") 智能化編碼面臨的算力瓶頸 如何利用CPU解決全鏈路智能編碼?
智能化編碼面臨的算力瓶頸 如何利用CPU解決全鏈路智能編碼?
智能化編碼面臨的算力瓶頸
圖中是一個(gè)視頻轉(zhuǎn)碼推流的一般性流程圖。主播將視頻上傳到上行CDN,然后再由視頻處理中心進(jìn)行各種前處理,包括內(nèi)容理解,審核,編輯,增強(qiáng)和超分,然后進(jìn)行編碼,再推送到下行CDN,供觀眾觀看。
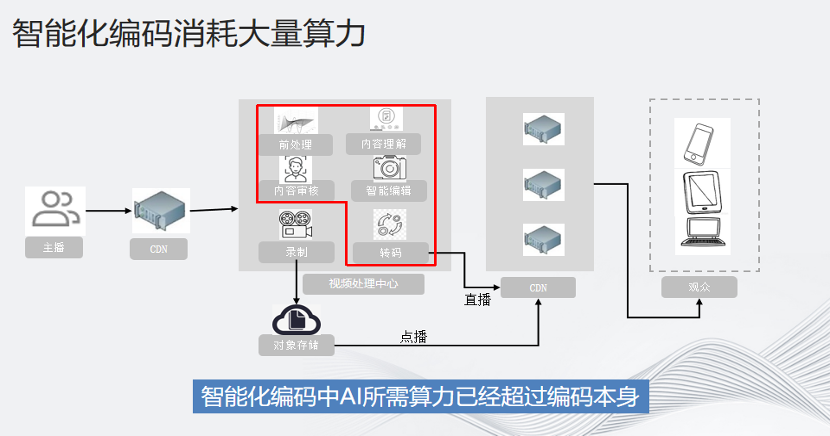
紅色框部分都是和AI相關(guān)的部分。智能化編碼中,AI所需算力已經(jīng)超過編碼本身。1080p的數(shù)據(jù)超成4K,編碼只需要20幾個(gè)物理核,但是如果要超分,就需要一張GPU卡。一張GPU卡5000塊一個(gè)月,對比下來成本優(yōu)勢一目了然。
根據(jù)相關(guān)視頻企業(yè)公開的財(cái)報(bào),視頻轉(zhuǎn)碼和帶寬的成本占到公司全年收入的10%左右。隨著AIGC的發(fā)展,未來肯定不局限于10%,因此成本問題是我們的痛點(diǎn)之一。
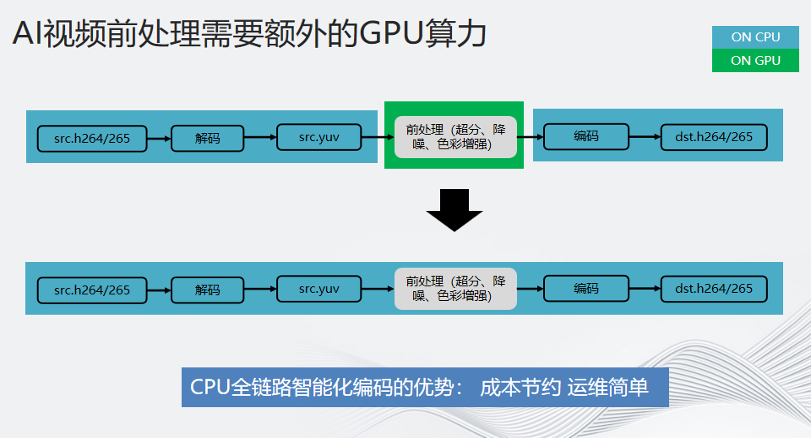
CPU全鏈路智能化編碼的優(yōu)勢就在于成本節(jié)約,運(yùn)維簡單。下面舉一個(gè)更具體的例子:
我們都知道轉(zhuǎn)碼方式有很多種,但CPU有兩個(gè)不可替代的優(yōu)勢:1.高靈活性;2.高復(fù)用性。CPU的升級(jí)幾乎沒有成本,只需升級(jí)一下軟件部分即可,以云為基礎(chǔ),申請一個(gè)虛擬主機(jī),無論是docker還是container都可以隨用隨放,十分自由靈活,成本很低。
