") 基于PoseDiffusion相機(jī)姿態(tài)估計(jì)方法
基于PoseDiffusion相機(jī)姿態(tài)估計(jì)方法
介紹
一般意義上,相機(jī)姿態(tài)估計(jì)通常依賴(lài)于如手工的特征檢測(cè)匹配、RANSAC和束調(diào)整(BA)。在本文中,作者提出了PoseDiffusion,這是一種新穎的相機(jī)姿態(tài)估計(jì)方法,它將深度學(xué)習(xí)與基于對(duì)應(yīng)關(guān)系的約束結(jié)合在一起,因此能夠在稀疏視圖和密集視圖狀態(tài)下以高精度重建相機(jī)位置,他們?cè)诟怕蕯U(kuò)散框架內(nèi)公式化了SfM問(wèn)題,對(duì)給定輸入圖像的相機(jī)姿態(tài)的條件分布進(jìn)行建模,用Diffusion模型來(lái)輔助進(jìn)行姿態(tài)估計(jì)。在兩個(gè)真實(shí)世界的數(shù)據(jù)集上證明了其方法比經(jīng)典的SfM中的姿態(tài)估計(jì)和基于學(xué)習(xí)的方法有顯著的改進(jìn),同時(shí)可以在不需要進(jìn)一步訓(xùn)練的情況下在數(shù)據(jù)集之間進(jìn)行泛化。
明確一下,該方法同時(shí)估計(jì)相機(jī)內(nèi)外參,不同于視覺(jué)定位(估計(jì)相機(jī)外參,即旋轉(zhuǎn)矩陣R和平移向量t)。
什么是擴(kuò)散模型?
擴(kuò)散模型是一類(lèi)生成模型,受非平衡熱力學(xué)的啟發(fā),通過(guò)擴(kuò)散步驟的馬爾可夫鏈近似數(shù)據(jù)分布,在圖像、視頻,3D點(diǎn)云生成方面都取得了令人印象深刻的成果。它們能夠準(zhǔn)確生成各種高質(zhì)量的樣本。
擴(kuò)散模型的目標(biāo)是通過(guò)捕捉從數(shù)據(jù)到簡(jiǎn)單分布的擴(kuò)散過(guò)程的逆過(guò)程來(lái)學(xué)習(xí)復(fù)雜的數(shù)據(jù)分布,通常是通過(guò)加噪聲和去噪來(lái)實(shí)現(xiàn)。加噪聲處理通過(guò)一系列步驟將數(shù)據(jù)樣本x逐漸轉(zhuǎn)換為噪聲,然后對(duì)模型進(jìn)行訓(xùn)練以學(xué)習(xí)去噪過(guò)程。
去噪擴(kuò)散概率模型(DDPM)專(zhuān)門(mén)將噪聲處理定義為高斯。給定T個(gè)步驟的方差表,噪聲變換定義如下:
方差表被設(shè)置為使得xT遵循各向同性高斯分布,即。定義αt=1?βt和,則存在一個(gè)閉式解,在給定數(shù)據(jù)x0的情況下直接對(duì)xt進(jìn)行采樣:
如果βt足夠小,則反向仍然是高斯的。因此,它可以通過(guò)模型Dθ來(lái)近似:
為什么可以使用擴(kuò)散模型來(lái)進(jìn)行姿態(tài)估計(jì)任務(wù)?
