") protobuf的編碼和存儲方式
protobuf的編碼和存儲方式
一、protobuf簡介:
1.1 protobuf的定義:
protobuf是用來干嘛的?
protobuf是一種用于 對結(jié)構(gòu)數(shù)據(jù)進行序列化的工具,從而實現(xiàn) 數(shù)據(jù)存儲和交換。
(主要用于網(wǎng)絡通信中 收發(fā)兩端進行消息交互。所謂的“結(jié)構(gòu)數(shù)據(jù)”是指類似于struct結(jié)構(gòu)體的數(shù)據(jù),可用于表示一個網(wǎng)絡消息。當結(jié)構(gòu)體中存在函數(shù)指針類型時,直接對其存儲或傳輸相當于是“淺拷貝”,而對其序列化后則是“深拷貝”。)
序列化:將結(jié)構(gòu)數(shù)據(jù)或者對象轉(zhuǎn)換成能夠用于存儲和傳輸?shù)母袷健?/p>
反序列化:在其他的計算環(huán)境中,將序列化后的數(shù)據(jù)還原為數(shù)據(jù)結(jié)構(gòu)和對象。
從“序列化”字面上的理解,似乎使用C語言中的struct結(jié)構(gòu)體就可以實現(xiàn)序列化的功能:將結(jié)構(gòu)數(shù)據(jù)填充到定義好的結(jié)構(gòu)體中的對應字段即可,接收方再對結(jié)構(gòu)體進行解析。
在單機的不同進程間通信時,使用struct結(jié)構(gòu)體這種方法實現(xiàn)“序列化”和“反序列化”的功能問題不大,但是,在網(wǎng)絡編程中,即面向網(wǎng)絡中不同主機間的通信時,則不能使用struct結(jié)構(gòu)體,原因在于:
(1)跨語言平臺,例如發(fā)送方是用C語言編寫的程序,接收方是用Java語言編寫的程序,不同語言的struct結(jié)構(gòu)體定義方式不同,不能直接解析;
(2)struct結(jié)構(gòu)體存在 內(nèi)存對齊 和 CPU不兼容的問題。
因此,在網(wǎng)絡編程中,實現(xiàn)“序列化”和“反序列化”功能需要使用通用的組件,如 Json、XML、protobuf 等。
1.2 protobuf的優(yōu)缺點:
1.2.1 優(yōu)點:
① 性能高效:
與XML相比,protobuf更小(3 ~ 10倍)、更快(20 ~ 100倍)、更為簡單。
② 語言無關、平臺無關:
protobuf支持Java、C++、Python等多種語言,支持多個平臺。
③ 擴展性、兼容性強:
只需要使用protobuf對結(jié)構(gòu)數(shù)據(jù)進行一次描述,即可從各種數(shù)據(jù)流中讀取結(jié)構(gòu)數(shù)據(jù),更新數(shù)據(jù)結(jié)構(gòu)時不會破壞原有的程序。
Protobuf與XML、Json的性能對比:
測試10萬次序列化:
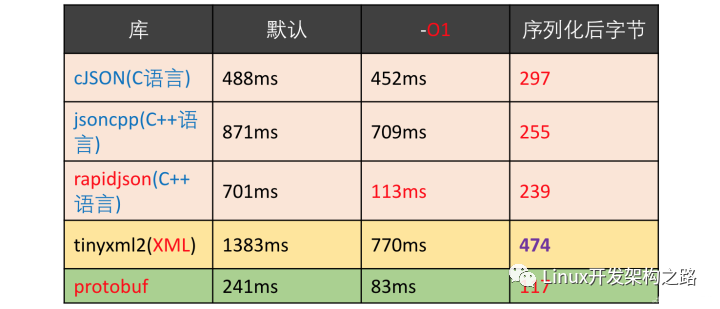
測試10萬次反序列化:

1.2.2 缺點:
① 自解釋性較差,數(shù)據(jù)存儲格式為二進制,需要通過 .proto 文件才能了解到內(nèi)部的數(shù)據(jù)結(jié)構(gòu);
② 不適合用來對 基于文本的標記文檔(如HTML) 建模。
1.3 protobuf中的數(shù)據(jù)類型限定修飾符:
protobuf 2 中有三種數(shù)據(jù)類型限定修飾符:
required表示字段必選,optional表示字段可選,repeated表示一個數(shù)組類型。
其中, required 和 optional 已在 proto3 棄用了。
1.4 protobuf中常用的數(shù)據(jù)類型:
double, 64位浮點數(shù)
float, 32位浮點數(shù)
int32, 32位整數(shù)
int64, 64位整數(shù)
uint64, 64位無符號整數(shù)
sint32, 32位整數(shù),處理負數(shù)效率更高
sint64, 64位整數(shù),處理負數(shù)效率更高
string, 只能處理ASCII字符
bytes, 用于處理多字節(jié)的語言字符
enum, 枚舉類型
二、protobuf的使用流程:
下載protobuf壓縮包后,解壓、配置、編譯、安裝,即可使用 protoc 命令 查看Linux中是否安裝成功:
libprotoc 3.15.8
使用protobuf時,需要先根據(jù)應用需求編寫 .proto 文件 定義消息體格式,例如:
package tutorial;
option optimize_for = LITE_RUNTIME;
message Person {
int32 id = 1;
repeated string name = 2;
}
其中,syntax 關鍵字表示使用的protobuf的版本,如不指定則默認使用 "proto2";package關鍵字 表示“包”,生成目標語言文件后對應C++中的namespace命名空間,用于防止不同的消息類型間的命名沖突。
(syntax單詞字面含義:句法,句法規(guī)則,語構(gòu))
然后使用 protobuf編譯器(protoc命令)將編寫好的 .proto 文件生成 目標語言文件(例如目標語言是C++,則會生成 .cc 和 .h 文件),例如:
其中:
**SRC_DIR 表示 .proto文件所在的源目錄;**DST_DIR 表示生成目標語言代碼的目標目錄;xxx.proto 表示要對哪個.proto文件進行解析;--cpp_out 表示生成C++代碼。
編譯完成后,將會在目標目錄中生成 xxx.pb.h 和 pb.cc, 文件,將其引入到我們的C++工程中即可實現(xiàn)使用protobuf進行序列化:
在C++源文件中包含 xxx.pb.h 頭文件,在g++編譯時鏈接 xxx.pb.cc源文件即可:
三、C++使用protobuf實現(xiàn)序列化的示例:
在protobuf源碼中的 /examples 目錄下有官方提供的protobuf使用示例:addressbook.proto
參考官方示例實現(xiàn)C++使用protobuf進行序列化和反序列化:
addressbook.proto :
package tutorial;
option optimize_for = LITE_RUNTIME;
message Person {
string name = 1;
int32 id = 2;
string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
string number = 1;
PhoneType type = 2;
}
repeated PhoneNumber phones = 4;
}
生成的addressbook.pb.h 文件內(nèi)容摘要:
class Person;
class Person_PhoneNumber;
};
class Person_PhoneNumber : public MessageLite {
public:
Person_PhoneNumber();
virtual ~Person_PhoneNumber();
public:
//string number = 1;
void clear_number();
const string& number() const;
void set_number(const string& value);
//int32 id = 2;
void clear_id();
int32 id() const;
void set_id(int32 value);
//string email = 3;
//...
};
add_person.cpp :
#include
#include
#include "pbs/addressbook.pb.h"
using namespace std;
void serialize_process() {
cout << "serialize_process" << endl;
tutorial::Person person;
person.set_name("Obama");
person.set_id(1234);
person.set_email("[email protected]");
tutorial::Person::PhoneNumber *phone1 = person.add_phones();
phone1->set_number("110");
phone1->set_type(tutorial::Person::MOBILE);
tutorial::Person::PhoneNumber *phone2 = person.add_phones();
phone2->set_number("119");
phone2->set_type(tutorial::Person::HOME);
fstream output("person_file", ios::out | ios::trunc | ios::binary);
if( !person.SerializeToOstream(&output) ) {
cout << "Fail to SerializeToOstream." << endl;
}
cout << "person.ByteSizeLong() : " << person.ByteSizLong() << endl;
}
void parse_process() {
cout << "parse_process" << endl;
tutorial::Person result;
fstream input("person_file", ios::in | ios::binary);
if(!result.ParseFromIstream(&input)) {
cout << "Fail to ParseFromIstream." << endl;
}
cout << result.name() << endl;
cout << result.id() << endl;
cout << Buy and Sell Domain Names() << endl;
for(int i = 0; i < result.phones_size(); ++i) {
const tutorial::Person::PhoneNumber &person_phone = result.phones(i);
switch(person_phone.type()) {
case tutorial::Person::MOBILE :
cout << "MOBILE phone : ";
break;
case tutorial::Person::HOME :
cout << "HOME phone : ";
break;
case tutorial::Person::WORK :
cout << "WORK phone : ";
break;
default:
cout << "phone type err." << endl;
}
cout << person_phone.number() << endl;
}
}
int main(int argc, char *argv[]) {
