") 超詳細!一文講透機器視覺常用的 3 種“目標識別”方法
超詳細!一文講透機器視覺常用的 3 種“目標識別”方法

來源:機器視覺沙龍
隨著機器視覺技術(shù)的快速發(fā)展,傳統(tǒng)很多需要人工來手動操作的工作,漸漸地被機器所替代。傳統(tǒng)方法做目標識別大多都是靠人工實現(xiàn),從形狀、顏色、長度、寬度、長寬比來確定被識別的目標是否符合標準,最終定義出一系列的規(guī)則來進行目標識別。這樣的方法當然在一些簡單的案例中已經(jīng)應(yīng)用的很好,唯一的缺點是隨著被識別物體的變動,所有的規(guī)則和算法都要重新設(shè)計和開發(fā),即使是同樣的產(chǎn)品,不同批次的變化都會造成不能重用的現(xiàn)實。而隨著機器學習,深度學習的發(fā)展,很多肉眼很難去直接量化的特征,深度學習可以自動學習這些特征,這就是深度學習帶給我們的優(yōu)點和前所未有的吸引力。很多特征我們通過傳統(tǒng)算法無法量化,或者說很難去做到的,深度學習可以。特別是在圖像分類、目標識別這些問題上有顯著的提升。視覺常用的目標識別方法有三種:Blob分析法(BlobAnalysis)、模板匹配法、深度學習法。下面就三種常用的目標識別方法進行對比。
Blob分析法
BlobAnalysis
在計算機視覺中的Blob是指圖像中的具有相似顏色、紋理等特征所組成的一塊連通區(qū)域。Blob分析(BlobAnalysis)是對圖像中相同像素的連通域進行分析(該連通域稱為Blob)。其過程就是將圖像進行二值化,分割得到前景和背景,然后進行連通區(qū)域檢測,從而得到Blob塊的過程。簡單來說,blob分析就是在一塊“光滑”區(qū)域內(nèi),將出現(xiàn)“灰度突變”的小區(qū)域?qū)ふ页鰜怼?br />
舉例來說,假如現(xiàn)在有一塊剛生產(chǎn)出來的玻璃,表面非常光滑,平整。如果這塊玻璃上面沒有瑕疵,那么,我們是檢測不到“灰度突變”的;相反,如果在玻璃生產(chǎn)線上,由于種種原因,造成了玻璃上面有一個凸起的小泡、有一塊黑斑、有一點裂縫,那么,我們就能在這塊玻璃上面檢測到紋理,經(jīng)二值化(BinaryThresholding)處理后的圖像中色斑可認為是blob。而這些部分,就是生產(chǎn)過程中造成的瑕疵,這個過程,就是Blob分析。
Blob分析工具可以從背景中分離出目標,并可以計算出目標的數(shù)量、位置、形狀、方向和大小,還可以提供相關(guān)斑點間的拓撲結(jié)構(gòu)。在處理過程中不是對單個像素逐一分析,而是對圖像的行進行操作。圖像的每一行都用游程長度編碼(RLE)來表示相鄰的目標范圍。這種算法與基于像素的算法相比,大大提高了處理的速度。
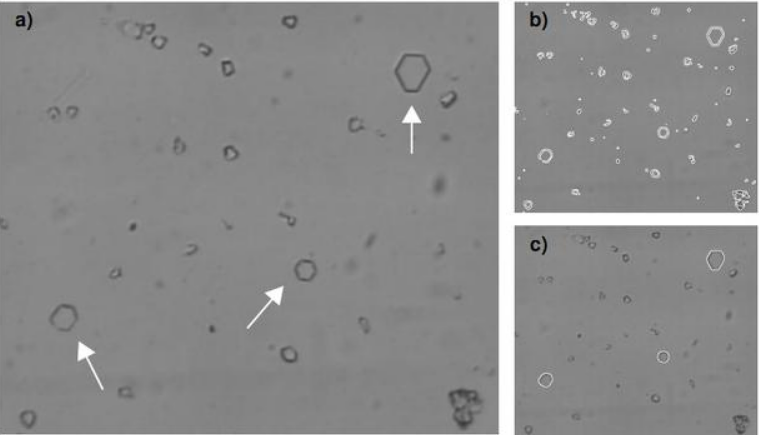
但另一方面,Blob分析并不適用于以下圖像:1.低對比度圖像;2.必要的圖像特征不能用2個灰度級描述;3.按照模版檢測(圖形檢測需求)。
總的來說,Blob分析就是檢測圖像的斑點,適用于背景單一,前景缺陷不區(qū)分類別,識別精度要求不高的場景。
模板匹配法
template matching
模板匹配是一種最原始、最基本的模式識別方法,研究某一特定對象物的圖案位于圖像的什么地方,進而識別對象物,這就是一個匹配問題。它是圖像處理中最基本、最常用的匹配方法。換句話說就是一副已知的需要匹配的小圖像,在一副大圖像中搜尋目標,已知該圖中有要找的目標,且該目標同模板有相同的尺寸、方向和圖像元素,通過統(tǒng)計計算圖像的均值、梯度、距離、方差等特征可以在圖中找到目標,確定其坐標位置。
這就說明,我們要找的模板是圖像里標標準準存在的,這里說的標標準準,就是說,一旦圖像或者模板發(fā)生變化,比如旋轉(zhuǎn),修改某幾個像素,圖像翻轉(zhuǎn)等操作之后,我們就無法進行匹配了,這也是這個算法的弊端。
所以這種匹配算法,就是在待檢測圖像上,從左到右,從上向下對模板圖像與小東西的圖像進行比對。

