") 數(shù)據(jù)庫分區(qū)、分庫和分表
數(shù)據(jù)庫分區(qū)、分庫和分表
今天先說說數(shù)據(jù)庫的數(shù)據(jù)分區(qū),分庫以及分表的內(nèi)容吧!
數(shù)據(jù)庫分區(qū)、分庫和分表
數(shù)據(jù)庫分區(qū)、分庫和分表是針對大型數(shù)據(jù)庫系統(tǒng)的優(yōu)化策略。它們的主要目的是提高數(shù)據(jù)庫的性能和可靠性,以滿足不斷增長的數(shù)據(jù)存儲需求。
數(shù)據(jù)庫分區(qū)
將一個大型數(shù)據(jù)庫分成多個邏輯部分,每個部分被稱為一個分區(qū)。每個分區(qū)可以獨立進行管理和維護,使得數(shù)據(jù)庫系統(tǒng)的可擴展性和可用性得到了提高。
水平分區(qū)和垂直分區(qū)是數(shù)據(jù)庫分區(qū)的兩種主要方式,其主要存在如下的區(qū)別:
- 水平分區(qū)是將一個大表按照某個條件(如按照時間、地理位置等)分成多個小表,每個小表中包含相同的列,但是行數(shù)不同。在選擇水平分區(qū)的分區(qū)鍵時,需要考慮數(shù)據(jù)的訪問模式和數(shù)據(jù)的增長模式。例如按照時間分區(qū)可以提高歷史數(shù)據(jù)的查詢效率,按照地理位置分區(qū)可以提高地理數(shù)據(jù)的查詢效率。水平分區(qū)的優(yōu)點是可以提高數(shù)據(jù)的查詢效率和并發(fā)處理能力,缺點是可能會導(dǎo)致數(shù)據(jù)的冗余和數(shù)據(jù)的一致性問題。
- 垂直分區(qū)是將一個大表按照列的不同將其分成多個小表,每個小表中包含相同的行,但是列數(shù)不同。選擇垂直分區(qū)的分區(qū)鍵時,可將經(jīng)常一起查詢的列分到同一個分區(qū)中可以提高查詢效率,將經(jīng)常被更新的列分到單獨的分區(qū)中也可以提高更新效率。垂直分區(qū)的優(yōu)點是可以減少數(shù)據(jù)的冗余,提高數(shù)據(jù)的查詢效率,也可能會導(dǎo)致數(shù)據(jù)的一致性問題。
水平分區(qū)栗子:
CREATE TABLE mytable (
id SERIAL PRIMARY KEY,
data TEXT,
created_at TIMESTAMP WITH TIME ZONE
)
PARTITION BY RANGE (created_at);
CREATE TABLE mytable_2021_01 PARTITION OF mytable
FOR VALUES FROM ('2021-01-01') TO ('2021-02-01');
CREATE TABLE mytable_2021_02 PARTITION OF mytable
FOR VALUES FROM ('2021-02-01') TO ('2021-03-01');
CREATE TABLE mytable_2021_03 PARTITION OF mytable
FOR VALUES FROM ('2021-03-01') TO ('2021-04-01');
-- 創(chuàng)建更多的分區(qū)表,每個表代表一個月份
垂直分區(qū)栗子:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(10) NOT NULL,
age INTEGER NOT NULL,
address VARCHAR(200) NOT NULL,
