") 一個簡單模型就讓ChatGLM性能大幅提升 | 最“in”大模型
一個簡單模型就讓ChatGLM性能大幅提升 | 最“in”大模型
引言
自大語言模型 (LLM) 成為熱點話題以來,涌現(xiàn)了一大批中文大語言模型并在優(yōu)化平臺中得到了積極部署。ChatGLM 正是廣受好評的主流中文 LLM 之一。然而,由于 ChatGLM 模型尚未成為 Transformer 生態(tài)的原生模型,因此,官方 optimum 擴展庫對其仍缺乏支持。本文提供了一種使用 OpenVINO opset 重構(gòu)該模型架構(gòu)的便捷方法。該方案包含專為 ChatGLM 定制的優(yōu)化節(jié)點,且這些節(jié)點都利用英特爾 高級矩陣擴展(Intel Advanced Matrix Extensions,英特爾 AMX)內(nèi)聯(lián)和 MHA(Multi-Head Attention,多頭注意力)融合實現(xiàn)了高度優(yōu)化。
*請注意,本文僅介紹了通過為 ChatGLM 創(chuàng)建 OpenVINO stateful 模型實現(xiàn)優(yōu)化的解決方案。本方案受平臺限制,必須使用內(nèi)置了英特爾 AMX 的第四代英特爾 至強 可擴展處理器1(代號 Sapphire Rapids)。筆者不承諾對該解決方案進行任何維護。
ChatGLM 模型簡介
筆者在查看 ChatGLM 原始模型的源碼時,發(fā)現(xiàn) ChatGLM 與 Optimum ModelForCasualML 并不兼容,而是定義了新的類 ChatGLMForConditionalGeneration。該模型的流水線回路包含 3 個主要模塊(Embedding、GLMBlock 層和 lm_logits),結(jié)構(gòu)如下:
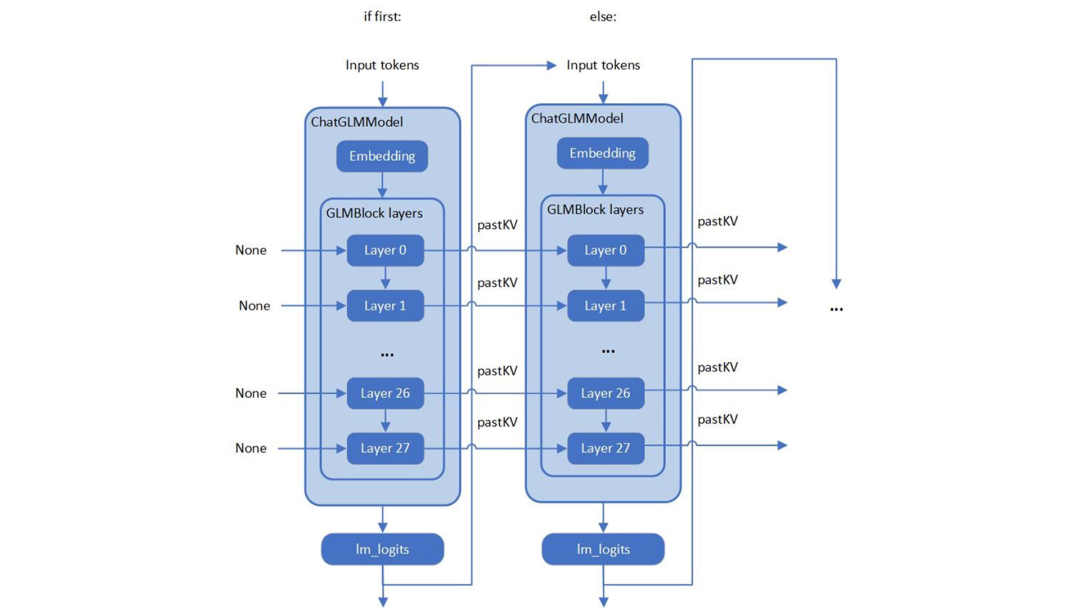
圖 1. ChatGLM 的模型結(jié)構(gòu)
如上圖所示,整個流水線實際要求模型有兩個不同的執(zhí)行圖,使用輸入提示符進行首次推理時不需要 KV 緩存作為 GLMBlock 層的輸入。從第二次迭代開始,QKV 注意力機制的上一次結(jié)果將成為當(dāng)前一輪模型推理的輸入。隨著生成符的長度不斷增加,在流水線推理過程中,模型輸入和輸出之間將存留大量的大型內(nèi)存副本。以ChatGLM6b 默認(rèn)模型配置2為示例,輸入和輸出陣列之間的內(nèi)存副本類似于以下偽代碼,其內(nèi)存拷貝的開銷由模型的參數(shù) hidden_size 以及迭代的次數(shù)決定:

因此,本文要解決的兩大關(guān)鍵問題是:
-
如何優(yōu)化模型推理流水線來消除模型輸入和輸出之間的內(nèi)存副本
-
如何通過重新設(shè)計執(zhí)行圖來優(yōu)化 GLMBlock 模塊
構(gòu)建 OpenVINO stateful 模型
實現(xiàn)顯著優(yōu)化
首先,需要分析 GLMBlock 層的結(jié)構(gòu),嘗試封裝一個類并按以下工作流來調(diào)用 OpenVINO opset。接著,將圖形數(shù)據(jù)序列化為 IR 模型 (.xml, .bin)。

圖 2. 為 ChatGLM 構(gòu)建 OpenVINO stateful 模型
關(guān)于如何構(gòu)建 OpenVINO stateful模型,可參閱以下文檔:
https://docs.openvino.ai/2022.3/openvino_docs_OV_UG_network_state_intro.html
OpenVINO 還提供了模型創(chuàng)建樣本,以展示如何通過 opset 構(gòu)建模型。
https://github.com/openvinotoolkit/openvino/blob/master/samples/cpp/model_creation_sample/main.cpp
ChatGLM 的自定義注意力機制是本文所關(guān)注和優(yōu)化的部分。主要思路是:構(gòu)建全局上下文結(jié)構(gòu)體,用于在模型內(nèi)部追加并保存每一輪迭代后的 pastKV 的結(jié)果,這樣減少了 pastKV 作為模型輸入輸出的拷貝開銷,同時使用內(nèi)聯(lián)優(yōu)化以實現(xiàn) Rotary Embedding 和多頭注意力機制 (Multi-Head Attentions)。 英特爾 AMX 是內(nèi)置在第四代英特爾至強 可擴展處理器中的矩陣乘法加速器,能夠更快速地處理 bf16 或 int8 數(shù)據(jù)類型的矩陣乘加運算,通過加速張量處理,顯著提高推理和訓(xùn)練性能。借助英特爾 AMX 內(nèi)聯(lián)指令(用于加速計算的單指令多操作),實現(xiàn)了對 ChatGLM 模型中 Attention,Rotary Embedding 等算子的高度優(yōu)化,并且使用 bf16 指令進行乘加操作,在保證浮點指數(shù)位精度的同時提高運算效率。 與此同時,本方案還使用 int8 精度來壓縮全連接層的權(quán)重,在實時計算中將使用bf16進行計算。因此,無需通過訓(xùn)練后量化 (PTQ) 或量化感知訓(xùn)練 (QAT) 對模型進行低精度處理。模型壓縮方法可以降低模型存儲空間,減少內(nèi)存帶寬的負(fù)載,因為計算仍然使用浮點,不會造成溢出,不會對模型精度造成損失。
為 ChatGLM 創(chuàng)建
OpenVINO stateful 模型
請依照下方示例配置軟硬件環(huán)境,并按照以下步驟優(yōu)化 ChatGLM:
硬件要求
第四代英特爾 至強 可擴展處理器(代號 Sapphire Rapids)及后代產(chǎn)品
軟件驗證環(huán)境
Ubuntu 22.04.1 LTS 面向 OpenVINO Runtime Python API 的 Python 3.10.11 用于構(gòu)建 OpenVINO Runtime 的 GCC 11.3.0 cmake 3.26.4
構(gòu)建 OpenVINO 源碼
-
安裝系統(tǒng)依賴并設(shè)置環(huán)境
-
創(chuàng)建并啟用 Python 虛擬環(huán)境