這種方法相比Blob分析有較好的檢測精度,同時也能區(qū)分不同的缺陷類別,這相當于是一種搜索算法,在待檢測圖像上根據(jù)不同roi用指定的匹配方法與模板庫中的所有圖像進行搜索匹配,要求缺陷的形狀、大小、方法都有較高的一致性,因此想要獲得可用的檢測精度需要構(gòu)建較完善的模板庫。
深度學習法
deep learning method
2014年R-CNN的提出,使得基于CNN的目標檢測算法逐漸成為主流。深度學習的應(yīng)用,使檢測精度和檢測速度都獲得了改善。
卷積神經(jīng)網(wǎng)絡(luò)不僅能夠提取更高層、表達能力更好的特征,還能在同一個模型中完成對于特征的提取、選擇和分類。
在這方面,主要有兩類主流的算法:
一類是結(jié)合RPN網(wǎng)絡(luò)的,基于分類的R-CNN系列兩階目標檢測算法(twostage);
另一類則是將目標檢測轉(zhuǎn)換為回歸問題的一階目標檢測算法(singlestage)。
物體檢測的任務(wù)是找出圖像或視頻中的感興趣物體,同時檢測出它們的位置和大小,是機器視覺領(lǐng)域的核心問題之一。

物體檢測過程中有很多不確定因素,如圖像中物體數(shù)量不確定,物體有不同的外觀、形狀、姿態(tài),加之物體成像時會有光照、遮擋等因素的干擾,導致檢測算法有一定的難度。
進入深度學習時代以來,物體檢測發(fā)展主要集中在兩個方向:twostage算法如R-CNN系列和onestage算法如YOLO、SSD等。兩者的主要區(qū)別在于twostage算法需要先生成proposal(一個有可能包含待檢物體的預選框),然后進行細粒度的物體檢測。而onestage算法會直接在網(wǎng)絡(luò)中提取特征來預測物體分類和位置。
兩階算法中區(qū)域提取算法核心是卷積神經(jīng)網(wǎng)絡(luò)CNN,先利用CNN骨干提取特征,然后找出候選區(qū)域,最后滑動窗口確定目標類別與位置。R-CNN首先通過SS算法提取2k個左右的感興趣區(qū)域,再對感興趣區(qū)域進行特征提取。存在缺陷:感興趣區(qū)域彼此之間權(quán)值無法共享,存在重復計算,中間數(shù)據(jù)需單獨保存占用資源,對輸入圖片強制縮放影響檢測準確度。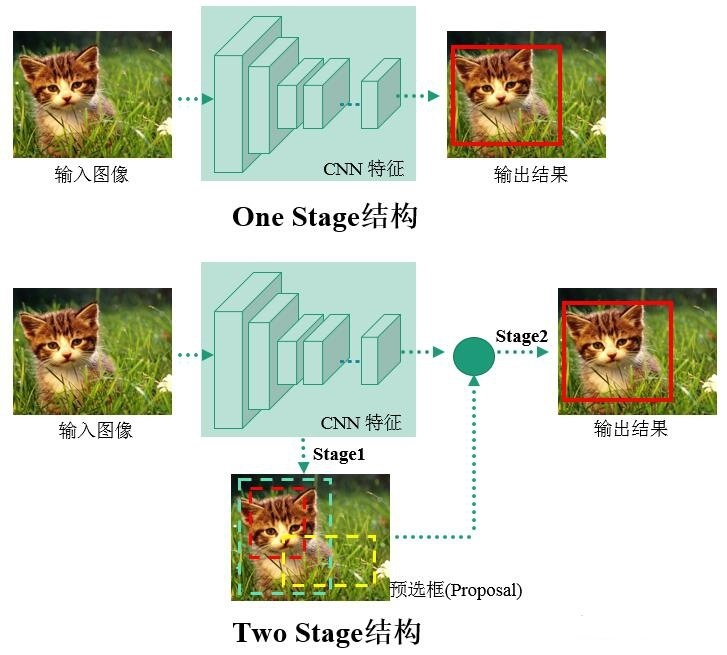
SPP-NET在最后一個卷積層和第一個全連接層之間做些處理,保證輸入全連接層的尺寸一致即可解決輸入圖像尺寸受限的問題。SPP-NET候選區(qū)域包含整張圖像,只需通過一次卷積網(wǎng)絡(luò)即可得到整張圖像和所有候選區(qū)域的特征。
