") Lua5.4源碼剖析—性能優(yōu)化與原理分析
Lua5.4源碼剖析—性能優(yōu)化與原理分析
測試設(shè)備
1)本文中的數(shù)據(jù)是基于我的個人電腦MacBookPro:4核2.2GHz的i7處理器;
2)在時間的測量上,為了能精確到毫秒級別,我使用了Lua自帶的os.clock()函數(shù),它返回的是一個浮點(diǎn)數(shù),單位是秒數(shù),乘1000就是對應(yīng)的毫秒數(shù),本文測試數(shù)據(jù)均以毫秒為單位。另外本文為了放大不同寫法數(shù)據(jù)的性能差異,在樣例比較中,通常會循環(huán)執(zhí)行較多的次數(shù)來累計總的消耗進(jìn)行比較。
3星優(yōu)化
推薦程度:極力推薦,使用簡單,且優(yōu)化收益明顯,每個Lua使用者都應(yīng)該遵循。
1)全類型通用CPU優(yōu)化——高頻訪問的對象,應(yīng)先賦值給一個local變量再進(jìn)行訪問
測試樣例 :用循環(huán)模擬高頻訪問,每輪循環(huán)中訪問調(diào)用math.random函數(shù),用它來創(chuàng)建一個隨機(jī)數(shù)。
備注 :這里的對象,是Lua的所有類型,包括Booeal、Number、Table、Function、Thread等等。
錯誤寫法 :
for i = 1, 1000000 do local randomVal = math.random(0, 10000)end
正確寫法(把函數(shù)math.random賦值給local變量) :
local random = math.randomfor i = 1, 1000000 do local randomVal = random(0, 10000)end
測試樣例及性能差異(循環(huán)100 0000次消耗):
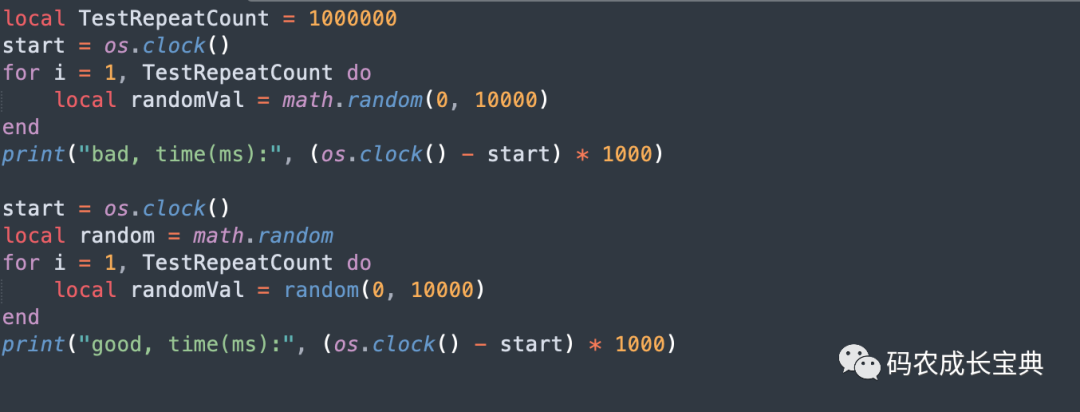
結(jié)果(耗時減少14毫秒):

原理分析 :
非local局部變量,即UpValue(全局變量其實也是記錄在名為_ENV的第一個Table類型的UpValue中)的訪問通常需要更多的指令操作,如果對應(yīng)的UpValue是個Table的話,還需要進(jìn)入Table的復(fù)雜的數(shù)據(jù)查詢流程。而local變量的訪問,只需要一條簡單寄存器讀取指令,所以能節(jié)省出數(shù)據(jù)查詢帶來的性能開銷。
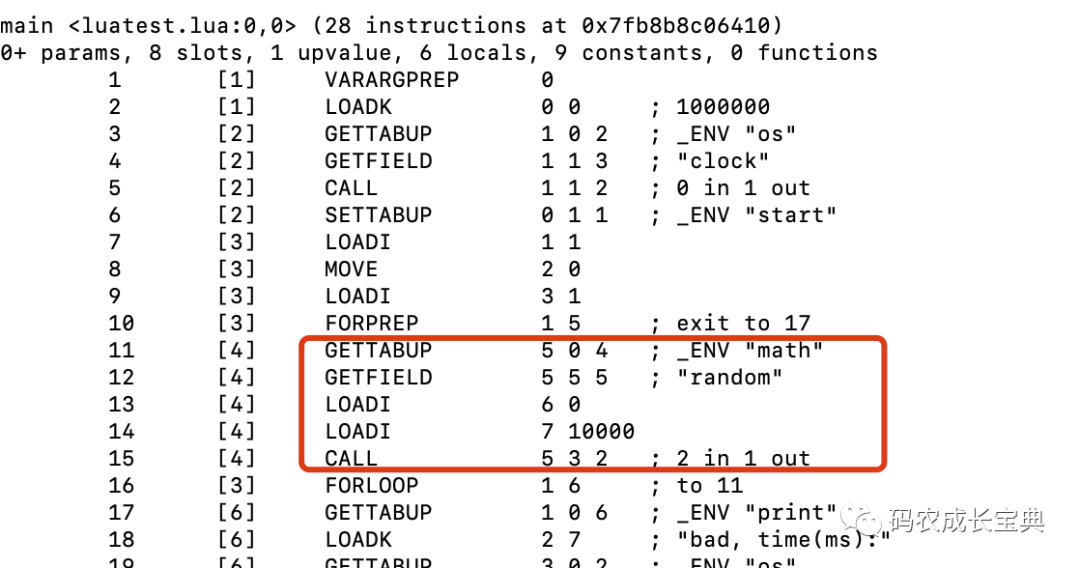
OpCode對比 :
錯誤寫法:每次循環(huán)需要執(zhí)行下面5條指令:
正確寫法:每次循環(huán)只需要執(zhí)行下面4條指令操作,原本復(fù)雜的函數(shù)從Table中查詢定位的操作,替換成了簡單的OP_MOVE寄存器賦值操作: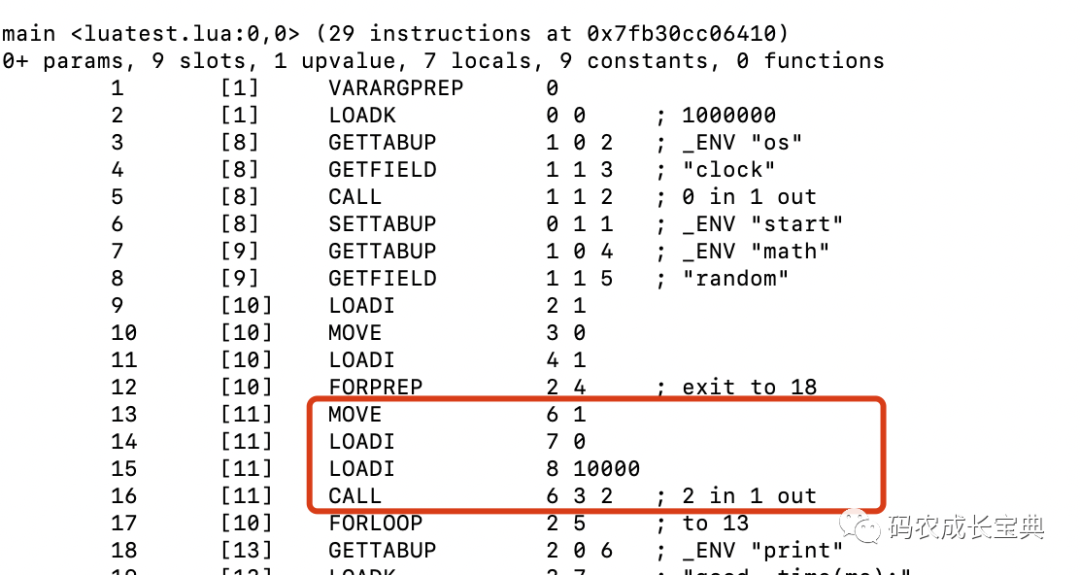
2)String類型CPU與內(nèi)存優(yōu)化——要拼接的字符串如果比較多,應(yīng)使用table.conat函數(shù)
測試樣例 :多次循環(huán),每次拼接一個0到10000范圍的隨機(jī)數(shù)到目標(biāo)字符串上。
錯誤寫法 :
local random = math.randomlocal sumStr = ""for i = 1, 10000 dosumStr = sumStr .. tostring(random(0, 10000))end
正確寫法 :
local random = math.randomlocal sumStr = ""local concat_list = {}for i = 1, 10000 dotable.insert(concat_list, tostring(random(0, 10000)))end
測試樣例及性能差異(循環(huán)1 0000次消耗):
由于本樣例會產(chǎn)生臨時內(nèi)存數(shù)據(jù),我們統(tǒng)計時間消耗的時候要把GC的時間也算上,所以都先調(diào)用了collectgarbage("collect")進(jìn)行強(qiáng)制的GC。
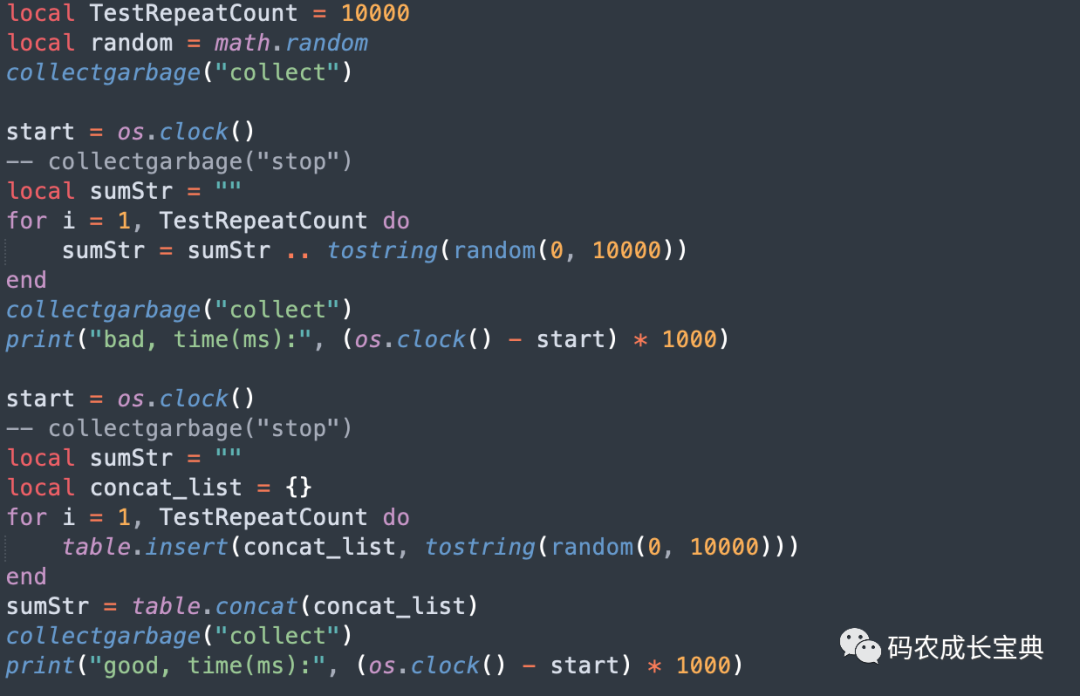
結(jié)果(循環(huán)中允許自動GC,節(jié)省18毫秒) :

