達(dá)的高端GPU在AI訓(xùn)練需求方面難以替代,但并非不可替代。
此外,AI芯片與手機(jī)芯片不同,并不關(guān)乎大眾消費(fèi)者。華為已在手機(jī)芯片領(lǐng)域取得突破。因此,無論是大眾還是行業(yè),對(duì)禁令都持坦然態(tài)度,甚至有些習(xí)以為常。然而,必須承認(rèn)的是,禁令對(duì)中國(guó)AI行業(yè)仍造成了一定程度的傷害:短期內(nèi)更換英偉達(dá)GPU面臨芯片產(chǎn)能和生態(tài)兼容性等難題;禁令還將直接損害使用英偉達(dá)產(chǎn)品的AI服務(wù)器等領(lǐng)域的廠商。
長(zhǎng)期禁令可能使中國(guó)AI計(jì)算與全球高端芯片脫鉤,可能帶來復(fù)雜的負(fù)面影響,包括:中國(guó)AI算力發(fā)展可能落后于英偉達(dá)高端GPU的更新迭代;在底層算力發(fā)展分歧下,中國(guó)AI產(chǎn)業(yè)可能在軟件技術(shù)方面掉隊(duì);科技封鎖可能從AI芯片擴(kuò)展到通用算力、存儲(chǔ)、基礎(chǔ)軟件等數(shù)字化基礎(chǔ)能力。因此,需要制定三項(xiàng)同時(shí)發(fā)力的“突圍方案”:加快國(guó)產(chǎn)AI芯片的自主研發(fā)和生態(tài)建設(shè);加大力度投資大模型等軟件技術(shù),降低對(duì)英偉達(dá)等公司的依賴;加強(qiáng)與國(guó)際科技合作,推動(dòng)中國(guó)AI計(jì)算的全球化發(fā)展。
二、解決方案一:用好買家身份
作為全球芯片市場(chǎng)最大買家,中國(guó)企業(yè)應(yīng)該利用好這個(gè)身份,擺脫中美科技貿(mào)易中的思維誤區(qū)。我們往往認(rèn)為游戲規(guī)則是由美國(guó)政府和企業(yè)制定的,只能被動(dòng)接受,但實(shí)際上作為買家應(yīng)該擁有更多話語權(quán)。針對(duì)中國(guó)市場(chǎng)的AI芯片禁令,最直接傷害的是以英偉達(dá)為代表的美國(guó)科技巨頭,因?yàn)橹袊?guó)市場(chǎng)對(duì)他們的AI芯片需求最大。英偉達(dá)CEO黃仁勛曾表示,如果被剝奪了中國(guó)市場(chǎng),他們將沒有應(yīng)急措施,世界上沒有另一個(gè)中國(guó)。因此,我們應(yīng)該認(rèn)識(shí)到作為買家的力量,并利用好這個(gè)身份來維護(hù)自己的利益。
我們可以看到美國(guó)科技公司和政府之間的矛盾。科技公司追求商業(yè)利益,而政府則追求政治利益。美國(guó)科技公司一直在嘗試反對(duì)和繞過禁令,例如英偉達(dá)推出針對(duì)中國(guó)市場(chǎng)的特供版GPU。
三、解決方案2:以云代卡,算力集中
在可見的較長(zhǎng)時(shí)間里,美國(guó)對(duì)中國(guó)AI芯片封禁只會(huì)加強(qiáng),這給AI大模型發(fā)展帶來挑戰(zhàn)。許多業(yè)內(nèi)人士認(rèn)為,大模型發(fā)展雖快,但沒有呈現(xiàn)此前科技風(fēng)口的迅猛局面,投資缺錢、計(jì)算缺卡是主要原因。
為解決中國(guó)AI產(chǎn)業(yè)在禁令之下的算力缺口問題,企業(yè)需要加大云端AI算力配置和投入,推動(dòng)以云代卡。事實(shí)上,在高端AI芯片可能被禁的大趨勢(shì)下,中國(guó)幾大公有云廠商都開始加強(qiáng)囤積英偉達(dá)高端GPU。這不僅因?yàn)樽陨硇枰哟蟠竽P屯度耄蜷_MaaS市場(chǎng),也對(duì)AI算力有直接需求。此外,GPU轉(zhuǎn)化為云資源池后可以長(zhǎng)期復(fù)用,對(duì)云廠商來說具有進(jìn)可攻、退可守的優(yōu)勢(shì)。因此,今年上半年出現(xiàn)高端AI芯片流向云廠商、中小企業(yè)難以獲得芯片的局面。