由于超分部分對算力的要求非常高,需要通過GPU來輔助,但同時(shí)也會(huì)引發(fā)一些問題:客戶將高要求的AI負(fù)載遷移到GPU上,將編碼和前處理完全分離。這就像在一間屋子里解碼——發(fā)送到另一間屋子進(jìn)行前處理——再轉(zhuǎn)回來編碼。這不僅讓流程變得冗長,也對運(yùn)維造成了極大負(fù)擔(dān),數(shù)據(jù)的反復(fù)調(diào)度也造成了一定時(shí)延的增加。
CPU全鏈路智能化編碼正是解決了這一痛點(diǎn)。
英特爾第四代至強(qiáng)可擴(kuò)展處理器及AMX賦能智能化編碼
接下來會(huì)介紹英特爾第四代至強(qiáng)可擴(kuò)展處理器及其內(nèi)置的AI加速器AMX,以及如何利用AMX和英特爾成熟的軟件棧和工具鏈幫助視頻編解碼工作者,打造全鏈路智能化編碼。
據(jù)最新的統(tǒng)計(jì)數(shù)據(jù),英特爾至強(qiáng)服務(wù)器在中國市場的數(shù)據(jù)中心的占有率保持在80%以上,可以說至強(qiáng)服務(wù)器是數(shù)據(jù)中心的基石。第四代至強(qiáng)一個(gè)重要的革新就是內(nèi)置了數(shù)個(gè)硬件加速器,用于不同應(yīng)用場景的性能加速,例如之前需要外置的PCIE插卡就已經(jīng)內(nèi)置在CPU內(nèi)部。
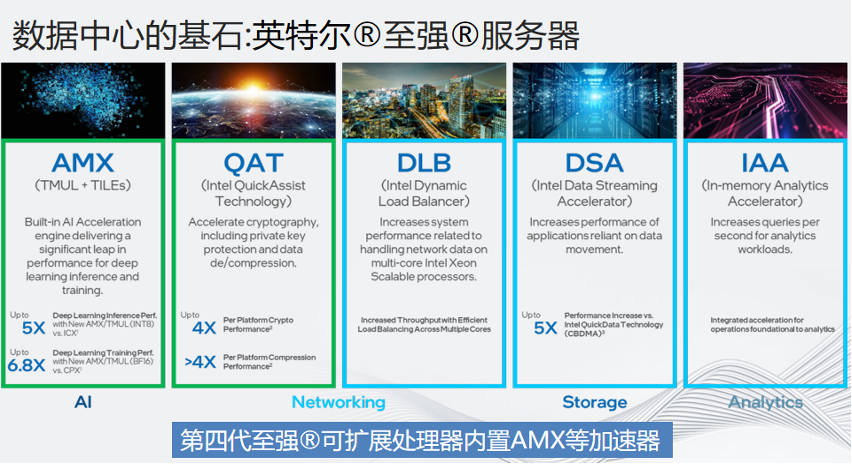
從左往右第一個(gè)AMX適用于AI;QAT負(fù)責(zé)壓縮、解壓和加解密;DLB負(fù)責(zé)Load Balance,CDN負(fù)責(zé)負(fù)載均衡,自動(dòng)dispatch到閑散的資源上;DSA負(fù)責(zé)內(nèi)存拷貝,不需要CPU參與,異步拷貝不僅速度快,而且不占用CPU內(nèi)存;IAA負(fù)責(zé)存內(nèi)分析,更多和數(shù)據(jù)庫相關(guān),IAA可以在不解壓數(shù)據(jù)的情況下分析數(shù)據(jù)。