特殊情況 :
若在兩種寫法的開頭都加上collectgarbage("stop"),即把上述代碼注釋部分取消,在循環(huán)中就不會自動觸發(fā)GC,有些開發(fā)者會控制GC時機(jī),例如只在Loading過場的時候調(diào)用GC,所以實際中會有這種情況出現(xiàn)。
我們之前學(xué)習(xí)Lua字符串源碼的時候知道,字符串的使用是有自動的緩存機(jī)制的,當(dāng)前已經(jīng)緩存住的未被GC的字符串越多,后續(xù)字符串的查詢效率越低下,此時運(yùn)算結(jié)果如下(循環(huán)中不自動GC,錯誤寫法時間消耗大增,正確寫法節(jié)省100毫秒):
另外,在循環(huán)中可自動GC的情況下,把測試次數(shù)由10000乘以10改成100000次時,正確寫法時間消耗幾乎成比例增長10倍,而錯誤寫法則會隨著拼接后的字符串越來越長,時間消耗指數(shù)性急劇上升,增長了50倍:
源碼分析 :
每次有兩個字符串使用".."連接符進(jìn)行拼接的時候,會生成一個新的中間字符串,隨著拼接的字符串長度越長,內(nèi)存占用與CPU消耗越大。在上述測試樣例中,我們只需要最終所有字符串的拼接結(jié)果,這些中間產(chǎn)物其實對我們是沒有意義的;而table.concat函數(shù)則是可以一次性拼接table中所有的字符串,無中間產(chǎn)物,所以會對內(nèi)存與CPU有較大的優(yōu)化。
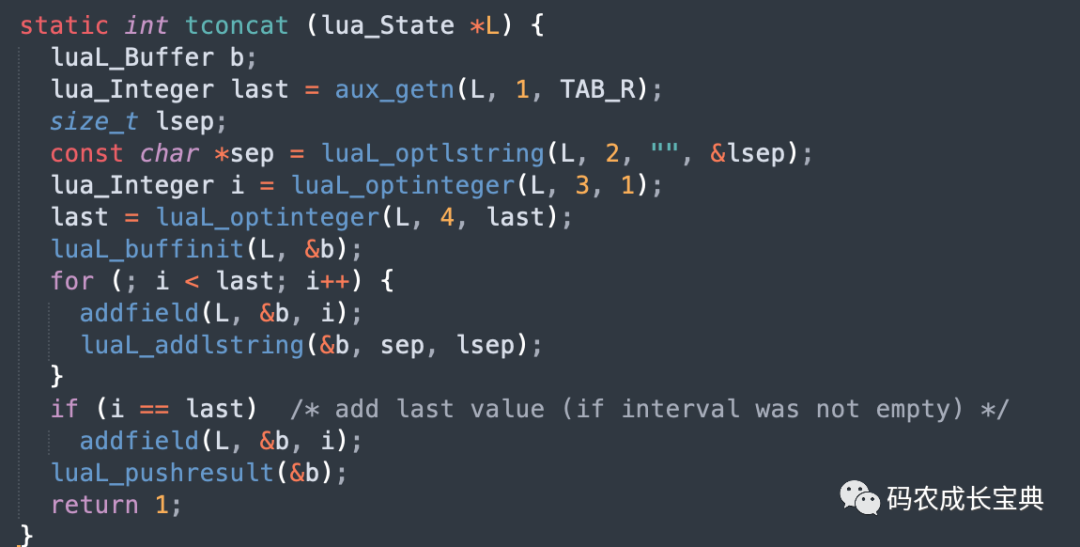
table.concat函數(shù)的實現(xiàn)如下,會先創(chuàng)建一個緩存區(qū),把所有字符串都放到緩沖區(qū)中,放入緩沖區(qū)的時候雖然也可能觸發(fā)緩沖區(qū)擴(kuò)容,但比起".."連接符每次創(chuàng)建一個新的字符串消耗要小很多,然后拼接完成后返回僅僅一個新的字符串:
不適用的場景:
要拼接的字符串?dāng)?shù)量較少、長度較短,此時可能創(chuàng)建并GC回收一個Table的消耗會比直接用".."更大。
3)String類型CPU與內(nèi)存優(yōu)化——使用".."連接符拼接字符串應(yīng)盡可能一次性把更多的待拼接的子字符串都寫上
測試樣例 :把數(shù)字0到5拼接成"012345"。
錯誤寫法1 :
**
local sumStr = "0"sumStr = sumStr .. "1"sumStr = sumStr .. "2"sumStr = sumStr .. "3"sumStr = sumStr .. "4"sumStr = sumStr .. "5"
**
錯誤寫法2(加括號其實跟獨(dú)立一行運(yùn)算效果差不多,只是節(jié)省了一個賦值操作的OpCode) :
local sumStr = (((("0" .. "1") .. "2") .. "3") .. "4") .. "5"正確寫法 :
local sumStr = "0" .. "1" .. "2" .. "3" .. "4" .. "5"測試樣例及性能差異(循環(huán)100 0000次消耗):
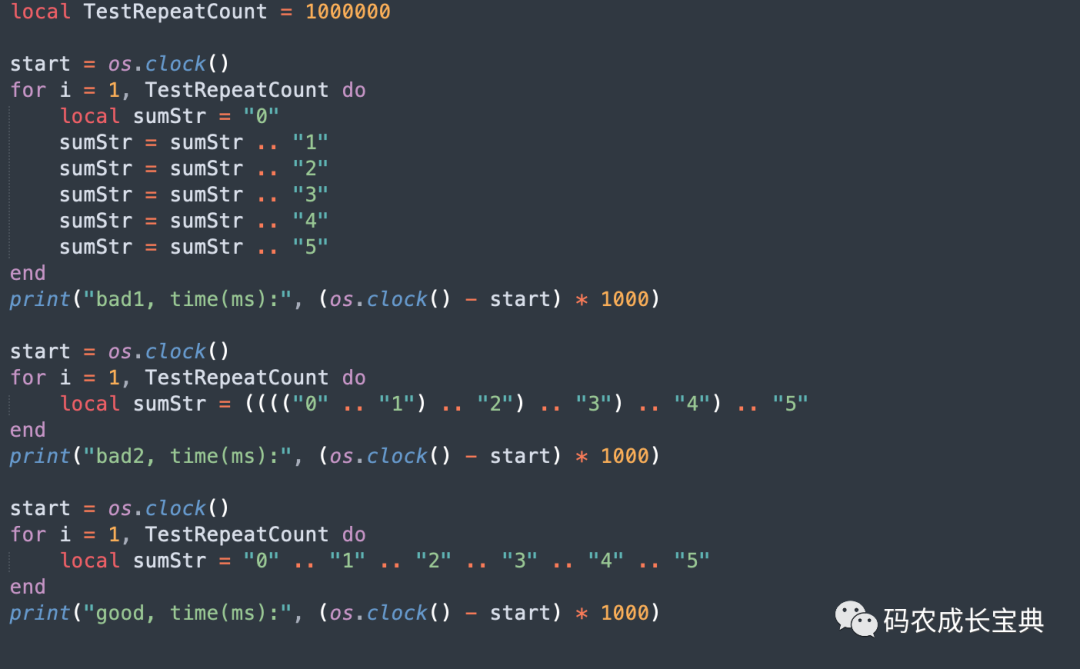
結(jié)果(耗時減少了100多毫秒,同時運(yùn)算中內(nèi)存占用也會大幅減少):

