") 人工智能的生態(tài)樹及算力研究
人工智能的生態(tài)樹及算力研究
通用人工智能的生態(tài)樹如圖1所示,它龐大的樹根(算力)從大地中吸取營養(yǎng)(數(shù)據(jù)),形成茁壯的樹干(基座大模型),上面結(jié)滿了大蘋果(縱向應(yīng)用包括聊天機(jī)器人、智能操作系統(tǒng)、瀏覽器、第三方應(yīng)用插件、辦公套裝軟件、AI圖像、軟件開發(fā)、醫(yī)療、制藥、機(jī)器人等)。修剪刀剪去病枝爛果,修正樹勢,保證果實(shí)茁壯成長。
科技發(fā)展都是為了應(yīng)用。在AGI生態(tài)樹中,縱向應(yīng)用是結(jié)出的成千上萬的大蘋果。這些應(yīng)用幾乎無所不至,國內(nèi)外對此均有巨大的市場需求。技術(shù)、資金等進(jìn)入的門檻不是太高,而且收效快,眾多大中小企業(yè)、創(chuàng)業(yè)者都可參與,B端、C端均可分享。
樹壯才能碩果累累。基座大模型的算法當(dāng)前都不成問題,采用LLM(大語言模型)已成共識,國內(nèi)外基本所有的大模型都來源于2017年谷歌開源的Transformer模型。國外的大模型有微軟和OpenAI的GPT 4、谷歌的PaLM 2、亞馬遜的Titan大模型、Intel的Aurora genAI模型、Meta公司的LLaMA 模型,而國內(nèi)則是百度“文心一言”等的百模爭雄。近日,智源研究院發(fā)布了“悟道3.0”系列大模型及算法,這是目前我國市場上為數(shù)不多的可商用開源大語言模型之一。雖然“悟道3.0”的模型參數(shù)沒有公布,但2021年6月發(fā)布的“悟道2.0”模型參數(shù)規(guī)模達(dá)到1.75萬億,是當(dāng)時我國首個萬億級模型。而且,“悟道3.0”中的天演團(tuán)隊(duì)將“天演”接入我國新一代百億億次超級計(jì)算機(jī)——天河新一代超級計(jì)算機(jī)。通過“天演-天河”的成功運(yùn)行,實(shí)現(xiàn)鼠腦V1視皮層精細(xì)網(wǎng)絡(luò)等模型仿真,計(jì)算能耗均可降低約10倍以上,計(jì)算速度實(shí)現(xiàn)10倍以上提升,達(dá)到全球范圍內(nèi)最極致的精細(xì)神經(jīng)元網(wǎng)絡(luò)仿真性能。
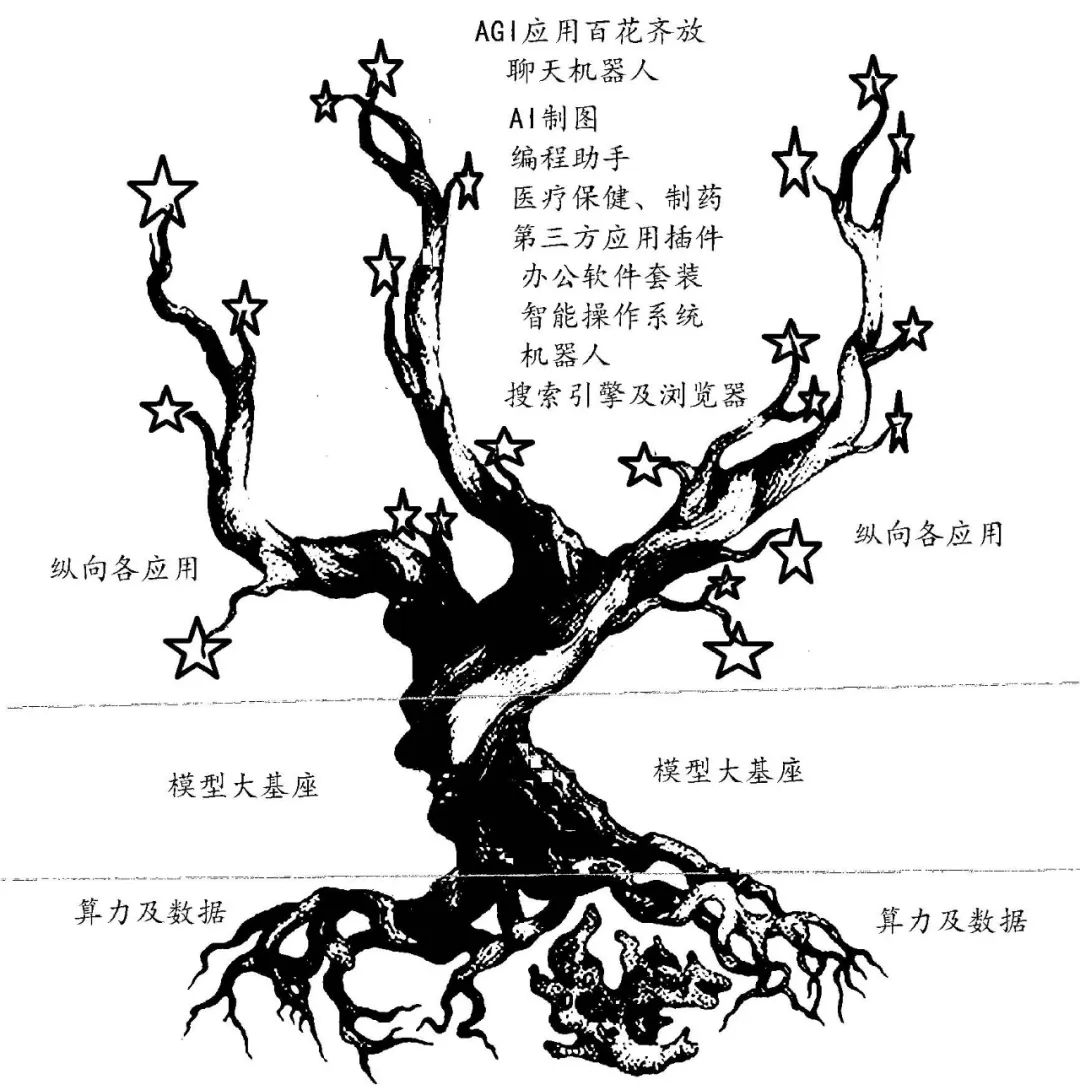
圖1 AGI強(qiáng)人工智能生態(tài)樹
數(shù)據(jù)是肥料,來源于人類的自然積累,位于人腦(經(jīng)驗(yàn))、書本(文字)、音像作品中。ChatGPT 的訓(xùn)練使用了來自于2021年9月前互聯(lián)網(wǎng)公開的文本數(shù)據(jù)(維基百科、書籍、期刊、Reddit社交新聞?wù)军c(diǎn)等),共45TB、近1萬億個單詞。但國內(nèi)AGI中公益數(shù)據(jù)不多,數(shù)據(jù)的版權(quán)分散在各個機(jī)構(gòu)、互聯(lián)網(wǎng)廠商的手中,若能建立中文數(shù)據(jù)集的產(chǎn)業(yè)聯(lián)盟,打破版權(quán)壁壘,將人工智能訓(xùn)練數(shù)據(jù)統(tǒng)一規(guī)劃,則必是好事一樁。
