 AI Codec在應用落地方面的案例
AI Codec在應用落地方面的案例

AI Codec自2016年首次提出以來,眾多海內外高校、企業研究院等機構對此展開了廣泛研究。6年時間里,AI Codec 的SOTA方案的壓縮性能已經超越了H.266(最新的傳統Codec標準),展現了強大的技術潛力。但受限于計算復雜度、非標等原因,AI Codec在應用落地方面的案例卻屈指可數。LiveVideoStackCon2022北京站邀請了來自雙深科技的田康為大家分享基于雙深科技的AI Image Codec技術落地探索經驗。
文/田康 編輯/LiveVideoStack
大家好,本次分享的主題為:AI Image Codec技術落地實踐,主要將分三部分介紹我們在移動端方面取得的技術成果。第一部分介紹圖像視頻行業發展趨勢和我們的理解;第二部分簡單總結AI Codec發展;第三部分為重點,即AI Image Codec移動端落地實踐。
-01-
圖像視頻行業發展趨勢
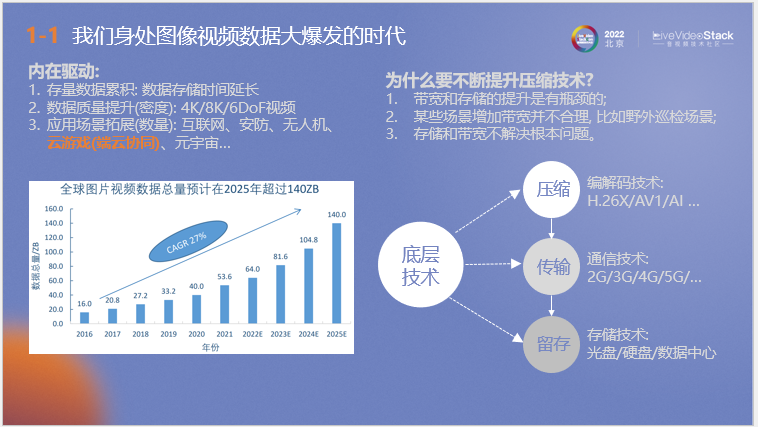
首先介紹圖像視頻行業發展趨勢,“我們身處圖像數據大爆發的時代”可能已成為了一項行業共識。據我們從相關機構取得的調研數據顯示,全球圖片視頻數據總量至2025年預計將超過140ZB,每年的數據復合增長率達到27%,這是一個很恐怖的數量級。隨著近年來ChatGPT等技術的火爆,相信增長率還會進一步提升。 簡單分析數據量迅速增長的原因:首先是在醫療、安防等應用場景下,影像數據按照國家政策要求需要長期或永久存儲,導致數據積累量越來越大。第二是隨著大眾對高畫質、高幀率等高質量視頻需求的增長,導致數據密度提升。第三是隨著視頻數據在互聯網、安防、無人機、云游戲(不同于傳統游戲,過程中伴隨著超大量視頻傳輸)等等多種應用場景的拓展帶來了數據量的巨量增長。 那么要高效運用這些數據必定伴隨著壓縮、傳輸和存儲等底層技術的發展優化,我們認為壓縮技術的提升是其中的關鍵,主要原因有三個:首先是帶寬和存儲的提升是有瓶頸的。其次針對野外巡檢等特殊應用場景,增加帶寬并不適用。第三是存儲和帶寬的提升并沒有從根本解決傳輸數據量龐大這個問題。
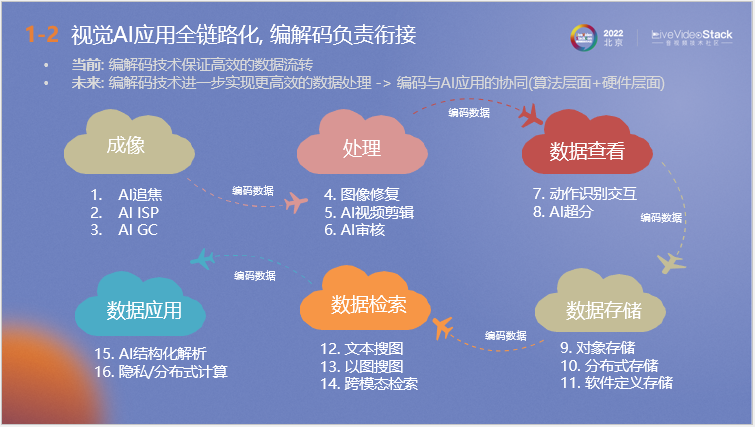
