") 英偉達(dá)江郎才盡,下一代芯片架構(gòu)變化只是封裝
英偉達(dá)江郎才盡,下一代芯片架構(gòu)變化只是封裝
2023年8月23日,英偉達(dá)宣布下一代汽車芯片Thor量產(chǎn)時間略有推遲,正式量產(chǎn)在2026財年,英偉達(dá)的財政年度與自然年相差11個月,也就是說正式量產(chǎn)最遲可能是2026年1月。
FY2019-FY2024H1英偉達(dá)自動駕駛及AI座艙業(yè)績情況
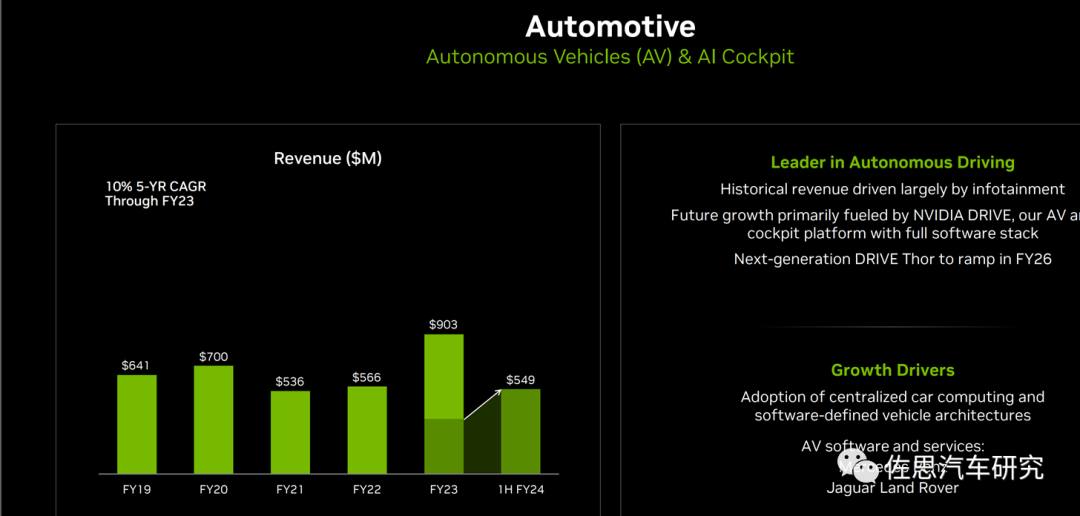
圖片來源:英偉達(dá)
英偉達(dá)通常兩年升級一次芯片架構(gòu)。在2022年英偉達(dá)透露即將在2024年推出Blackwell架構(gòu),而Thor也會采用Blackwell架構(gòu)。
Blackwell是致敬美國統(tǒng)計學(xué)家,加利福尼亞大學(xué)伯克利分校統(tǒng)計學(xué)名譽教授,拉奧-布萊克韋爾定理的提出者之一David Harold Blackwell。
英偉達(dá)Blackwell架構(gòu)