AMX的全稱是Advanced Matrix eXensions,高級(jí)矩陣擴(kuò)展指令集。它在AVX512的基礎(chǔ)之上做了進(jìn)一步的擴(kuò)展。AMX有兩個(gè)核心思想,一個(gè)是Tiles,一個(gè)是Timo。Tiles是物理上兩地寄存器的疊加,16個(gè)AVX512疊加在一塊。Timo是針對兩地Tiles的矩陣運(yùn)算。最新的至強(qiáng)每一顆物力核上都有一個(gè)內(nèi)置的AMX,充當(dāng)AI 的加速卡。
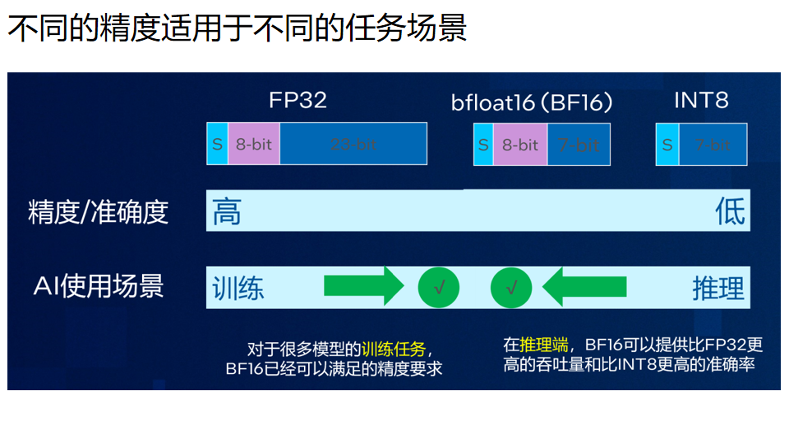
和大多數(shù)加速卡一樣,AMX加速的是量化精度。目前第四代至強(qiáng)支持的是BF16和INT8,未來也會(huì)很快支持FP8和FP16。BF16的表達(dá)范圍和FP32一模一樣,只是精度比FP32小一點(diǎn)。目前絕大多數(shù)的場景,BF16已經(jīng)足夠。對于訓(xùn)練來說FP16足矣,而推理則只需要INT8。
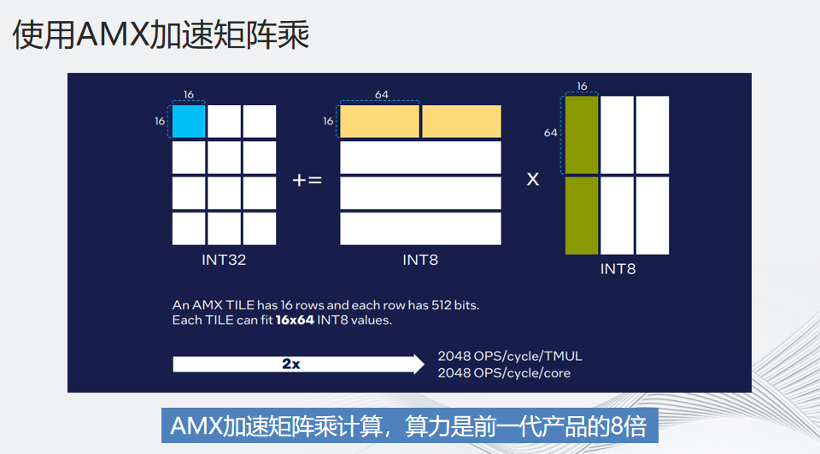
AMX是如何加速矩陣乘的呢?我們在做大的矩陣時(shí)可以把矩陣拆成16*64,然后一次性計(jì)算。如果算力不夠,可以用oneDNN和MLKDNN處理,而AMX加速矩陣乘計(jì)算,算力是前一代產(chǎn)品的8倍。
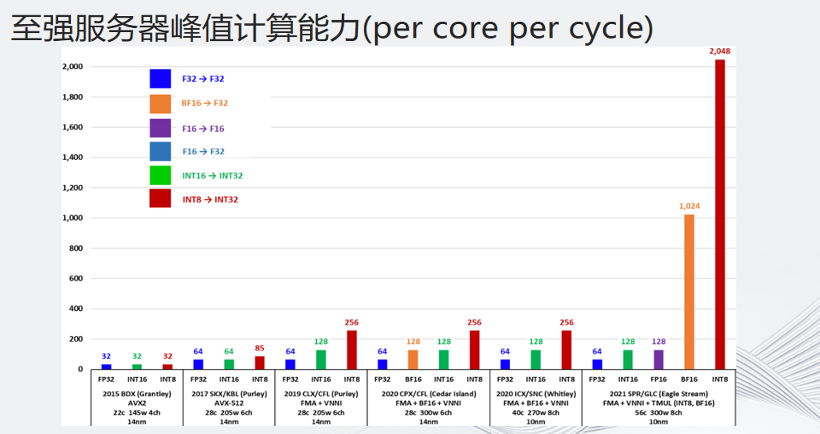