-
安裝 Python 依賴

-
使用 GCC 11.3.0 編譯 OpenVINO
-
克隆 OpenVINO 并升級子模塊

-
安裝 Python 環(huán)境依賴,以構(gòu)建 Python Wheel

-
創(chuàng)建編譯目錄

-
使用 CMake 編譯 OpenVINO
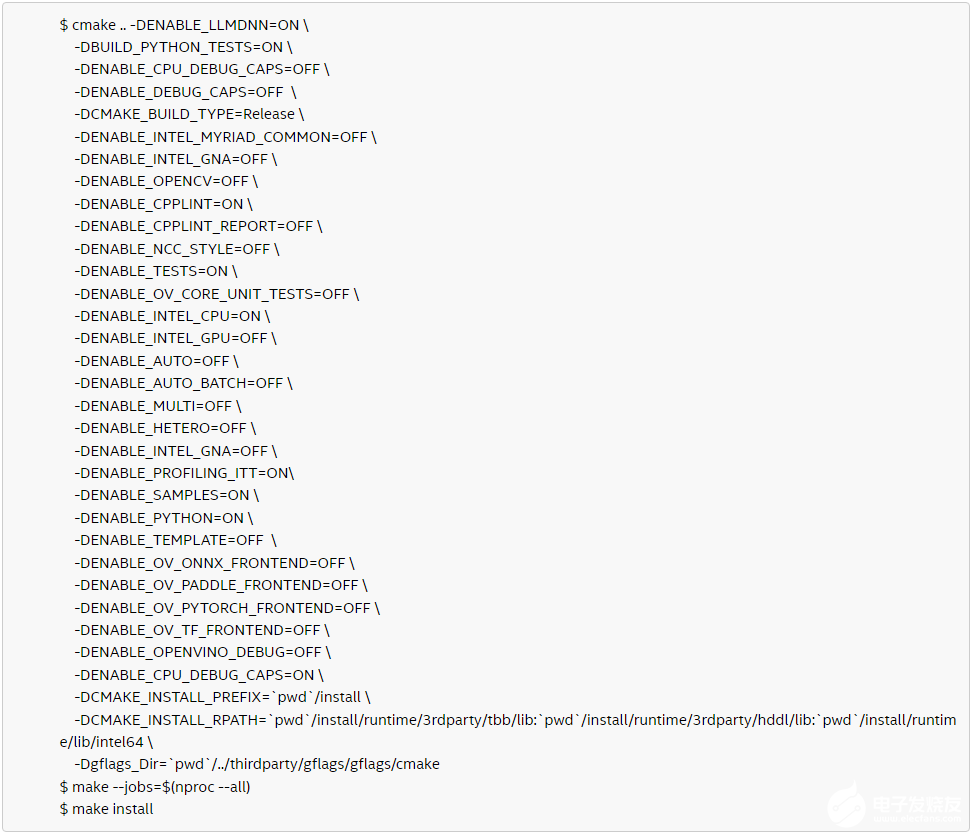
-
安裝針對 OpenVINO Runtime 和 openvino-dev 工具構(gòu)建好的 Python Wheel

-
檢查系統(tǒng) GCC 版本和 Conda Runtime GCC 版本。如下所示,如果系統(tǒng) GCC 版本高于 Conda GCC 版本,請升級 Conda GCC 至相同版本,以滿足 OpenVINO Runtime 的需求。(可選)



-
將 PyTorch 模型轉(zhuǎn)為 OpenVINO IR

使用 OpenVINO Runtime API
為 ChatGLM 構(gòu)建推理流水線
本文提供了使用 Transformer 和 OpenVINO Runtime API 構(gòu)建推理流水線的樣本。首先,在test_chatglm.py中,創(chuàng)建一個由transformers.PreTrainedModel衍生的新類。然后,通過使用 OpenVINO Runtime Python API 構(gòu)建模型推理流水線來更新轉(zhuǎn)發(fā)函數(shù)。其他成員函數(shù)則遷移自modeling_chatglm.py的 ChatGLMForConditionalGeneration。如此一來,即可確保輸入準(zhǔn)備工作、set_random_seed、分詞器/連接器 (tokenizer/detokenizer) 以及余下的流水線操作能夠與原始模型的源碼保持一致。 如需啟用 int8 權(quán)重壓縮,只需設(shè)置簡單的環(huán)境變量 USE_INT8_WEIGHT=1。這是因為在模型生成階段,已使用 int8 對全連接層的權(quán)重進行了壓縮,因此模型可在之后的運行過程中直接使用 int8 權(quán)重進行推理,從而免除了通過框架或量化工具壓縮模型的步驟。 請按照以下步驟使用 OpenVINO Runtime 流水線測試 ChatGLM:
-
運行 bf16 模型