Blackwell架構(gòu)將采用COPA-GPU設(shè)計。很多人認(rèn)為COPA-GPU就是Chiplet,不過COPA-GPU不是嚴(yán)格意義上的Chiplet,眾所周知,英偉達(dá)一直對Chiplet缺乏興趣。在2017年英偉達(dá)曾提出非常近似Chiplet的MCM設(shè)計,但在2021年12月,英偉達(dá)發(fā)表了一篇名為《GPU Domain Specialization via Composable On-Package Architecture》的論文,應(yīng)該就是Blackwell架構(gòu)的論文,這篇論文則否定了Chiplet設(shè)計。
2017年6月英偉達(dá)發(fā)表論文《MCM-GPU: Multi-Chip-Module GPUs for Continued Performance Scalability》提出了MCM設(shè)計。
MCM-GPU設(shè)計
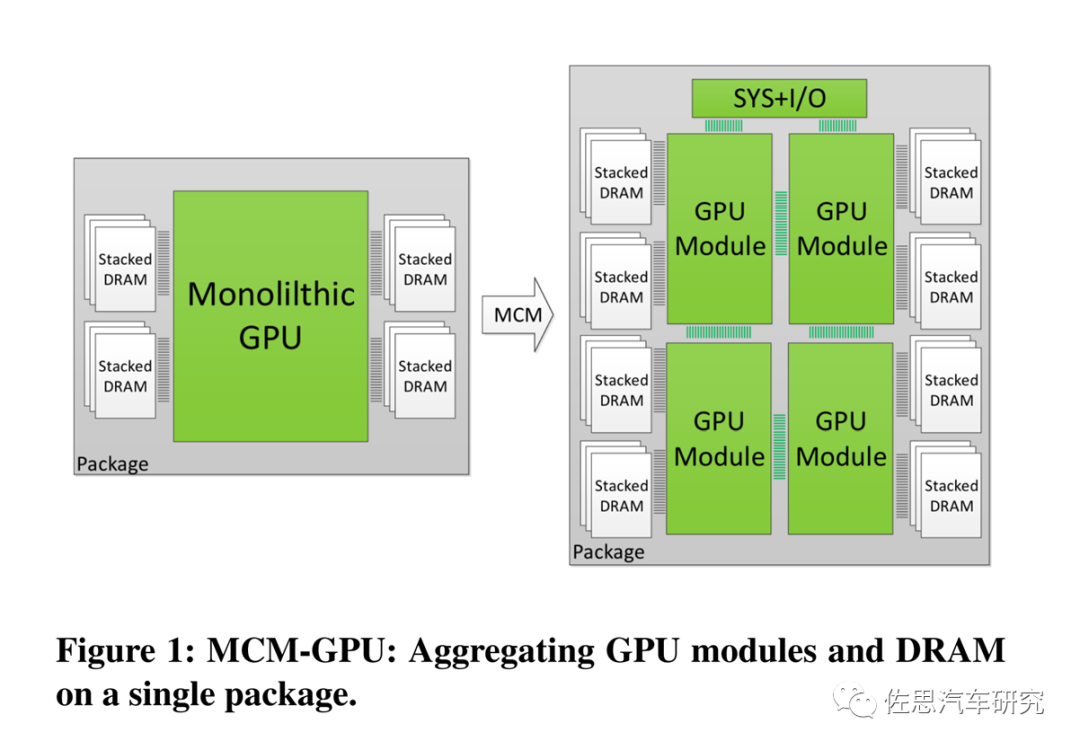
圖片來源:英偉達(dá)