互聯(lián)網(wǎng)上的文本數(shù)據(jù)有限,且有很多虛假、違反法律/道德和意識形態(tài)以及侵犯隱私的信息。下一代大模型的參數(shù)可能達(dá)到萬億級別以上,為了避免數(shù)據(jù)短缺問題成為訓(xùn)練的瓶頸,人們推出了“合成數(shù)據(jù)”。合成數(shù)據(jù)(syntheticdata)是通過計(jì)算機(jī)技術(shù)人工生成的數(shù)據(jù),雖然不是由真實(shí)事件產(chǎn)生的數(shù)據(jù),但能夠在數(shù)學(xué)上或統(tǒng)計(jì)學(xué)上反映原始數(shù)據(jù)的屬性,因此可以作為原始數(shù)據(jù)的替代品來訓(xùn)練、測試并驗(yàn)證大模型。合成數(shù)據(jù)具有更高的效率(較短的時間內(nèi)大量生成)、更低的成本、更高的質(zhì)量(通過深度學(xué)習(xí)算法合成原始數(shù)據(jù)中沒有的罕見樣本,規(guī)避用戶隱私問題)。據(jù)稱,到2024年,人工智能和數(shù)據(jù)分析項(xiàng)目中的數(shù)據(jù)預(yù)計(jì)將有60%來自合成數(shù)據(jù)。
對人工智能的監(jiān)管(法律、道德、倫理)就是對果樹的修剪。為了促進(jìn)生成式人工智能技術(shù)健康發(fā)展和規(guī)范應(yīng)用,國家網(wǎng)信辦在2023年4月11日發(fā)布了關(guān)于《生成式人工智能服務(wù)管理辦法(征求意見稿)》。2023年2月16日,中美等60多國簽署聲明“軍事領(lǐng)域負(fù)責(zé)任使用人工智能”。5月22日,OpenAI的創(chuàng)始人奧特曼、總裁和首席科學(xué)家聯(lián)合撰文稱:“我們最終可能需要類似于IAEA(國際原子能機(jī)構(gòu))的東西來進(jìn)行超級智能方面的努力;任何超過一定能力(計(jì)算等資源)門檻的努力都需要接受國際權(quán)威機(jī)構(gòu)的檢查,要求進(jìn)行審計(jì),測試是否符合安全標(biāo)準(zhǔn),對部署程度和安全級別進(jìn)行限制等。”
龐大的根系是果樹生長結(jié)果的根本。算力作為根系,一直都是掣肘人工智能發(fā)展的基石。