-
運行 int8 模型

權(quán)重壓縮:降低內(nèi)存帶寬使用率
提升推理速度
本文采用了 Vtune 對模型權(quán)重數(shù)值精度分別為 bf16 和 int8 的內(nèi)存帶寬使用率(圖 3 和圖 4)以及 CPI 率進行了性能對比分析(表 1)。結(jié)果發(fā)現(xiàn):當(dāng)模型權(quán)重數(shù)值精度壓縮至 int8 時,可同時降低內(nèi)存帶寬使用率和 CPI 率。
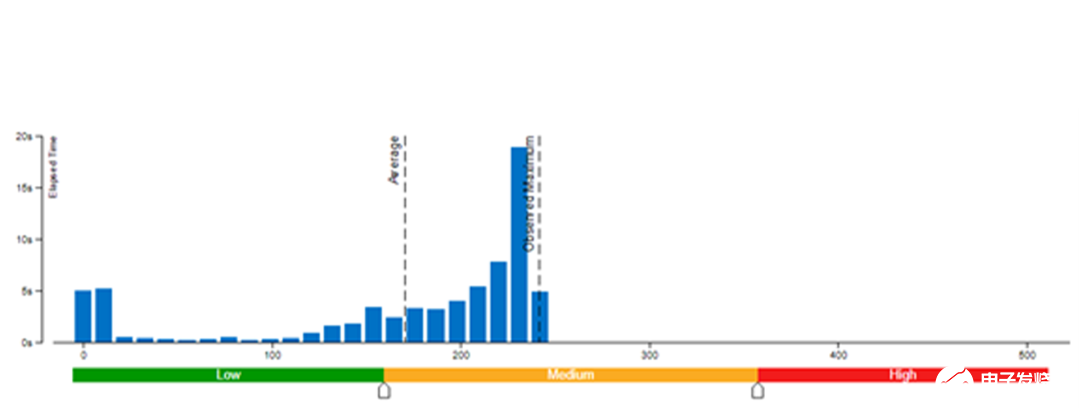
圖 3. 模型權(quán)重數(shù)值精度為 bf16 時的內(nèi)存帶寬使用率
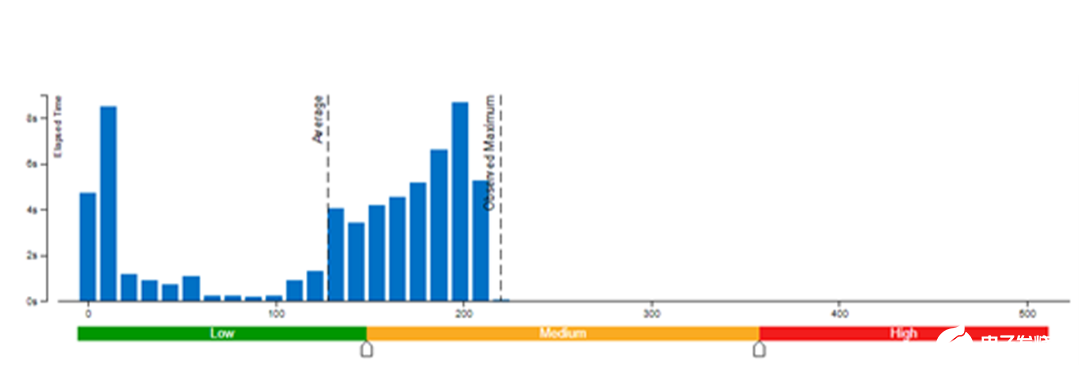
圖 4. 模型權(quán)重數(shù)值精度為 int8 時的內(nèi)存帶寬使用率
|
模型權(quán)重數(shù)值精度 |
bf16 |
int8 |
|
CPI 率 |
10.766 |
1.175 |
每條指令消耗的時鐘周期 (Clockticks per Instruction Retired, CPI) 事件率,也稱為“平均指令周期數(shù) (Cycles per Instruction)”,是基于硬件事件抽樣收集的基礎(chǔ)性能指標(biāo)之一,在抽樣模式下也稱為“性能監(jiān)控計數(shù)器 (PMC) 分析”。該比率計算方式為:用處于非停機狀態(tài)的處理器時鐘周期數(shù) (Clockticks) 除以已消耗指令數(shù)。每個處理器用于計算時鐘周期數(shù)和已消耗指令數(shù)的確切事件可能并不相同,但 VTune Profiler 可辨別和使用正確的數(shù)量。 CPI < 1 時,通常為采用指令密集型代碼的應(yīng)用,而 CPI > 1 則可能是停滯時鐘周期密集型應(yīng)用,也可能是內(nèi)存密集型應(yīng)用。由此,我們可以得出結(jié)論,類似 chatGLM 等語言模型對內(nèi)存帶寬的要求非常高,性能往往受到內(nèi)存操作或帶寬的限制。很多場景下,消除內(nèi)存操作的負(fù)載,性能會因此獲得大幅收益。在優(yōu)化此類模型時,如何在不影響精度的同時對模型進行壓縮或輕量化處理是一項不可或缺的技巧。除此之外,在異構(gòu)平臺和框架上進行部署,還涉及到減少內(nèi)存/設(shè)備存儲之間的數(shù)據(jù)搬運等優(yōu)化思路。因此,在壓縮模型的同時,還需要考慮對原始 pytorch 模型推理 forward/generates 等函數(shù)流水線的優(yōu)化,而 OpenVINO 在優(yōu)化模型自身的同時,還將流水線的優(yōu)化思路體現(xiàn)在修改模型結(jié)構(gòu)中(將 KV cache保存在模型內(nèi)部),通過優(yōu)化 Optimum-intel 等框架的流水線,減少內(nèi)存拷貝和數(shù)據(jù)搬運。