一方面擴(kuò)散模型在建模復(fù)雜分布(例如,在圖像、視頻和點(diǎn)云上)方面都取得了成功,另一方面擴(kuò)散模型的隨機(jī)采樣過(guò)程已被證明可以有效地駕馭復(fù)雜分布的對(duì)數(shù)似然,因此非常適合復(fù)雜的BA優(yōu)化。擴(kuò)散過(guò)程的另一個(gè)好處是,它可以一步一步地訓(xùn)練,而不需要在整個(gè)優(yōu)化過(guò)程中展開(kāi)梯度。
方法
基于擴(kuò)散模型的Bundle Adjustment(BA)
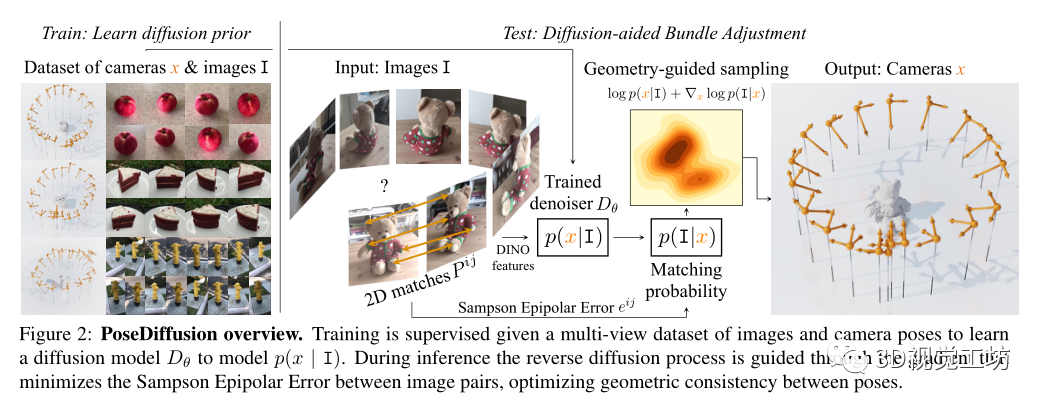
PoseDiffusion對(duì)給定圖像I的樣本x(即相機(jī)參數(shù))的條件概率分布p(x|I)進(jìn)行建模。根據(jù)擴(kuò)散模型(如上所述),通過(guò)去噪過(guò)程對(duì)p(x| I)進(jìn)行建模,更具體地說(shuō),p(x|I)首先通過(guò)在N個(gè)場(chǎng)景的大訓(xùn)練集 of 上訓(xùn)練擴(kuò)散模型Dθ來(lái)估計(jì),該場(chǎng)景具有真實(shí)值圖像批Ij和它們的相機(jī)參數(shù)xj。在推斷時(shí),對(duì)于一組新的觀測(cè)圖像I,對(duì)p(x|I)進(jìn)行采樣,以估計(jì)相應(yīng)的相機(jī)參數(shù)x。注意,與獨(dú)立于I的噪聲處理不同,去噪處理以輸入圖像集I為條件,即
將去噪Dθ實(shí)現(xiàn)為transfomer Trans,
這里,Trans接受輸入圖像Ii的有噪姿態(tài)元組、擴(kuò)散時(shí)間t和特征嵌入。去噪器輸出相應(yīng)的去噪相機(jī)參數(shù)的元組,在訓(xùn)練時(shí),Dθ受到監(jiān)督,具有以下去噪損失:
訓(xùn)練后的去噪器Dθ被用來(lái)對(duì)pθ(x|I)進(jìn)行采樣,這解決了在給定輸入圖像I的情況下推斷相機(jī)參數(shù)x的任務(wù)。更詳細(xì)地說(shuō),在DDPM采樣之后,從隨機(jī)相機(jī)開(kāi)始,在每次迭代中,下一步通過(guò)下式采樣:
幾何引導(dǎo)的采樣