這張圖是至強(qiáng)服務(wù)器峰值計(jì)算能力的演進(jìn)過程。從2019年開始的第二代至強(qiáng)可擴(kuò)展處理器支持VNNI,最新發(fā)布的第四代至強(qiáng)可擴(kuò)展處理器支持AMX,可以看到每個(gè)指令周期的計(jì)算能力得到8倍的提升。
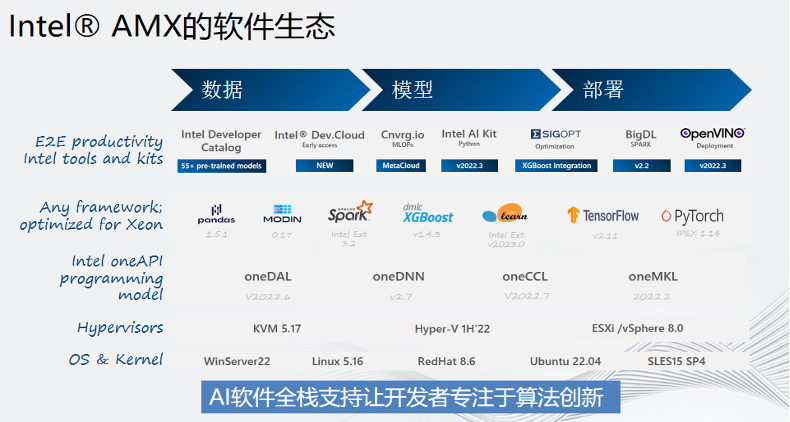
硬件性能只是一方面,軟件生態(tài)某種意義上說對開發(fā)者來說更為關(guān)鍵。這是一張英特爾 AMX的軟件生態(tài)圖,從下往上,從最底層的操作系統(tǒng)到虛擬化KVM、HyperV,再到核心AI計(jì)算庫都是英特爾開發(fā)的。在框架層面,主流的TF和PyTorch也都包含在內(nèi),除此之外英特爾還提供了豐富的推理工具。這些成熟的軟件生態(tài)使得我們的開發(fā)者可以專注于算法創(chuàng)新,而不用考慮如何部署等細(xì)節(jié),開箱即用。
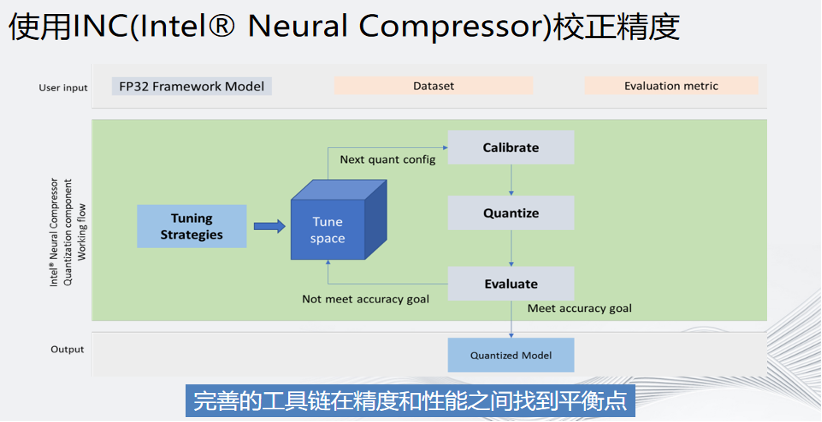
BF16和INT8的高算力對將AI從GPU遷到CPU之上確實(shí)有很大的幫助,但如何保證精度呢?英特爾有一個(gè)工具叫做INC,內(nèi)置了很多專門用于精度的校正算法。作為開發(fā)者,只需要做三件事:輸入模型、輸入數(shù)據(jù)集和輸入精度要求即可。INC會(huì)根據(jù)客戶的輸入進(jìn)行tuning,直到有一個(gè)用戶滿意的算法。如果最終達(dá)不到設(shè)定的精度要求,還可以對某些層進(jìn)行回滾,從而保證設(shè)定的精度可以達(dá)到要求。
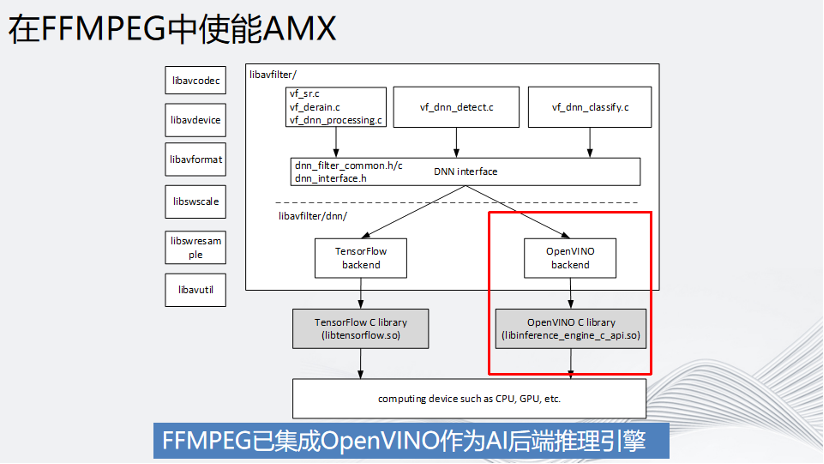