serialize_process();
parse_process();
google::protobuf::ShutdownProtobufLibrary(); //刪除所有已分配的內(nèi)存(Protobuf使用的堆內(nèi)存)
return 0;
}
輸出結(jié)果:
person.ByteSizeLong() : 39
[parse_process]
Obama
1234
[email protected]
MOBILE phone : 110
HOME phone : 119
3.1 protobuf提供的序列化和反序列化的API接口函數(shù):
public:
//序列化:
bool SerializeToOstream(ostream* output) const;
bool SerializeToArray(void *data, int size) const;
bool SerializeToString(string* output) const;
//反序列化:
bool ParseFromIstream(istream* input);
bool ParseFromArray(const void* data, int size);
bool ParseFromString(const string& data);
};
三種序列化的方法沒有本質(zhì)上的區(qū)別,只是序列化后輸出的格式不同,可以供不同的應用場景使用。
序列化的API函數(shù)均為const成員函數(shù),因為序列化不會改變類對象的內(nèi)容, 而是將序列化的結(jié)果保存到函數(shù)入?yún)⒅付ǖ牡刂分小?/p>
3.2 .proto文件中的 option 選項:
.proto文件中的option選項用于配置protobuf編譯后生成目標語言文件中的代碼量,可設置為 SPEED, CODE_SIZE, LITE_RUNTIME 三種。
默認option選項為 SPEED,常用的選項為 LITE_RUNTIME。
三者的區(qū)別在于:
① SPEED(默認值):表示生成的代碼運行效率高,但是由此生成的代碼編譯后會占用更多的空間。② CODE_SIZE:與SPEED恰恰相反,代碼運行效率較低,但是由此生成的代碼編譯后會占用更少的空間,
通常用于資源有限的平臺,如Mobile。③ LITE_RUNTIME:生成的代碼執(zhí)行效率高,同時生成代碼編譯后的所占用的空間也非常少。這是以犧牲Protobuf提供的反射功能為代價的。因此我們在C++中鏈接Protobuf庫時僅需鏈接libprotobuf-lite,而非protobuf。
SPEED 和 LITE_RUNTIME相比,在于調(diào)試級別上,例如 msg.SerializeToString(&str); 在 SPEED 模式下會利用反射機制打印出詳細字段和字段值,但是 LITE_RUNTIME 則僅僅打印字段值組成的字符串。
因此:可以在調(diào)試階段使用 SPEED 模式,而上線以后提升性能使用 LITE_RUNTIME 模式優(yōu)化。
最直觀的區(qū)別是使用三種不同的 option 選項時,編譯后產(chǎn)生的 .pb.h 中自定義的類所繼承的 protobuf類不同:
// .proto 文件:
option optimize_for = SPEED;
// .pb.h 文件:
class Person : public ::PROTOBUF_NAMESPACE_ID::Message {};
//2. CODE_SIZE模式:(自定義的類繼承自 Message 類)
// .proto 文件:
option optimize_for = CODE_SIZE;
// .pb.h 文件:
class Person : public ::PROTOBUF_NAMESPACE_ID::Message {};
//3. LITE_RUNTIME模式:(自定義的類繼承自 MessageLite 類)
// .proto 文件:
option optimize_for = LITE_RUNTIME;
// .pb.h 文件:
class Person : public ::PROTOBUF_NAMESPACE_ID::MessageLite {};
四、protobuf的編碼和存儲方式:
① protobuf 將消息里的每個字段進行編碼后,再利用TLV或者TV的方式進行數(shù)據(jù)存儲;
② protobuf 對于不同類型的數(shù)據(jù)會使用不同的編碼和存儲方式;
③ protobuf 的編碼和存儲方式是其性能優(yōu)越、數(shù)據(jù)體積小的原因。
-
存儲
+關注
關注
13文章
4498瀏覽量
87042 -
編碼
+關注
關注
6文章
966瀏覽量
55459 -
函數(shù)指針
+關注
關注
2文章
57瀏覽量
3928
發(fā)布評論請先 登錄
【LeMaker Guitar試用體驗】8.Lemuntu系統(tǒng)中編譯protobuf源代碼和簡單示例
存儲器的編碼方法
利用protobuf通信原理
什么是protobuf?怎么使用?
基于加密技術(shù)和編碼技術(shù)的存儲分割編碼技術(shù)
protobuf是什么?protobuf有什么作用支持什么數(shù)據(jù)類型?
深入剖析ProtoBuf原理與工程實踐
Intellij IDEA插件idea-plugin-protobuf






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論