") TPU-MLIR中的融合處理
TPU-MLIR中的融合處理
通常,模型的輸入是 預處理過的NCHW 格式的張量,但有時我們可能希望直接將原始圖像輸入模型。 在這種情況下,我們需要將預處理操作作為模型的一部分。我們目前支持這些類型的圖像輸入,它們對應不同的像素和通道格式。 其中一些是專門針對 CV 系列芯片的,所以這部分我們暫且先不深入探討。
對于預處理類型,我們目前可以做一些典型的預處理操作,包括中心裁剪、轉(zhuǎn)置、像素格式變換和歸一化,更多類型的操作會在未來完成。
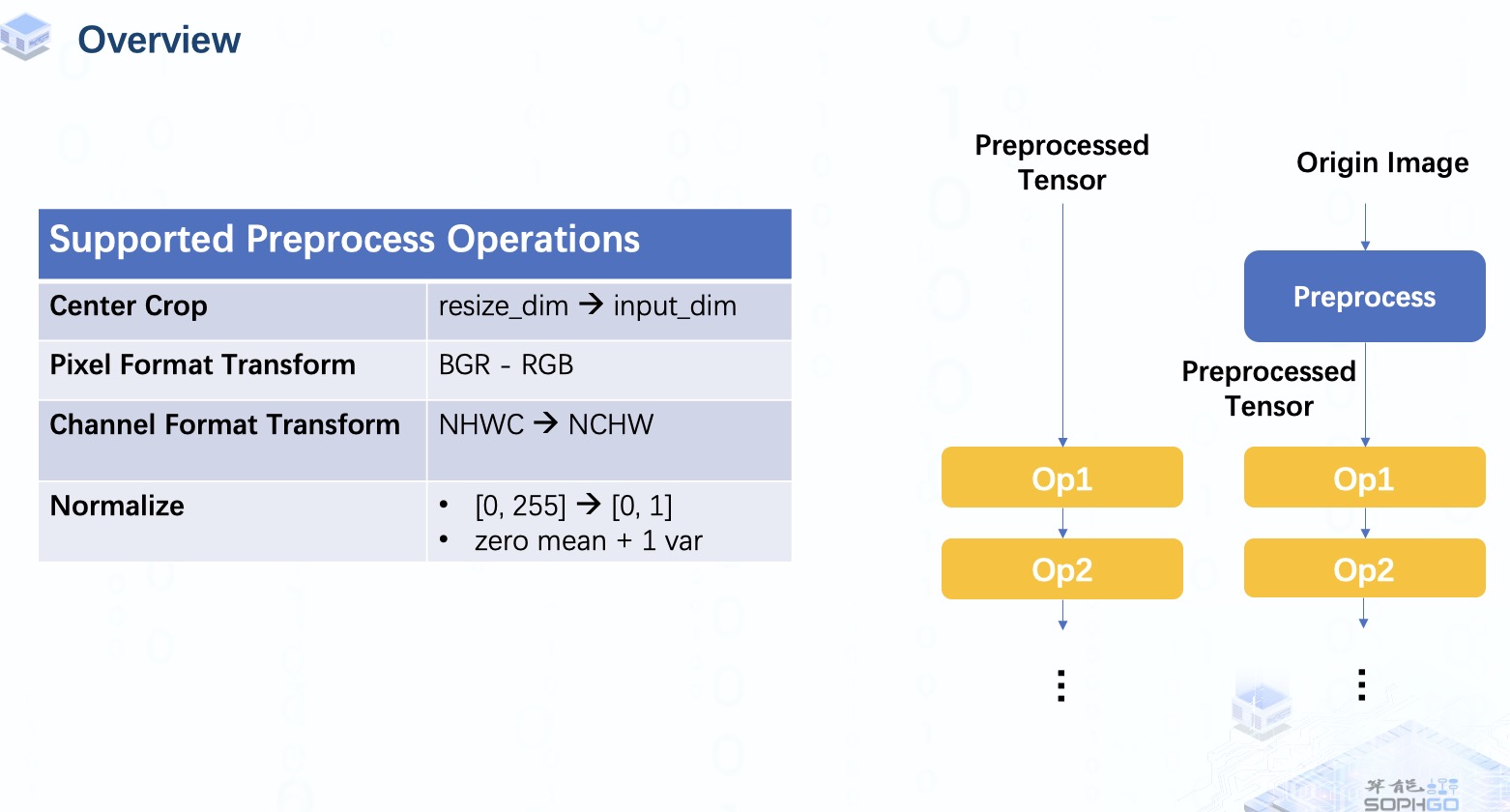
那么,我們怎樣才能得到一個包含預處理操作的bmodel呢?
