") 一種支持AI視頻處理的高容量流媒體加速卡方案
一種支持AI視頻處理的高容量流媒體加速卡方案
本次要和大家分享的是AMD近期推出的新一代多媒體視頻加速卡,它主要應(yīng)用于視頻處理場(chǎng)景,我們內(nèi)部將它稱為異構(gòu)加速卡,行業(yè)同仁更認(rèn)可將其稱作視頻處理單元(VPU)。AMD或賽靈思此前的主要業(yè)務(wù)方向是研發(fā)數(shù)據(jù)中心級(jí)加速器卡,因而大家可能對(duì)此次媒體加速卡的發(fā)布感到驚訝,實(shí)際上這背后伴隨著深厚的研發(fā)背景。
賽靈思時(shí)期,我們的目標(biāo)是實(shí)現(xiàn)FPGA在數(shù)據(jù)中心的算力落地,通過(guò)將FPGA包裝為PCIE擴(kuò)展卡并部署在服務(wù)器上,使客戶可以按照自身需求調(diào)用加速卡的算力,最終推出了Alveo系列加速卡U200、U250和U280。
隨著FaaS(FPGA as a service)的落地,我們的工作進(jìn)一步轉(zhuǎn)向應(yīng)用化并發(fā)現(xiàn)了媒體加速方面的前景,因而開始進(jìn)行編解碼器和IP核的自研設(shè)計(jì)。賽靈思還專門收購(gòu)了編解碼器公司以推動(dòng)VPU的開發(fā),從而促成了上一代視頻流加速器卡U30和U50的誕生。
我們認(rèn)為,雖然傳統(tǒng)的流媒體服務(wù)以及相關(guān)的視頻處理、壓縮是在服務(wù)器級(jí)CPU上的軟件中完成的。但隨著分辨率的增加,幀數(shù)要求提高,流媒體體量的增加,直播和互動(dòng)流應(yīng)用對(duì)低延遲的要求變得更加嚴(yán)格,傳統(tǒng)的CPU不能高效地處理這種場(chǎng)景。因而我們開始尋求異構(gòu)加速的方法,用專業(yè)的芯片/IP來(lái)處理視頻流。
基于以上背景,我們認(rèn)為下一代視頻加速卡要支持高質(zhì)量、高密度、低時(shí)延的視頻處理,并要具備更好的拓展性,才能滿足當(dāng)前低延時(shí)、高交互、大流量多媒體應(yīng)用環(huán)境的需要。
我們將此次推出的新一代加速卡命名為Alveo MA35D Media Accelerator,它是業(yè)界首款基于ASIC的5nm視頻加速卡,在我們內(nèi)部的芯片代號(hào)為supernova。