原理分析: ".."連接符號對應(yīng)的OpCode為OP_CONCAT,它的功能不僅僅是連接兩個字符串,而是會把以".."連接符號相鄰的所有字符串結(jié)合為一個操作批次,把它們一次性連接起來,同時也會避免產(chǎn)生中間連接臨時字串符。
由于字符串緩存機(jī)制的存在,在上述錯誤寫法1、2中,會產(chǎn)生無用中間字符串產(chǎn)物:"01","012","0123","0124";它們會導(dǎo)致內(nèi)存的上升和加重后續(xù)GC的工作量。而正確寫法則只會產(chǎn)生最終"012345"這僅僅一個字符串。
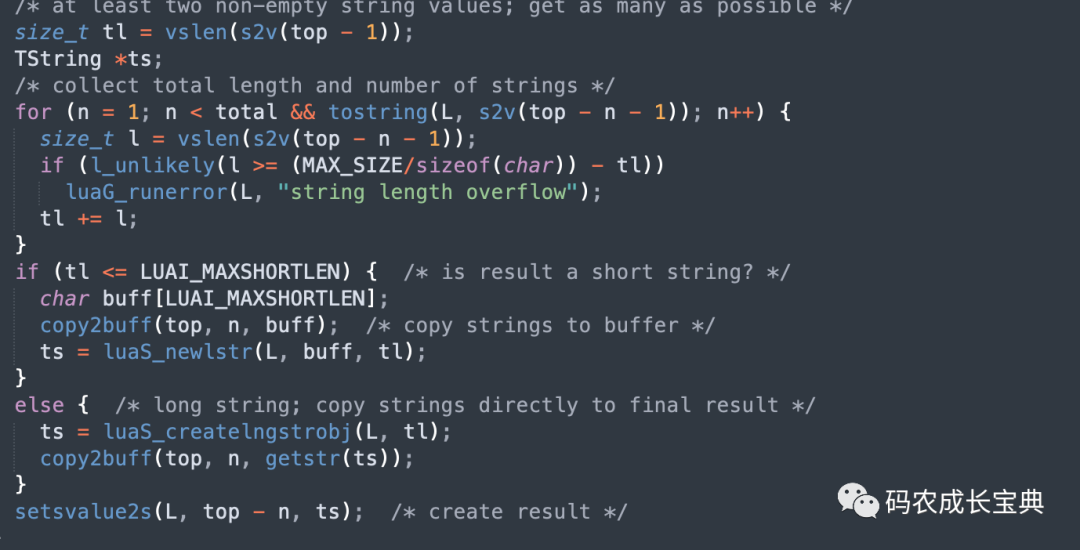
OP_CONCAT實現(xiàn)核心邏輯如下,會先計算出結(jié)果字符串長度,然后一次性創(chuàng)建出對應(yīng)大小的字符串緩沖區(qū),把所有子串放進(jìn)去,然后返回僅僅一個新的字符串:
OpCode對比:
錯誤寫法2:
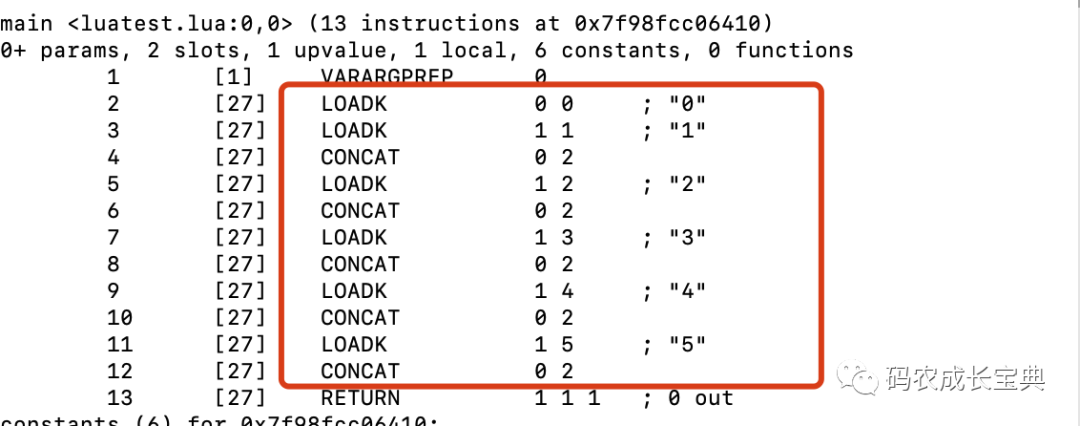
正確寫法(一條OP_CONCAT就可以完成所有拼接操作):
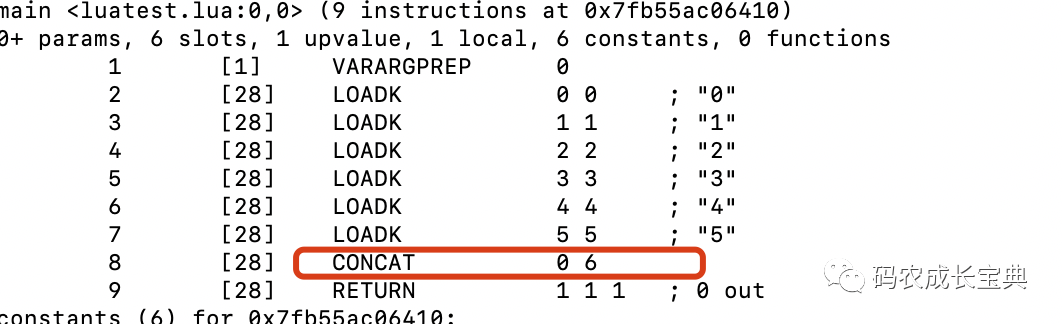
4)Table類型CPU優(yōu)化——盡量在table構(gòu)造時完成數(shù)據(jù)初始化
測試樣例 :創(chuàng)建一個初始值為1, 2, 3的Table;
錯誤寫法:
local t = {}t[1] = 1t[2] = 2t[3] = 3
正確寫法:
local t = {1, 2, 3}測試樣例及性能差異(循環(huán)10 0000次消耗):
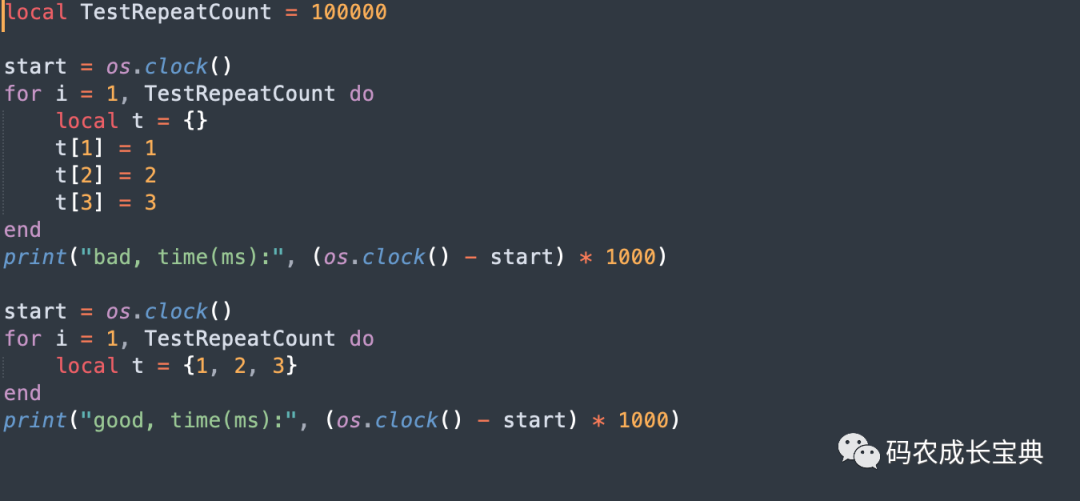
結(jié)果(節(jié)省35毫秒):

