 淺談AI模型在漂移檢測中的應用
淺談AI模型在漂移檢測中的應用
人工智能應用的開發過程中,AI 模型的泛化能力是一個非常重要的考量因素,理想情況下,基于訓練數據集優化得到的 AI 模型,不存在過擬合或欠擬合問題,可以直接遷移到新數據上用于推斷。
在這種設定下,訓練數據集是從未知分布 P 中獨立同分布生成,且數據集是靜態、均衡且無偏的,1. 訓練數據集中的樣本能夠全面描述目標總體的底層特征,2. 數據總體的統計分布不會隨時間和外部環境因素改變。實際上,真實應用場景無法滿足這種理想假設,所以,在生產或運營環境中,如果 AI 模型的輸入數據和訓練集來自不同統計分布時,模型的性能將無法達到預期,甚至輸出不可靠的預測結果。
因此,在實際應用中,可能出現以下兩種場景:
1.持續監控并維護 AI 模型,例如,定期使用新數據更新模型,必要時重新選擇特征輸入或更改模型以保證預測能力;
2.維持原 AI 模型,在出現置信度不夠高的預測結果時,例如,針對未知類別的樣本,或異常值進行預測時,駁回模型推斷結果并預警。
本文將圍繞第一種場景,展開介紹如何結合數據開展漂移檢測,以判定合適的時機對模型進行更新。
引例:車載動力電池的健康狀態估計
舉個簡單的例子,針對電動汽車電池的容量衰退問題,開發健康狀態估計算法。在駕駛條件下無法直接測量電池容量,基于歷史或實驗數據,構建 AI 模型作為估計容量衰退趨勢,以緩解里程焦慮。
在訓練 AI 模型用于健康狀態(SoH)估計時,模型的輸入包括電壓、電流、電池荷電狀態 (SoC) 等信息,其中 SoC 這一狀態量,會受到外部環境溫度影響,而溫度波動的統計分布又隨時間或空間而變化,從而間接影響到 SoH 估計的結果,這種現象稱為漂移,當訓練數據無法覆蓋到實際應用中某些工況的溫度范圍,實際預測過程中采集的數據偏離原訓練數據的統計分布,將導致模型預測準確度下降。
因此,在生產環境中部署 AI 模型的同時,引入漂移檢測,監控流數據是否發生漂移,以確定是否需要基于最近采集的數據執行再訓練(如下圖黃色箭頭所示)。
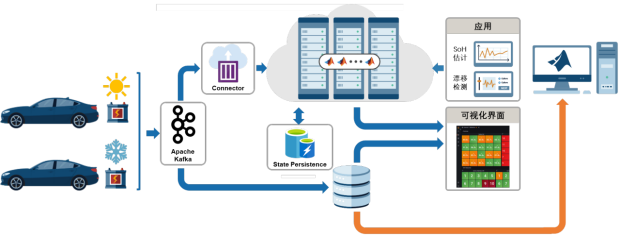
“數據漂移” 和 “概念漂移”
在監控機器學習模型的性能,判斷是否需要對模型進行維護時,存在兩種可能的情況:
數據漂移:如果模型推斷時,輸入的數據和訓練數據存在明顯差異,模型性能無法達到預期,這種情況下,需要結合新數據,對模型進行再訓練,調整可學習參數。
概念漂移:當模型學習的概念依賴于某些未被考慮到特征/變量時,例如,利用模型預測交通堵塞情況,但沒有考慮到與節假日相關的特征,或是當輸入特征和模型預測的目標概念之間,底層關系發生變化時,這種情況下,需要評估是否需要更換模型,而不僅僅是重訓練原模型。
MATLAB 的 Statistics and Machine Learning Toolbox,可支持:
1.根據批量數據檢測數據漂移:調用 detectdrift 函數,通過置換檢驗判斷目標數據集相對于基準數據集是否存在漂移。