客觀來看,這種高端AI芯片集中向云的舉動(dòng)有利于中國(guó)市場(chǎng)統(tǒng)籌應(yīng)對(duì)AI芯片禁令,也符合東數(shù)西算戰(zhàn)略思路。另一趨勢(shì)是,隨著大模型參數(shù)和使用數(shù)據(jù)量不斷加大,本地化卡池訓(xùn)練已經(jīng)越來越緊張,在云端進(jìn)行千卡、萬卡訓(xùn)練成為未來主要發(fā)展方向,因此企業(yè)用戶會(huì)更加積極地走向云端。
同時(shí),云端AI算力不僅限于囤積英偉達(dá)GPU。隨著政策推動(dòng)和自主AI芯片采購(gòu)力度的加大,云端化和自主化結(jié)合的AI算力將成為發(fā)展趨勢(shì)。根據(jù)IDC數(shù)據(jù),2023上半年中國(guó)AI服務(wù)器已經(jīng)使用50萬塊自主開發(fā)的AI加速器芯片。華為已經(jīng)推出昇騰AI云服務(wù),提供自主AI算力服務(wù)。在東數(shù)西算背景下,各地建立一批采用自主AI算力的AI計(jì)算中心,保障云端AI算力穩(wěn)定可靠供給。
然而,很多企業(yè)仍然傾向于采購(gòu)本地AI算力。一方面是因?yàn)橛ミ_(dá)GPU市場(chǎng)緊缺,保值性高,甚至可以作為企業(yè)的核心資產(chǎn)。另一方面是因?yàn)樵贫薃I算力存在排隊(duì)、宕機(jī)、軟件服務(wù)缺失等問題,影響開發(fā)者體驗(yàn)。為進(jìn)一步提高開發(fā)者的云端AI算力使用體驗(yàn),公有云廠商需要進(jìn)一步努力。
四、方案三:讓國(guó)產(chǎn)AI算力爆發(fā)式成長(zhǎng)
面對(duì)新一輪AI芯片禁令,中國(guó)AI產(chǎn)業(yè)并非依賴英偉達(dá)的高端GPU,而是經(jīng)過多年發(fā)展,AI芯片產(chǎn)業(yè)已經(jīng)得到巨大發(fā)展。雖然英偉達(dá)市場(chǎng)份額仍占主導(dǎo),國(guó)產(chǎn)AI算力已經(jīng)具備一定市場(chǎng)占比,但在核心性能、軟件生態(tài)和出貨能力方面仍需不斷提升。客觀上,禁令的倒逼將加速國(guó)產(chǎn)AI算力的成長(zhǎng)與成熟周期。
為了實(shí)現(xiàn)這個(gè)目標(biāo),有幾件事非常重要:
1、形成產(chǎn)業(yè)共識(shí),避免概念混淆
雖然AI芯片市場(chǎng)呈現(xiàn)出眾多品牌和類型參與者,但其中存在的問題也不容忽視。對(duì)于類腦芯片等前沿技術(shù),目前仍處于暢想階段,而一些AI芯片廠商僅能自用,無法面向市場(chǎng)出貨,同時(shí)還有大量廠商處于早期建設(shè)階段,短期內(nèi)對(duì)AI計(jì)算自主化貢獻(xiàn)有限。
為應(yīng)對(duì)英偉達(dá)高端GPU禁售問題,需要將關(guān)注點(diǎn)集中在可行、有效的GPU替代方案上,避免過多的聯(lián)想和發(fā)散。只有形成產(chǎn)業(yè)共識(shí),才能更好地解決問題。
2、走向規(guī)模化商用,避免PPT造芯
目前國(guó)內(nèi)能夠出貨的AI芯片廠商主要集中在華為、百度、燧原科技和海光信息等少數(shù)幾家。大量半導(dǎo)體廠商與AI企業(yè)還停留在打造芯片的計(jì)劃與愿景上,導(dǎo)致政策支持與投資市場(chǎng)期待的國(guó)產(chǎn)AI芯片發(fā)展停滯,甚至有些企業(yè)可能只是在這一階段享受金融市場(chǎng)紅利而缺乏實(shí)質(zhì)性進(jìn)展。
為推動(dòng)產(chǎn)業(yè)發(fā)展,未來的產(chǎn)業(yè)導(dǎo)向應(yīng)該重將AI芯片從計(jì)劃轉(zhuǎn)向出貨,幫助廠商獲得直接商業(yè)回饋,讓產(chǎn)品與產(chǎn)能接受市場(chǎng)檢驗(yàn),逐步塑造正向現(xiàn)金流。