首先,我們像往常一樣進行 model_transform 以獲得Top層的mlir 文件。但是在 model_deploy 步驟中,我們需要指定 fuse-preprocess 參數(shù)。 一旦指定了這個參數(shù),test_input 應該是一個圖像而不是 numpy 數(shù)組。對于自定義格式,如果不指定,它會被默認設(shè)置為和preprocesse infor一致。
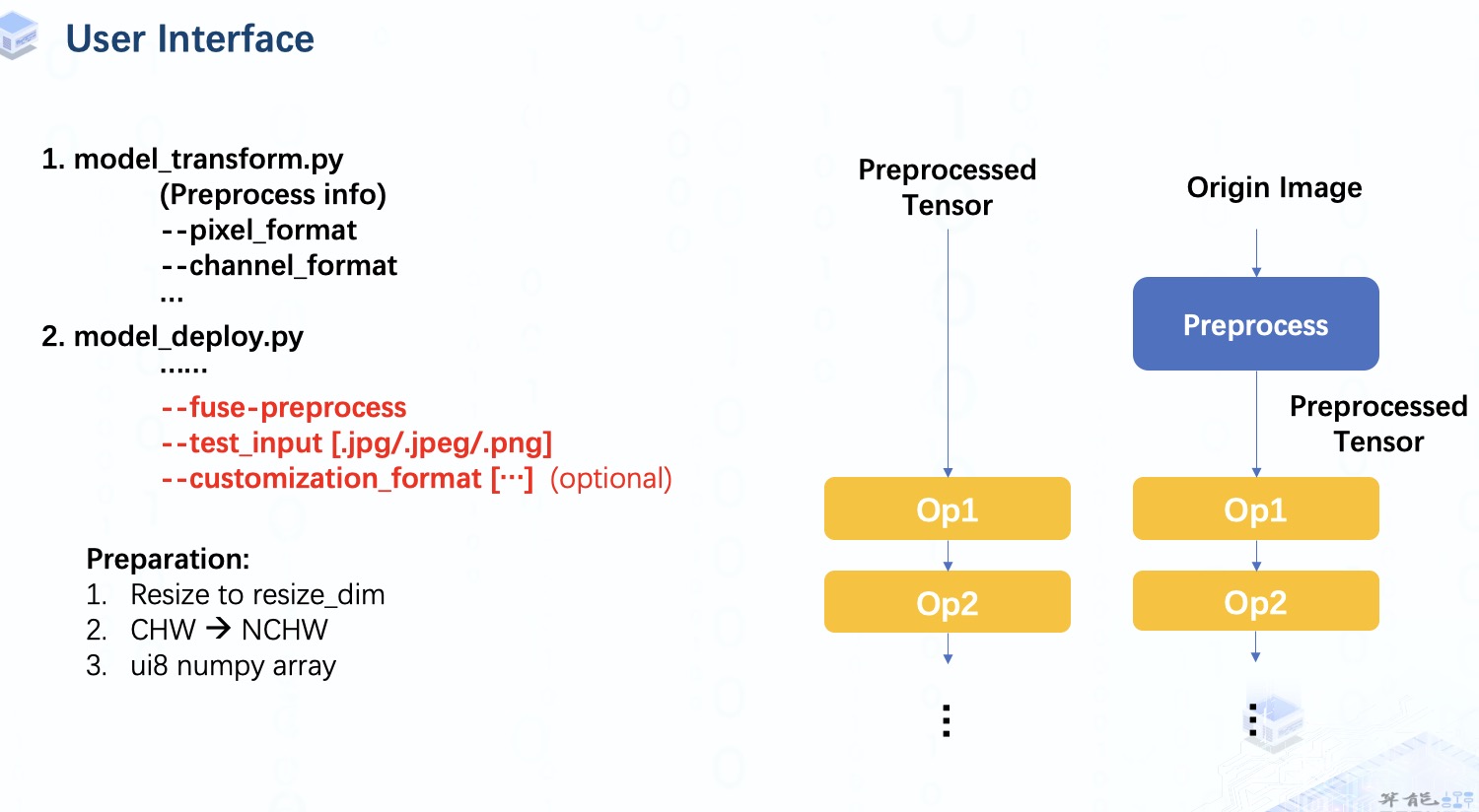
在我們將它提供給模型之前,我們?nèi)匀恍枰獙D像數(shù)據(jù)做一些工作,包括:
調(diào)整圖像到指定尺寸。
將數(shù)據(jù)擴展為4維。
并轉(zhuǎn)換為ui8 numpy 數(shù)組。這里數(shù)據(jù)格式是 unsinged int8,因為像素值范圍是0到255的整數(shù)值。
通過運行帶有 fuse-preprocess 參數(shù)的 model_deploy 接口,TPU-MLIR 將從 inputOp 收集所有必要的預處理和校準信息,然后將它們保存在 InputOp 之后的 preprocessOp 中。
