") AXI的控制和數(shù)據(jù)通道分離
AXI的控制和數(shù)據(jù)通道分離

AXI的控制和數(shù)據(jù)通道分離,可以帶來很多好處。地址和控制信息相對數(shù)據(jù)的相位獨立,可以先發(fā)地址,然后再是數(shù)據(jù),這樣自然而然的支持顯著操作,也就是outstanding 操作。
Master訪問slave的時候,可以不等需要的操作完成,就發(fā)出下一個操作。這樣,可以讓slave在控制流的處理上流水起來,達到提速的作 用。
同時對于master,也許需要對不同的地址和slave就行訪問,所以可以對不同的slave 連續(xù)操作。而這樣的操作,由于slave返回數(shù)據(jù)的先后可能不按照master 發(fā)出控制的先后進行,導致出現(xiàn)了亂序操作(out of order )。
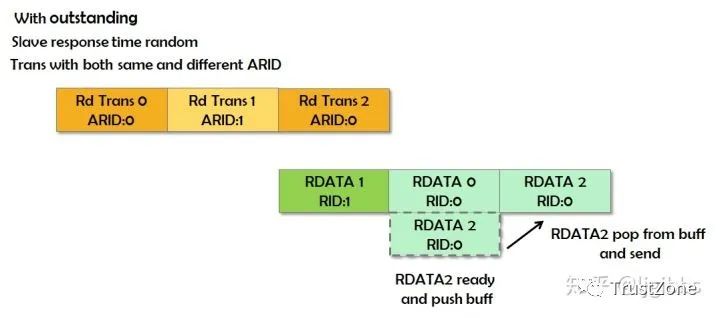
亂序傳輸需要依賴ARID來完成,亂序傳輸是針對transaction而言的,可以認為ARID是transaction的ID。
若支持亂序傳輸,當存在多個transaction時,從機可以不按照transaction的發(fā)起順序進行返回數(shù)據(jù),主機通過從機返回的BID(寫)或RID(讀)來判斷返回的數(shù)據(jù)屬于哪個transaction。
另外,擁有相同AWID與ARID的transaction,其返回數(shù)據(jù)需要按照transaction發(fā)起的順序進行返回數(shù)據(jù)。亂序傳輸?shù)臄?shù)據(jù)傳輸過程如下圖所示:
interleaving 交織
寫交織使用WID來實現(xiàn),interleaving用來實現(xiàn)不同transaction中的beat的交替?zhèn)鬏敚籺ransaction的beat是需要按照順序進行傳輸?shù)摹?/p>
AXI4中已經(jīng)取消了WID信號的使用,不再支持寫交織。interleaving的輸出傳輸過程如下:
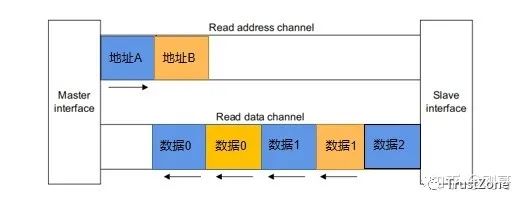
其中數(shù)據(jù)0與數(shù)據(jù)1屬于同一transaction的不同beat,地址A與地址B表示兩個transaction。
關于AXI4不支持寫交織是一個非常自然地過程。為了提高效率,AXI總線的寫數(shù)據(jù)通道并不依賴寫地址通道,這就是說,寫數(shù)據(jù)可以先于寫地址發(fā)送,但是總線不知道寫地址,沒辦法將數(shù)據(jù)發(fā)送出去,只能暫存在buffer中,等待寫地址。比較理想的方案是總線為每個master預留一個寫地址通道buffer和寫數(shù)據(jù)通道buffer。
在這種方案下,若支持寫交織,地址通道buffer和數(shù)據(jù)通道buffer的數(shù)據(jù)可能永遠都對不上(AWID與WID),這會造成該master的所有數(shù)據(jù)都被堵塞。當然可以采用其他方案來解決這個問題,比如說為每個master分配多個buffer,但實現(xiàn)起來會比較復雜。
合理地設計可以減少寫交織被取消帶來的影響,master應該在某個transaction的數(shù)據(jù)準備好之后再向總線發(fā)起寫請求,否則mater可能長時間占用總線,大大降低總線的效率。因此,設計人員本就應該避免寫交織十分高效時的場景,設計合理的情況下,寫交織的取消并不會給系統(tǒng)帶來明顯的效率影響。
-
數(shù)據(jù)
+關注
關注
8文章
7250瀏覽量
91539 -
總線
+關注
關注
10文章
2958瀏覽量
89534 -
通道
+關注
關注
0文章
60瀏覽量
20626 -
AXI
+關注
關注
1文章
136瀏覽量
17176
發(fā)布評論請先 登錄
NVMe協(xié)議簡介之AXI總線
玩轉Zynq連載3——AXI總線協(xié)議介紹1
AXI4協(xié)議的讀寫通道結構
AXI總線的相關資料下載
看看Axi4寫通道decoder的設計
AMBA AXI協(xié)議指南
AXI 總線和引腳的介紹
AXI4接口協(xié)議的基礎知識
AXI總線學習(AXI3&4)

關于AXI BRAM控制器的相關內容
AXI總線通道定義
ZYNQ基礎---AXI DMA使用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論