phone VARCHAR(20) NOT NULL
);
CREATE TABLE users_name_gender (
id INTEGER PRIMARY KEY REFERENCES users(id),
name VARCHAR(50) NOT NULL,
gender VARCHAR(10) NOT NULL
);
CREATE VIEW users_info AS
SELECT users.id, users_name_gender.name, users_name_gender.gender, users.age, users.address, users.phone
FROM users
JOIN users_name_gender ON users.id = users_name_gender.id;
數(shù)據(jù)庫分表
將一個大型表分成多個小型表,每個表被稱為一個分表。每個分表可以獨立進行管理和維護,使得數(shù)據(jù)庫系統(tǒng)的可擴展性和可用性得到了提高。同時,分表還可以提高數(shù)據(jù)庫系統(tǒng)的查詢速度和并發(fā)處理能力,降低數(shù)據(jù)沖突和死鎖的發(fā)生概率。
分表的復(fù)雜性就比分區(qū)大多了,需要業(yè)務(wù)邏輯的配合才可以。
數(shù)據(jù)庫分表的方式有以下幾種:
- 垂直分表:按照列的業(yè)務(wù)邏輯將表拆分成多個表,每個表包含一部分列。這種方式適用于表中某些列的訪問頻率較低,或者某些列的數(shù)據(jù)量較大,可以將這些列獨立成一個表,從而提高查詢性能和并發(fā)能力。
- 水平分表:按照行的業(yè)務(wù)邏輯將表拆分成多個表,每個表包含部分行數(shù)據(jù)。這種方式適用于表中數(shù)據(jù)量較大,或者訪問頻率較高的行可以分散到多個表中,從而減少單個表的數(shù)據(jù)量,提高查詢性能和并發(fā)能力。
- 分區(qū)表:按照某個特定的規(guī)則將表分成多個邏輯上的部分,每個部分稱為一個分區(qū)。分區(qū)可以按照時間、范圍、哈希等方式進行劃分。這種方式適用于表中數(shù)據(jù)量較大,或者訪問頻率較高的數(shù)據(jù)可以按照某個規(guī)則分散到多個分區(qū)中,從而提高查詢性能和并發(fā)能力。
- 組合分表:將垂直分表、水平分表和分區(qū)表結(jié)合起來使用,可以根據(jù)具體的業(yè)務(wù)需求和數(shù)據(jù)特點進行靈活的組合,從而達到最優(yōu)的性能和可擴展性。
舉栗子:
假設(shè)有一個訂單表,包含訂單號、用戶ID、下單時間、訂單金額等字段,數(shù)據(jù)量較大,需要進行分表操作。
- 垂直分表:將訂單表按照列的業(yè)務(wù)邏輯進行拆分,可以將訂單金額獨立成一個表,每個表包含訂單號、用戶ID、下單時間和訂單金額。
- 水平分表:將訂單表按照行的業(yè)務(wù)邏輯進行拆分,可以按照用戶ID進行拆分,將同一個用戶的訂單分散到多個表中,每個表包含訂單號、下單時間和訂單金額。
- 分區(qū)表:將訂單表按照時間進行分區(qū),可以按照下單時間的年份、月份或日期進行分區(qū),每個分區(qū)包含一段時間內(nèi)的訂單數(shù)據(jù)。
- 組合分表:可以將垂直分表、水平分表和分區(qū)表結(jié)合起來使用,例如按照用戶ID進行水平分表,再按照下單時間進行分區(qū),每個分區(qū)包含一個用戶在一段時間內(nèi)的訂單數(shù)據(jù)
數(shù)據(jù)庫分庫