如果沒有提供校準表,這意味著我們得到一個不需要任何校準信息的純浮點型bmodel,在這種情況下我們實際上也不需要任何校準信息。
接下來,我們會對InputOp進行修改,特別是Type,由于模型的輸入是unsigned INT8張量,所以我們需要將其設(shè)置為ui8的均勻量化類型。 您會發(fā)現(xiàn)量化參數(shù)只是單純設(shè)置為 1,因為我們將真實的校準信息保存在preprocessOp中了。接著,func type也要修改,以保證其和inputOp的Type一致。完成所有這些工作后,該模型的輸入現(xiàn)在已修改為圖像。

這里我們便可以開始lower到 Tpu Dialect。
在這個階段,如果我們處于F32等浮點量化模式,在 InputOp 之后會插入一個 CastOp,將數(shù)據(jù)從整數(shù)轉(zhuǎn)換為浮點數(shù),以確保類型的一致性。由于 inputOp 的量化參數(shù)已經(jīng)被設(shè)置為 1。對于 f32,我們就相當于只是單純進行類型轉(zhuǎn)換。
接下來,我們將開始插入算子,首先在模型中設(shè)置插入點,然后在輸入圖像為NHWC格式時插入permuteOp。當resize_dim與模型輸入形狀不同時,SliceOp 會被用來進行裁剪的工作。
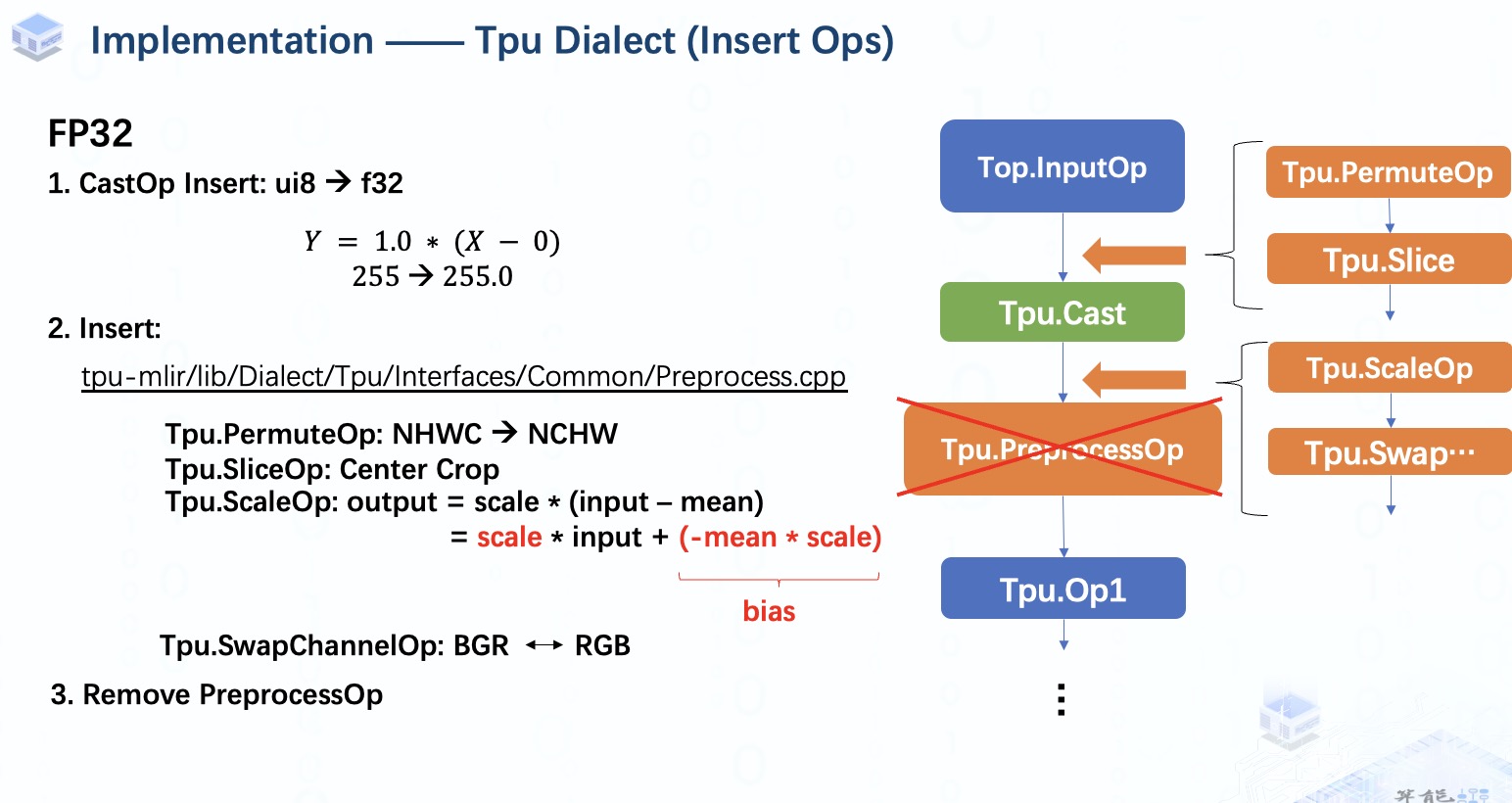
之后我們會在CastOp后設(shè)置一個新的插入點,ScaleOp在這里會被用來完成歸一化操作。然后,我們還將添加 swapChannelOp 以進行 RGB 和 BGR之間的轉(zhuǎn)換。完成所有算子插入工作后,我們將刪除 preprocessOp,它就像一個占位符一樣,利用完后就該跟它說再見了。
但是預處理融合工作還沒有完成,這里我們還可以做一些優(yōu)化。
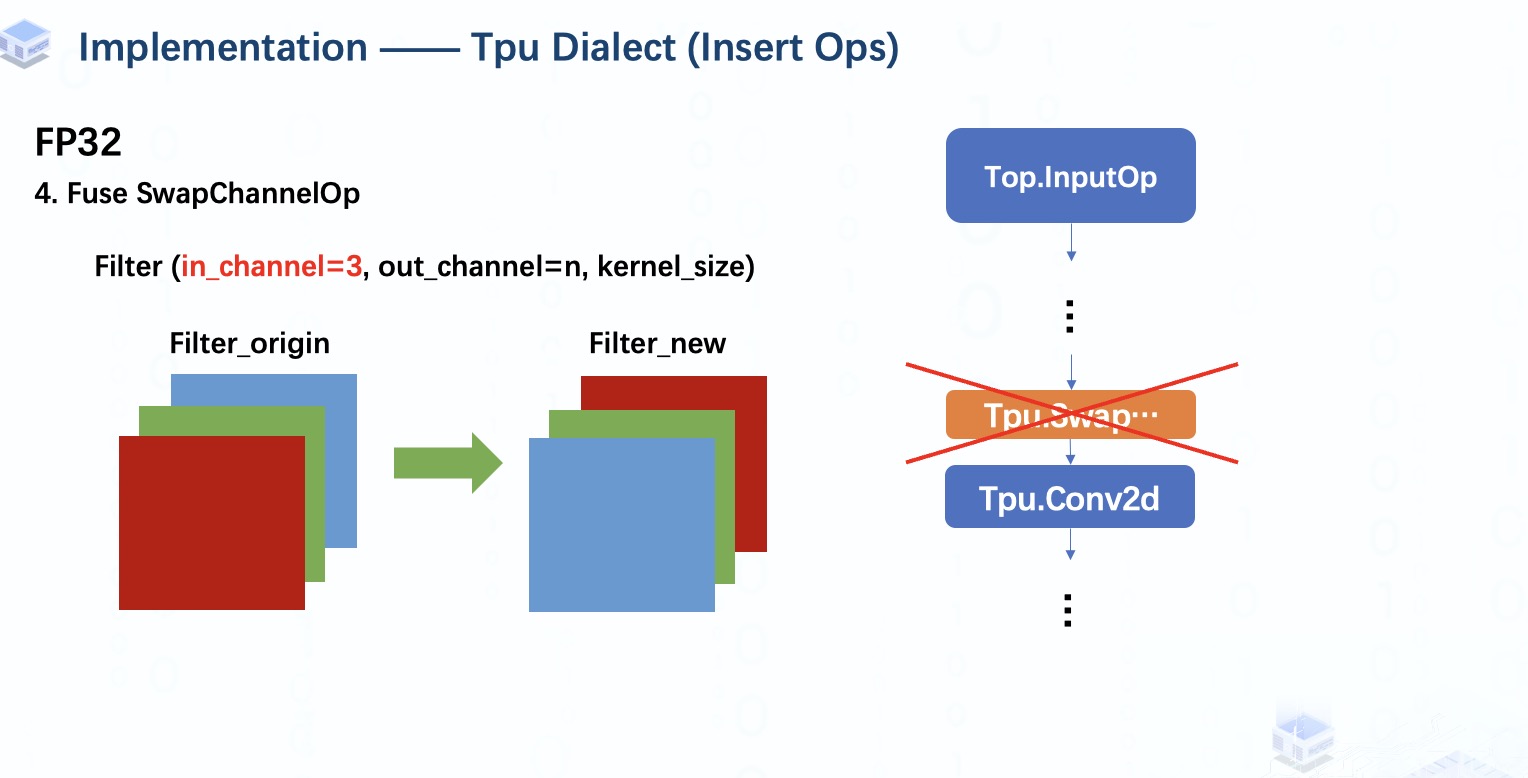
如果模型原本的第一個算子是Conv2d,那么其filter的輸入通道一定是3,對應輸入圖像數(shù)據(jù)的3個顏色通道。
所以我們可以通過簡單地轉(zhuǎn)換filter的輸入通道來替換swapChannelOp。至此,預處理工作結(jié)束。