MCM-GPU設(shè)計基本就是現(xiàn)在比較火爆的Chiplet設(shè)計,但英偉達(dá)一直未將MCM付諸實際設(shè)計中。英偉達(dá)一直堅持Monolithic單一光刻設(shè)計,這是因為die與die之間通訊帶寬永遠(yuǎn)無法和monolithic內(nèi)部的通訊帶寬相比,換句話說Chiplet不適合高AI算力場合,在純CPU領(lǐng)域是Chiplet的最佳應(yīng)用領(lǐng)域。
MCM-GPU架構(gòu)
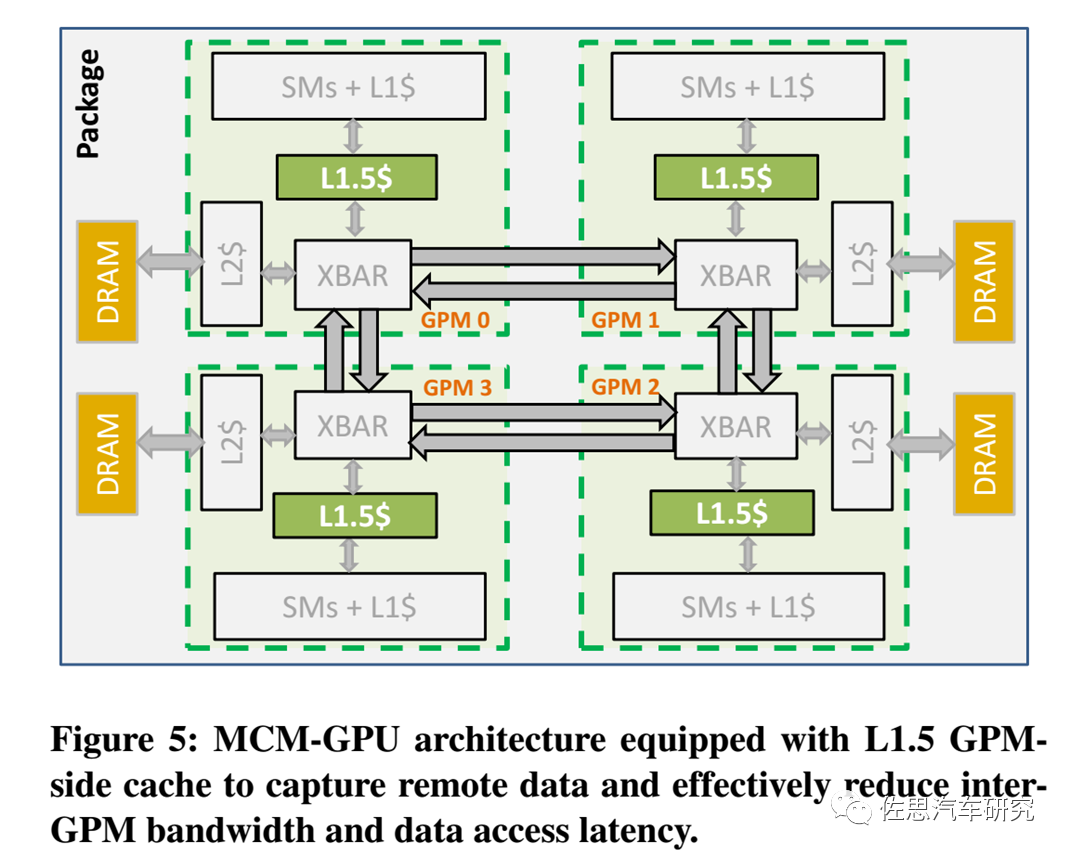
圖片來源:英偉達(dá)
英偉達(dá)2017年論文提及的MCM-GPU架構(gòu)如上圖。英偉達(dá)在MCM-GPU架構(gòu)里主要引入了L1.5緩存,它介于L1緩存和L2緩存之間,XBAR是Crossbar,英偉達(dá)的解釋是The Crossbar (XBAR) is responsible for carrying packets from a given source unit to a specific destination unit,有點像交換或路由。GPM就是GPU模塊。
不同容量L1.5緩存下各種應(yīng)用的速度對比