回到視頻編解碼領(lǐng)域,我們知道視頻前處理是在FFmpeg解碼之后,對YUV或者RGB數(shù)據(jù)進(jìn)行處理,處理結(jié)束后再送到編碼器x264或者x265編碼。由于整個(gè)pipeline中,數(shù)據(jù)的處理速度并不一致,因此為了讓整個(gè)過程的數(shù)據(jù)順滑地流動(dòng)起來,就需要做一部分的改造,比如解碼后的raw data放入一個(gè)buffer隊(duì)列中,AI推理異步從這個(gè)隊(duì)列中取數(shù)據(jù)做推理,并把推理后的結(jié)果送到編碼器中,這需要一定量針對FFmpeg的開發(fā)工作。
幸運(yùn)的是,英特爾已經(jīng)幫用戶做好了。FFmpeg中有一個(gè)英特爾的OpenVINO后端,用戶直接使用就行。FFmpeg的DNN AI推理后端,目前只支持2個(gè)后端,一個(gè)是Tensorflow,另外一個(gè)就是英特爾的OpenVINO。
總結(jié):FFmpeg已經(jīng)集成了OpenVINO作為AI 的后端推理引擎且英特爾有專門的團(tuán)隊(duì)去維護(hù),大家可以放心使用。
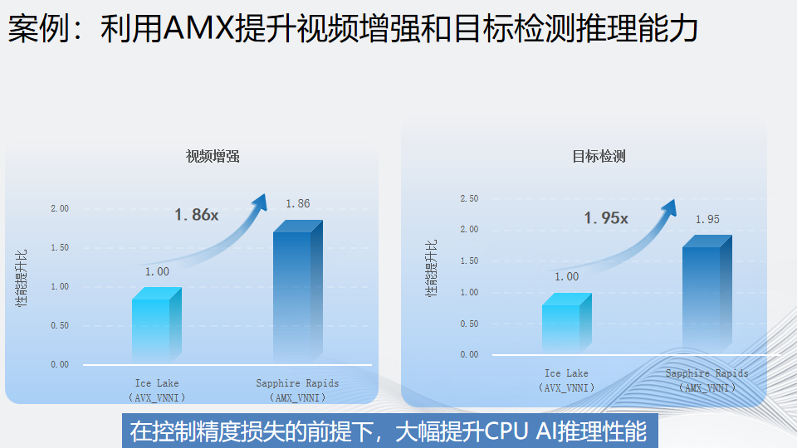
這是一個(gè)和合作伙伴的實(shí)際案例。在視頻增強(qiáng)和目標(biāo)檢測這兩個(gè)場景下,使用了英特爾第四代至強(qiáng)可擴(kuò)展處理器AMX優(yōu)化的AI推理性能相對上一代平臺(tái)分別提升了1.86倍和1.95倍。與此同時(shí),精度損失被控制在可接受的范圍,這也使得英特爾的客戶在CPU上實(shí)現(xiàn)了全鏈路智能化編碼,大幅降低了部署成本和運(yùn)維成本。
審核編輯:劉清
-
處理器
+關(guān)注
關(guān)注
68文章
19811瀏覽量
233603 -
編碼器
+關(guān)注
關(guān)注
45文章
3775瀏覽量
137195 -
DSA