原理分析:
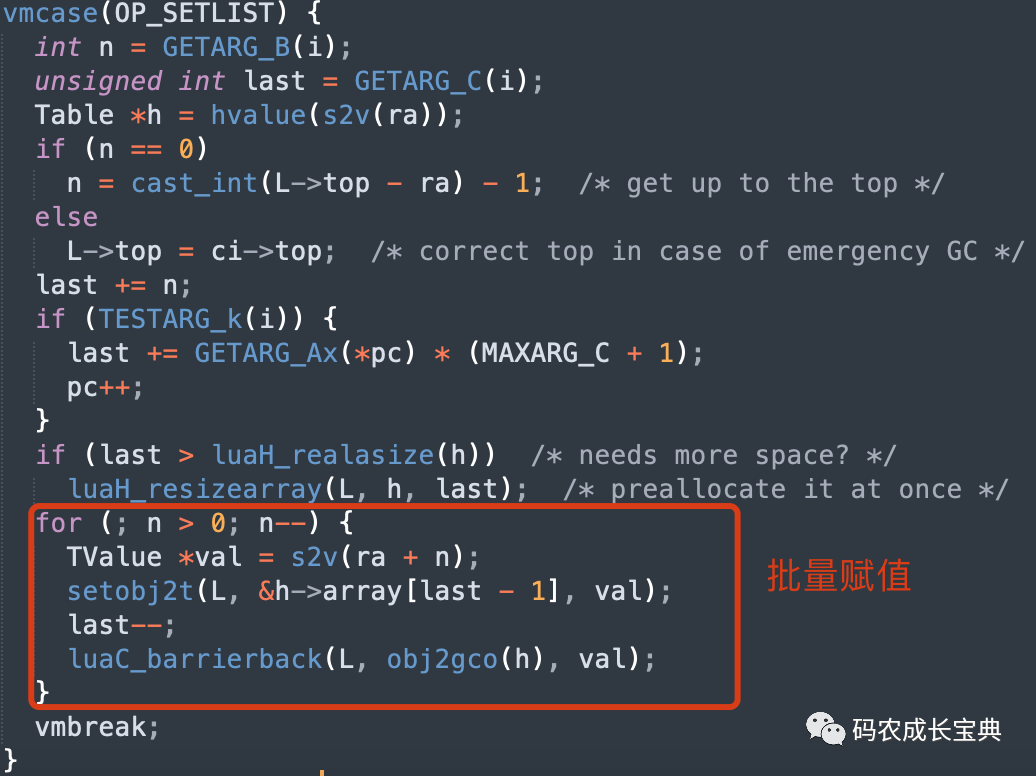
Table在使用"{}"列表形式進(jìn)行賦值的時候,會把其中數(shù)組部分的所有數(shù)據(jù)合并成一條OP_SETLIST指令(哈希部分無法通過此方式優(yōu)化),在里面批量一次性完成所有數(shù)組元素的賦值。而使用t[i]=value的形式進(jìn)行賦值,則每次都會調(diào)用一條OpCode,會生成更多的OpCode指令。
OP_SETLIST實現(xiàn)如下:
OpCode對比:
錯誤寫法:
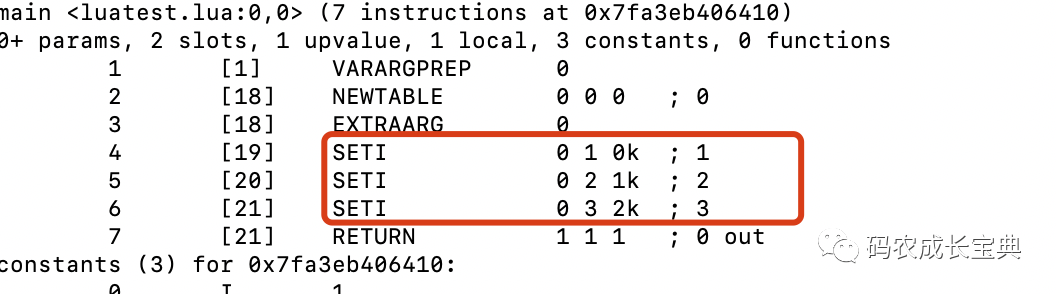
正確寫法(生成的OpCode的數(shù)量雖然更多了,但OP_LOADI的消耗遠(yuǎn)比上面的OP_SETI要小):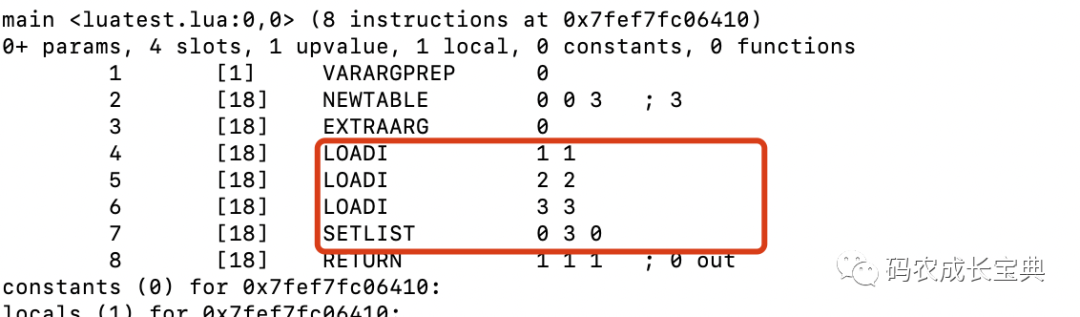
5)Table類型內(nèi)存優(yōu)化——Table關(guān)聯(lián)到類似excel的只讀數(shù)據(jù)表時,頻繁出現(xiàn)的復(fù)雜類型數(shù)據(jù)可以單獨(dú)定義為一個local變量進(jìn)行復(fù)用
測試樣例 :4條射線,射線用Table進(jìn)行表示,它有一個起點(diǎn)坐標(biāo)和一個方向;多數(shù)時候起點(diǎn)為(0, 0, 0)坐標(biāo)。
錯誤寫法:
local Ray1 = {origin = {x = 0, y = 0, z = 0},direction = {x = 1, y = 0, z = 0},}local Ray2 = {origin = {x = 0, y = 0, z = 0},direction = {x = -1, y = 0, z = 0},}local Ray3 = {origin = {x = 1, y = 0, z = 0},direction = {x = 1, y = 0, z = 0},}local Ray4 = {origin = {x = 1, y = 0, z = 0},direction = {x = -1, y = 0, z = 0},}
正確寫法:
local x0_y0_z0 = {x = 0, y = 0, z = 0}local x1_y0_z0 = {x = 1, y = 0, z = 0}local xn1_y0_z0 = {x = -1, y = 0, z = 0}local Ray1 = {origin = x0_y0_z0,direction = x1_y0_z0,}local Ray2 = {origin = x0_y0_z0,direction = xn1_y0_z0,}local Ray3 = {origin = x1_y0_z0,direction = x1_y0_z0,}local Ray4 = {origin = x1_y0_z0,direction = xn1_y0_z0,}
原理分析:
正確寫法在數(shù)據(jù)賦值的時候效率也會更高,不過該優(yōu)化更多的是針對內(nèi)存。被復(fù)用的復(fù)雜結(jié)構(gòu)對象單獨(dú)定義,然后用到的每個對象實例只存儲它的一個引用,避免了重復(fù)的數(shù)據(jù)定義,能極大降低內(nèi)存占用。
6)Table類型內(nèi)存優(yōu)化——Table關(guān)聯(lián)到類似excel的只讀數(shù)據(jù)表時,默認(rèn)值的查詢可以使用元表和__index元方法
測試樣例 :班級內(nèi)部有一個學(xué)生信息表,學(xué)生有姓名,年齡,年級。該界學(xué)生默認(rèn)且最多都是12歲,上6年級。本例班級中有3名學(xué)生,其中2名學(xué)生信息都與默認(rèn)值一致,另外一名年紀(jì)與默認(rèn)值不一致。
錯誤寫法:
local Students1 = {name = "小明",age = 12,grade = 6}local Students2 = {name = "小紅",age = 12,grade = 6}local Students3 = {name = "小剛",-- 小剛年紀(jì)比同一屆的其它同學(xué)大一點(diǎn)點(diǎn)age = 13,grade = 6}
正確寫法:
local StudentsDefault = {__index = {age = 12,grade = 6}}local Students1 = {name = "小明",}setmetatable(Students1, StudentsDefault)local Students2 = {name = "小紅",}setmetatable(Students2, StudentsDefault)local Students3 = {name = "小剛",-- 小剛年紀(jì)比同一屆的其它同學(xué)大一點(diǎn)點(diǎn)age = 13,}setmetatable(Students3, StudentsDefault)
原理分析:
把所有對象的字段默認(rèn)值獨(dú)立出來進(jìn)行定義,不用每個對象都定義一堆相同的字段,當(dāng)字段與默認(rèn)值不一致時才需要重新定義,減少了重復(fù)數(shù)據(jù)的內(nèi)存占用。當(dāng)對一個對象實例查詢其字段數(shù)據(jù)的時候,若字段未定義,則代表該字段沒有或者采用了默認(rèn)值,此時會通過元方法__index在默認(rèn)值元表對象中進(jìn)行查詢,以多一層的數(shù)據(jù)查詢性能開銷換來內(nèi)存的大幅減少。
7)Function類型 內(nèi)存、堆棧優(yōu)化—— 函數(shù)遞歸調(diào)用時盡量使用尾調(diào)用的方式
測試樣例 :以函數(shù)遞歸的方式求1,2,...到n的和。
錯誤寫法:
local function BadRecursionFunc(n)if n > 1 thenreturn n + BadRecursionFunc(n - 1)endreturn 0end
正確寫法:
local function GoodRecursionFunc(sum, n)if n > 1 thenreturn GoodRecursionFunc(sum + n, n - 1)endreturn sum, 0end
當(dāng)n為10 0000:
結(jié)果如下(節(jié)省14毫秒):