在人工智能(AI)研究過程中,有兩種流派:一種流派是嚴(yán)格的邏輯推理,另一種流派是研究模擬生物學(xué)的人類及大腦。后者在20世紀(jì)80年代推出了神經(jīng)網(wǎng)絡(luò)學(xué)說,把人腦看成是一臺碳基計(jì)算機(jī),用我們的硅基計(jì)算機(jī)來模擬生物的進(jìn)化。隨著神經(jīng)網(wǎng)絡(luò)模型不斷變大,神經(jīng)元不斷增多,不知在突破某個值后是否會發(fā)生突變,變得更為智能。有專家按照現(xiàn)代神經(jīng)網(wǎng)絡(luò)的架構(gòu)分析人類神經(jīng)網(wǎng)絡(luò)參數(shù)最少為100萬億(100~1000萬億),僅同時激活10%,其算力最少需0.79 EFLOPS,功耗僅幾十瓦。計(jì)算機(jī)所需要的數(shù)據(jù)空間大概為400~4 000 TB。
神經(jīng)網(wǎng)絡(luò)學(xué)派推出了循環(huán)卷積等各種算法,但在20世紀(jì)沒有真正奏效的重要原因是當(dāng)時計(jì)算機(jī)運(yùn)行速度不夠快、數(shù)據(jù)集不夠大。隨著“神經(jīng)元”的膨脹,大模型(LLM)計(jì)算復(fù)雜度以指數(shù)級增加,當(dāng)時計(jì)算機(jī)有限的內(nèi)存和處理速度不足以解決任何實(shí)際的AI問題,而每次算力的突破都帶來人工智能的爆發(fā)。IBM 研制的深藍(lán)(算力為11.38 GFLOPS )、谷歌的AlphaGo(算力是深藍(lán)的30萬倍)帶動了深度學(xué)習(xí)的大發(fā)展,而這次NVIDIA的A100、H100及CUDA則助推了GPT生成式大模型的問世。
人類通常不斷有各種科學(xué)幻想和預(yù)言(期待的成果),而一些優(yōu)秀的科學(xué)家為實(shí)現(xiàn)這些幻想和預(yù)言研究出各種理論(牛頓的力學(xué)及萬有引力、霍金的黑洞及宇宙起源、愛因斯坦的相對論等)。理論往往都超前于當(dāng)時的科技水平,超前于算法,算法則要求有算力做支撐。有分析認(rèn)為,當(dāng)前的AGI算力和能耗都遠(yuǎn)比不上人腦的碳基計(jì)算機(jī)!當(dāng)下,千億級、萬億級參數(shù)的生成式大模型比人腦百萬億級參數(shù)還差很多,但能耗卻高得可怕。2023年4月,OpenAI就因需求量過大而停止了ChatGPT Plus的銷售。據(jù)數(shù)據(jù)預(yù)測,到2030年全球超算算力將達(dá)到0.2 ZFLOPS,平均年增速超過34%,未來10年人工智能算力需求將會增長500倍以上。為此,除NVIDIA外,幾乎所有的芯片大廠都在布局AI算力芯片。
AMD近期就推出一款新一代超級AI芯片———將CPU 和GPU 融合在一起的MI300X。該芯片是針對LLM 的優(yōu)化版,擁有192 GB的HBM 內(nèi)存,與NVIDIAH100相比,有2.4倍的HBM 密度和1.6倍的HBM 帶寬優(yōu)勢,這可以在芯片上容納更大的模型,以獲得更高的吞吐量。單個MI300X可以運(yùn)行一個參數(shù)多達(dá)800億的模型,這是全球首次在單個GPU 上運(yùn)行這么大參數(shù)量的模型。這表明在無人駕駛L5等應(yīng)用項(xiàng)目中需要強(qiáng)大邊緣計(jì)算算力的地方,MI300X將大放異彩。