結(jié) 論
筆者根據(jù)上述方法重新設(shè)計執(zhí)行圖并優(yōu)化了 GLMBlock,消除了 ChatGLM 模型輸入和輸出之間的內(nèi)存副本,且模型運行高效。隨著 OpenVINO 的不斷升級,本方案的優(yōu)化工作也將得到推廣并集成至正式發(fā)布的版本中。這將有助于擴展更多的大語言模型用例。敬請參考 OpenVINO 官方版本3 和 Optimum-intel OpenVINO 后端4,獲取有關(guān)大語言模型的官方高效支持。
作者簡介:
英特爾OpenVINO 開發(fā)工具客戶支持工程師趙楨和鄒文藝,英特爾 OpenVINO 開發(fā)工具 AI 框架工程師羅成和李亭騫,都在從事 AI 軟件工具開發(fā)與優(yōu)化工作。
-
英特爾
+關(guān)注
關(guān)注
61文章
10168瀏覽量
173932 -
cpu
+關(guān)注
關(guān)注
68文章
11037瀏覽量
216006
原文標(biāo)題:一個簡單模型就讓ChatGLM性能大幅提升 | 最“in”大模型
文章出處:【微信號:英特爾中國,微信公眾號:英特爾中國】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
如何將一個FA模型開發(fā)的聲明式范式應(yīng)用切換到Stage模型
首創(chuàng)開源架構(gòu),天璣AI開發(fā)套件讓端側(cè)AI模型接入得心應(yīng)手
添越智創(chuàng)基于 RK3588 開發(fā)板部署測試 DeepSeek 模型全攻略
【「基于大模型的RAG應(yīng)用開發(fā)與優(yōu)化」閱讀體驗】+第一章初體驗
【「基于大模型的RAG應(yīng)用開發(fā)與優(yōu)化」閱讀體驗】+大模型微調(diào)技術(shù)解讀
AI模型部署邊緣設(shè)備的奇妙之旅:目標(biāo)檢測模型
【「大模型啟示錄」閱讀體驗】如何在客服領(lǐng)域應(yīng)用大模型
什么是大模型、大模型是怎么訓(xùn)練出來的及大模型作用

如何通過OSI七層模型優(yōu)化網(wǎng)絡(luò)性能
使用vLLM+OpenVINO加速大語言模型推理

為THS3001構(gòu)建一個簡單的SPICE模型

AI大模型的性能優(yōu)化方法
chatglm2-6b在P40上做LORA微調(diào)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論