2.根據流式數據檢測概念漂移:構建 incrementalConceptDriftDetector 對象,指定使用 DDM,HDDMW 或 HDDMA 算法,根據實時輸入的數據流,調用 detectdrift 函數評估是否發生概念漂移。
本文將以電池 SoH 估計所使用的數據集為例,介紹基于批量數據的數據漂移檢測,并簡要說明如何開展流式數據的概念漂移檢測。
電池健康監控系統中的漂移檢測
數據準備
在分析工程大數據時,一個常見的問題是,如何高效管理多個不同試驗、工況、日期的多通道測量數據,Predictive Maintenance Toolbox 提供了一個專用的對象 fileEnsembleDatastore 用于創建關于本地或遠程數據集的索引,并根據自定義讀取函數 ReadFcn,對數據集進行增量式或批量式訪問。按照數據集中的不同變量類型,將不同變量分別定義為:數據變量(測量量)、獨立變量(時間戳、文件名等)或狀態變量(標簽信息)。并通過 SelectedVariables 屬性,指定每次訪問數據集需要讀取的部分變量。此外,經過特征提取后的數據可通過自定義 WriteToMemberFcn 函數,再次寫回到 fileEnsembleDatastore 便于集中管理。關于如何使用 fileEnsembleDatastore,可查看文檔鏈接:File Ensemble Datastore with Measured Data[1]。
sample = read(fensemble);
time = sample.("Current"){:}.Time;
current = sample.("Current"){:}.Var1;
voltage = sample.("Voltage"){:}.Var1;
SoC = sample.("SoC_B1"){:}.Var1;
SoH = sample.("SoH"){:}.Var1;
tt = timetable(time,current,voltage,SoC,SoH);
figure
stackedplot(tt)
ans = 1×5 table
| Key | Current | Voltage | SoC_B1 | ? | |
| 1 |
360001×1 timetable |
360001×1 timetable |
360001×1 timetable |
? |
完整文件集一共由20組電池數據組成,其中 key 代表各個文件的編號。
fileEnsembleDatastore 支持通過 read 或 readall 方法,將數據讀取到內存。接下來,我們嘗試選取一組數據查看各個狀態量的時間序列:
prj = currentProject; location = fullfile(prj.RootFolder,"TrainingData","battery*.mat"); extension = '.mat'; fensemble = fileEnsembleDatastore(location,extension); fensemble.ReadFcn = @readBatteryData; fensemble.DataVariables = ["Current","Voltage","SoC_B1","SoH"]; fensemble.SelectedVariables = ["Current","Voltage","SoC_B1","SoH"]; preview(fensemble)
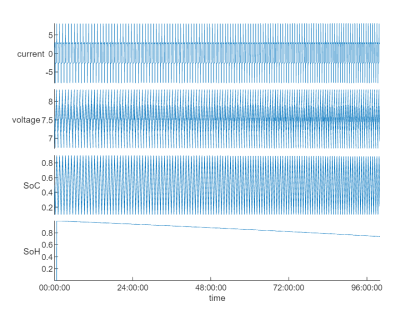
特征提取
從上圖信號波形構建 AI 模型進行預測或是判斷是否存在漂移,是非常困難的,因此,針對特征工程往往是必要的。利用 Diagnostic Feature Designer App 可通過交互式方式,對時間序列數據進行可視化探查,并提取統計或時頻域特征,并導出函數用于后續處理。了解更多可參考:Explore Ensemble Data and Compare Features Using Diagnostic Feature Designer[2]。使用預先導出的 diagnosticFeatures_Historical 函數,從基準數據集中提取各種統計特征得到特征表:
batteryData = readall(fensemble); % 通過 readall 函數將所有數據讀入內存 baselineData = batteryData(batteryData.key<=10,:); % 將編號前10的文件作為基準數據集 baselineFeatures = diagnosticFeatures_Historical(baselineData); head(baselineFeatures)

size(baselineFeatures)
ans = 1×2
2000 20
特征表維度為 2000x20,通過將原始基準數據分為 2000 個長度分別為 1800s 的時間序列,并提取各個原始物理量的多個統計和頻域特征,表格中,前4列記錄的是文件編號和起止時間戳信息,在后續處理中,將重點關注第 5 列到最末列(20)的特征數據。
再從完整數據集中,選取部分數據作為目標數據集,并提取特征:
idx = 15; % 范圍 11~19 targetData = batteryData(batteryData.key>idx,:); targetFeatures = diagnosticFeatures_Historical(targetData);
對比基準數據集和目標數據集,可視化各個特征的統計分布:
figure tiledlayout(4,4); for i = 5:width(baselineFeatures) nexttile; histogram(baselineFeatures{:,i},Normalization="pdf"); hold on histogram(targetFeatures{:,i},Normalization="pdf"); hold off xlabel(baselineFeatures.Properties.VariableNames{i},Interpreter="none"); end legend("baseline","target",location="northeastoutside")
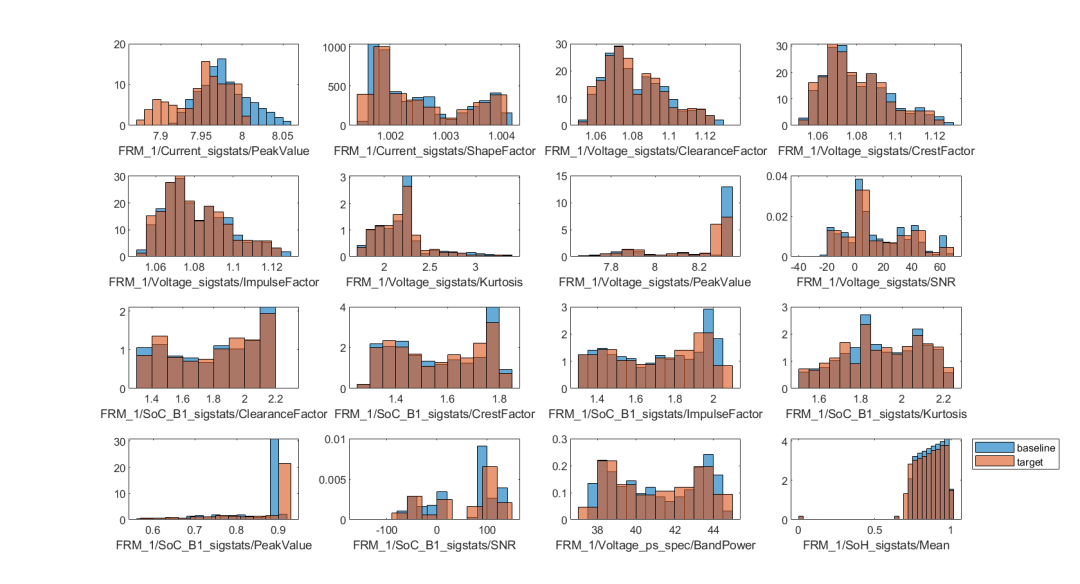
基于批量數據的漂移檢測
從上圖可以看出,部分特征,例如第一個特征電流峰值,可以從圖中看出,藍色基準數據集的取值范圍更大,這一特征的均值略高于紅色目標數據集的均值。如何定量或定性地判斷模型輸入數據/特征是否發生了漂移呢?針對批量數據,detectdrift 采用置換檢驗這一方法,推斷目標數據相較于基準數據,是否發生數據漂移,detectdrift 函數調用方式如下:
DDiagnostics = detectdrift(baselineFeatures(:,5:end),targetFeatures(:,5:end)); % 前4列記錄的是文件編號和起止時間戳信息,檢測漂移時不需要考慮
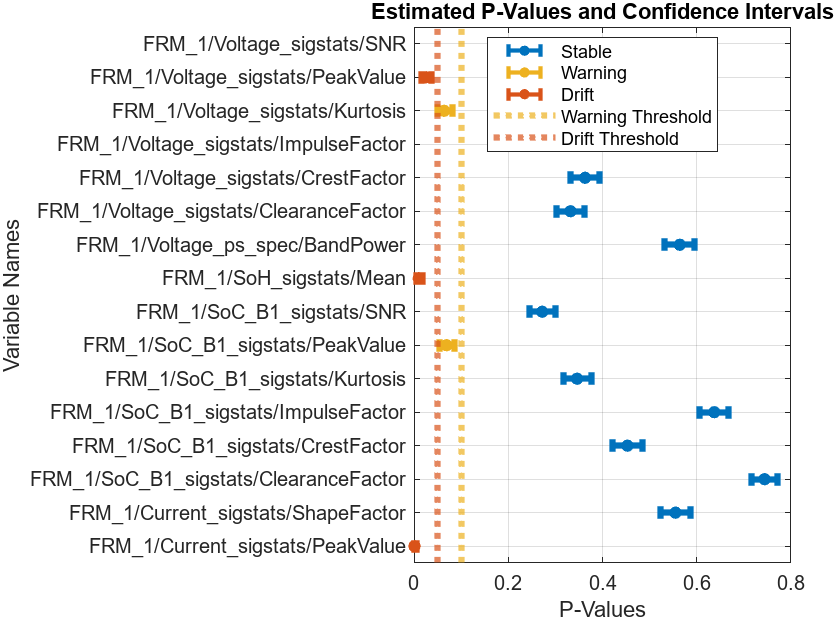
計算結果以 DriftDiagnostics 對象返回,其中記錄了上述計算中涉及到的相關屬性信息,針對 DriftDiagnostics 對象的方法函數可以幫助我們理解檢測結果和推斷過程。例如,通過 summary 匯總各個特征的漂移狀態、p 值和置信區間:
summary(DDiagnostics)
Multiple Test Correction Drift Status:Drift
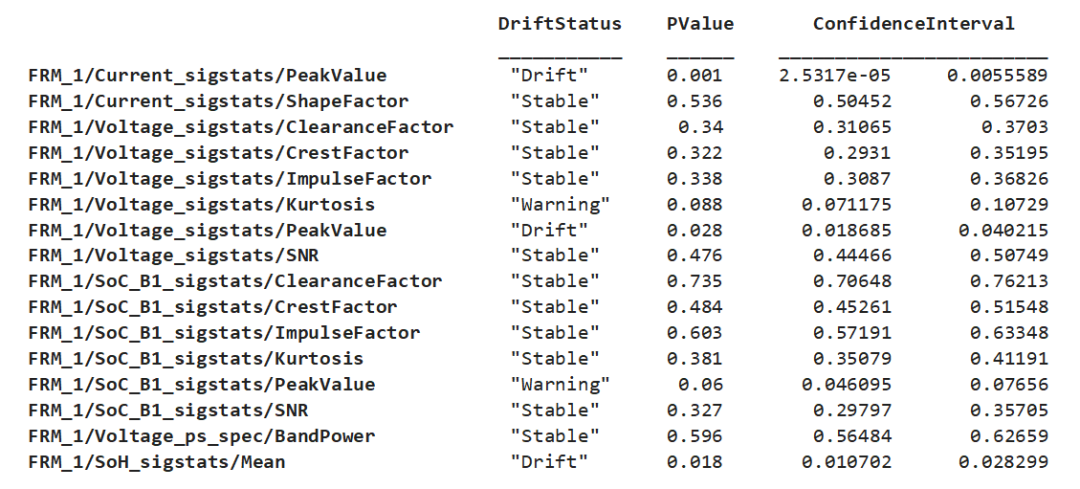
figure; plotDriftStatus(DDiagnostics)
【算法解析】
什么是置換檢驗?這是一個非參數化統計顯著度檢驗方法,適用于總體分布未知的數據集。實現過程如下:
提出零假設:數據沒有發生漂移
選擇一個測試統計量,例如基準數據m的個樣本均值 μ1和目標數據 n 個樣本均值 μ2的差值 t0=μ1-μ2,算法提供了 Wasserstein, Kolmogorov-Smirnov 等測試統計量供選擇
將兩組數據合并,對全部數據樣本進行不放回抽樣,重新得到兩組樣本量分別為 m 和 n 的集合,分別計算測試統計量,得到t1=μ1-μ2
假設零假設成立,重復上述抽樣多次,將全部測試統計量 t0,t1,t2,...排序形成抽樣分布,并計算 p 值p=x/perm,x 為 t1,t2,... 中大于 t0的次數,perm 為置換的次數
由于在樣本數量非常大的情況下,遍歷全部可能的組合,將限制計算速度,因此,算法將盡可能多地進行抽樣,以估計測試統計量的分布