與我們上一代產(chǎn)品(Alveo U30)和傳統(tǒng)Xilinx芯片的聯(lián)系不同,它完全脫離了 FPGA,是一個(gè)專門應(yīng)用于交互式流媒體大規(guī)模應(yīng)用場(chǎng)景的針對(duì)性解決方案。它內(nèi)部包含很多專用視頻單元和最先進(jìn)的IP核,通過(guò)PCIE Gen 5.0和LPDDR5保證帶寬,充分助力視頻加速服務(wù)。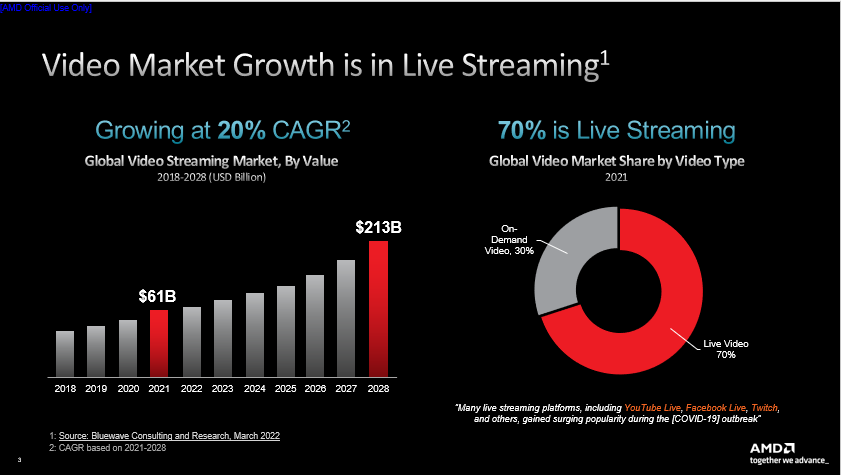
Bluewave Consulting發(fā)布的調(diào)研成果促使我們下定決心推出新一代流媒體加速卡,該項(xiàng)研究指出了兩點(diǎn),一是全球視頻流媒體市場(chǎng)正在快速增長(zhǎng)。據(jù)預(yù)測(cè),流媒體的市場(chǎng)價(jià)值將從 2022 年的略高于 600 億美元增至 2028 年的超過(guò) 2130 億美元,復(fù)合年增長(zhǎng)率約為 20%。在美國(guó)這很大程度上要?dú)w功于 Netflix、Amazon Prime、Hulu、Disney+、HBO 等服務(wù)商,國(guó)內(nèi)現(xiàn)階段也存在諸如優(yōu)酷、騰訊、愛奇藝、抖音、快手、Bilibili等大量視頻平臺(tái),甚至微博、微信和知乎等應(yīng)用也在逐步推出流媒體服務(wù),幾乎所有公司都在進(jìn)行流媒體方向的嘗試。二是流媒體服務(wù)正在迎來(lái)轉(zhuǎn)型。隨著流媒體市場(chǎng)的增長(zhǎng),直播業(yè)務(wù)所占份額越來(lái)越大(例如國(guó)內(nèi)的抖音等直播平臺(tái)),至2021年已占到總量的70%。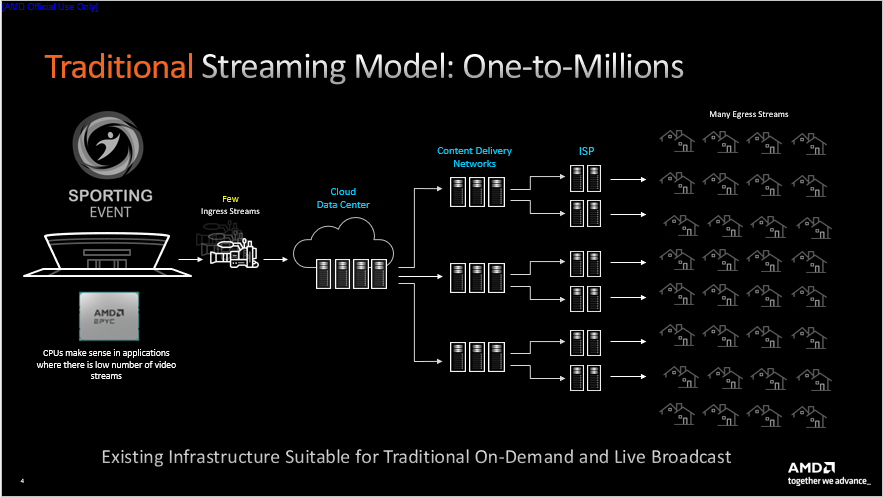
傳統(tǒng)流媒體服務(wù)架構(gòu)的形式為廣播流媒體,是“一對(duì)百萬(wàn)”的模式,該架構(gòu)下視頻的輸入源一般較少。以體育賽事的轉(zhuǎn)播場(chǎng)景為例,場(chǎng)外的轉(zhuǎn)播車組織現(xiàn)場(chǎng)的數(shù)十臺(tái)攝像機(jī)拍攝賽事畫面,經(jīng)過(guò)剪輯上傳至云端數(shù)據(jù)中心/核心網(wǎng),過(guò)程中傳輸?shù)牧飨鄬?duì)并不多。隨后視頻流被分發(fā)至CDN,廣大用戶通過(guò)ISP訪問(wèn)CDN獲取視頻畫面。