3、加強(qiáng)軟件生態(tài),強(qiáng)化遷移能力
英偉達(dá)GPU重要性不僅在于硬件性能,更在于其CUDA和PyTorch等軟件生態(tài)的強(qiáng)大能力。因此,發(fā)展國(guó)產(chǎn)AI芯片不能忽視軟件能力的提升。在加強(qiáng)自主軟件生態(tài)建設(shè)的同時(shí),還需要關(guān)注基于英偉達(dá)生態(tài)的AI模型遷移能力和遷移成本。
許多廠商已經(jīng)在這方面進(jìn)行探索,例如海光信息的DCU與CUDA在生態(tài)和編程環(huán)境上高度相似,使得CUDA用戶能夠以較低代價(jià)快速遷移到海光的ROCm平臺(tái)。此前,PyTorch2.1版本宣布支持華為昇騰,顯示出國(guó)產(chǎn)AI芯片已經(jīng)具備一定的規(guī)模化影響力,可以更多地融入全球軟件生態(tài)。未來要實(shí)現(xiàn)國(guó)產(chǎn)AI計(jì)算的爆發(fā),離不開國(guó)產(chǎn)AI基礎(chǔ)軟件生態(tài)的蓬勃發(fā)展。
4、加大對(duì)“主品牌”支持,形成規(guī)模化效應(yīng)
在中國(guó),為加速AI計(jì)算的成熟并實(shí)現(xiàn)自主化替代,應(yīng)盡快形成一超多強(qiáng)的市場(chǎng)格局,避免生態(tài)割裂和IT投資浪費(fèi)。在這個(gè)過程中,市場(chǎng)機(jī)制將起到?jīng)Q定性作用。然而,在當(dāng)前芯片禁令背景下,國(guó)產(chǎn)AI計(jì)算崛起已刻不容緩,應(yīng)加速形成一個(gè)“主品牌”來快速替代英偉達(dá)等進(jìn)口芯片。
目前看來,華為昇騰系列是最有可能成為國(guó)產(chǎn)AI算力的主品牌之一。科大訊飛董事長(zhǎng)劉慶峰曾表示,華為GPU已經(jīng)與英偉達(dá)A100并駕齊驅(qū)。數(shù)據(jù)顯示,昇騰310的整數(shù)精度算力達(dá)到16TOPS,而昇騰910的整數(shù)精度算力更是高達(dá)640TOPS,這意味著昇騰910的性能已接近英偉達(dá)A100。
同時(shí),昇騰是目前唯一在市場(chǎng)上占據(jù)一定份額的國(guó)產(chǎn)AI算力品牌,并在軟件方面培育類似英偉達(dá)CUDA的異構(gòu)計(jì)算架構(gòu)CANN和AI計(jì)算框架MindSpore。從核心性能、軟件生態(tài)和市場(chǎng)占有率三個(gè)角度來看,昇騰已經(jīng)具備加快成長(zhǎng)并實(shí)現(xiàn)AI算力大規(guī)模國(guó)產(chǎn)化替代的可能性。
短期內(nèi)推動(dòng)國(guó)產(chǎn)AI算力快速成長(zhǎng)的主要途徑包括規(guī)范行業(yè)標(biāo)準(zhǔn)、強(qiáng)化軟件建設(shè)以及提高自主品牌的支持。英偉達(dá)禁令是中國(guó)AI行業(yè)不愿面對(duì)、盡力避免,但又諱莫如深的問題。
英偉達(dá)將針對(duì)中國(guó)市場(chǎng)推出新的AI芯片,以應(yīng)對(duì)美國(guó)出口限制
據(jù)知情人士透露,NVIDIA已研發(fā)出為中國(guó)市場(chǎng)量身打造的新型改良AI芯片系列,包括HGX H20、L20 PCle和L2 PCle。在美國(guó)政府針對(duì)中國(guó)高科技行業(yè)加強(qiáng)出口限制的大背景下,NVIDIA的這一舉動(dòng)被業(yè)界視為對(duì)相關(guān)政策調(diào)整的直接回應(yīng)。此舉可能暗示該公司正在尋找遵守規(guī)定的同時(shí)保持市場(chǎng)競(jìng)爭(zhēng)力的策略。
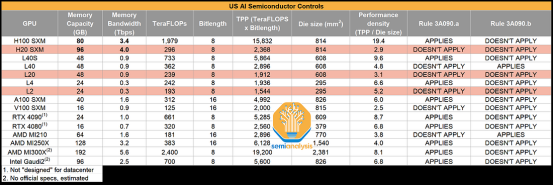