前饋網(wǎng)絡(luò)需要將圖像直接映射到相機(jī)參數(shù)的空間。考慮到深度網(wǎng)絡(luò)在回歸精確量(即旋轉(zhuǎn)矩陣和平移向量)方面很糟糕,通過(guò)利用兩視圖幾何約束,提取場(chǎng)景圖像之間可靠的2D對(duì)應(yīng)關(guān)系,并指導(dǎo)DDPM采樣迭代以便估計(jì)的姿態(tài)滿(mǎn)足對(duì)應(yīng)關(guān)系誘導(dǎo)的雙視圖極線約束。
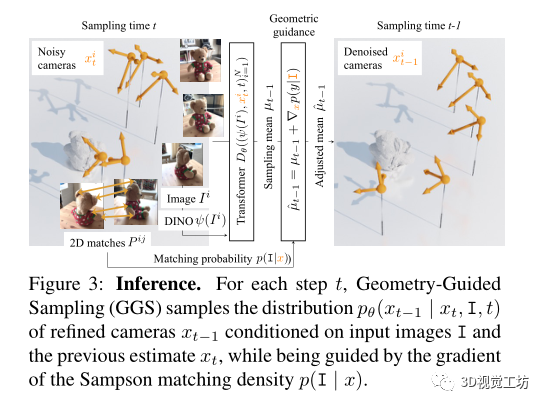
具體來(lái)說(shuō),讓表示一對(duì)場(chǎng)景圖像的圖像點(diǎn)之間的一組二維對(duì)應(yīng),表示相應(yīng)的相機(jī)姿勢(shì)。通過(guò)Sampson Epipolar Error 來(lái)評(píng)估相機(jī)和2D對(duì)應(yīng)關(guān)系之間的兼容性:
遵循分類(lèi)器diffusion指導(dǎo)來(lái)引導(dǎo)采樣朝著最小化Sampson極線誤差的解決方案進(jìn)行,因此這滿(mǎn)足了圖像-圖像間的極線約束。
在每次采樣迭代中,分類(lèi)器引導(dǎo)以xt條件引導(dǎo)分布p(I|xt)的梯度擾動(dòng)預(yù)測(cè)的平均值:
假設(shè)攝像機(jī)x上的一致先驗(yàn)允許將p(I|xt)建模為成對(duì)Sampson誤差上的獨(dú)立指數(shù)分布的乘積:
當(dāng)所有圖像對(duì)之間的Sampson誤差為0(即滿(mǎn)足所有核約束)時(shí),可以獲得最終模型。
實(shí)驗(yàn)
在兩個(gè)真實(shí)世界的數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn),討論了模型的設(shè)計(jì)選擇,并與之前的工作進(jìn)行了比較。
考慮了兩個(gè)具有不同統(tǒng)計(jì)數(shù)據(jù)的數(shù)據(jù)集。第一個(gè)是CO3Dv2,其中包含50個(gè)MS-COCO類(lèi)別中的物體的大約37k個(gè)視頻。
其次,對(duì)RealEstate10k進(jìn)行了評(píng)估,它包括捕捉房地產(chǎn)內(nèi)部和外部的80k YouTube剪輯視頻。