在INT8 量化模式下,情況就有點不同了,
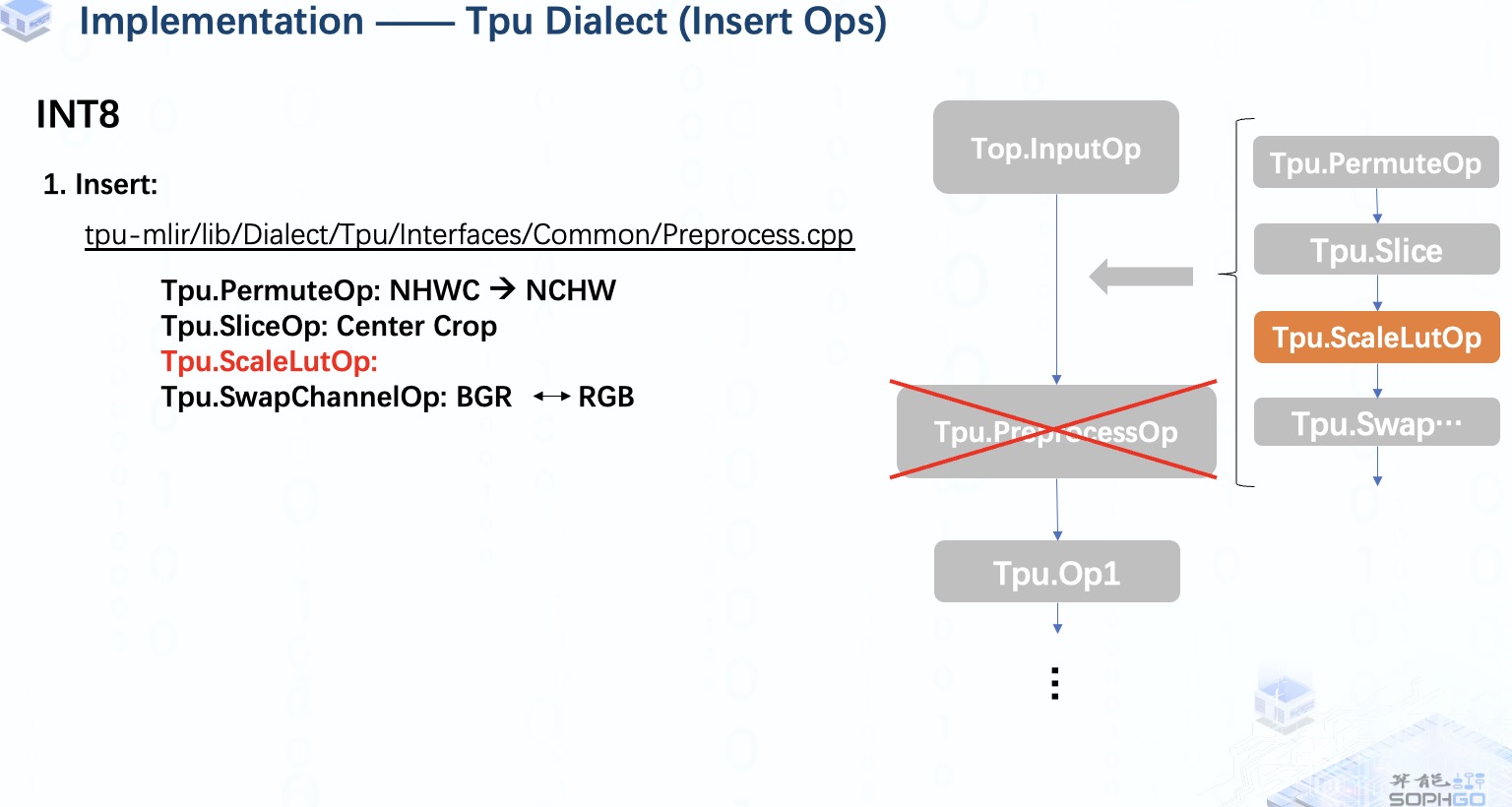
首先,因為所有操作都是int8類型,所以不會有CastOp被插入。
其次,因為我們想對int8數(shù)據(jù)進行歸一化操作,并且結(jié)果仍然是 int8,所以我們將插入 scalelutOp 而不是 scaleOp。
ScaleLutOp 就像我們在用查找表的方式進行均勻量化,也就是說我們預先計算出所有 256 個可能的量化結(jié)果并保存在表中,然后我們可以在推理時直接從表中得到結(jié)果。
但是由于我們有 3 對mean和scale,所以我們必須創(chuàng)建3個表來對每個通道的元素分別進行量化。

需要注意的一點是,當所有均值為零時,我們假設(shè)它是unsigned int8量化,否則我們就做signed int8量化。
當然,有時候我們會遇到所有scales_new都等于1,所有means都為0的情況。 在這種情況下,ScalelutOp 實際上對輸入數(shù)據(jù)什么都不做,所以我們將跳過這個插入部分。