1 提高算力的路徑
(1) 提高制程及Chiplet
根據(jù)摩爾定律,集成電路上可以容納的晶體管數(shù)目大約每經(jīng)過18個月便會增加一倍,因此微處理器的性能每隔18個月提高一倍,價格下降一半。而光刻“制程”的進(jìn)步是每18個月單位面積硅片上可容納的晶體管數(shù)目翻倍的主要原因。經(jīng)歷了二十多年的正增長后,新世紀(jì)摩爾生長曲線在變緩,尤其是近年來芯片“制程”的提升越來越難,從16 nm 到7 nm 節(jié)點(diǎn),芯片制造成本也在大幅提升,出現(xiàn)“摩爾定律失效”的議論。在將芯片制程繼續(xù)從7 nm降至5nm、3 nm、2 nm 的同時,芯片業(yè)也在從各方面應(yīng)對AGI算力提升和功耗降低面臨的挑戰(zhàn)。
Chiplet是一種芯片設(shè)計(jì)和集成的方法,它將一個大型AI芯片分解為多核異構(gòu)、多個獨(dú)立的功能模塊片段(稱為IP核或Chiplet)。每個Chiplet指已經(jīng)過驗(yàn)證的、可以重復(fù)使用的具有某種確切功能的集成電路設(shè)計(jì)模塊,如圖形處理器(GPU)IP、神經(jīng)網(wǎng)絡(luò)處理器(NPU)IP、視頻處理器(VPU)IP、數(shù)字信號處理器(DSP)IP等。Chiplet設(shè)計(jì)可以使芯片設(shè)計(jì)更加模塊化,具有更強(qiáng)的靈活性。不同的芯片片段可以獨(dú)立設(shè)計(jì)和優(yōu)化,然后通過集成技術(shù)組合成一個完整的芯片。這種模塊化的設(shè)計(jì)使芯片開發(fā)更加容易,而且每個芯片片段可以在獨(dú)立的制造工藝下生產(chǎn),而不是整個芯片都使用同一種復(fù)雜的制造工藝,這樣可以降低制造成本,提高芯片的產(chǎn)量和良品率。
當(dāng)前計(jì)算機(jī)均為馮·諾依曼架構(gòu),計(jì)算單元和存儲單元分離,存儲帶寬制約了計(jì)算系統(tǒng)的有效帶寬,造成時延長、功耗高等問題。采用多維集成芯片將多個芯片堆疊在一起,使存儲與計(jì)算完全融合,以新的高效運(yùn)算架構(gòu)進(jìn)行二維和三維矩陣計(jì)算,具有更大算力(1000 TFLOPS以上)、更高能效(超過10~100 TFLOPS/W)、降本增效三大優(yōu)勢,有效克服了馮·諾依曼架構(gòu)瓶頸,實(shí)現(xiàn)計(jì)算能效的數(shù)量級提升。
AMD近期推出的MI300X就采用了3D堆疊技術(shù)和Chiplet設(shè)計(jì),配備了9個基于5 nm 制程的芯片組,置于4個基于6nm 制程的芯片組之上。
(2) CPU到GPU、TPU、NPU和多核異構(gòu)