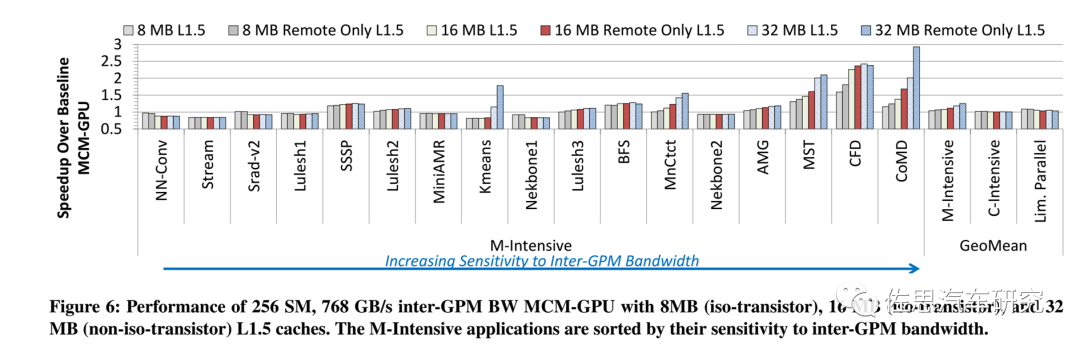
圖片來源:英偉達(dá)
上圖是英偉達(dá)2017年論文仿真不同容量L1.5緩存下各種應(yīng)用的速度對比,不過彼時各種應(yīng)用還是各種浮點數(shù)學(xué)運算和存儲密集型算子,而非深度學(xué)習(xí)。
Transformer時代相對CNN時代,存儲密集型算子所占比例大幅增加。
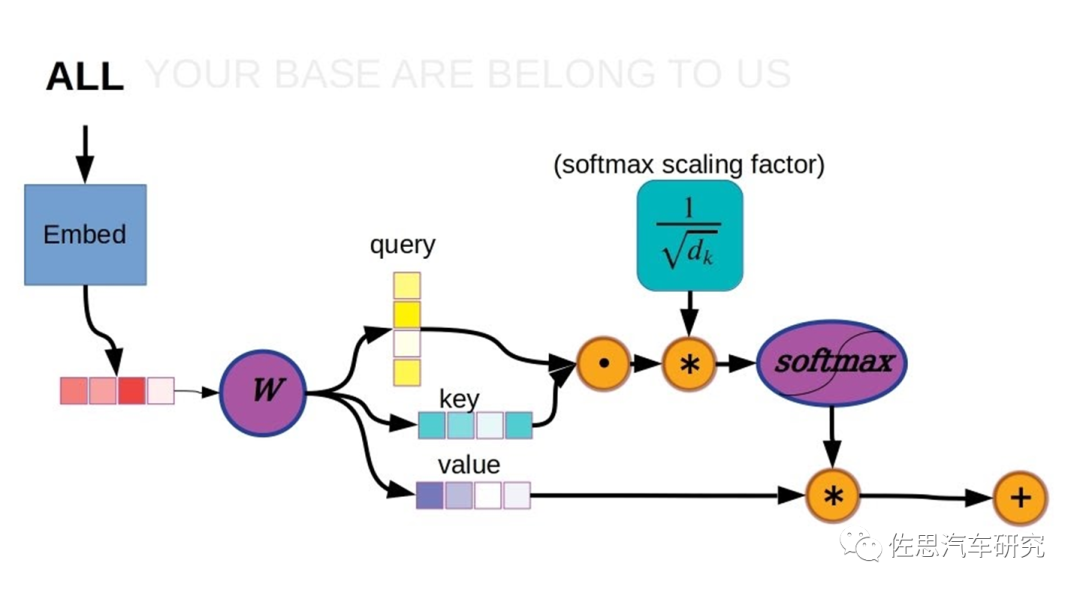
以上是Transformer的計算過程,在此計算過程中,矩陣乘法是典型的計算密集型算子,也叫GEMM(通用矩陣乘法)。存儲密集型算子分兩種,一種是矢量或張量的神經(jīng)激活,多非線性運算,也叫GEMV (通用矩陣矢量乘法)。另一種是逐點元素型element-wise,典型的如矩陣反轉(zhuǎn),實際沒有任何運算,只是存儲行列對調(diào)。
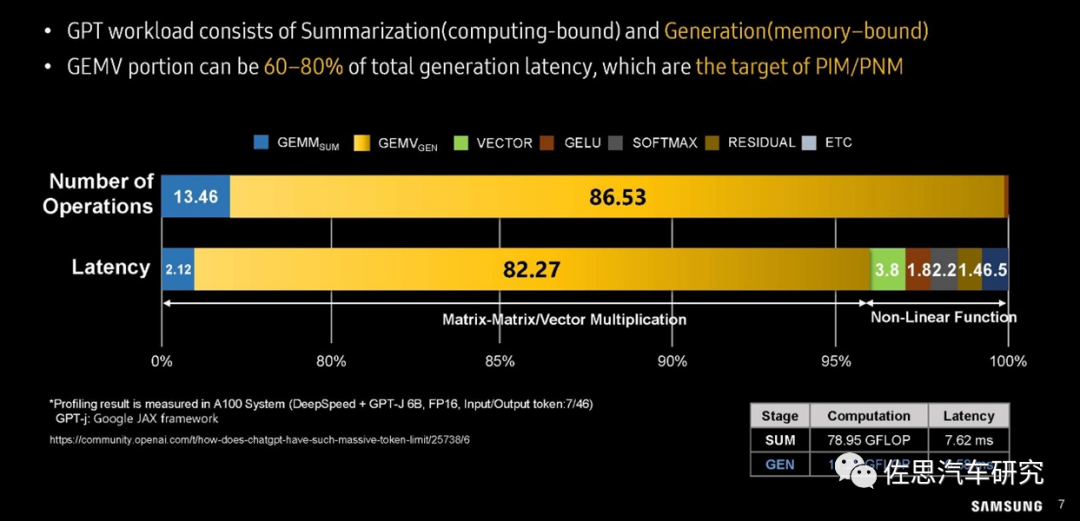
圖片來源:三星
上圖中,在運算操作數(shù)量上,GEMV所占比例高達(dá)86.53%,在大模型運算延遲分析上,82.27%的延遲都來自GEMV;GEMM占比只有2.12%;非線性運算也就是神經(jīng)元激活部分占的比例也遠(yuǎn)高于GEMM。