上圖為我們設計的視覺AI應用鏈路圖,首先通過攝像頭或計算機生產影像內容,然后進行修復、剪輯或AI審核等處理,并將數據呈遞給用戶進行數據查看,過程中可能伴隨著AI動作識別交互或超分,隨后傳遞至存儲設備進行數據存儲。在應用前通過文本、圖片、跨模態等檢索方式查找所需的數據,最終可以對其進行結構化解析和隱私/分布式計算等應用。 可以看到整個流程都由編解碼來進行銜接。同時在每個環節都可能存在AI的應用,這也是數據處理后續的發展趨勢。 和傳統編解碼相比,AI端到端編解碼在天然上更適應這種趨勢。從算法層面來看,AI編解碼以提取的圖像特征直接進行下游應用,從而節約了下游特征提取計算量。從硬件層面來看,AI的大量應用使當下硬件都或多或少地帶有AI算力,這同時為AI編解碼的應用創造了條件。
-02-
AI Codec發展

接下來介紹AI Codec的發展,上圖為傳統和AI編解碼發展歷程的對比。可以看到,AI Codec壓縮性能超越傳統的H.264、H.265僅使用了傳統方法1/6的發展時間。從1988年的H.261到2020年的H.266,相較于傳統編解碼器平均十年一次的迭代頻率,AI編解碼實現了飛速發展,從2016年端到端編碼框架的提出到后續GAN、1857標準的應用,甚至是后續AIGC編碼發展方向的出現,它在短時間內不斷涌現可落地應用的各種新方法。
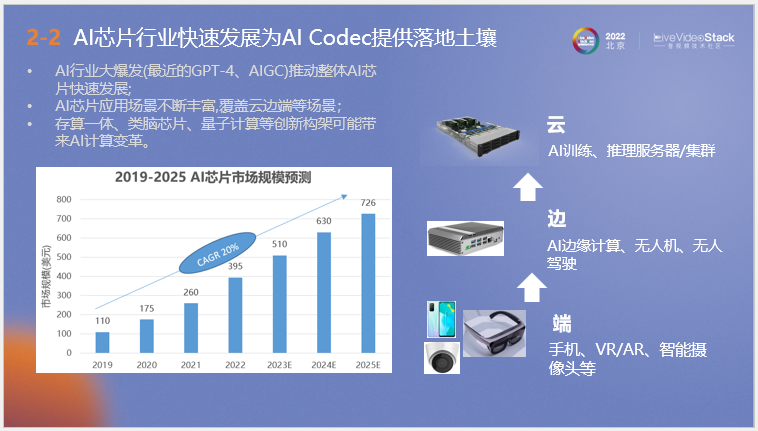
另一方面是AI芯片行業的發展同時為AI編解碼提供了落地土壤。近年來GPT-4、AIGC的大規模使用在側面推動了AI芯片業整體的快速發展,隨著行業利好,高通等著名邊緣芯片企業也在逐步啟動對AI芯片的開發研究。其次是存算一體、類腦芯片、量子計算等未來技術為芯片算力發展帶來了更好前景。
-03-
AI Image Codec移動端落地實踐
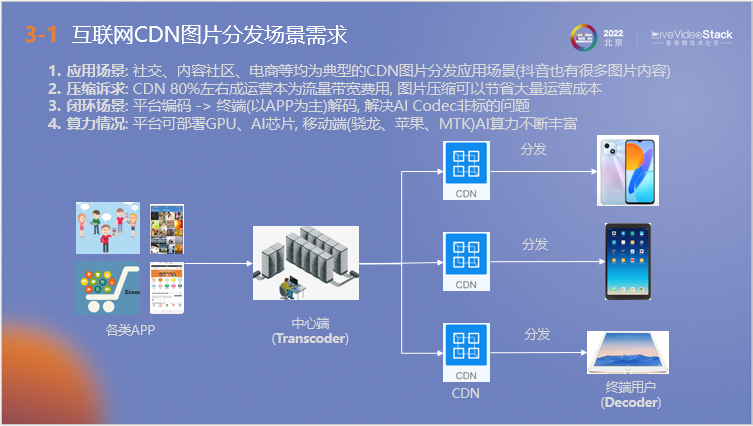
接下來介紹我們關于AI Image Codec在移動端的落地實踐,以互聯網移動端CDN圖片分發場景為應用場景,首先解釋采用該場景的原因。
第一,當下大量社交、內容社區、電商APP均涉及該場景,中心端以一對多方式進行圖片的分發,即使是抖音這種小視頻平臺也會涉及很多圖片內容。同時由于CDN 80%左右的運營成本為流量帶寬費用,因此它有很大的圖片壓縮訴求,優化圖片壓縮技術可以有效節約成本。第三是該場景為閉環場景,可以解決目前AI Codec非標的問題。最后是移動端的AI算力相對于其他物聯網設備較強,可以實現更好的編解碼效果。
