 Linux 性能優化總結!3
Linux 性能優化總結!3
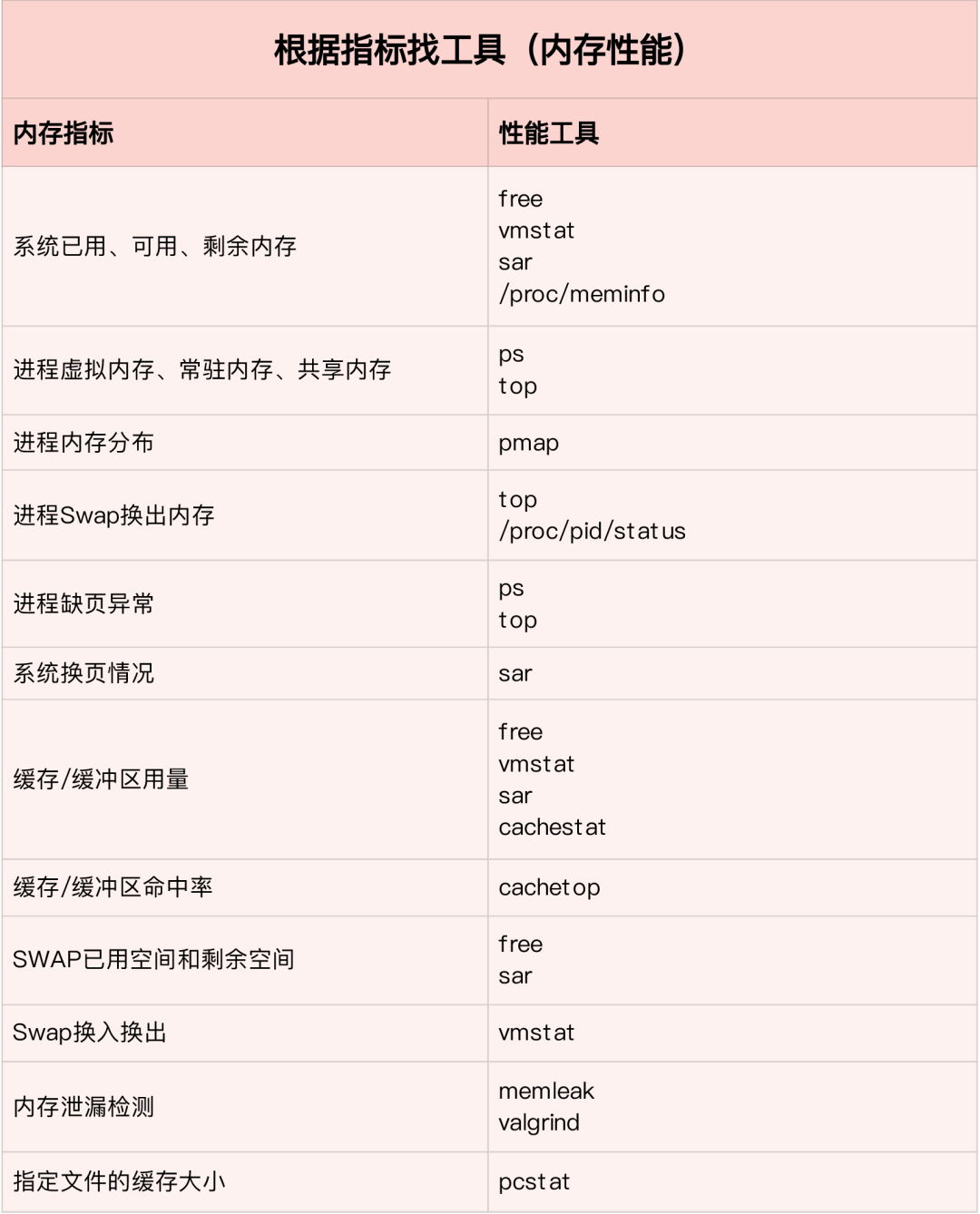
如何迅速分析內存的性能瓶頸
通常先運行幾個覆蓋面比較大的性能工具,如 free,top,vmstat,pidstat 等
- 先用 free 和 top 查看系統整體內存使用情況
- 再用 vmstat 和 pidstat,查看一段時間的趨勢,從而判斷內存問題的類型
- 最后進行詳細分析,比如內存分配分析,緩存/緩沖區分析,具體進程的內存使用分析等
常見的優化思路:
- 最好禁止 Swap,若必須開啟則盡量降低 swappiness 的值
- 減少內存的動態分配,如可以用內存池,HugePage 等
- 盡量使用緩存和緩沖區來訪問數據。如用堆棧明確聲明內存空間來存儲需要緩存的數據,或者用 Redis 外部緩存組件來優化數據的訪問
- cgroups 等方式來限制進程的內存使用情況,確保系統內存不被異常進程耗盡
- /proc/pid/oom_adj 調整核心應用的 oom_score,保證即使內存緊張核心應用也不會被OOM殺死
vmstat 使用詳解
vmstat 命令是最常見的 Linux/Unix 監控工具,可以展現給定時間間隔的服務器的狀態值,包括服務器的 CPU 使用率,內存使用,虛擬內存交換情況,IO讀寫情況。可以看到整個機器的 CPU,內存,IO 的使用情況,而不是單單看到各個進程的 CPU 使用率和內存使用率(使用場景不一樣)。
vmstat 2procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 1379064 282244 11537528 0 0 3 104 0 0 3 0 97 0 0 0 0 0 1372716 282244 11537544 0 0 0 24 4893 8947 1 0 98 0 0 0 0 0 1373404 282248 11537544 0 0 0 96 5105 9278 2 0 98 0 0 0 0 0 1374168 282248 11537556 0 0 0 0 5001 9208 1 0 99 0 0 0 0 0 1376948 282248 11537564 0 0 0 80 5176 9388 2 0 98 0 0 0 0 0 1379356 282256 11537580 0 0 0 202 5474 9519 2 0 98 0 0 1 0 0 1368376 282256 11543696 0 0 0 0 5894 8940 12 0 88 0 0 1 0 0 1371936 282256 11539240 0 0 0 10554 6176 9481 14 1 85 1 0 1 0 0 1366184 282260 11542292 0 0 0 7456 6102 9983 7 1 91 0 0 1 0 0 1353040 282260 11556176 0 0 0 16924 7233 9578 18 1 80 1 0 0 0 0 1359432 282260 11549124 0 0 0 12576 5495 9271 7 0 92 1 0 0 0 0 1361744 282264 11549132 0 0 0 58 8606 15079 4 2 95 0 0 1 0 0 1367120 282264 11549140 0 0 0 2 5716 9205 8 0 92 0 0 0 0 0 1346580 282264 11562644 0 0 0 70 6416 9944 12 0 88 0 0 0 0 0 1359164 282264 11550108 0 0 0 2922 4941 8969 3 0 97 0 0 1 0 0 1353992 282264 11557044 0 0 0 0 6023 8917 15 0 84 0 0