三星對GPU利用率的分析
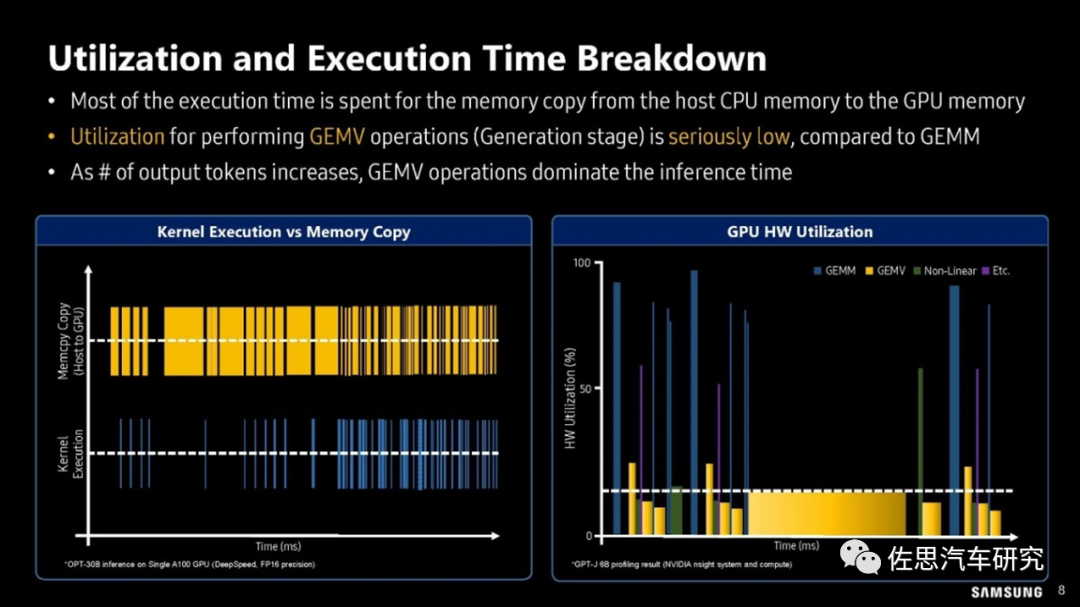
圖片來源:三星
上圖可以看出在GEMV算子時,GPU的利用率很低,一般不超過20%,換句話說80%的時間GPU都是在等待存儲數(shù)據(jù)的搬運。GPU的靈活性還是比較高的,如果換做靈活性比較差的AI專用加速器,如谷歌的TPU,那么GEMV的利用率會更低,不到10%甚至5%。
三星的GPT瓶頸分析
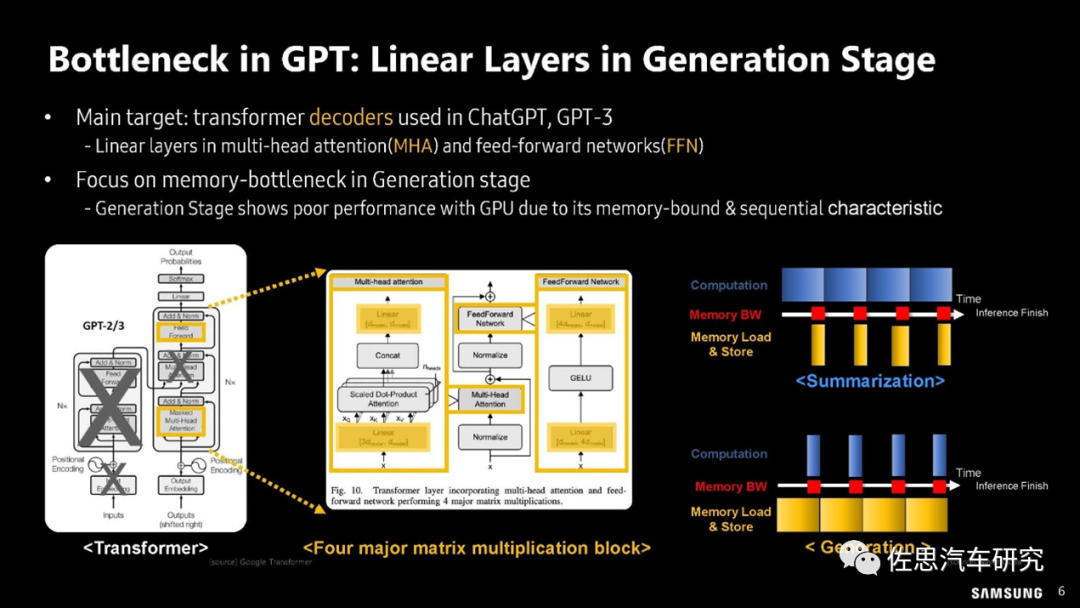
圖片來源:三星
Roof-line訪存與算力模型
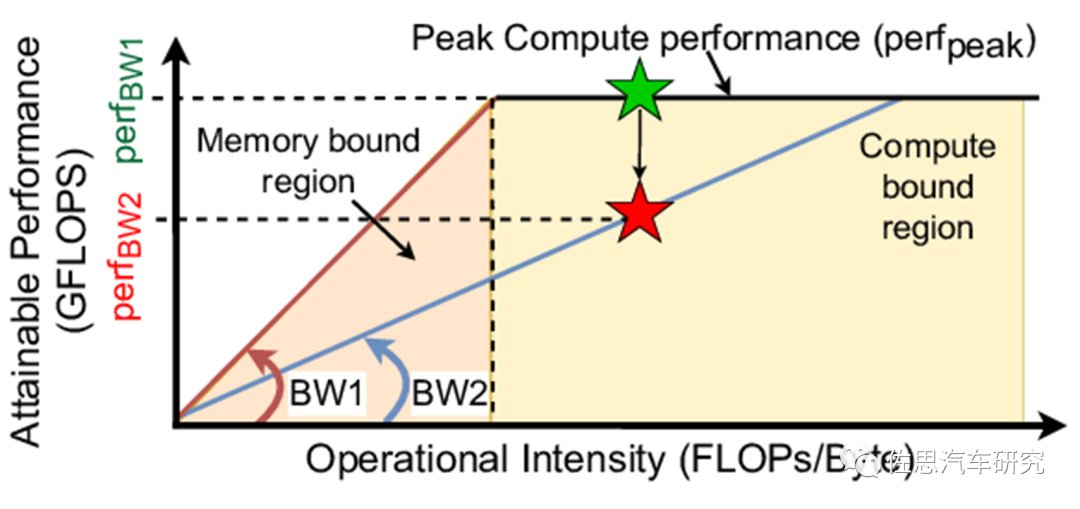
圖片來源:互聯(lián)網(wǎng)
上圖是鼎鼎大名的roof-line訪存與算力模型。
COPA-GPU架構(gòu)
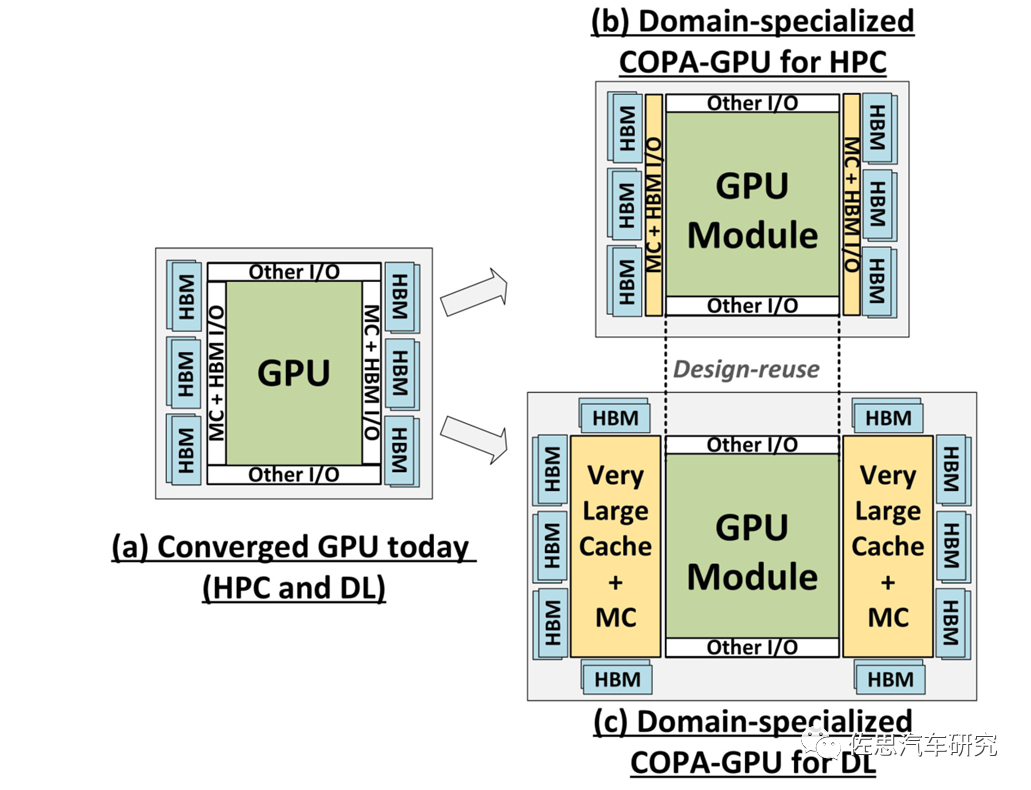
圖片來源:英偉達(dá)