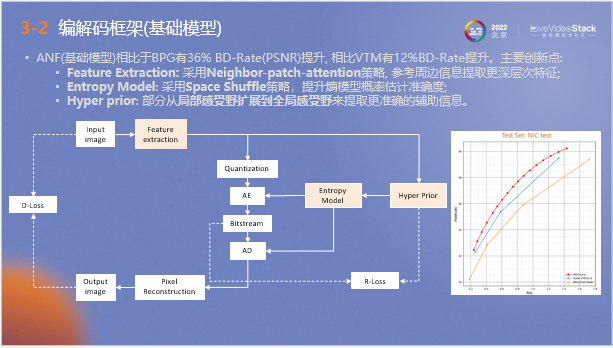
以上為我們自研的AI圖像編解碼模型框架,它被稱為ANF。不同于傳統編解碼器通過分塊預測處理來進行數據壓縮,ANF編解碼器在接收圖片后,通過神經網絡提取高層像素規律作為數據量化和輔助熵模型概率預估的依據。數據最終傳遞至傳輸端進行熵解碼和像素重建,向用戶呈現圖片。
我們在整個流程中針對AI訓練設置了兩個約束,第一是R-Loss,它代表比特流和超先驗的存儲信息量;第二是D-Loss,它用于衡量輸入和輸出圖片之間的質量差,以上兩個指標都需要保持盡量小。
針對該模型我們也提出了一些優化策略,如在特征提取階段采用Neighbor-patch-attention策略來參考周邊信息,提取更深層次特征。其次是在熵模型概率預估階段: 采用Space Shuffle策略,提升概率估計準確度。第三是在超先驗階段,將局部感受野擴展到全局感受野來提取更準確的輔助信息。
右圖為測試結果,其中紅線代表ANF模型數據,可以看到相比于VVC等傳統編碼器,它的測試結果要超出0.5~0.7dB左右。
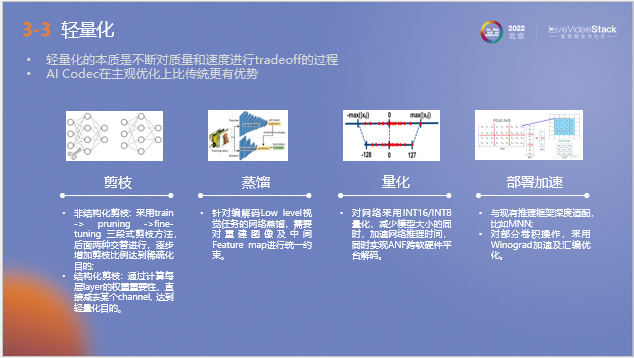
由于ANF模型的架構比較復雜,為了更好的在移動端上進行應用,我們對它進行了輕量化處理,在量化和部署加速方面做了相當多的工作。在畫質損失盡量小的前提下盡量獲取加速收益。
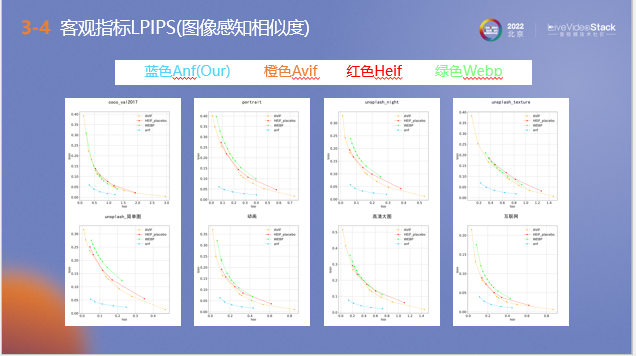
以上是輕量化后的ANF模型和其他編解碼器使用LPIPS指標測試的對比結果,用于衡量ANF和其他編解碼器之間的差距,該指標越小代表壓縮后的圖像和原圖主觀質量越接近。通過在多種場景下測試可以看到,ANF壓縮的圖片質量要明顯優于其他編解碼器。
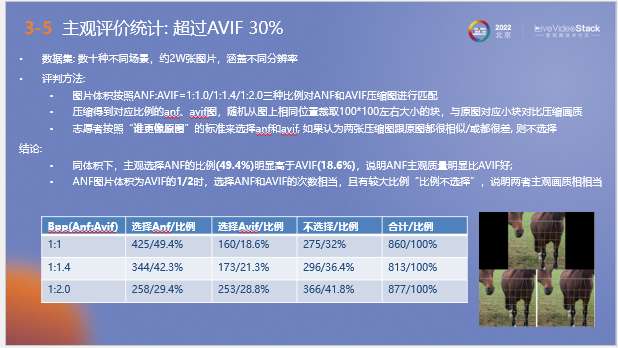
在客觀指標結果較好的基礎上,我們組織對壓縮圖像進行了主觀評測,選擇了數十種不同場景,約兩萬張涵蓋不同分辨率的圖片作為數據集進行測試。以avif的壓縮圖像作為基準進行對比,按照三種不同比例將原始圖片用ANF和avif編解碼器進行壓縮,將壓縮后的圖片從相同位置裁取100*100左右大小的塊,與原圖對應小塊對比壓縮畫質,最后征集志愿者進行測評。