據(jù)業(yè)內(nèi)人士透露,英偉達(dá)為中國(guó)市場(chǎng)研發(fā)新一代改進(jìn)型AI芯片系列,包括HGX H20、L20 PCIe和L2 PCIe。這些芯片都基于英偉達(dá)的H100系列芯片,并采用了不同的架構(gòu)。
HGX H20采用NVIDIA Hopper架構(gòu),并配備高達(dá)96 GB的HBM3內(nèi)存,提供4TBB/s的帶寬。適用于要求極高的計(jì)算場(chǎng)景,展現(xiàn)出了卓越的性能。
L20 PCIe和L2 PCIe則采用NVIDIA Ada Lovelace架構(gòu),并針對(duì)不同計(jì)算需求提供多樣化的選擇。L20 PCIe配備48 GB GDDR6 w/ ECC內(nèi)存,而L2 PCIe則擁有24 GB GDDR6 w/ ECC內(nèi)存。特別值得注意的是,H20型號(hào)沒有RT Core,而L20和L2 PCIe則增加了這一功能,表明它們?cè)诠饩€追蹤能力上有所加強(qiáng)。
這些新系列芯片可能通過調(diào)整性能參數(shù)來滿足中國(guó)市場(chǎng)的特殊要求并規(guī)避某些出口禁令中的敏感技術(shù)。雖然這樣的產(chǎn)品定制化可能會(huì)帶來技術(shù)創(chuàng)新,但同時(shí)也可能帶來技術(shù)分裂的風(fēng)險(xiǎn),引發(fā)行業(yè)對(duì)技術(shù)標(biāo)準(zhǔn)分化的擔(dān)憂。
分析人士認(rèn)為,NVIDIA的這一舉措是其全球供應(yīng)鏈戰(zhàn)略的重要組成部分,反映出公司對(duì)全球經(jīng)濟(jì)形勢(shì)的靈活適應(yīng)。此舉將有助于NVIDIA維持在中國(guó)市場(chǎng)的業(yè)務(wù)活動(dòng)和客戶關(guān)系,同時(shí)也可能推動(dòng)中國(guó)本土廠商加速技術(shù)自立自強(qiáng)的步伐。
盡管美國(guó)的出口限制給中國(guó)市場(chǎng)的技術(shù)產(chǎn)品帶來了挑戰(zhàn),但據(jù)知情人士透露,英偉達(dá)已經(jīng)采取了針對(duì)性的技術(shù)調(diào)整,以符合出口規(guī)則,確保其產(chǎn)品可以順利進(jìn)入中國(guó)市場(chǎng)。據(jù)悉,英偉達(dá)預(yù)計(jì)將在11月16日之后宣布這一新系列產(chǎn)品,屆時(shí)將有更多細(xì)節(jié)公布。盡管英偉達(dá)尚未對(duì)此消息作出官方回應(yīng),但市場(chǎng)對(duì)這些可能的新產(chǎn)品已經(jīng)充滿期待。
藍(lán)海大腦大模型訓(xùn)練平臺(tái)
藍(lán)海大腦大模型訓(xùn)練平臺(tái)提供強(qiáng)大的算力支持,包括基于開放加速模組高速互聯(lián)的AI加速器。配置高速內(nèi)存且支持全互聯(lián)拓?fù)洌瑵M足大模型訓(xùn)練中張量并行的通信需求。支持高性能I/O擴(kuò)展,同時(shí)可以擴(kuò)展至萬卡AI集群,滿足大模型流水線和數(shù)據(jù)并行的通信需求。強(qiáng)大的液冷系統(tǒng)熱插拔及智能電源管理技術(shù),當(dāng)BMC收到PSU故障或錯(cuò)誤警告(如斷電、電涌,過熱),自動(dòng)強(qiáng)制系統(tǒng)的CPU進(jìn)入U(xiǎn)LFM(超低頻模式,以實(shí)現(xiàn)最低功耗)。致力于通過“低碳節(jié)能”為客戶提供環(huán)保綠色的高性能計(jì)算解決方案。主要應(yīng)用于深度學(xué)習(xí)、學(xué)術(shù)教育、生物醫(yī)藥、地球勘探、氣象海洋、超算中心、AI及大數(shù)據(jù)等領(lǐng)域。
一、為什么需要大模型?