雖然整個(gè)傳輸路徑較長(zhǎng),延遲相對(duì)較大,但該場(chǎng)景對(duì)實(shí)時(shí)性的要求不大,并且時(shí)延相對(duì)可控。同時(shí)由于輸入流較少,因而對(duì)轉(zhuǎn)碼的要求也不高。
迅猛增長(zhǎng)的直播市場(chǎng)與傳統(tǒng)點(diǎn)播場(chǎng)景不同,每個(gè)人都能生成自己的流媒體,個(gè)人產(chǎn)生的視頻流可能與其他流混同,被不同人群在不同地點(diǎn)使用各異的終端設(shè)備觀看,過(guò)程中還伴隨著低時(shí)延和高交互等等要求。 這種場(chǎng)景的實(shí)際應(yīng)用也越來(lái)越多,如online party、遠(yuǎn)程醫(yī)療、云游戲場(chǎng)景和Zoom、Microsoft Teams等在線會(huì)議軟件。
不同用戶使用的設(shè)備可能不同,導(dǎo)致輸入源的格式、清晰度等等屬性五花八門。而以上場(chǎng)景都具備高交互性,對(duì)時(shí)延的要求相當(dāng)高(如云游戲的時(shí)延要在10毫秒內(nèi)),因而我們希望研發(fā)新一代芯片,能夠?qū)崿F(xiàn)低時(shí)延、高容量、多路輸入(不同格式,不同速率,不同size)、多路輸出、多流交互的視頻處理。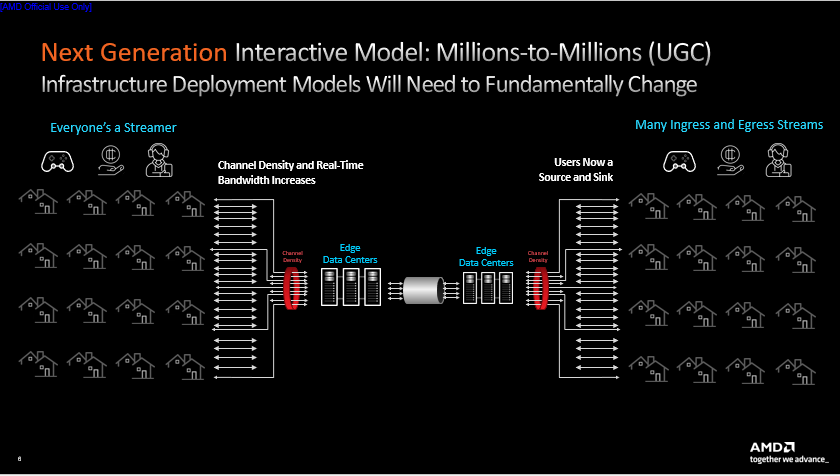
新一代直播場(chǎng)景是“百萬(wàn)對(duì)百萬(wàn)”的多對(duì)多模式。由于每個(gè)人都會(huì)產(chǎn)生視頻流,流的數(shù)量將進(jìn)一步增加,并且突發(fā)式的增長(zhǎng)會(huì)越來(lái)越多。直播的高交互性使視頻流傳輸可能將更多采用邊到邊傳輸,避免發(fā)送至云端數(shù)據(jù)中心。用戶們使用的終端設(shè)備不盡相同,對(duì)視頻流分辨率和碼率的要求也不一樣。
為了應(yīng)對(duì)直播場(chǎng)景帶來(lái)的技術(shù)挑戰(zhàn),Alveo MA35D支持32路流的1080P60 ABR轉(zhuǎn)碼;每通道功耗僅有1W,峰值功耗約35W;4K編碼的最低延時(shí)達(dá)到8毫秒,1080P可以做到單幀2ms;支持做成單個(gè)U.2/M.2 的子卡或是多卡集成部署,支持筆記本、平板、園區(qū)、數(shù)據(jù)中心等多種不同部署環(huán)境,適配用戶的不同需求。與此同時(shí),它還具備22 TOPS AI算力(INT8),可以通過(guò)AI技術(shù)來(lái)賦能智能視頻處理。