下表為評測結果,可以看到同體積下,主觀選擇ANF的比例(49.4%)明顯高于AVIF(18.6%),說明ANF主觀質量明顯比AVIF好; 體積比為1:1.4時,結果與1:1時相同;體積比為1:2時,選擇ANF和AVIF的次數相當,且有較大比例“不選擇”,說明兩者主觀畫質相當。

以上為同體積比下,兩種編碼器的測試效果圖,可以看到ANF壓縮圖片的質量和原圖更加接近。

以上為體積比為1:1.5時,兩種編碼器的測試效果圖。可以看到ANF的圖像細節效果仍然不錯。
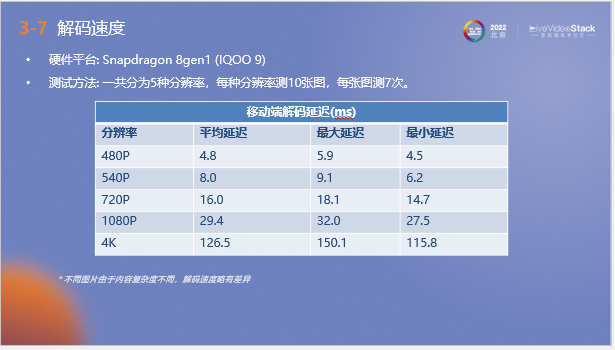
接下來介紹ANF的解碼速度,我們在驍龍8gen1平臺上對解碼速度進行了測試,使用自封SDK測試從圖片載入到最終在移動端顯示所需的時間。可以看到在1080P分辨率下,ANF的平均延遲可以達到29.4毫秒,這個量級是人眼感受不到的,可以滿足應用需求。
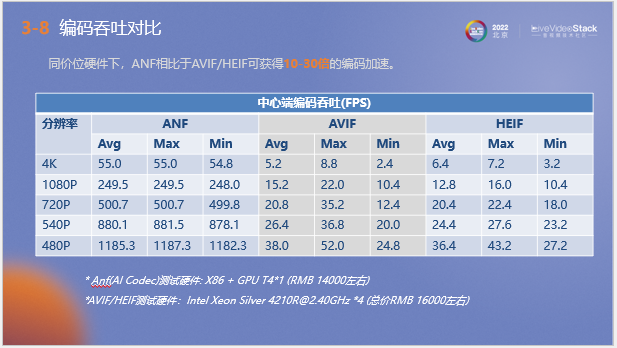
以上為編碼吞吐對比結果,在同樣的硬件條件下和傳統編碼器相比,ANF可獲得10-30倍的編碼加速。
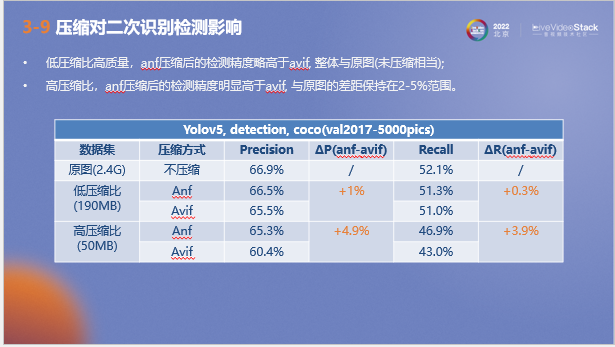
以上為壓縮對二次識別檢測影響的測試結果,選取了精確率和召回率兩個指標進行衡量。可以看到在低壓縮比下,ANF壓縮圖片的檢測精度略高于avif, 兩項指標與原圖相當;在高壓縮比下,ANF壓縮圖片的檢測精度明顯高于avif, 與原圖的差距保持在2-5%范圍。

接下來進行總結,首先在當前的圖像視頻大爆發時代,我們認為編解碼技術的提升迫在眉睫和勢在必行的。第二是圖像處理AI化的趨勢明顯,基于AI的編碼方式從算法和硬件層面均能夠更好地協同。第三是AI Codec的發展速度很快,未來發展前景光明;同時AI Codec的發展也順應了AI芯片發展的趨勢。最終我們基于AI Codec的主觀優化,可以超過AVIF 30%以上,解碼效率可在高端機型落地,編碼效率顯著優于傳統Codec的CPU軟編方案,具備在CDN圖片場景落地的可行性。我的分享到此結束,謝謝大家!
責任編輯:彭菁
-
帶寬
+關注
關注
3文章
993瀏覽量
42010 -
AI
+關注
關注
88文章
34781瀏覽量
277129 -
移動端
+關注
關注
0文章
42瀏覽量
4577
原文標題:AI Image Codec技術落地實踐
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄







 工商網監
工商網監
評論