# 結果說明- r 表示運行隊列(就是說多少個進程真的分配到CPU),我測試的服務器目前CPU比較空閑,沒什么程序在跑,當這個值超過了CPU數目,就會出現CPU瓶頸了。這個也和top的負載有關系,一般負載超過了3就比較高,超過了5就高,超過了10就不正常了,服務器的狀態很危險。top的負載類似每秒的運行隊列。如果運行隊列過大,表示你的CPU很繁忙,一般會造成CPU使用率很高。
- b 表示阻塞的進程,這個不多說,進程阻塞,大家懂的。
- swpd 虛擬內存已使用的大小,如果大于0,表示你的機器物理內存不足了,如果不是程序內存泄露的原因,那么你該升級內存了或者把耗內存的任務遷移到其他機器。
- free 空閑的物理內存的大小,我的機器內存總共8G,剩余3415M。
- buff Linux/Unix系統是用來存儲,目錄里面有什么內容,權限等的緩存,我本機大概占用300多M
- cache cache直接用來記憶我們打開的文件,給文件做緩沖,我本機大概占用300多M(這里是Linux/Unix的聰明之處,把空閑的物理內存的一部分拿來做文件和目錄的緩存,是為了提高 程序執行的性能,當程序使用內存時,buffer/cached會很快地被使用。)
- si 每秒從磁盤讀入虛擬內存的大小,如果這個值大于0,表示物理內存不夠用或者內存泄露了,要查找耗內存進程解決掉。我的機器內存充裕,一切正常。
- so 每秒虛擬內存寫入磁盤的大小,如果這個值大于0,同上。
- bi 塊設備每秒接收的塊數量,這里的塊設備是指系統上所有的磁盤和其他塊設備,默認塊大小是1024byte,我本機上沒什么IO操作,所以一直是0,但是我曾在處理拷貝大量數據(2-3T)的機器上看過可以達到140000/s,磁盤寫入速度差不多140M每秒
- bo 塊設備每秒發送的塊數量,例如我們讀取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO過于頻繁,需要調整。
- in 每秒CPU的中斷次數,包括時間中斷
- cs 每秒上下文切換次數,例如我們調用系統函數,就要進行上下文切換,線程的切換,也要進程上下文切換,這個值要越小越好,太大了,要考慮調低線程或者進程的數目,例如在apache和nginx這種web服務器中,我們一般做性能測試時會進行幾千并發甚至幾萬并發的測試,選擇web服務器的進程可以由進程或者線程的峰值一直下調,壓測,直到cs到一個比較小的值,這個進程和線程數就是比較合適的值了。系統調用也是,每次調用系統函數,我們的代碼就會進入內核空間,導致上下文切換,這個是很耗資源,也要盡量避免頻繁調用系統函數。上下文切換次數過多表示你的CPU大部分浪費在上下文切換,導致CPU干正經事的時間少了,CPU沒有充分利用,是不可取的。
- us 用戶CPU時間,我曾經在一個做加密解密很頻繁的服務器上,可以看到us接近100,r運行隊列達到80(機器在做壓力測試,性能表現不佳)。
- sy 系統CPU時間,如果太高,表示系統調用時間長,例如是IO操作頻繁。
- id 空閑CPU時間,一般來說,id + us + sy = 100,一般我認為id是空閑CPU使用率,us是用戶CPU使用率,sy是系統CPU使用率。
- wt 等待IO CPU時間pidstat 使用詳解
pidstat 主要用于監控全部或指定進程占用系統資源的情況,如CPU,內存、設備IO、任務切換、線程等。
使用方法:
- pidstat –d interval times 統計各個進程的IO使用情況
- pidstat –u interval times 統計各個進程的CPU統計信息
- pidstat –r interval times 統計各個進程的內存使用信息
- pidstat -w interval times 統計各個進程的上下文切換
- p PID 指定PID
1、統計 IO 使用情況
pidstat -d 1 10