根據零假設,測試統計量t1,t2,...,應該與t0接近,當 t0被判定為區別于t1,t2,...的異常值時,駁回零假設,即判斷數據發生漂移
在假設 x 符合二項分布的條件下,通過 [~,CI] = binofit(x,perm,0.05) 估計 p 值的 95% 置信區間
detectdrift 函數中,默認條件下,漂移閾值定義為 0.05,警告閾值定義為 0.1,當計算得到的置信區間上限小于漂移閾值時,判定漂移狀態出現
反之,當置信區間下限大于警告閾值時,判定狀態穩定,介于二者之間,則發出警告
結果分析
為了方便理解,我們可以使用 DriftDiagnostics 的方法函數 plotPermutationResults ,可視化指定特征的置換檢驗結果:
figure tiledlayout(3,1) nexttile % stable plotPermutationResults(DDiagnostics,Variable=DDiagnostics.VariableNames(5)) nexttile % warning plotPermutationResults(DDiagnostics,Variable=DDiagnostics.VariableNames(6)) nexttile % drift plotPermutationResults(DDiagnostics,Variable=DDiagnostics.VariableNames(7))
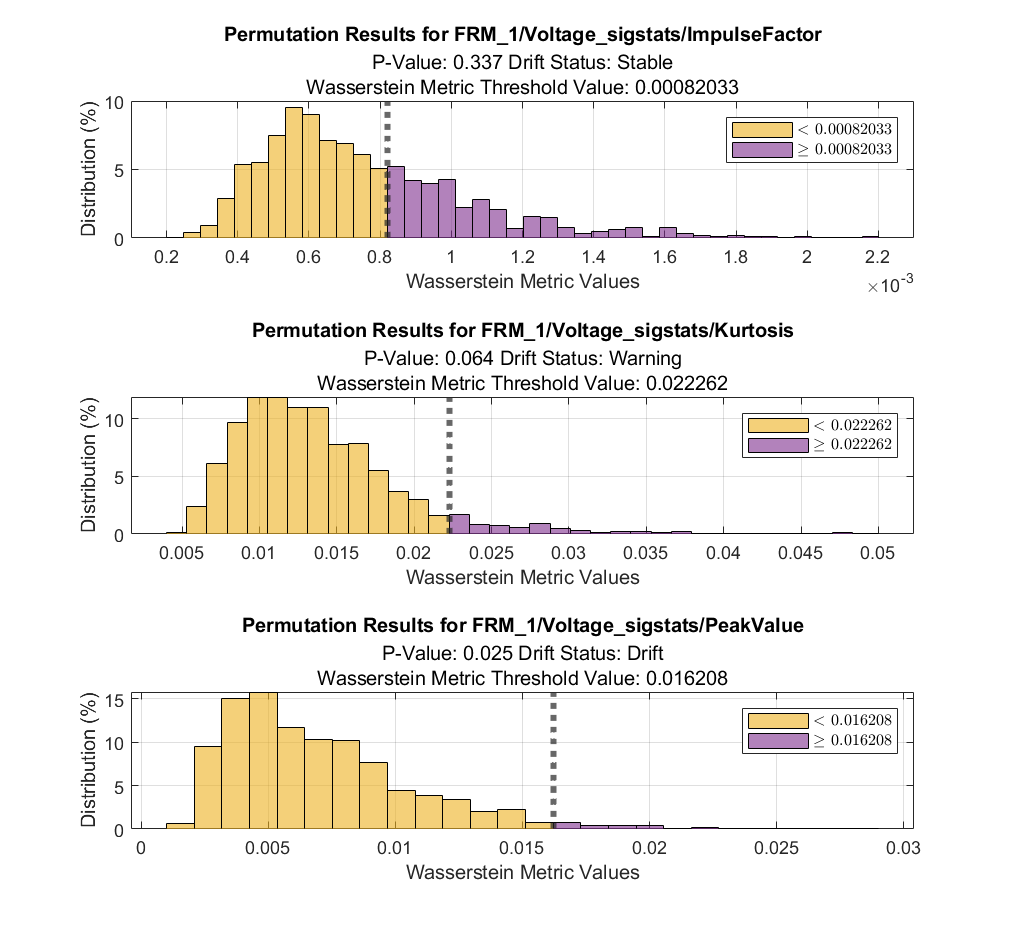
其中,灰色虛線代表使用原有的基準數據集和目標數據集計算得到的測試統計量,即,作為閾值,將置換組合后的測試統計量所形成抽樣分布劃分為兩部分,p 值代表大于閾值的部分占比。由以上直方圖,可以清晰看到原始測試統計量在置換組合的測試統計量抽樣分布中的位置。另外結合二項分布假設計算得到的置信區間,可以判定是否發生漂移。此外,plotHistogram,plotEmpiricalCDF 函數也可用于可視化輔助分析。
問題延申:基于流式數據的概念漂移檢測
如引例圖示,在實際生產環境中,通常需要采集流式數據,如何根據有限且分布未知的數據,監控數據或概念本身是否存在漂移,并對AI模型進行維護呢?一方面,可以結合增量學習方法,根據模型準確度在一定時間窗口內準確度的平均值和累積值,作為是否存在漂移問題的判定標準。另一方面,可以使用 incrementalConceptDriftDetector 對象定義漂移檢測模型,然后根據實時數據流更新檢測模型,并調用 detectdrift 函數檢測漂移。此外,如果將構建機器學習模型的過程和漂移檢測合二為一,可以通過 incrementalDriftAwareLearner 創建可感知概念漂移的分類或回歸模型,根據輸入數據和漂移狀態的變化,自動調整模型參數。
以下簡要介紹第三種方式的實現步驟:
1.初始化基礎增量學習模型,例如樸素貝葉斯分類模型:
BaseLearner = incrementalClassificationNaiveBayes(MaxNumClasses=2,Metrics="classiferror");
2.定義概念漂移檢測算法,并將基礎模型和檢測器作為參數,創建可感知漂移的增量學習模型:
dd = incrementalConceptDriftDetector("hddma");
idaMdl = incrementalDriftAwareLearner(BaseLearner,DriftDetector=dd,TrainingPeriod=5000);
3.根據輸入數據流 (XNew,YNew),先評估模型當前性能指標(updateMetrics),再調整模型參數:
idaMdl = updateMetricsAndFit(idaMdl,XNew,YNew);
classficationError{j,:} = idal.Metrics{"ClassificationError",:};
4.記錄數據用于可視化:
plot(classficationError.Variables)
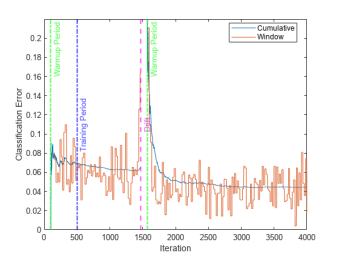
關于上述方法,可查看以下文檔鏈接了解更多:Construct drift-aware model for incremental learning[3]。
AI 模型在生產環境中使用時,需要進行持續性維護,以確保性能,本文介紹了常用的漂移檢測方法,在某些場景下,原模型維持不變,在出現推斷結果置信度不夠高時,例如,出現未知類別的樣本時,需要駁回模型推斷結果并預警,這類問題一般定義為分布外檢測。針對深度學習的分布外檢測問題,可安裝附加功能包Deep Learning Toolbox Verification Library[4],并查看相關文檔。
-
matlab
+關注
關注
188文章
2998瀏覽量
233260 -
AI
+關注
關注
87文章
34274瀏覽量
275453 -
人工智能
+關注
關注
1804文章
48726瀏覽量
246623 -
模型
+關注
關注
1文章
3488瀏覽量
50008
原文標題:AI 模型運維 - 淺談漂移檢測
文章出處:【微信號:MATLAB,微信公眾號:MATLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
防止AI大模型被黑客病毒入侵控制(原創)聆思大模型AI開發套件評測4
淺談電機模型
介紹在STM32cubeIDE上部署AI模型的系列教程
在X-CUBE-AI.7.1.0中導入由在線AI平臺生成的.h5模型報錯怎么解決?
AI視覺檢測在工業領域的應用
在AI愛克斯開發板上用OpenVINO?加速YOLOv8目標檢測模型

AI Transformer模型支持機器視覺對象檢測方案






 工商網監
工商網監
評論