FastR-CNN借鑒SPP-NET的特征金字塔,提出ROIPooling把各種尺寸的候選區(qū)域特征圖映射成統(tǒng)一尺度的特征向量,首先,將不同大小的候選區(qū)域都切分成M×N塊,再對每塊都進行maxpooling得到1個值。這樣,所有候選區(qū)域特征圖就都統(tǒng)一成M×N維的特征向量了。但是,利用SS算法產(chǎn)生候選框?qū)r間消耗非常大。
FasterR-CNN是先用CNN骨干網(wǎng)提取圖像特征,由RPN網(wǎng)絡(luò)和后續(xù)的檢測器共享,特征圖進入RPN網(wǎng)絡(luò)后,對每個特征點預設(shè)9個不同尺度和形狀的錨盒,計算錨盒和真實目標框的交并比和偏移量,判斷該位置是否存在目標,將預定義的錨盒分為前景或背景,再根據(jù)偏差損失訓練RPN網(wǎng)絡(luò),進行位置回歸,修正ROI的位置,最后將修正的ROI傳入后續(xù)網(wǎng)絡(luò)。但是,在檢測過程中,RPN網(wǎng)絡(luò)需要對目標進行一次回歸篩選以區(qū)分前景和背景目標,后續(xù)檢測網(wǎng)絡(luò)對RPN輸出的ROI再一次進行細分類和位置回歸,兩次計算導致模型參數(shù)量大。
MaskR-CNN在FasterR-CNN中加了并行的mask分支,對每個ROI生成一個像素級別的二進制掩碼。在FasterR-CNN中,采用ROIPooling產(chǎn)生統(tǒng)一尺度的特征圖,這樣再映射回原圖時就會產(chǎn)生錯位,使像素之間不能精準對齊。這對目標檢測產(chǎn)生的影響相對較小,但對于像素級的分割任務(wù),誤差就不容忽視了。MaskR-CNN中用雙線性插值解決像素點不能精準對齊的問題。但是,由于繼承兩階段算法,實時性仍不理想。
一階算法在整個卷積網(wǎng)絡(luò)中進行特征提取、目標分類和位置回歸,通過一次反向計算得到目標位置和類別,在識別精度稍弱于兩階段目標檢測算法的前提下,速度有了極大的提升。
YOLOv1把輸入圖像統(tǒng)一縮放到448×448×3,再劃分為7×7個網(wǎng)格,每格負責預測兩個邊界框bbox的位置和置信度。這兩個b-box對應(yīng)同一個類別,一個預測大目標,一個預測小目標。bbox的位置不需要初始化,而是由YOLO模型在權(quán)重初始化后計算出來的,模型在訓練時隨著網(wǎng)絡(luò)權(quán)重的更新,調(diào)整b-box的預測位置。但是,該算法對小目標檢測不佳,每個網(wǎng)格只能預測一個類別。
YOLOv2把原始圖像劃分為13×13個網(wǎng)格,通過聚類分析,確定每個網(wǎng)格設(shè)置5個錨盒,每個錨盒預測1個類別,通過預測錨盒和網(wǎng)格之間的偏移量進行目標位置回歸。
SSD保留了網(wǎng)格劃分方法,但從基礎(chǔ)網(wǎng)絡(luò)的不同卷積層提取特征。隨著卷積層數(shù)的遞增,錨盒尺寸設(shè)置由小到大,以此提升SSD對多尺度目標的檢測精度。