將一個大型數(shù)據(jù)庫分成多個小型數(shù)據(jù)庫,每個數(shù)據(jù)庫被稱為一個分庫。每個分庫可以獨立進行管理和維護,使得數(shù)據(jù)庫系統(tǒng)的可擴展性和可用性得到了提高。同時,分庫還可以提高數(shù)據(jù)庫系統(tǒng)的并發(fā)處理能力,降低數(shù)據(jù)沖突和死鎖的發(fā)生概率。
- 垂直分庫:
垂直分庫是指將一張表按照列的業(yè)務(wù)邏輯劃分成多個表,每個表只包含部分列。這種方式適用于某些列經(jīng)常被查詢,而其他列很少被查詢的情況。垂直分庫的優(yōu)點是可以將數(shù)據(jù)分散到不同的物理節(jié)點上,從而提高查詢效率和可用性。在 PostgreSQL 中,可以使用視圖或表繼承來實現(xiàn)垂直分庫。
- 水平分庫:
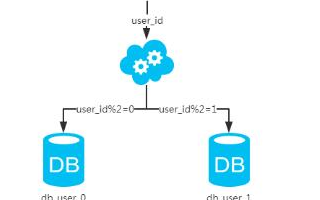
水平分庫是指將一張表按照行的業(yè)務(wù)邏輯劃分成多個表,每個表包含部分行。這種方式適用于數(shù)據(jù)量很大,單個節(jié)點無法存儲全部數(shù)據(jù)的情況。水平分庫的優(yōu)點是可以將數(shù)據(jù)分散到多個物理節(jié)點上,從而提高查詢效率和可用性。在實現(xiàn)水平分庫時,可以使用分片鍵將數(shù)據(jù)分散到不同的節(jié)點上,同時需要考慮數(shù)據(jù)的一致性和事務(wù)處理等問題。
分庫的常見實現(xiàn)方式
- 數(shù)據(jù)庫代理:通過在客戶端和數(shù)據(jù)庫之間插入代理層,將請求分發(fā)到不同的數(shù)據(jù)庫節(jié)點上。
- 分布式事務(wù)協(xié)議:通過協(xié)議實現(xiàn)分布式事務(wù)的一致性,保證數(shù)據(jù)的正確性。
- 分片鍵路由:通過分片鍵將數(shù)據(jù)分散到不同的節(jié)點上,同時需要考慮數(shù)據(jù)的一致性和事務(wù)處理等問題。
- 數(shù)據(jù)庫復(fù)制:將數(shù)據(jù)復(fù)制到多個節(jié)點上,提高查詢效率和可用性。
什么時候分庫
- 單臺DB的存儲空間不夠時。
- 隨著查詢量的增加單臺數(shù)據(jù)庫服務(wù)器已經(jīng)沒辦法支撐業(yè)務(wù)擴展。
總的來說,數(shù)據(jù)庫分區(qū)、分庫和分表的目的都是為了提高數(shù)據(jù)庫系統(tǒng)的性能和可靠性,使得它能夠更好地應(yīng)對不斷增長的數(shù)據(jù)存儲需求。
-
存儲
+關(guān)注
關(guān)注
13文章
4499瀏覽量
87053 -
服務(wù)器
+關(guān)注
關(guān)注
12文章
9681瀏覽量
87256 -
數(shù)據(jù)庫
+關(guān)注
關(guān)注
7文章
3900瀏覽量
65751 -
視圖
+關(guān)注
關(guān)注
0文章
140瀏覽量
6728
發(fā)布評論請先 登錄
談分布式數(shù)據(jù)庫中間件之分庫分表
基于聚類分析分庫策略的社交網(wǎng)絡(luò)數(shù)據(jù)庫查詢性能與數(shù)據(jù)遷移
數(shù)據(jù)庫分庫分表基礎(chǔ)和實踐
數(shù)據(jù)庫瓶頸及分庫分表示例
優(yōu)化MySQL數(shù)據(jù)庫中樸實無華的分表和花里胡哨的分庫
MySQL數(shù)據(jù)庫性能優(yōu)化的意義及其措施
數(shù)據(jù)庫優(yōu)化最有效的方式是什么?