當(dāng)n為100 0000:
錯誤寫法會直接報錯,Lua運(yùn)行堆棧溢出了:

而正確寫法能正常運(yùn)算出結(jié)果,消耗為26毫秒:

原理分析:
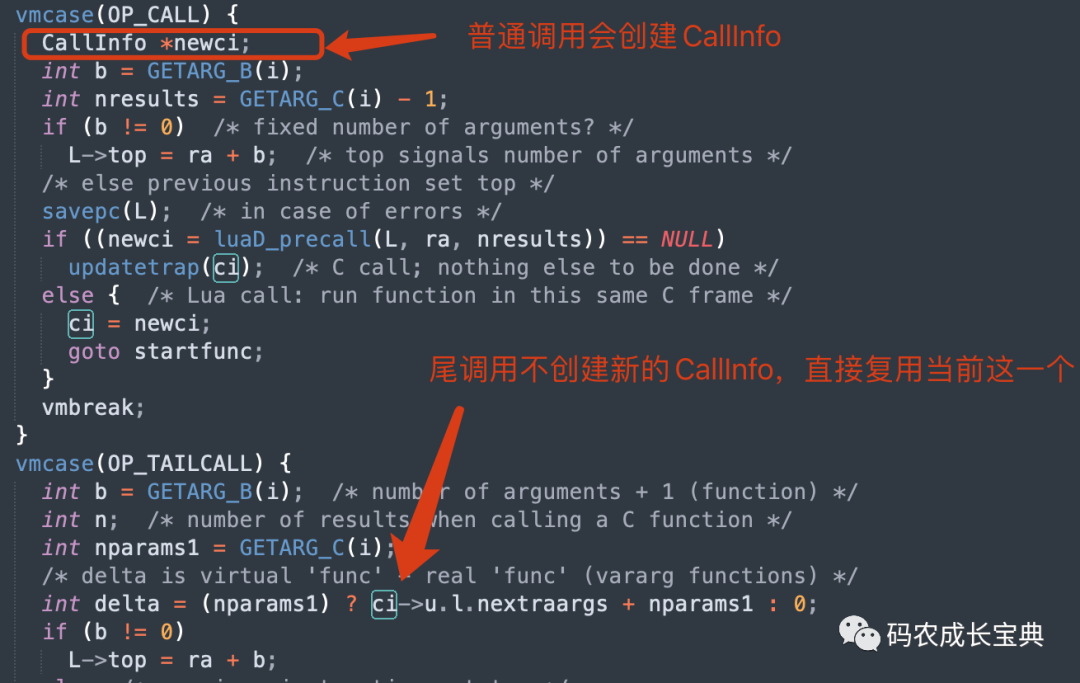
Lua的函數(shù)調(diào)用在return 的時候,若直接單純調(diào)用另外一個函數(shù),則會使用尾調(diào)用的方式,在尾調(diào)用模式下,會復(fù)用之前的CallInfo與函數(shù)堆棧。所以無論樣例中的n多大、遞歸層次多深,都不會造成堆棧溢出。
OpCode實現(xiàn)對比,OP_CALL為普通函數(shù)調(diào)用,會創(chuàng)建CallInfo;OP_TAILCALL為尾調(diào)用,直接復(fù)用CallInfo:
8)Thread類型CPU、內(nèi)存優(yōu)化——不需要多個協(xié)程并行運(yùn)行時,盡量復(fù)用同一個協(xié)程,協(xié)程的創(chuàng)建與銷毀開銷較大
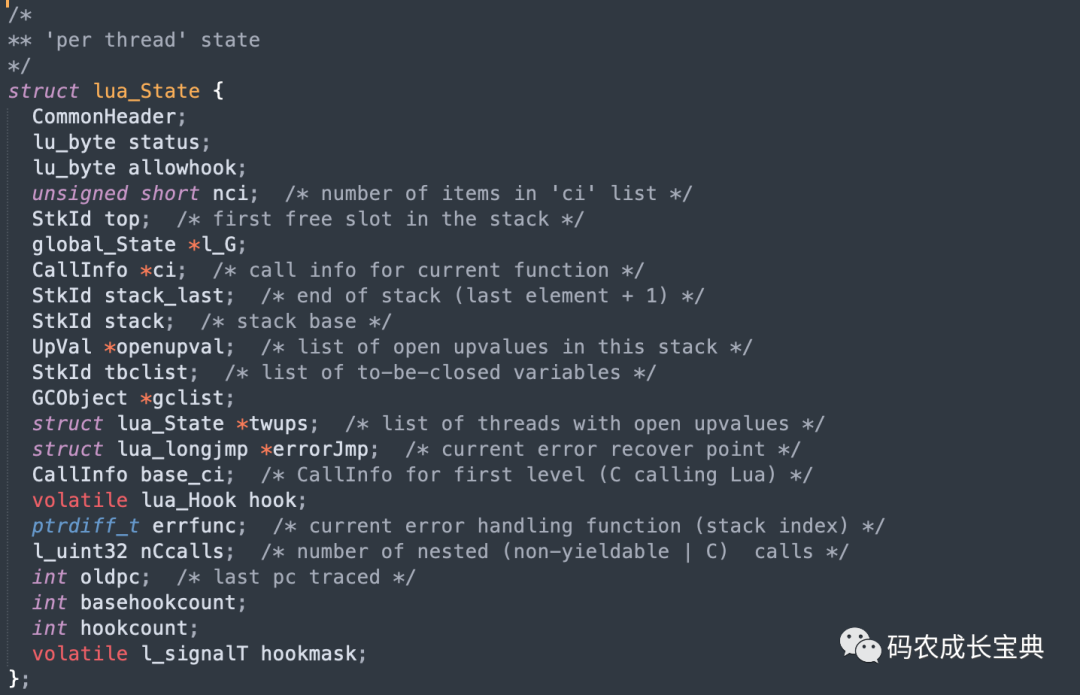
Lua中Thread類型其實就是協(xié)程(Coroutine),每一個協(xié)程的創(chuàng)建都會創(chuàng)建一個lua_State對象,該對象字段繁多,初始化或者銷毀邏輯復(fù)雜,定義如下圖:
測試樣例 :用協(xié)程執(zhí)行3個不同的函數(shù),但不要求它們同時并行執(zhí)行。
錯誤寫法:
local function func1()endlocal function func2()endlocal function func3()endlocal ff = coroutine.wrap(func1)f()f = coroutine.wrap(func2)f()f = coroutine.wrap(func3)f()
正確寫法(復(fù)用同一個協(xié)程,下面的co變量):
local function func1()endlocal function func2()endlocal function func3()endlocal co = coroutine.create(function(f)while(f) dof = coroutine.yield(f())endend)coroutine.resume(co, func1)coroutine.resume(co, func2)coroutine.resume(co, func3)
測試樣例及性能差異(循環(huán)1 0000次消耗):
結(jié)果(節(jié)省18毫秒):