+關(guān)注
關(guān)注
0文章
51瀏覽量
15494 -
硬件加速器
+關(guān)注
關(guān)注
0文章
42瀏覽量
12996 -
GPU芯片
+關(guān)注
關(guān)注
1文章
305瀏覽量
6124
原文標(biāo)題:面對算力瓶頸,如何利用CPU解決全鏈路智能編碼?
文章出處:【微信號(hào):livevideostack,微信公眾號(hào):LiveVideoStack】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
精準(zhǔn)定位 高效驅(qū)動(dòng)丨基于極海APM32E030的磁電式絕對值編碼器參考方案,加速工業(yè)智能化轉(zhuǎn)型

智能算力基建:RAKsmart如何賦能下一代AI開發(fā)工具
點(diǎn)動(dòng)科技戰(zhàn)略聚焦AI智算,領(lǐng)航算力服務(wù)新征程
智能家居Mesh組網(wǎng)方案:實(shí)現(xiàn)智能化生活的無縫連接NRF52832
智能算力最具潛力的行業(yè)領(lǐng)域

工業(yè)4.0革命利器!明遠(yuǎn)智睿SSD2351核心板:低成本+高算力,破解產(chǎn)線智能化難題
國產(chǎn)化算力新標(biāo)桿!卓怡恒通EPC-S4450邊緣AI工控機(jī)開啟工業(yè)智能新紀(jì)元

云 GPU 加速計(jì)算:突破傳統(tǒng)算力瓶頸的利刃
智能化如何讓汽車產(chǎn)業(yè)鏈加速變革?

算智算中心的算力如何衡量?

MT6501 磁編碼 IC:推動(dòng)智能倉儲(chǔ)系統(tǒng)與自動(dòng)穿梭車的應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論