上一代U30的“U”代表通用,而MA35D的“MA”代表媒體加速器(Media Accelerator),表示該卡專為媒體加速場(chǎng)景設(shè)計(jì)。和上一代相比,MA35D實(shí)現(xiàn)了全面提升,它的通道密度提高了 4 倍,每通道功耗降低2倍,壓縮效率效果提高2倍,時(shí)延降低4倍。在實(shí)現(xiàn)以上提升的基礎(chǔ)上,功耗僅為上一代的一半。
接下來(lái)介紹該卡的技術(shù)細(xì)節(jié)。首先四個(gè)位于該卡芯片四角的獨(dú)立編碼器和兩個(gè)解碼器支持當(dāng)前主流編碼標(biāo)準(zhǔn)和下一代AV1標(biāo)準(zhǔn);自適應(yīng)比特率(ABR)縮放器支持變碼率、恒定QP、CBR、VBR等多樣化變換;合成器(Compositor)引擎支持多流分塊拼接、分層疊加等視頻合成處理,它是可編程的,可按照客戶自身需求改變輸出;VQ 前瞻(Look-Ahead)引擎用于在編碼前分析視頻流的動(dòng)態(tài)特征,配合編碼器實(shí)時(shí)優(yōu)化參數(shù);視頻質(zhì)量(VQ)和體驗(yàn)質(zhì)量(QoE)引擎作為在線質(zhì)量分析引擎可以將編碼后視頻的質(zhì)量分析結(jié)果實(shí)時(shí)反饋至編碼器和AI模塊,動(dòng)態(tài)調(diào)整編碼器設(shè)置以達(dá)到更好的視頻輸出質(zhì)量;AI處理器可以對(duì)視頻進(jìn)行一些簡(jiǎn)單的分類和檢測(cè)處理,依據(jù)結(jié)果實(shí)時(shí)調(diào)整編碼器參數(shù),改善視頻質(zhì)量。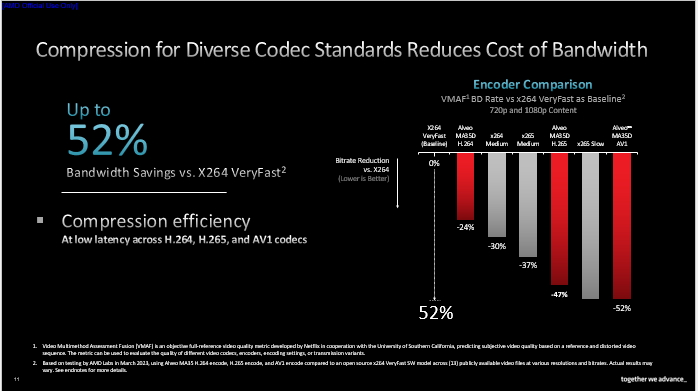
我們也致力于改善編解碼器的壓縮效率。據(jù)AMD內(nèi)部測(cè)試結(jié)果顯示,在達(dá)到同等視覺質(zhì)量的前提下,以X264 VeryFast為基準(zhǔn)對(duì)比,AMD H.264編碼器可實(shí)現(xiàn)24%的碼率節(jié)省,H.265編碼器可節(jié)省47%,AV1編碼器可節(jié)省高達(dá)52%。如果加入AI處理環(huán)節(jié),壓縮效率還將進(jìn)一步提升。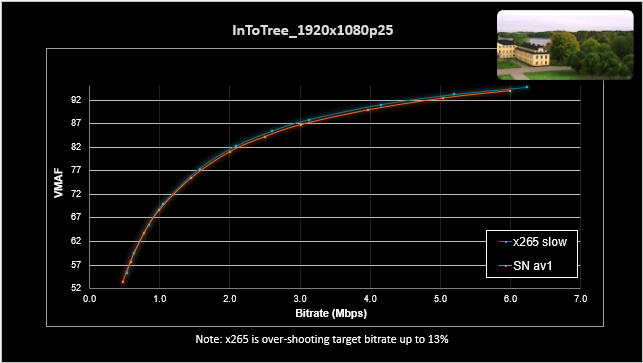
