 使用LabVIEW 實現物體識別、圖像分割、文字識別、人臉識別等深度視覺
使用LabVIEW 實現物體識別、圖像分割、文字識別、人臉識別等深度視覺
前言
哈嘍,各位朋友們,這里是virobotics(儀酷智能),這兩天有朋友私信問之前給大家介紹的工具包都可以實現什么功能,最新的一些模型能否使用工具包加載,今天就給大家介紹一下博主目前使用工具包已經實現的深度視覺模型及案例
下表為前期寫過的一些范例介紹,朋友們可以按需點擊查看
| 名字 | 鏈接 |
|---|---|
| 使用LabVIEW人工智能視覺工具包快速實現圖像讀取與采集 | [https://blog.csdn.net/virobotics/article/details/123663532] |
| 使用LabVIEW人工智能視覺工具包快速實現傳統Opencv算子的調用 | [https://blog.csdn.net/virobotics/article/details/123817051] |
| 使用LabVIEW OpenCV DNN實現手寫數字識別 | [https://blog.csdn.net/virobotics/article/details/123880476] |
| 使用LabVIEW OpenCV dnn實現圖像分類 | [https://blog.csdn.net/virobotics/article/details/123982933] |
| 使用LabVIEW OpenCV dnn實現物體識別(Object Detection) | [https://blog.csdn.net/virobotics/article/details/124008160] |
| 【YOLOv5】LabVIEW+YOLOv5快速實現實時物體識別(Object Detection) | [https://blog.csdn.net/virobotics/article/details/124929483] |
| 【YOLOv5】LabVIEW+OpenVINO讓你的YOLOv5在CPU上飛起來 | [https://blog.csdn.net/virobotics/article/details/124951862] |
| 【YOLOv5】使用LabVIEW ONNX Runtime部署 TensorRT加速,實現YOLOv5實時物體識別 | [https://blog.csdn.net/virobotics/article/details/124981658] |
| 使用LabVIEW實現Mask R-CNN圖像實例分割 | [https://blog.csdn.net/virobotics/article/details/125194701] |