baseline:
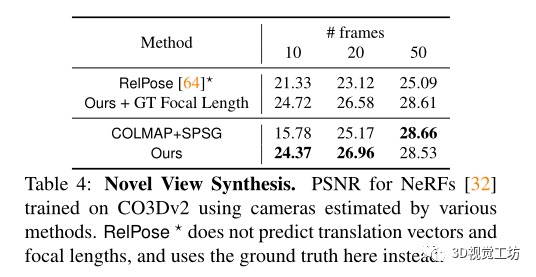
選擇COLMAP作為密集姿態(tài)估計(jì)基線。除了利用RANSAC匹配的SIFT的經(jīng)典版本外,還對(duì)COLMAP+SPG進(jìn)行了基準(zhǔn)測(cè)試,它建立在與SuperGlue匹配的SuperPoints的基礎(chǔ)上,還與RelPose進(jìn)行了比較,RelPose是當(dāng)前稀疏姿態(tài)估計(jì)的最先進(jìn)技術(shù)。最后為了理解幾何引導(dǎo)采樣的影響,在沒(méi)有GGS的情況下實(shí)現(xiàn)了學(xué)習(xí)去噪器。
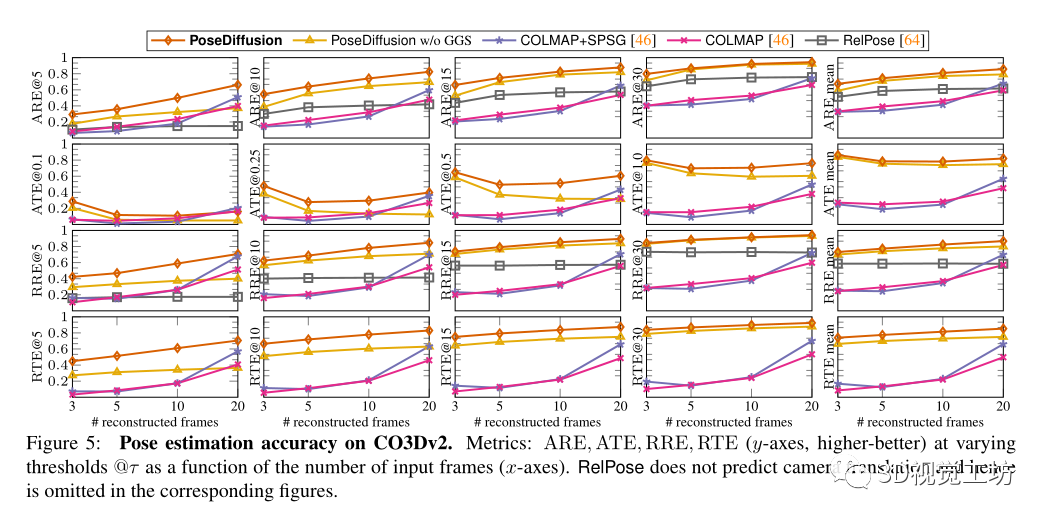
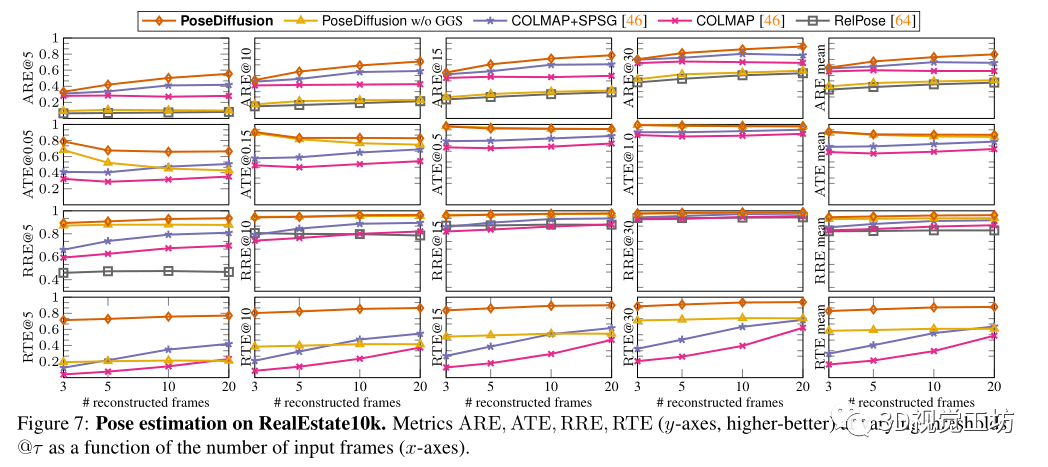
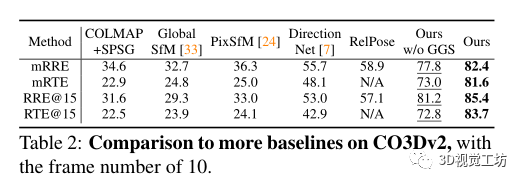
還評(píng)估了不同方法泛化到不同數(shù)據(jù)的能力。首先,在RelPose之后,對(duì)來(lái)自CO3Dv2的41個(gè)訓(xùn)練類(lèi)別進(jìn)行訓(xùn)練,并對(duì)剩余的10個(gè)保留類(lèi)別進(jìn)行評(píng)估。其方法優(yōu)于所有基線,表明具有優(yōu)越的泛化性。
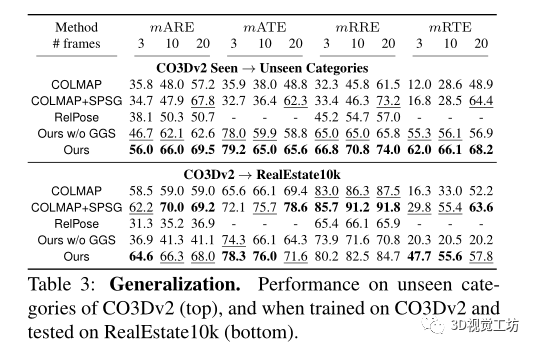
同時(shí)該方法還可以用來(lái)進(jìn)行新視圖合成,用來(lái)幫助nerf。
總結(jié):
提出了Pose diffusion,這是一種學(xué)習(xí)的相機(jī)估計(jì)器,同時(shí)具有傳統(tǒng)極線幾何約束和擴(kuò)散模型的能力。展示了擴(kuò)散框架如何與相機(jī)參數(shù)估計(jì)任務(wù)兼容。這一經(jīng)典任務(wù)的迭代性質(zhì)反映在去噪擴(kuò)散公式中。此外,圖像對(duì)之間的點(diǎn)匹配約束可以用于指導(dǎo)模型并細(xì)化最終預(yù)測(cè)。這改進(jìn)了傳統(tǒng)的SfM方法,如COLMAP,以及學(xué)習(xí)的方法。展示了在姿態(tài)預(yù)測(cè)精度以及新的視圖合成(COLMAP當(dāng)前最流行的應(yīng)用之一)任務(wù)方面的改進(jìn)。