oracle數(shù)據(jù)庫分區(qū)有哪些
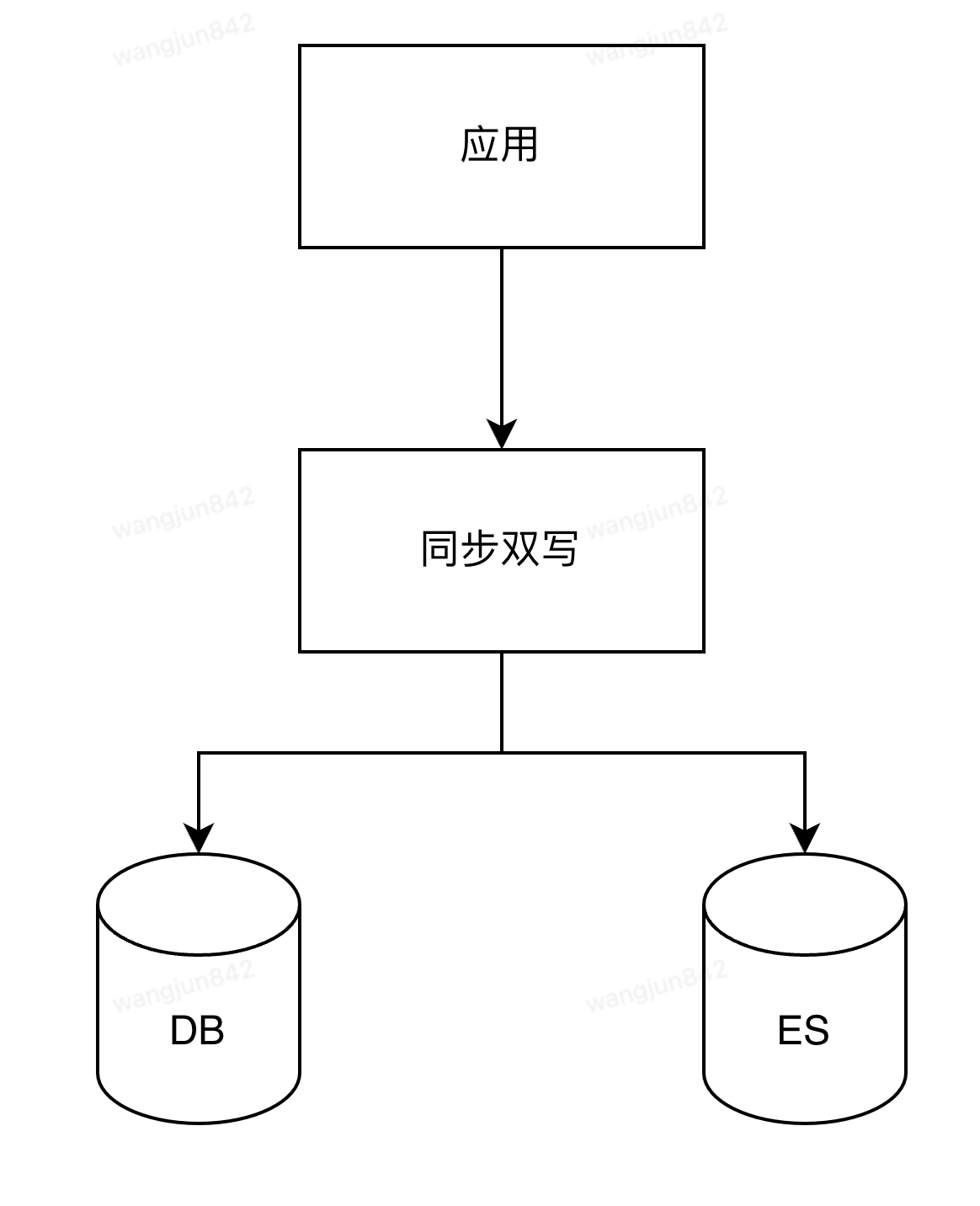
分庫分表后復(fù)雜查詢的應(yīng)對之道:基于DTS實時性ES寬表構(gòu)建技術(shù)實踐
數(shù)據(jù)庫數(shù)據(jù)恢復(fù)—SQL Server數(shù)據(jù)庫所在分區(qū)空間不足報錯的數(shù)據(jù)恢復(fù)案例
軟件系統(tǒng)數(shù)據(jù)庫的分庫分表設(shè)計





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論