原理分析:
每一個協(xié)程的創(chuàng)建都會創(chuàng)建出一個lua_State對象,如上面的定義,它字段繁多,而且邏輯復(fù)雜,創(chuàng)建與銷毀的開銷極大。協(xié)程創(chuàng)建的時候最終會創(chuàng)建Thread類型對象,源碼實現(xiàn)如下,會創(chuàng)建一個lua_State:
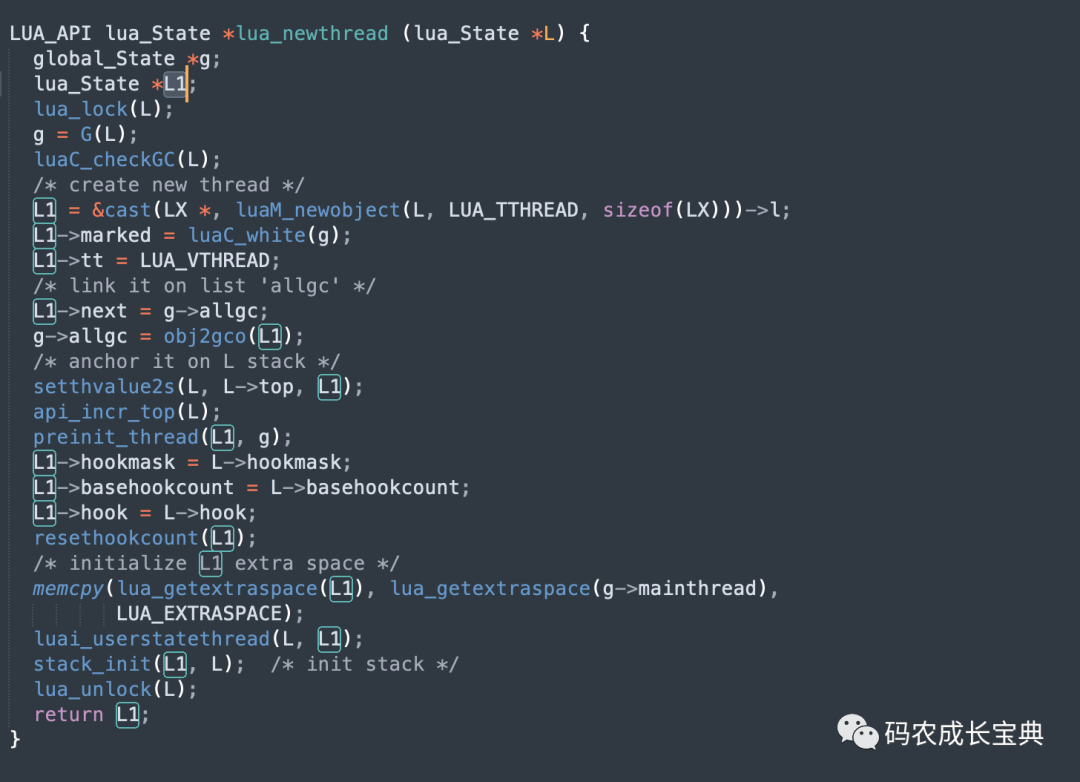
所以通過特定的寫法重復(fù)使用同一個協(xié)程能極大優(yōu)化性能與內(nèi)存。
2星優(yōu)化
推薦程度:較為推薦,使用簡單,但優(yōu)化收益一般。
1)Table類型CPU優(yōu)化——數(shù)據(jù)插入盡量使用t[key]=value的方式而不使用table.insert函數(shù)
測試樣例 :把1到1000000之間的數(shù)字插入到table中。
錯誤寫法:
local t = {}
local table_insert_func = table.insert
for i = 1, 1000000 do
table_insert_func(t, i)
end
正確寫法:
local t = {}for i = 1, 1000000 dot[i] = iend
測試樣例及性能差異(循環(huán)100 0000次消耗):
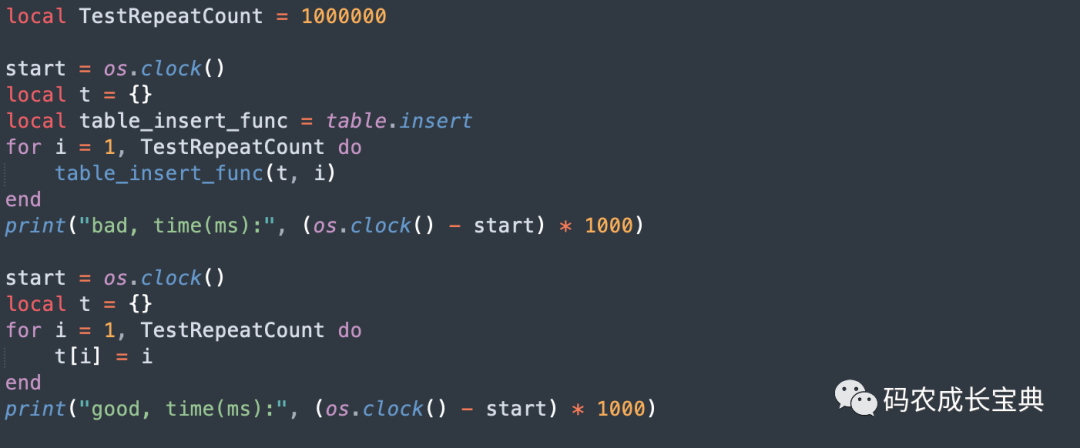
結(jié)果(節(jié)省40毫秒):

原理分析:
通過t[integer_key]=value或者t[string_key]=value的方式插入數(shù)據(jù),只會生成OP_SETI或者OP_SETFIELD一條OpCode,會直接往Table的數(shù)組或哈希表部分插入數(shù)據(jù);而通過table.insert函數(shù)插入數(shù)據(jù),會多出以下這堆邏輯:1)table.insert這一個函數(shù)的查詢定位(上述樣例中使用local緩存優(yōu)化了);
2)暫不考慮table.insert函數(shù)的邏輯,單純函數(shù)的調(diào)用就會有創(chuàng)建CallInfo,參數(shù)準(zhǔn)備,返回處理等固定開銷;3)table.insert函數(shù)對參數(shù)的判斷與table類型對象的獲取與轉(zhuǎn)化;4)為了在table的最尾端插入數(shù)據(jù),需要計算table當(dāng)前的數(shù)組部分長度;
OpCode對比:
錯誤寫法(table.insert):

正確寫法(t[i]=value):

明顯使用t[key]=value方式插入數(shù)據(jù)能減少較多的指令或邏輯,對CPU優(yōu)化有一定效果。
1星優(yōu)化
推薦程度:一般推薦,某種程度上來說屬于吹毛求疵,有一定優(yōu)化收益,但可能影響可讀性、或者需要特定場景配合實現(xiàn)。
1)全類型通用CPU優(yōu)化——變量盡量在定義的同時完成賦值
測試樣例: 把變量a初始化為一個整數(shù)。
錯誤寫法:
local aa = 1
正確寫法:
local a = 1測試樣例及性能差異(循環(huán)100 0000次消耗):

結(jié)果(耗時減少了2毫秒):

原理分析:
錯誤寫法中第一行的local a其實與local a = nil是等價的,底層會生成OP_LOADNIL這條OpCode,來創(chuàng)建出一個nil對象,第二行則又調(diào)用了另一條OpCode完成真正賦值;而正確寫法中則會省略掉第一條的OP_LOADNIL。
OpCode對比:
錯誤寫法(2條OpCode,分別對應(yīng)nil類型的創(chuàng)建與整數(shù)的加載賦值):

正確寫法(只生成一條整數(shù)加載的OpCode):