最初的處理器是CPU,采用馮·諾依曼架構(gòu),存儲程序,順序執(zhí)行。在圖2(a)CPU 架構(gòu)圖中,負(fù)責(zé)計(jì)算的ALU 區(qū)占的面積太小,而Cache和Control單元占據(jù)了大量空間。為提升算力,出現(xiàn)了多線程的流水線作業(yè),繼而出現(xiàn)新結(jié)構(gòu)的各類處理器。
GPU(圖形處理器)。在圖像處理中,每個像素點(diǎn)都需要處理,而且處理的過程和方式十分相似,都需要相同的精度、不高的運(yùn)算,為此推出了GPU(Graphics Processing Unit)。GPU 架構(gòu)示意圖如圖2(b)所示,它有數(shù)量眾多的計(jì)算單元和超長的流水線,特別適合處理大量的類型統(tǒng)一的數(shù)據(jù)。它將求解的問題分解成若干子任務(wù),各子任務(wù)并行計(jì)算。雖然GPU 為了圖像處理而生,但它在結(jié)構(gòu)上并沒有專門為圖像服務(wù)的部件,只是對CPU的結(jié)構(gòu)進(jìn)行了優(yōu)化與調(diào)整,所以GPU不僅可以在圖像處理領(lǐng)域大顯身手,還被用來進(jìn)行科學(xué)計(jì)算、密碼破解、數(shù)值分析、海量AGI數(shù)據(jù)處理。
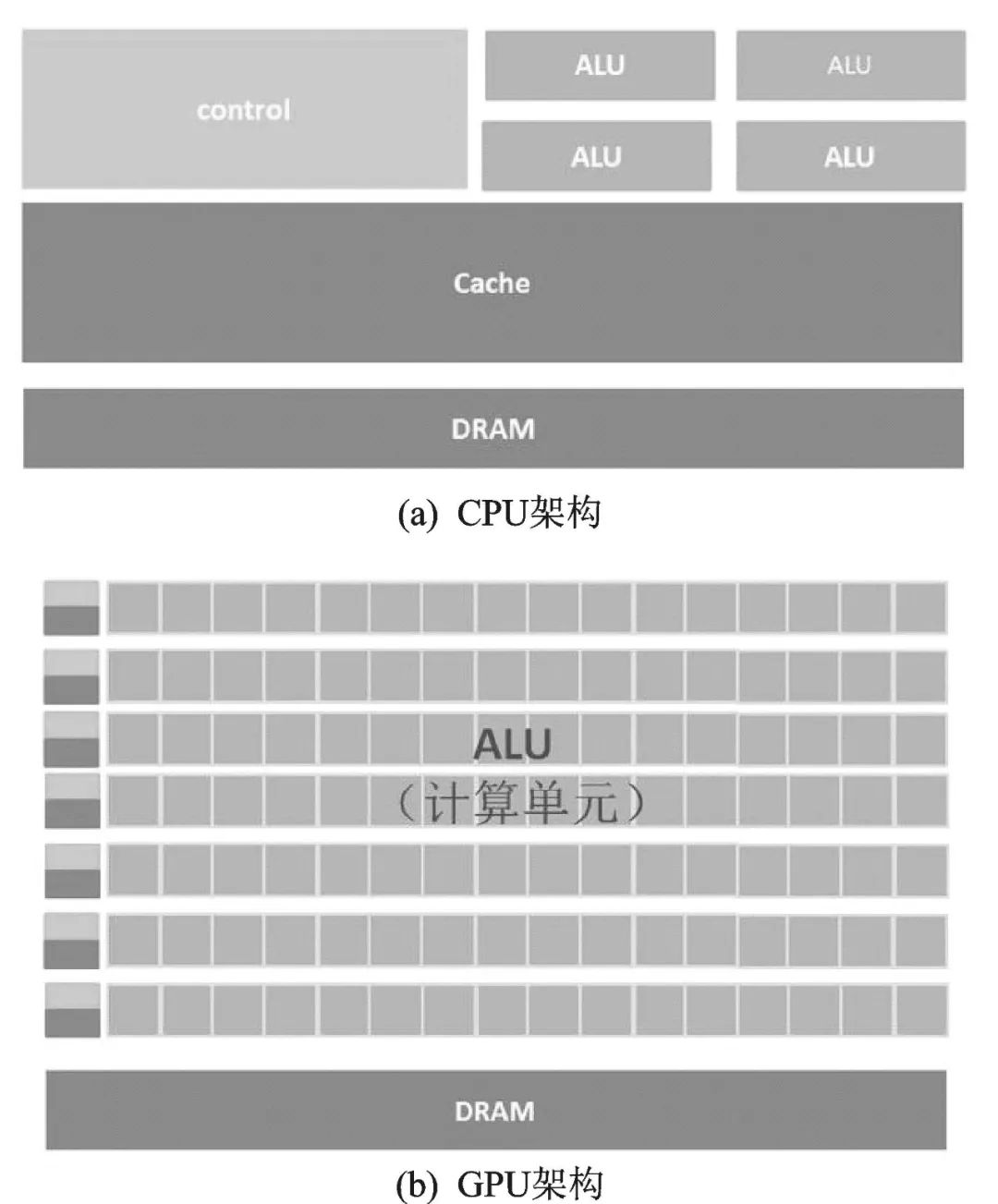
圖2 CPU及GPU的架構(gòu)圖
TPU(Tensor Processing Unit)即張量處理器。張量是機(jī)器學(xué)習(xí)中常見的多維數(shù)組結(jié)構(gòu),谷歌就專門為此開發(fā)了一款TPU 芯片。TPU 專注于高效地執(zhí)行大規(guī)模張量計(jì)算,具有高帶寬和低延遲的內(nèi)存訪問以及快速的張量操作指令,用于進(jìn)行機(jī)器學(xué)習(xí)和人工智能任務(wù)中的張量計(jì)算,提供高效、快速且能耗低的計(jì)算性能。據(jù)稱,TPU有高性能和能耗效率,與同期的CPU 和GPU 相比,可以提供15~30倍的性能提升,以及30~80倍的效率(性能/瓦特)提升。2021年谷歌發(fā)布的第四代TPUv4,每個芯片擁有2.5 PFLOPS的算力。
NPU(Neural Network Processing Unit)是用電路模仿人類的神經(jīng)元,深度學(xué)習(xí)的基本操作是神經(jīng)網(wǎng)絡(luò)中神經(jīng)元和突觸的處理,其中存儲和處理是一體化的。NPU通常不單獨(dú)存在,而是存在于多核異構(gòu)的處理器中。典型代表有國內(nèi)的寒武紀(jì)芯片和IBM 的TrueNorth。Dian-NaoYu指令直接面對大規(guī)模神經(jīng)元和突觸的處理,一條指令即可完成一組神經(jīng)元的處理,并對神經(jīng)元和突觸數(shù)據(jù)在芯片上的傳輸提供了一系列專門的支持。
(3) 人工智能專用計(jì)算機(jī)