另外,在TPU-MLIR中我們也可能會使用mix precision模式,比如在int8量化模式下對原始的首個OP做浮點運算或者在FP量化模式下對原始的首個OP做INT8運算。
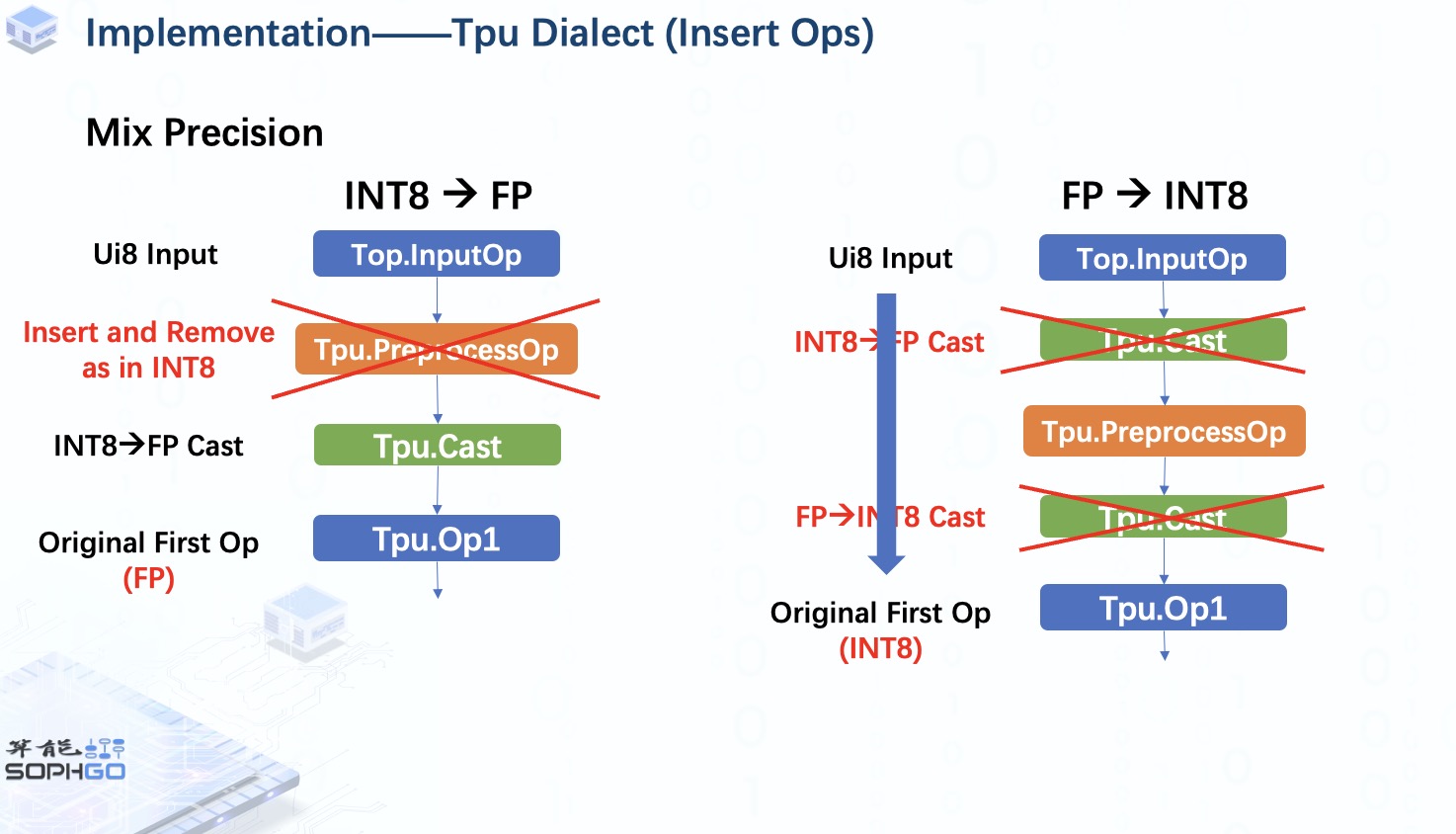
在前者中,將在 preprocessOp 和原始第一個 op 之間插入一個 CastOp,以將 INT8 數(shù)據(jù)轉(zhuǎn)換為FP,對于這種情況,fuse preprocess步驟將與 int8 量化模式下相同。
但是對于后者,我們可以看到兩個CastOp的作用其實相互抵消了,所以我們可以將它們刪除并再次像 int8量化模式一樣進行fuse preprocess操作。
審核編輯:湯梓紅
-
芯片
+關(guān)注
關(guān)注
459文章
52091瀏覽量
435382 -
預處理
+關(guān)注
關(guān)注
0文章
33瀏覽量
10598 -
TPU
+關(guān)注
關(guān)注
0文章
151瀏覽量
21062
發(fā)布評論請先 登錄
yolov5量化INT8出錯怎么處理?
TPU-MLIR開發(fā)環(huán)境配置時出現(xiàn)的各種問題求解
【算能RADXA微服務器試用體驗】+ GPT語音與視覺交互:2,圖像識別
TPU透明副牌.TPU副牌料.TPU抽粒廠.TPU塑膠副牌.TPU再生料.TPU低溫料
TPU副牌低溫料.TPU熱熔料.TPU中溫料.TPU低溫塑膠.TPU低溫抽粒.TPU中溫塑料
在“model_transform.py”添加參數(shù)“--resize_dims 640,640”是否表示tpu會自動resize的?

TPU-MLIR量化敏感層分析,提升模型推理精度

如何適配新架構(gòu)?TPU-MLIR代碼生成CodeGen全解析!
深入學習和掌握TPU硬件架構(gòu)有困難?TDB助力你快速上手!
如何高效處理LMEM中的數(shù)據(jù)?這篇文章帶你學會!
基于TPU-MLIR:詳解EinSum的完整處理過程!





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論