2)Nil類型CPU優(yōu)化——nil對象在定義的時候盡量相鄰,中間不要穿插其它對象
測試樣例 :定義6個變量,其中3個為nil,3個為整數(shù)100。
錯誤寫法:
local a = nillocal b = 100local c = nillocal d = 100local e = nillocal f = 100
正確寫法(把nil的賦值排在相鄰的位置):
local a = nillocal c = nillocal e = nillocal b = 100local d = 100local f = 100
測試樣例及性能差異(循環(huán)100 0000次消耗):
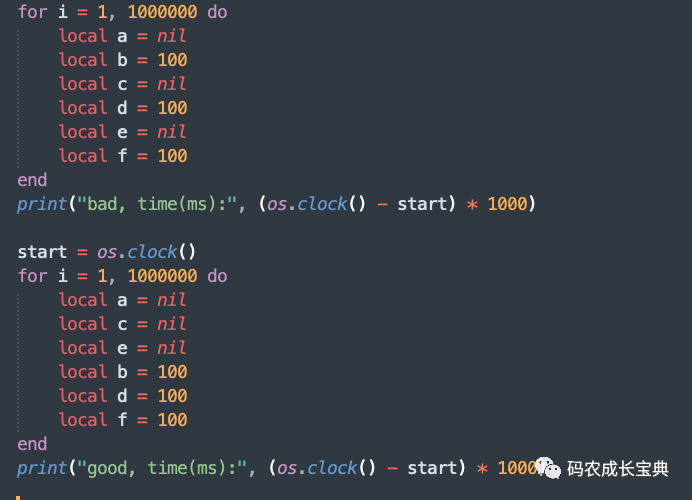
結(jié)果(耗時減少了4毫秒):

原理分析:
賦值或者加載一個nil對象的OpCode為OP_LOADNIL,它支持把棧上面連續(xù)的一定數(shù)量的對象都設(shè)置為nil。若中間被隔開了,則后面的調(diào)用需要重新生成OP_LOADNIL。
OP_LOADNIL實現(xiàn):
OpCode對比:
錯誤寫法:
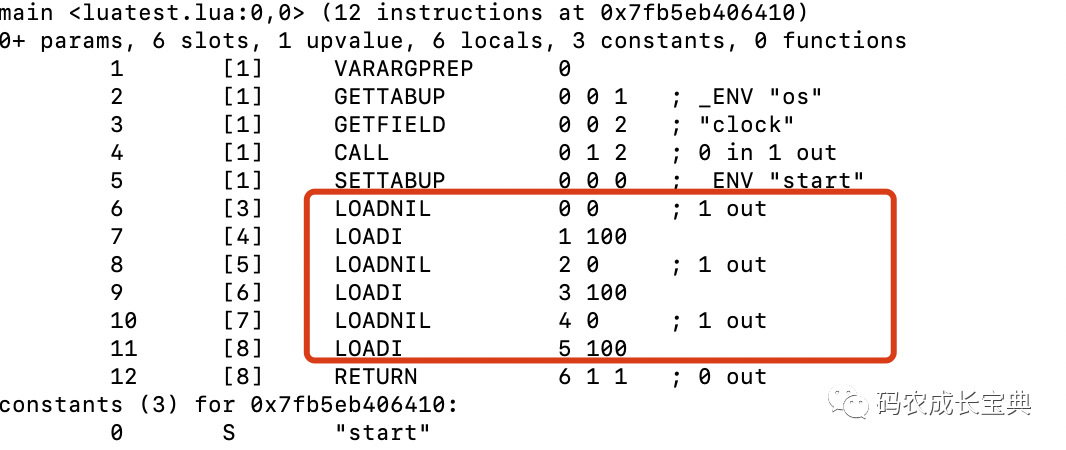
正確寫法(3條OP_LOADNIL合成了一條):
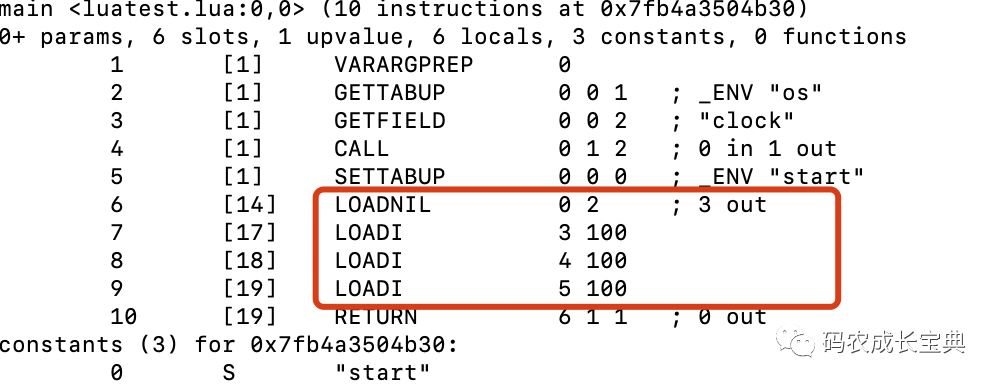
3)Function類型CPU優(yōu)化——不返回多余的返回值
測試樣例 :外部對函數(shù)進(jìn)行調(diào)用,只請求獲取第一個返回值。
錯誤寫法(返回了多余的對象):
local function BadRetFunc()local value1 = 1local value2 = 2local value3 = 3local value4 = 4local value5 = 5return value1, value2, value3, value4, value5endlocal ret = BadRetFunc()
正確寫法(外部調(diào)用者需要多少個返回值就返回多少個):
local function GoodRetFunc()local value1 = 1local value2 = 2local value3 = 3local value4 = 4local value5 = 5return value1endlocal ret = GoodRetFunc()
測試樣例及性能差異(循環(huán)100 0000次消耗):
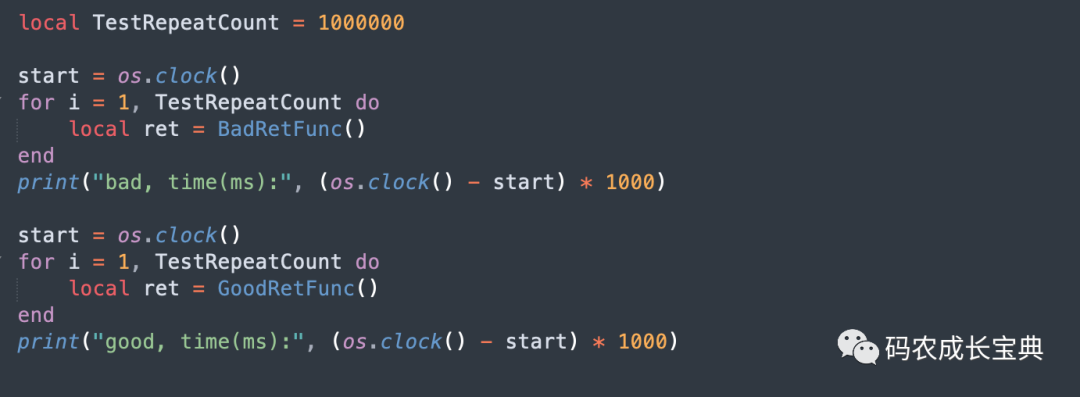
結(jié)果(節(jié)省12毫秒):

原理分析:
函數(shù)返回對應(yīng)的OpCode為OP_RETURN0,OP_RETURN1,OP_RETURN。它們的邏輯復(fù)雜度由小到大,消耗由小到大。返回值的增加一方面導(dǎo)致了調(diào)用更復(fù)雜的return的OpCode;另一方面則是調(diào)用這些return的OpCode之前,Lua需要先把所有返回值獲取并放到棧的頂部,會多執(zhí)行一些賦值操作。
OpCode對比:
錯誤寫法(多了一些OP_MOVE指令的調(diào)用,另外return的OpCode為最復(fù)雜的OP_RETURN):
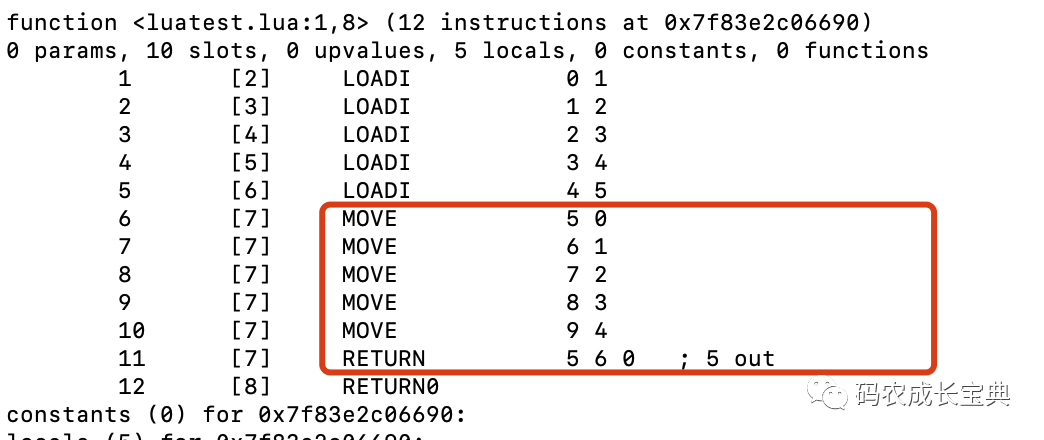
正確寫法(只調(diào)用了一條更簡單的return的OpCode,只需要一個返回值的OP_RETURN1):