芯片能力直接影響算力訓(xùn)練效果和速度,當(dāng)前最好的AI芯片是NVIDIA的A100和H100,其最高浮點(diǎn)算力分別實(shí)現(xiàn)19.5 TFLOPS和67 TFLOPS,但AGI所需算力和單個處理器所有的算力差距太大,當(dāng)前的AGI大模型的計(jì)算都需要成千上萬個GPU 堆疊起來應(yīng)用。業(yè)內(nèi)公認(rèn),做好AI大模型的算力門檻是1萬枚A100芯片,GPT3.5大模型需要2萬塊A100來處理訓(xùn)練數(shù)據(jù)。近期,谷歌推出了擁有26 000片H100的超級AGI計(jì)算機(jī)A3。
這樣大量GPU 堆起來使用就需要采用專門針對深度學(xué)習(xí)和神經(jīng)網(wǎng)絡(luò)的互聯(lián)硬件、架構(gòu)和軟件工具包,從而實(shí)現(xiàn)更高的計(jì)算速度和更低的功耗。通過優(yōu)化和協(xié)調(diào)來協(xié)同作用,再去組合模擬優(yōu)化的路徑。NVIDIA在2006年發(fā)布了一個名為CUDA(ComputeUnified Device Architecture)的軟件工具包。他們搭建的CUDA 開發(fā)者平臺以良好的易用性和通用性讓GPU 可以用于通用超級計(jì)算,使用CUDA和不使用CUDA,兩者在計(jì)算速度上往往有數(shù)倍到數(shù)十倍的差距。26000塊H100D的A3超極計(jì)算機(jī)單獨(dú)疊起用的算力是26 000×67 TFLOPS=1.724 EFLOPS,而采用CUDA后可提供高達(dá)26 FLOPS的算力。Meta的超級計(jì)算機(jī)RSC(Research Super Cluster) 花費(fèi)了數(shù)十億美元,配備了由 16000 個 NVIDIA A100 GPU 組裝成的2 000個 NVIDIA DGX A100 系統(tǒng)(8個A100+CUDA),集聯(lián)起來,在其巔峰時期算力可以達(dá)到近 5 EFLOPS,所以A100、H100、CUDA 三者確定了NVIDIA成為當(dāng)前全球AGI算力霸主的地位。
在谷歌的數(shù)據(jù)中心中,大規(guī)模的TPU 芯片則是通過光開關(guān)互連網(wǎng)絡(luò)連接在一起的。光開關(guān)是一種高帶寬、低延遲的互連技術(shù),它使用光纖作為傳輸介質(zhì),實(shí)現(xiàn)快速的數(shù)據(jù)傳輸和通信。通過光開關(guān),TPU 芯片之間可以進(jìn)行高速、并行的通信,以實(shí)現(xiàn)大規(guī)模的并行計(jì)算。這種互連方式能夠提供低延遲和高帶寬的通信性能,確保在分布式計(jì)算環(huán)境中各個TPU 芯片能夠有效地協(xié)同工作,共同完成復(fù)雜的機(jī)器學(xué)習(xí)任務(wù)。谷歌的光開關(guān)互連網(wǎng)絡(luò)架構(gòu)為其算力集群提供了高效的通信基礎(chǔ)設(shè)施,使得TPU能夠?qū)崿F(xiàn)高性能、大規(guī)模的機(jī)器學(xué)習(xí)計(jì)算。這種光開關(guān)連接的設(shè)計(jì)能夠支持谷歌處理海量數(shù)據(jù)和進(jìn)行復(fù)雜計(jì)算,提供出色的計(jì)算能力和可擴(kuò)展性。