1、模型效果更優(yōu)
大模型在各場(chǎng)景上的效果均優(yōu)于普通模型
2、創(chuàng)造能力更強(qiáng)
大模型能夠進(jìn)行內(nèi)容生成(AIGC),助力內(nèi)容規(guī)模化生產(chǎn)
3、靈活定制場(chǎng)景
通過舉例子的方式,定制大模型海量的應(yīng)用場(chǎng)景
4、標(biāo)注數(shù)據(jù)更少
通過學(xué)習(xí)少量行業(yè)數(shù)據(jù),大模型就能夠應(yīng)對(duì)特定業(yè)務(wù)場(chǎng)景的需求
二、平臺(tái)特點(diǎn)
1、異構(gòu)計(jì)算資源調(diào)度
一種基于通用服務(wù)器和專用硬件的綜合解決方案,用于調(diào)度和管理多種異構(gòu)計(jì)算資源,包括CPU、GPU等。通過強(qiáng)大的虛擬化管理功能,能夠輕松部署底層計(jì)算資源,并高效運(yùn)行各種模型。同時(shí)充分發(fā)揮不同異構(gòu)資源的硬件加速能力,以加快模型的運(yùn)行速度和生成速度。
2、穩(wěn)定可靠的數(shù)據(jù)存儲(chǔ)
支持多存儲(chǔ)類型協(xié)議,包括塊、文件和對(duì)象存儲(chǔ)服務(wù)。將存儲(chǔ)資源池化實(shí)現(xiàn)模型和生成數(shù)據(jù)的自由流通,提高數(shù)據(jù)的利用率。同時(shí)采用多副本、多級(jí)故障域和故障自恢復(fù)等數(shù)據(jù)保護(hù)機(jī)制,確保模型和數(shù)據(jù)的安全穩(wěn)定運(yùn)行。
3、高性能分布式網(wǎng)絡(luò)
提供算力資源的網(wǎng)絡(luò)和存儲(chǔ),并通過分布式網(wǎng)絡(luò)機(jī)制進(jìn)行轉(zhuǎn)發(fā),透?jìng)魑锢砭W(wǎng)絡(luò)性能,顯著提高模型算力的效率和性能。
4、全方位安全保障
在模型托管方面,采用嚴(yán)格的權(quán)限管理機(jī)制,確保模型倉(cāng)庫(kù)的安全性。在數(shù)據(jù)存儲(chǔ)方面,提供私有化部署和數(shù)據(jù)磁盤加密等措施,保證數(shù)據(jù)的安全可控性。同時(shí),在模型分發(fā)和運(yùn)行過程中,提供全面的賬號(hào)認(rèn)證和日志審計(jì)功能,全方位保障模型和數(shù)據(jù)的安全性。
三、常用配置
1、處理器CPU:
Intel Xeon Gold 8358P 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
Intel Xeon Platinum 8350C 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
Intel Xeon Platinum 8458P 28C/56T 2.7GHz 38.5MB,DDR4 2933,Turbo,HT 205W
Intel Xeon Platinum 8468 Processor 48C/64T 2.1GHz 105M Cache 350W
AMD EPYC? 7742 64C/128T,2.25GHz to 3.4GHz,256MB,DDR4 3200MT/s,225W
AMD EPYC? 9654 96C/192T,2.4GHz to 3.55GHz to 3.7GHz,384MB,DDR5 4800MT/s,360W
2、顯卡GPU:
NVIDIA L40S GPU 48GB
NVIDIA NVLink-A100-SXM640GB
NVIDIA HGX A800 80GB
NVIDIA Tesla H800 80GB HBM2
NVIDIA A800-80GB-400Wx8-NvlinkSW
審核編輯:湯梓紅
-
gpu
+關(guān)注
關(guān)注
28文章
4930瀏覽量
130992 -
人工智能
+關(guān)注
關(guān)注
1805文章
48936瀏覽量
248277 -
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3935瀏覽量
93429
發(fā)布評(píng)論請(qǐng)先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論