0星優(yōu)化
推薦程度:無效優(yōu)化,不會帶來任何性能提升,也不會有性能下降,通常使用這種寫法是為了更好的代碼可讀性。
1)全類型通用 可讀性優(yōu)化—— for循環(huán)的終止條件不需要提前緩存
測試樣例 :for循環(huán),結(jié)束條件需要復(fù)雜的才能計算出來,為一個復(fù)雜函數(shù)的返回值。
錯誤寫法:
local function ComplexGetCount()for i = 1, 100 dolocal r = math.random()endreturn 100endlocal len = ComplexGetCount()for j = 1, len doend
正確寫法(不需要刻意緩存循環(huán)終止條件):
local function ComplexGetCount()for i = 1, 100 dolocal r = math.random()endreturn 100endfor j = 1, ComplexGetCount() doend
測試樣例及性能差異(循環(huán)1 0000次消耗):
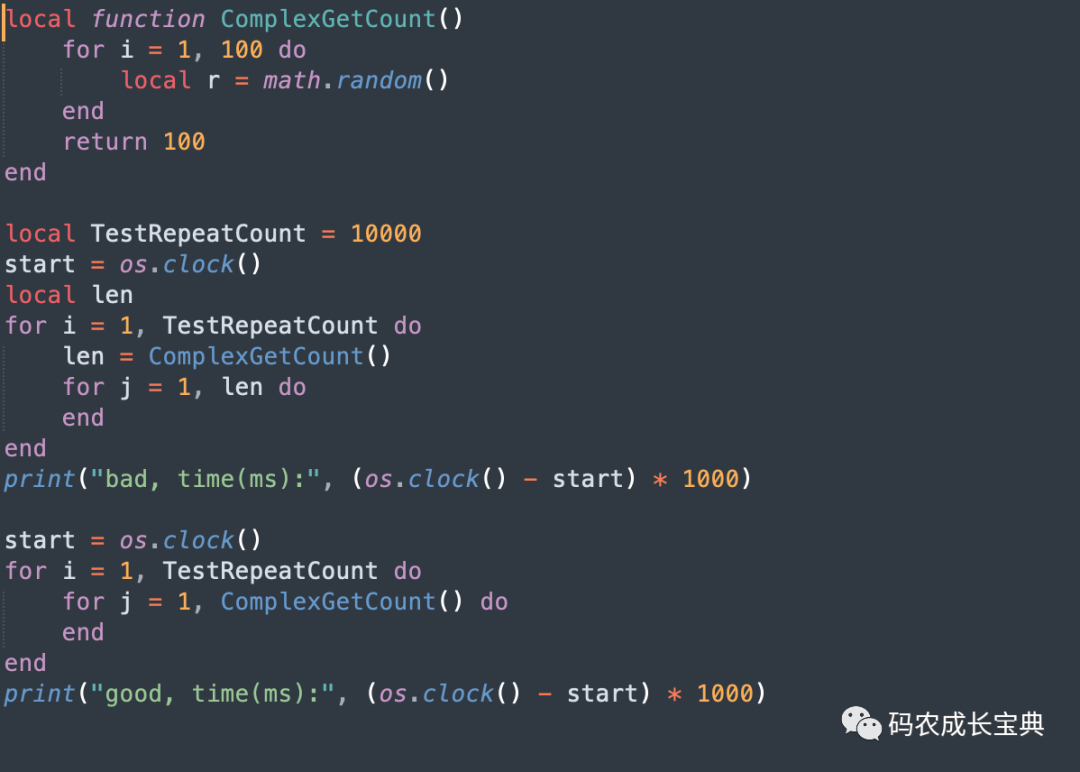
結(jié)果(消耗是一樣的):

原理分析:
有很多一些編程語言的循環(huán)語句中,會把結(jié)束條件視作一個動態(tài)的值,每輪循環(huán)結(jié)束會重新計算該值,然后再判斷循環(huán)是否終止。而在Lua中,循環(huán)表達(dá)式的終止條件是循環(huán)開始前就計算好了,只會計算一次,循環(huán)的過程中不會再被改變。
所以如果你覺得提前把循環(huán)結(jié)束條件計算出來,意圖在每輪循環(huán)中避免重復(fù)計算,那么這個操作在Lua中是多余沒有意義的,因為Lua語言本身就幫你做了這件事情。不過也正因如此,在Lua中無法在for 循環(huán)中動態(tài)修改循環(huán)結(jié)束條件控件循環(huán)次數(shù)。
OpCode對比:
正確寫法(循環(huán)體內(nèi)不會再有計算結(jié)束條件表達(dá)式的操作了):
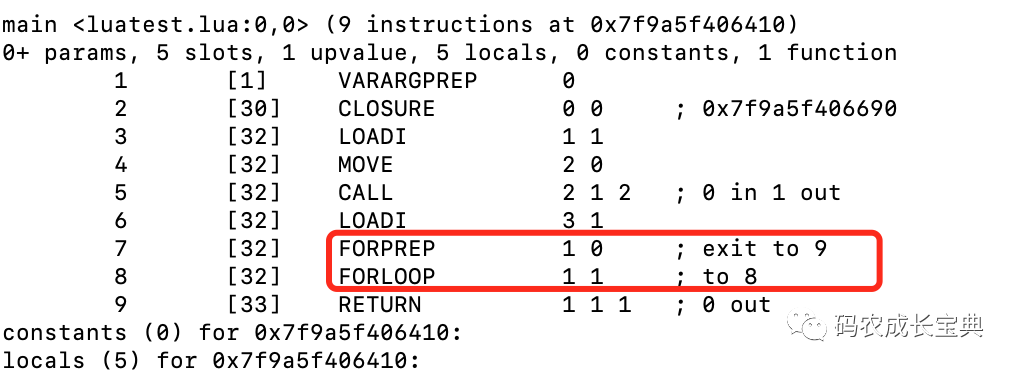
2)Nil類型可讀性優(yōu)化——初始化的時候顯示賦值和隱式賦值效果一樣
測試樣例 :定義一個nil類型變量a。
寫法1:
local a = nil寫法2(一些人以為的更好的寫法):
local a
原理分析: 無效優(yōu)化,上面兩種寫法在底層實現(xiàn)中是完全一模一樣的。兩種寫法最終都只是生成一條OP_LOADNIL的OpCode,寫法1并不會因為多了賦值符號就額外多生成其它的OpCode。
總結(jié)
本文我們從源碼虛擬機(jī)層面上對Lua語言多數(shù)較為有效的優(yōu)化手段進(jìn)行了一個學(xué)習(xí)。
-
處理器
+關(guān)注
關(guān)注
68文章
19795瀏覽量
233408 -
寄存器
+關(guān)注
關(guān)注
31文章
5416瀏覽量
123223 -
虛擬機(jī)
+關(guān)注
關(guān)注
1文章
962瀏覽量
28997 -
Lua語言
+關(guān)注
關(guān)注
0文章
9瀏覽量
1567
發(fā)布評論請先 登錄
Faster Transformer v2.1版本源碼解讀
PIC16LF1939的代碼性能分析
AN0004—AT32 性能優(yōu)化
重定義lua中文件操作的底層函數(shù)
《現(xiàn)代CPU性能分析與優(yōu)化》收到書了
《現(xiàn)代CPU性能分析與優(yōu)化》---精簡的優(yōu)化書
《現(xiàn)代CPU性能分析與優(yōu)化》--讀書心得筆記
使用Arm Streamline分析樹莓派的性能
STL源碼剖析的PDF電子書免費(fèi)下載

Linux性能分析工具perf詳解

Faster Transformer v1.0源碼詳解
SDAccel環(huán)境剖析和最優(yōu)化指南

BNC接頭技術(shù)原理與工程應(yīng)用剖析:從結(jié)構(gòu)到性能優(yōu)化






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論