(4) 下一代計(jì)算機(jī)
當(dāng)前,硅基計(jì)算機(jī)的摩爾定律似乎快走到盡頭,于是人們寄希望于“類人腦生物計(jì)算機(jī)”的非硅基計(jì)算機(jī)。未來的計(jì)算機(jī)可能會采用一種或多種可能的技術(shù)和架構(gòu)技術(shù)提高算力計(jì)算性能和效率。
① 量子計(jì)算機(jī):量子計(jì)算機(jī)利用量子力學(xué)原理來執(zhí)行計(jì)算。這種計(jì)算機(jī)可以大大提高處理大量數(shù)據(jù)和解決復(fù)雜問題的速度(例如加密和化學(xué)模擬)。近期量子計(jì)算機(jī)好消息不斷:在國際超算大會(ISC)上,NVIDIA公布了一個搭載384 顆Grace CPU 超級芯片的超級計(jì)算機(jī)Isambard 3。這臺超級計(jì)算機(jī)FP64峰值性能達(dá)到約2.7petaFLOPS,功耗低于270 kW。當(dāng)前全球大量的量子計(jì)算研究都在NVIDIA GPU 上運(yùn)行。歐洲量子計(jì)算設(shè)施于利希超算中心(JSC)計(jì)劃與NVIDIA 共同建立一座量子計(jì)算實(shí)驗(yàn)室。在NVIDIA 量子計(jì)算平臺的基礎(chǔ)上開發(fā)一臺量子超級計(jì)算機(jī),作為于利希量子計(jì)算用戶基礎(chǔ)設(shè)施(JUNIQ)的一部分,運(yùn)行高性能、低延遲的量子-經(jīng)典計(jì)算工作負(fù)載。近期,IBM 科學(xué)家在《自然》雜志上發(fā)表了論文《容錯前的量子計(jì)算實(shí)用性證據(jù)》。容錯量子計(jì)算指的是有量子糾錯保護(hù)的量子計(jì)算。IBM 科學(xué)家宣布,已經(jīng)設(shè)計(jì)出一種方法來管理量子計(jì)算的不可靠性,從而得出可靠、有用的答案。英特爾公布了名為Tunnel Falls的硅自旋量子芯片,它擁有12個硅自旋量子比特,是英特爾迄今為止研發(fā)的最先進(jìn)的硅自旋量子比特芯片。
② 光子計(jì)算機(jī):光子計(jì)算機(jī)使用光子而不是傳統(tǒng)的電子來執(zhí)行計(jì)算,這種計(jì)算機(jī)可以實(shí)現(xiàn)更高的速度和更低的功耗,并且更容易進(jìn)行并行計(jì)算。
③ DNA計(jì)算機(jī):DNA計(jì)算機(jī)使用DNA分子來執(zhí)行計(jì)算,這種計(jì)算機(jī)可以處理大量數(shù)據(jù),并且具有很好的并行性。