| 使用LabVIEW實現基于pytorch的DeepLabv3圖像語義分割 | [https://blog.csdn.net/virobotics/article/details/124998636] |
| 使用LabVIEW實現 DeepLabv3+ 語義分割 | [https://blog.csdn.net/virobotics/article/details/125264040] |
| LabVIEW+OpenVINO在CPU上部署新冠肺炎檢測模型實戰 | [https://blog.csdn.net/virobotics/article/details/125260923] |
| YOLOX目標檢測實戰:LabVIEW+YOLOX ONNX模型實現推理檢測 | [https://blog.csdn.net/virobotics/article/details/125412732] |
| 百度飛槳PP-YOLOE ONNX 在LabVIEW中的部署推理 | [https://blog.csdn.net/virobotics/article/details/126231434] |
| YOLOv6在LabVIEW中的推理部署 | [https://blog.csdn.net/virobotics/article/details/126356929] |
| LabVIEW圖形化的AI視覺開發平臺(非NI Vision)VI簡介 | [https://blog.csdn.net/virobotics/article/details/127497688] |
| 儀酷LabVIEW AI視覺工具包及開放神經網絡交互工具包常見問題解答 | [https://blog.csdn.net/virobotics/article/details/127449831] |
如您想要探討更多關于LabVIEW與人工智能技術,加入我們:705637299。
一、實現物體識別
無論使用何種框架訓練物體檢測模型,都可以無縫集成到LabVIEW中,并使用工具包提供的CUDA、tensorRT接口實現加速推理,模型包括但不限于:
- yolov3、yolov4、yolov5、yolov6、yolov7、pp-yoloe、yolox等
- torchvision中的圖像分類、目標檢測模型等
如下為已經實現中的一部分范例
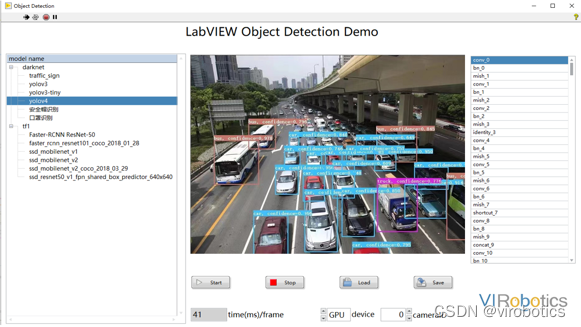
- yolov4實現目標檢測:
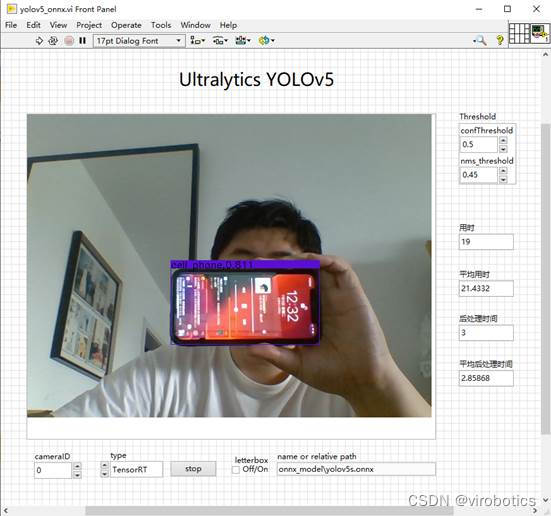
- 基于onnx,yolov5使用tensorRT實現推理加速:
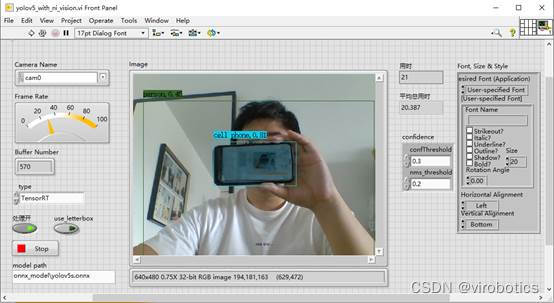
- NI vision采集圖像、tensorRT加速實現yolov5目標檢測
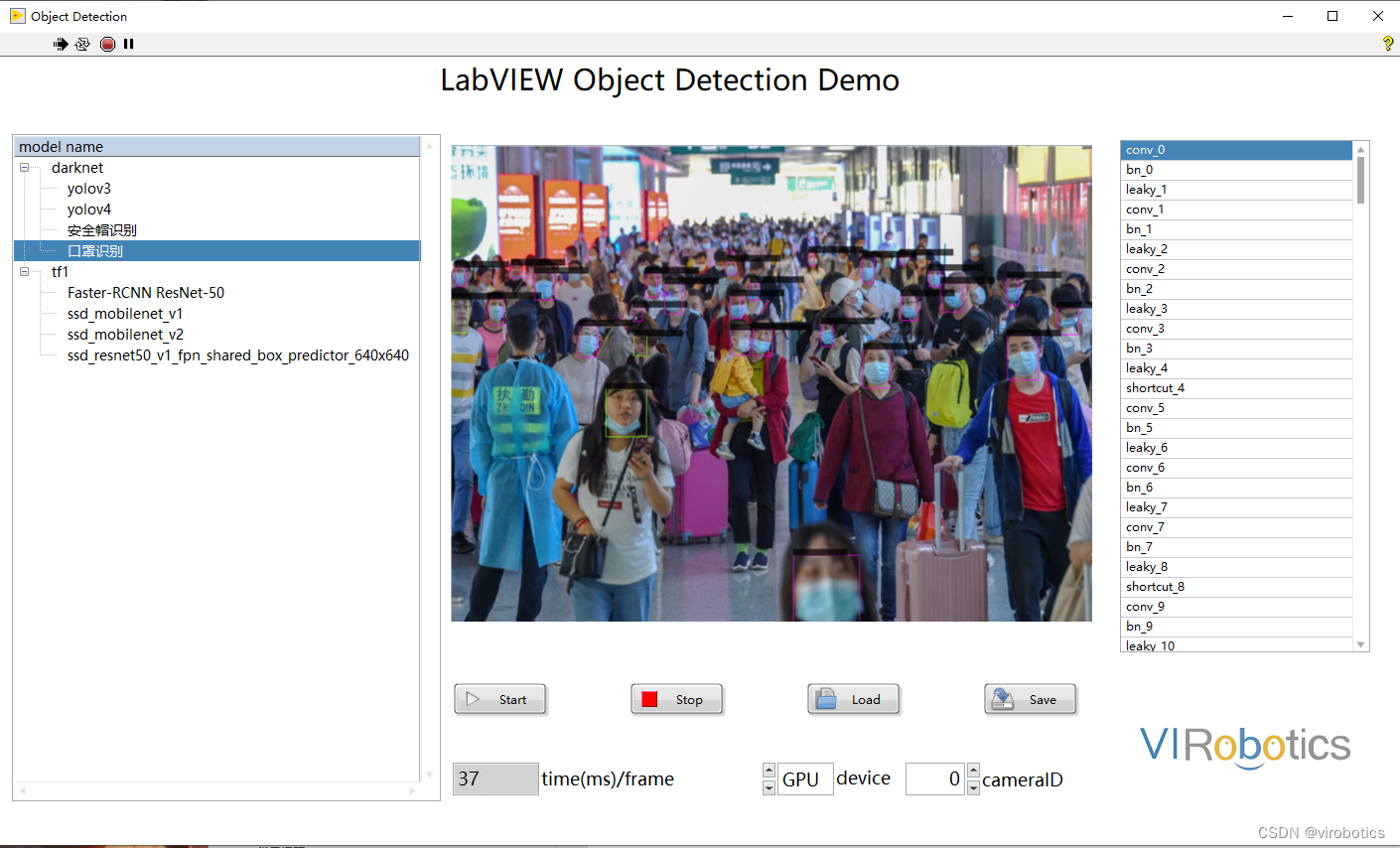
- yolov5實現口罩檢測:
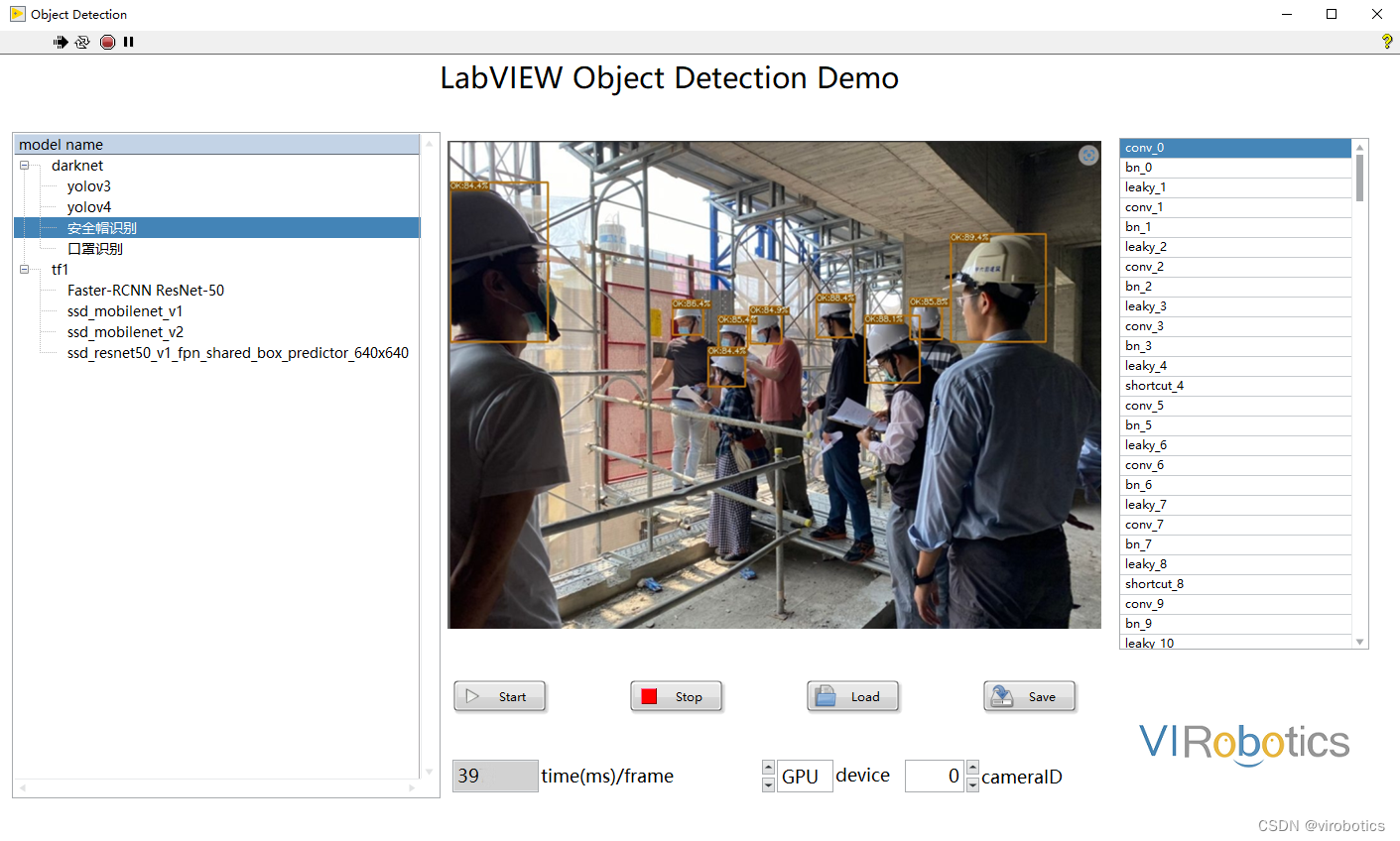
- yolov5實現安全帽檢測:
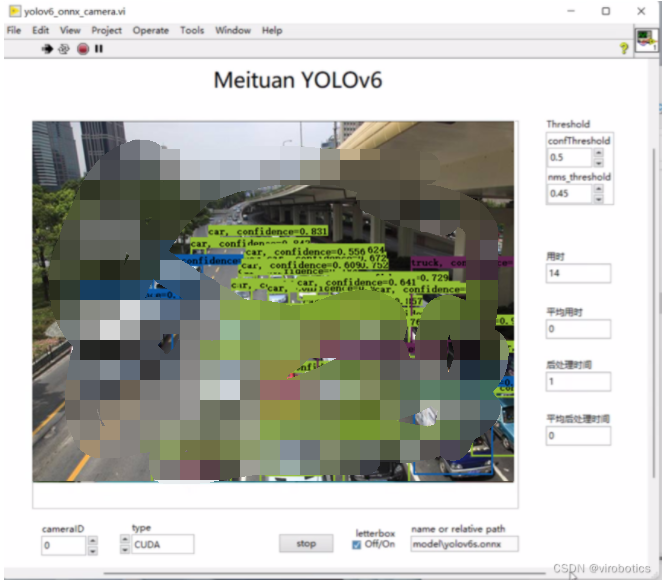
- yolov6實現目標檢測:
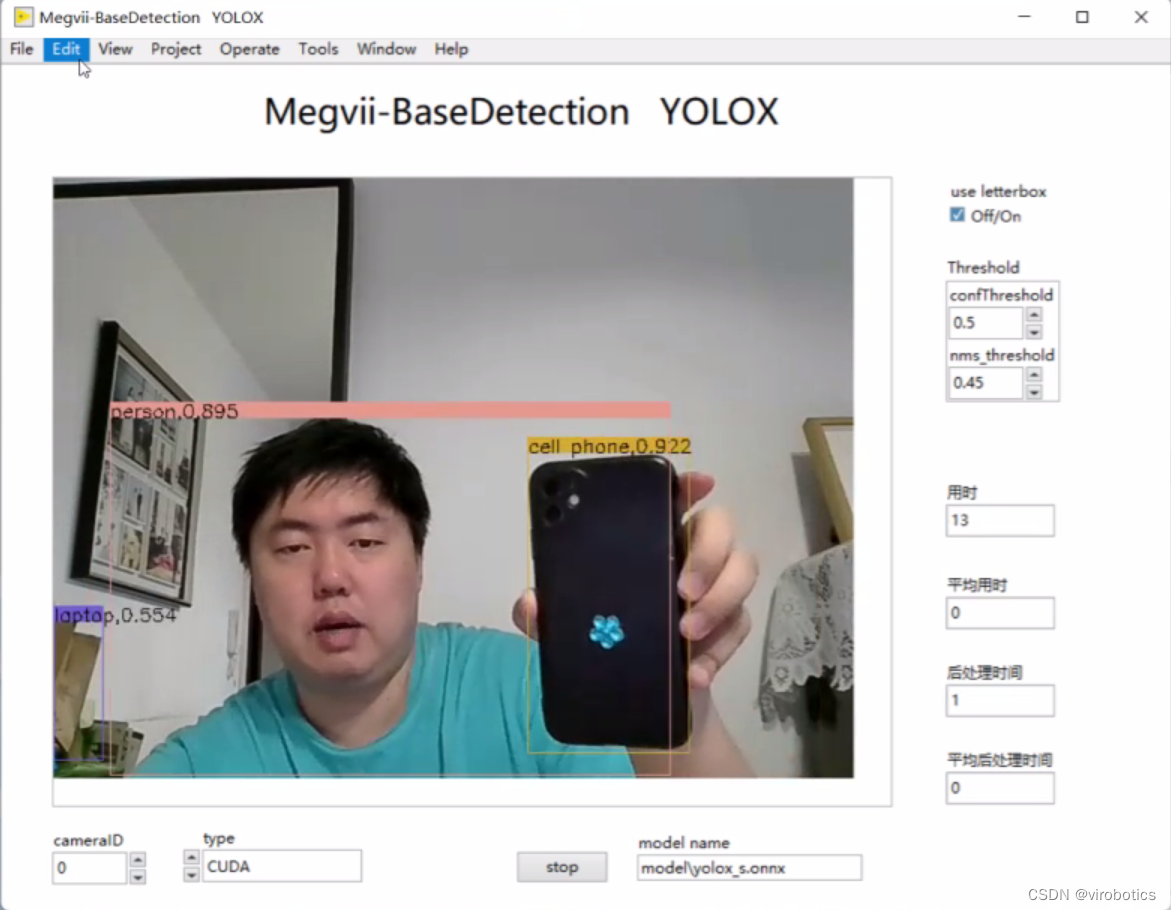
- yolox實現目標檢測:
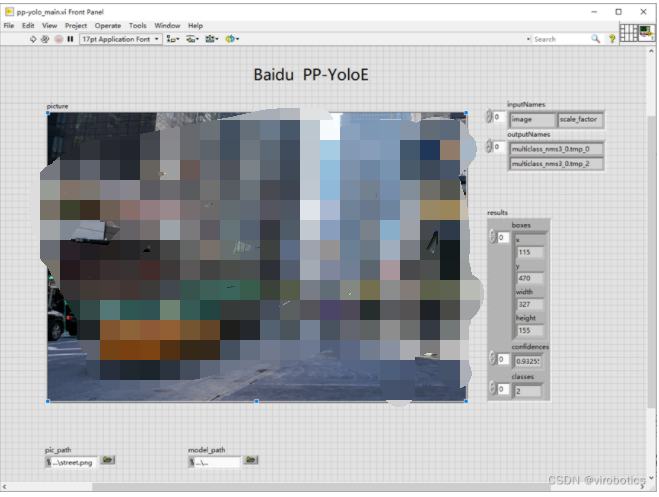
- 百度PP-YOLOE實現目標檢測:
二、實現圖像分割
圖像分割是當今計算機視覺領域的關鍵問題之一。從宏觀上看,圖像分割是一項高層次的任務,為實現場景的完整理解鋪平了道路。場景理解作為一個核心的計算機視覺問題,其重要性在于越來越多的應用程序通過從圖像中推斷知識來提供營養。隨著深度學習軟硬件的加速發展,一些前沿的應用包括自動駕駛汽車、人機交互、醫療影像等,都開始研究并使用圖像分割技術。
本次集成的工具包提供了多種圖像分割的調用模塊,并實現了GPU模式下TensorRT的加速運行。如:
語義分割:Segnet、deeplabv1~deeplabv3、deeplabv3+、u-net等;
實例分割:Mask-RCNN、PANet等
- deeplab實現分割
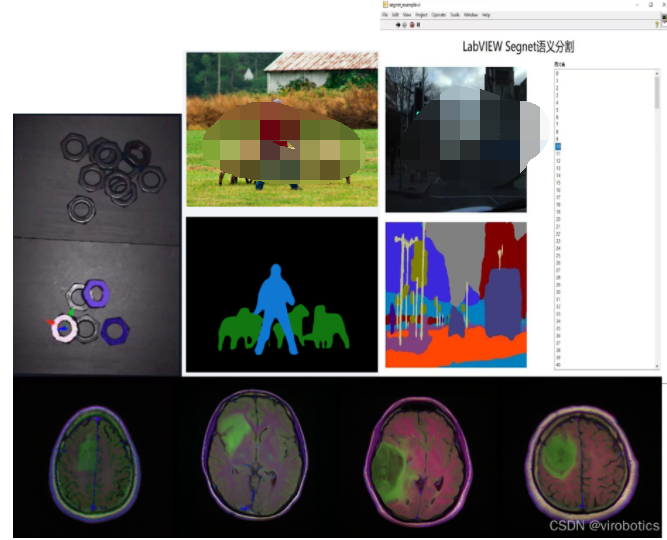
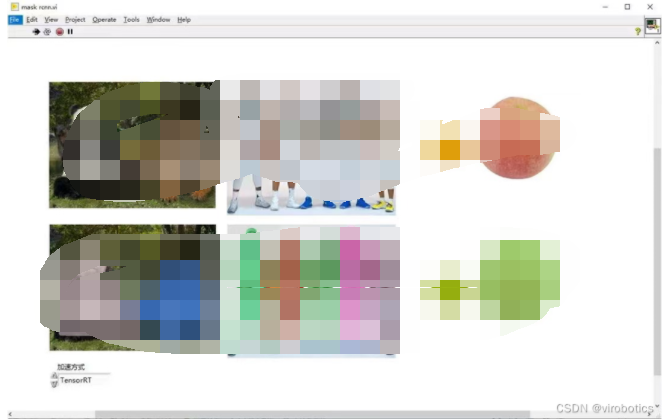
- mask Rcnn實現圖像分割
三、自然場景下的文字識別
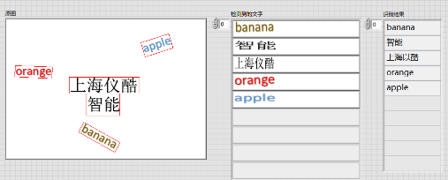
工具包提供了文本檢測定位(DB_TD500_resnet50、EAST)、文本識別的模塊(CRNN),用戶可以使用該模塊實現自然場景下的中英文文字識別
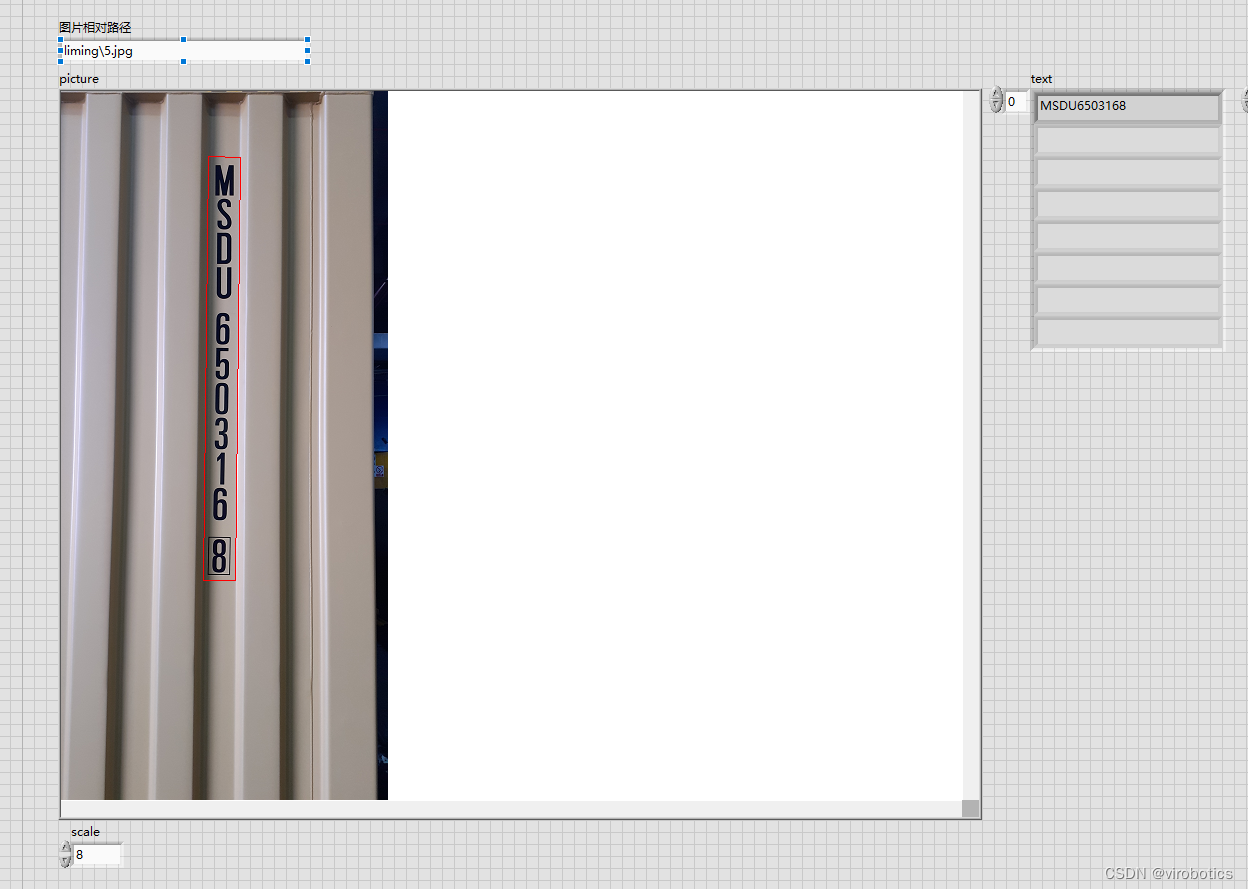
應用:身份證識別、表單識別、包裝盒標簽檢測等
- 簡單文字識別
- 包裝盒標簽檢測

- 復雜背景字母數字檢測
四、人臉檢測與識別
工具包提供了人臉檢測與識別的模塊,用戶可以使用該模塊實現人臉檢測與識別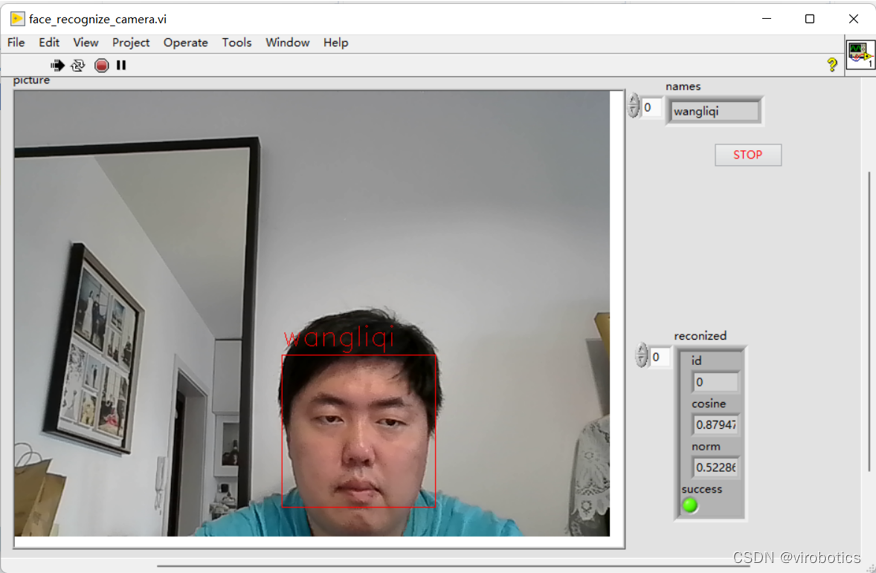
五、人體關鍵點檢測
機器學習ML5擴展功能中的Keypoint Rcnn功能可以實現17個人體姿態識別以及追蹤位置,通過此功能可以進行一些姿態控制應用,且此功能不用連接網絡,只需要一個攝像頭即可實現。