上圖是2021年12月英偉達(dá)論文提出的COPA-GPU架構(gòu),實際就是把一個特別大容量的L2緩存die分離出來。因為如果還是monolithic設(shè)計,那么整個die的面積會超過1000平方毫米,不過***決定了芯片的最大die size不超過880平方毫米,所以必須將L2分離。
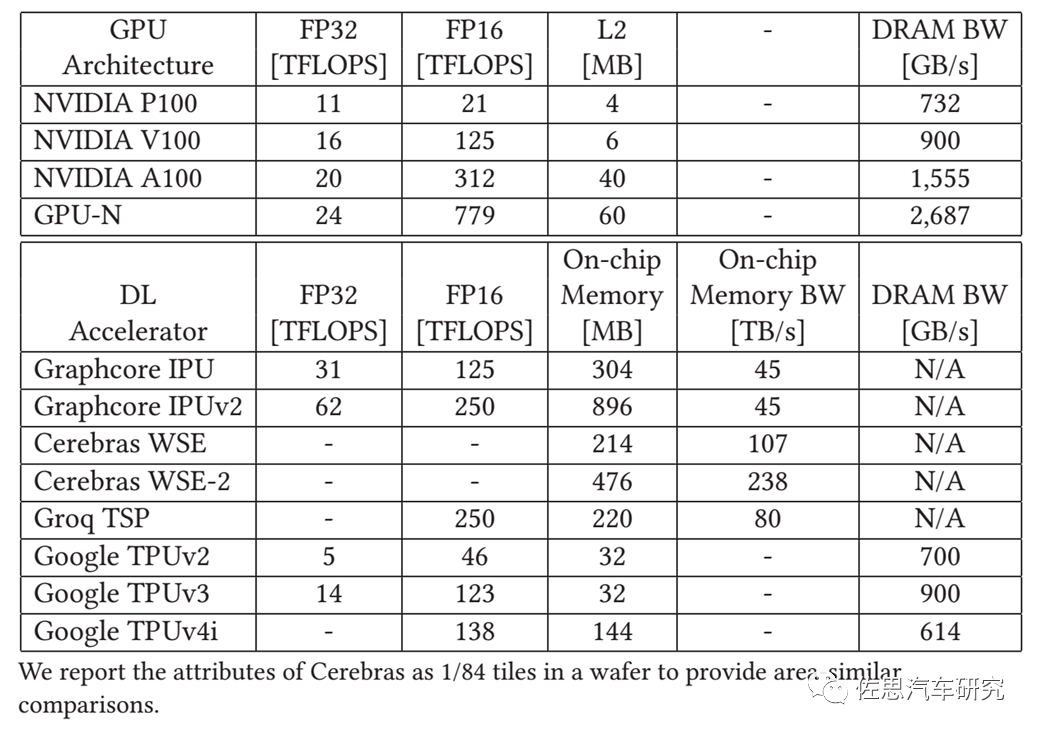
注:GPU-N就是英偉達(dá)的COPA-GPU。
圖片來源:英偉達(dá)
不同容量L2緩存對應(yīng)的延遲
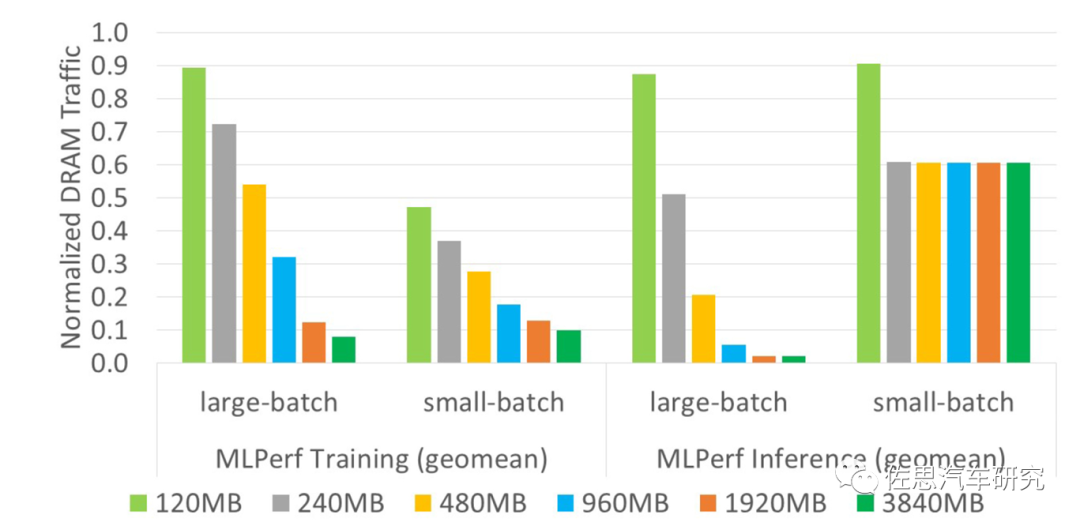
圖片來源:英偉達(dá)
上圖是不同容量L2緩存對應(yīng)的延遲情況,顯然L2緩存越高,延遲越低,不過在small-batch時不明顯。
幾種COPA-GPU的封裝分析
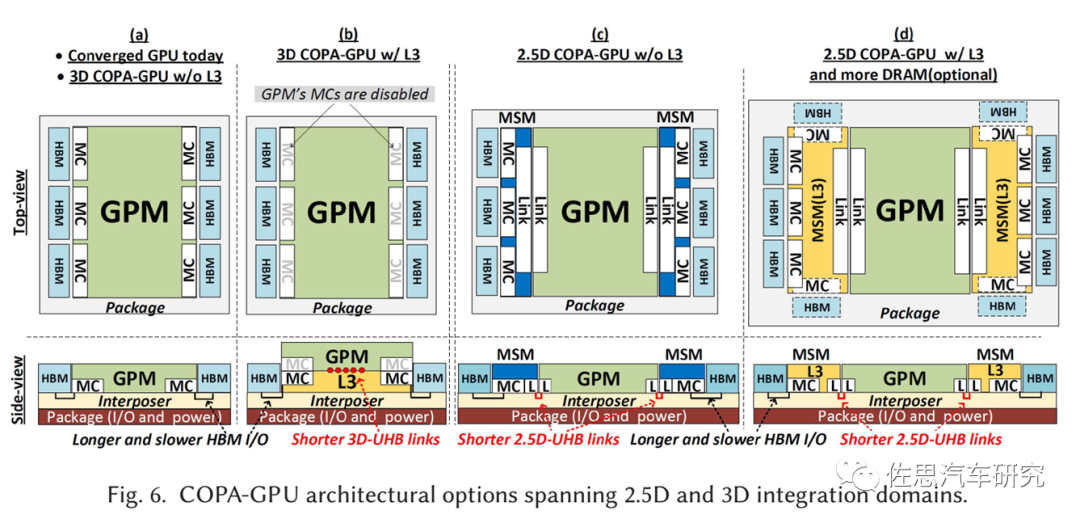
圖片來源:英偉達(dá)
從英偉達(dá)的論文里我們看不到架構(gòu)方面的絲毫改進(jìn),只有封裝領(lǐng)域的改變。這篇論文實際應(yīng)該由臺積電來寫,因為英偉達(dá)完全無法掌控芯片的封測工藝,CoWoS就是為英偉達(dá)這種設(shè)計而設(shè)計的,而CoWoS誕生在10年以前。