上圖展示了X265和AMD AV1編碼相同視頻的實(shí)測(cè)VMAF測(cè)試結(jié)果。可以看到在同等條件下,AMD AV1編碼視頻的質(zhì)量接近于X265 Slow,尤其在碼率較低時(shí)表現(xiàn)相當(dāng)好。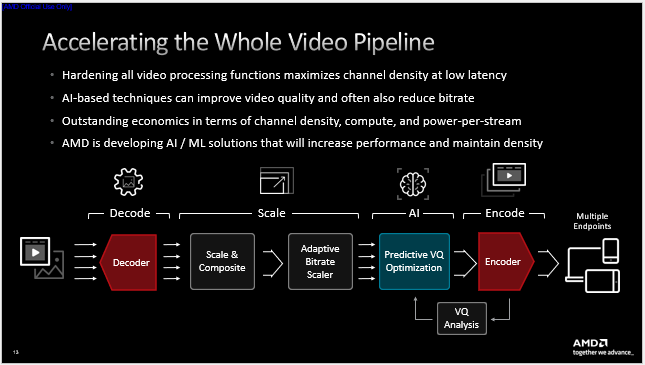
AMD深度耦合前述的各類硬件單元形成了上圖所示的視頻處理管道,視頻解碼、縮放與合成、ABR縮放、AI處理、編碼、質(zhì)量分析等步驟全部由硬件單元完成,通過(guò)將所有視頻處理功能硬化來(lái)最大限度減少CPU和加速卡之間的數(shù)據(jù)遷移。
在云游戲和直播場(chǎng)景,大家可能遇到過(guò)畫面內(nèi)字符顯示不清晰的問(wèn)題,運(yùn)用前述的AI技術(shù)則可對(duì)字符所在區(qū)域進(jìn)行顯示質(zhì)量的針對(duì)性優(yōu)化。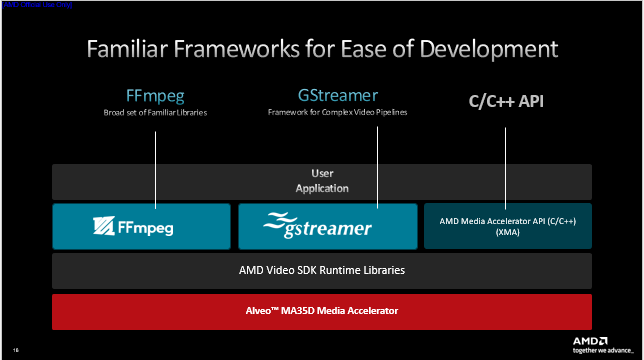
用戶可通過(guò)我們隨卡附帶的AMD媒體加速軟件開發(fā)套件(SDK)訪問(wèn)加速卡,它帶有FFmpeg、GStreamer接口,便于快速上手。高階用戶還可以通過(guò)AMD 媒體加速器接口客制化調(diào)用加速卡的各種視頻處理模塊。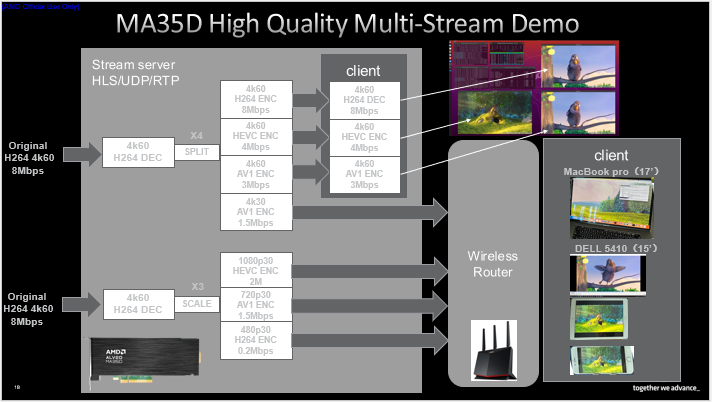
接下來(lái)介紹MA35D的一次視頻處理性能演示,我們使用單卡雙芯片同時(shí)處理兩個(gè)4k60 8Mps H264流。其中一路解碼后分為四個(gè)流以不同碼率和編碼標(biāo)準(zhǔn)輸出,四個(gè)流中的三個(gè)在同服務(wù)器上使用加速卡自帶解碼器進(jìn)行轉(zhuǎn)碼、編碼,傳輸至顯示器。另一路分為三個(gè)流按不同分辨率、碼率和編碼標(biāo)準(zhǔn)輸出,同第一路中的第四個(gè)流一并無(wú)線傳輸至不同設(shè)備解碼顯示。
如上所示,演示過(guò)程中第一路流在同服務(wù)器下的轉(zhuǎn)碼和解碼都達(dá)到了60fps水平,并且轉(zhuǎn)碼占用的CPU核1負(fù)載不大,核2到核8負(fù)責(zé)將解碼后YUV數(shù)據(jù)轉(zhuǎn)移至顯卡,因而出現(xiàn)了高負(fù)載情況。處理過(guò)程中的加速卡資源占用情況支持隨時(shí)調(diào)取查看。