姿勢估計是指計算機視覺技術,用于檢測圖像和視頻中的人類圖形,以便確定某人的肘部出現在圖像中的位置。需要說明的是,該技術無法識別圖像中的人員,不存在與姿勢檢測相關的個人身份信息。該算法只是估計關鍵體關節的位置
結合了Realsense的姿態識別,即可定位人體每個部位的精確位置。

六、工具包下載
如需下載工具包可查看指定博文,如需獲取最新版本工具包,可關注微信公眾號:VIRobotics,回復關鍵字:LabVIEW AI工具包
總結
以上就是今天要給大家分享的內容。如有筆誤,還請各位及時指正。后續還會繼續給各位朋友分享其他案例,歡迎大家關注博主。
如果有問題可以在評論區里討論,提問前請先點贊支持一下博主哦
**如果文章對你有幫助,歡迎?關注、
審核編輯 黃宇
-
LabVIEW
+關注
關注
1995文章
3670瀏覽量
333067 -
人工智能
+關注
關注
1804文章
48684瀏覽量
246392 -
人臉識別
+關注
關注
76文章
4069瀏覽量
83644 -
計算機視覺
+關注
關注
9文章
1706瀏覽量
46563 -
深度學習
+關注
關注
73文章
5554瀏覽量
122470
發布評論請先 登錄






 工商網監
工商網監
評論