大模型不斷消耗更多的算力和存儲,這顯然違背了自然界效率至上的原則,或許人類正在錯誤的道路上狂奔。
免責(zé)說明:本文觀點和數(shù)據(jù)僅供參考,和實際情況可能存在偏差。本文不構(gòu)成投資建議,文中所有觀點、數(shù)據(jù)僅代表筆者立場,不具有任何指導(dǎo)、投資和決策意見。
-
gpu
+關(guān)注
關(guān)注
28文章
4909瀏覽量
130632 -
芯片架構(gòu)
+關(guān)注
關(guān)注
1文章
31瀏覽量
14687 -
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3920瀏覽量
93086
原文標(biāo)題:英偉達(dá)江郎才盡,下一代芯片架構(gòu)變化只是封裝
文章出處:【微信號:zuosiqiche,微信公眾號:佐思汽車研究】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
NVIDIA 采用納微半導(dǎo)體開發(fā)新一代數(shù)據(jù)中心電源架構(gòu) 800V HVDC 方案,賦能下一代AI兆瓦級算力需求
光庭信息推出下一代整車操作系統(tǒng)A2OS
麥格納與英偉達(dá)達(dá)成戰(zhàn)略協(xié)作 共塑下一代智能出行藍(lán)圖

Imagination與瑞薩攜手,重新定義GPU在下一代汽車中的角色

納米壓印技術(shù):開創(chuàng)下一代光刻的新篇章
百度李彥宏談訓(xùn)練下一代大模型
黃仁勛宣布:豐田與英偉達(dá)攜手打造下一代自動駕駛汽車
蘋果下一代芯片,采用新封裝
今日看點丨龍芯中科:下一代桌面芯片3B6600預(yù)計明年上半年交付流片;消息稱英偉達(dá) Thor 芯片量產(chǎn)大幅推遲
意法半導(dǎo)體下一代汽車微控制器的戰(zhàn)略部署
英偉達(dá)加速Rubin平臺AI芯片推出,SK海力士提前交付HBM4存儲器
通過下一代引線式邏輯IC封裝實現(xiàn)小型加固型應(yīng)用

IaaS+on+DPU(IoD)+下一代高性能算力底座技術(shù)白皮書
24芯M16插頭在下一代技術(shù)中的潛力






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論