上圖展示了演示的實(shí)時(shí)多流多終端傳輸顯示效果。
審核編輯:劉清
-
FPGA
+關(guān)注
關(guān)注
1643文章
21941瀏覽量
613322 -
加速器
+關(guān)注
關(guān)注
2文章
823瀏覽量
38859 -
編解碼器
+關(guān)注
關(guān)注
0文章
272瀏覽量
24617 -
視頻處理器
+關(guān)注
關(guān)注
3文章
109瀏覽量
16000 -
LPDDR5
+關(guān)注
關(guān)注
2文章
89瀏覽量
12410
原文標(biāo)題:支持AI視頻處理的高容量流媒體加速卡方案
文章出處:【微信號(hào):livevideostack,微信公眾號(hào):LiveVideoStack】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄

邊緣AI運(yùn)算革新 DeepX DX-M1 AI加速卡結(jié)合Rockchip RK3588多路物體檢測(cè)解決方案

AI加速卡到底是個(gè)啥?一文讓小白也能看懂AI時(shí)代的“超級(jí)計(jì)算器”!

寒武紀(jì)基于思元370芯片的MLU370-X8 智能加速卡產(chǎn)品手冊(cè)詳解

RK3588核心板在邊緣AI計(jì)算中的顛覆性優(yōu)勢(shì)與場(chǎng)景落地
邊緣AI新突破:MemryX AI加速卡與RK3588打造高效多路物體檢測(cè)方案

基于Xilinx XCKU115的半高PCIe x8 硬件加速卡

S7t-VG6 VectorPath加速卡的特性和功能
PCIe加速卡在數(shù)據(jù)中心的應(yīng)用
AMD推出新款纖薄尺寸電子交易加速卡
大模型向邊端側(cè)部署,AI加速卡朝高算力、小體積發(fā)展
EPSON差分晶振SG3225VEN頻點(diǎn)312.5mhz應(yīng)用于AI加速卡
YXC高頻差分晶振,頻點(diǎn)312.5mhz,高精度.高穩(wěn)定性,應(yīng)用于AI加速卡

智能加速計(jì)算卡設(shè)計(jì)原理圖:628-基于VU3P的雙路100G光纖加速計(jì)算卡 XCVU3P板卡






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論