責(zé)任編輯:彭菁
-
相機(jī)
+關(guān)注
關(guān)注
4文章
1430瀏覽量
54471 -
模型
+關(guān)注
關(guān)注
1文章
3483瀏覽量
49962 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1222瀏覽量
25269
原文標(biāo)題:ArXiv2023 | PoseDiffusion:基于Diffusion的姿態(tài)估計(jì)算法,來(lái)自Meta AI
文章出處:【微信號(hào):3D視覺(jué)工坊,微信公眾號(hào):3D視覺(jué)工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
基于姿態(tài)校正的人臉檢測(cè)方法
針對(duì)姿態(tài)傳感器的姿態(tài)估計(jì)方法的詳細(xì)資料說(shuō)明免費(fèi)下載
一種采用深度殘差網(wǎng)絡(luò)的頭部姿態(tài)估計(jì)方法

基于深度學(xué)習(xí)的二維人體姿態(tài)估計(jì)方法

基于深度學(xué)習(xí)的二維人體姿態(tài)估計(jì)算法

基于Bagging-SVM集成分類(lèi)器的頭部姿態(tài)估計(jì)方法
基于面部特征點(diǎn)定位的圖像人臉姿態(tài)估計(jì)方法
基于編解碼殘差的人體姿態(tài)估計(jì)方法
人臉姿態(tài)檢測(cè)|Fine Grained Head Pose Estimation Without Keypoint

基于OnePose的無(wú)CAD模型的物體姿態(tài)估計(jì)
一種基于去遮擋和移除的3D交互手姿態(tài)估計(jì)框架
Meta研究:基于頭顯攝像頭進(jìn)行姿態(tài)估計(jì)的方法和優(yōu)缺點(diǎn)

硬件加速人體姿態(tài)估計(jì)開(kāi)源分享
AI深度相機(jī)-人體姿態(tài)估計(jì)應(yīng)用

基于飛控的姿態(tài)估計(jì)算法作用及原理





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論