2 合作共贏
算力是AGI的決定性的基礎(chǔ)建設(shè),是AGI金字塔的底座,需要人力和資金的巨大投入。ChatGPT全面放開導(dǎo)致用戶激增、算力不足。除大量購入GPU 外,近期又和甲骨文(Oracle)討論了一項(xiàng)協(xié)議,如果任何一家公司為使用大規(guī)模AI的云客戶所提供的計(jì)算能力不足,那么雙方就將相互租用對方服務(wù)器。
而日本經(jīng)產(chǎn)省2022年11月牽頭組建了“技術(shù)研究組合最先端半導(dǎo)體技術(shù)中心(LSTC)”,隨后,豐田汽車、索尼、NTT、NEC、軟銀等8家大型公司成立合資企業(yè)Rapidus公司,計(jì)劃最早2025年在日量產(chǎn)2 nm芯片,希望2025到2030年的幾年中為其他企業(yè)提供代工服務(wù)。
國內(nèi)重心放在了大模型上,近3年大模型發(fā)布數(shù)量為世界之首(達(dá)79個),已超過美國,但實(shí)際上國內(nèi)AGI的短板在于算力,國內(nèi)AGI都受制于算力,僅面向B端用戶或內(nèi)測,其使用效果、影響力、評價有目共賭。正如百度CEO李彥宏所說:“文心一言跟ChatGPT 的差距大約是兩個月,這兩個月的差距我們要用多長時間才能趕上,也許很快,也許永遠(yuǎn)也趕不上。”
面對芯片封控,算力是買不來的,也不是幾年時間可以一蹴而就的,也不是短期能解決的。在面對封鎖的重大問題上(如兩彈一星、北斗、航天等),國家都采用舉國體制,趕上了世界先進(jìn)水平。AGI重要性不遜于核能,其核心算力牽涉到國民經(jīng)濟(jì)的各個方面,需要在國家層面上,組織大廠合作共贏。當(dāng)前國內(nèi)百模競爭只會分散人力、財(cái)力,從而拉大差距。
-
半導(dǎo)體技術(shù)
+關(guān)注
關(guān)注
3文章
241瀏覽量
61178 -
人工智能
+關(guān)注
關(guān)注
1804文章
48726瀏覽量
246628 -
語言模型
+關(guān)注
關(guān)注
0文章
558瀏覽量
10681
原文標(biāo)題:人工智能的生態(tài)樹及算力研究
文章出處:【微信號:麥克泰技術(shù),微信公眾號:麥克泰技術(shù)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
大算力芯片的生態(tài)突圍與算力革命
軟通智算入選廣州智算聯(lián)盟首批“人工智能+”典型案例
Deepseek引發(fā)算力變革 《2025中國人工智能計(jì)算力發(fā)展評估報(bào)告》發(fā)布

算智算中心的算力如何衡量?

浪潮信息與智源研究院攜手共建大模型多元算力生態(tài)
算家計(jì)算 開啟貴州人工智能算力服務(wù)新篇章






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論