YOLOv3通過聚類分析,每個網(wǎng)格預設(shè)3個錨盒,只用darknet前52層,并大量使用殘差層。使用降采樣降低池化對梯度下降的負面效果。YOLOv3通過上采樣提取深層特征,使其與將要融合的淺層特征維度相同,但通道數(shù)不同,在通道維度上進行拼接實現(xiàn)特征融合,融合了13×13×255、26×26×255和52×52×255共3個尺度的特征圖,對應(yīng)的檢測頭也都采用全卷積結(jié)構(gòu)。
YOLOv4在原有YOLO目標檢測架構(gòu)的基礎(chǔ)上,采用了近些年CNN領(lǐng)域中最優(yōu)秀的優(yōu)化策略,從數(shù)據(jù)處理、主干網(wǎng)絡(luò)、網(wǎng)絡(luò)訓練、激活函數(shù)、損失函數(shù)等各個方面都進行了不同程度的優(yōu)化。時至今日,已經(jīng)有很多精度比較高的目標檢測算法提出,包括最近視覺領(lǐng)域的transformer研究也一直在提高目標檢測算法的精度。
總結(jié)來看,表示的選擇會對機器學習算法的性能產(chǎn)生巨大的影響,監(jiān)督學習訓練的前饋網(wǎng)絡(luò)可視為表示學習的一種形式。依此來看傳統(tǒng)的算法如Blob分析和模板匹配都是手工設(shè)計其特征表示,而神經(jīng)網(wǎng)絡(luò)則是通過算法自動學習目標的合適特征表示,相比手工特征設(shè)計來說其更高效快捷,也無需太多的專業(yè)的特征設(shè)計知識,因此其能夠識別不同場景中形狀、大小、紋理等不一的目標,隨著數(shù)據(jù)集的增大,檢測的精度也會進一步提高。
-
機器視覺
+關(guān)注
關(guān)注
163文章
4597瀏覽量
122903
發(fā)布評論請先 登錄
人形機器人 3D 視覺路線之爭:激光雷達、雙目和 3D - ToF 誰更勝一籌?
一文帶你了解什么是機器視覺網(wǎng)卡

基于LockAI視覺識別模塊:手寫數(shù)字識別
基于LockAI視覺識別模塊:C++目標檢測
基于LockAI視覺識別模塊:C++目標檢測

基于LockAI視覺識別模塊:C++條碼識別
詳細介紹機場智能指路機器人的工作原理
【「# ROS 2智能機器人開發(fā)實踐」閱讀體驗】視覺實現(xiàn)的基礎(chǔ)算法的應(yīng)用
基于 RFID 技術(shù)的某部隊編目標識高效識別與協(xié)同管控系統(tǒng)建設(shè)方案

適用于機器視覺應(yīng)用的智能機器視覺控制平臺

一文講透人形機器人常用的四類感知傳感器:視覺、力/力矩、觸覺、IMU





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論