03:02:02 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command03:02:03 PM 0 816 0.00 918.81 0.00 jbd2/vda1-803:02:03 PM 0 1007 0.00 3.96 0.00 AliYunDun03:02:03 PM 997 7326 0.00 1904.95 918.81 java03:02:03 PM 997 8539 0.00 3.96 0.00 java03:02:03 PM 0 16066 0.00 35.64 0.00 cmagent
03:02:03 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command03:02:04 PM 0 816 0.00 1924.00 0.00 jbd2/vda1-803:02:04 PM 997 7326 0.00 11156.00 1888.00 java03:02:04 PM 997 8539 0.00 4.00 0.00 java- UID
- PID
- kB_rd/s:每秒進程從磁盤讀取的數據量 KB 單位 read from disk each second KB
- kB_wr/s:每秒進程向磁盤寫的數據量 KB 單位 write to disk each second KB
- kB_ccwr/s:每秒進程向磁盤寫入,但是被取消的數據量,This may occur when the task truncates some dirty pagecache.
- iodelay:Block I/O delay,measured in clock ticks
- Command:進程名 task name
2、統計 CPU 使用情況
# 統計CPUpidstat -u 1 1003:03:33 PM UID PID %usr %system %guest %CPU CPU Command03:03:34 PM 0 2321 3.96 0.00 0.00 3.96 0 ansible03:03:34 PM 0 7110 0.00 0.99 0.00 0.99 4 pidstat03:03:34 PM 997 8539 0.99 0.00 0.00 0.99 5 java03:03:34 PM 984 15517 0.99 0.00 0.00 0.99 5 java03:03:34 PM 0 24406 0.99 0.00 0.00 0.99 5 java03:03:34 PM 0 32158 3.96 0.00 0.00 3.96 2 ansible- UID
- PID
- %usr: 進程在用戶空間占用 cpu 的百分比
- %system: 進程在內核空間占用 CPU 百分比
- %guest: 進程在虛擬機占用 CPU 百分比
- %wait: 進程等待運行的百分比
- %CPU: 進程占用 CPU 百分比
- CPU: 處理進程的 CPU 編號
- Command: 進程名
3、統計內存使用情況
# 統計內存pidstat -r 1 10Average: UID PID minflt/s majflt/s VSZ RSS %MEM CommandAverage: 0 1 0.20 0.00 191256 3064 0.01 systemdAverage: 0 1007 1.30 0.00 143256 22720 0.07 AliYunDunAverage: 0 6642 0.10 0.00 6301904 107680 0.33 javaAverage: 997 7326 10.89 0.00 13468904 8395848 26.04 javaAverage: 0 7795 348.15 0.00 108376 1233 0.00 pidstatAverage: 997 8539 0.50 0.00 8242256 2062228 6.40 javaAverage: 987 9518 0.20 0.00 6300944 1242924 3.85 javaAverage: 0 10280 3.70 0.00 807372 8344 0.03 aliyun-serviceAverage: 984 15517 0.40 0.00 6386464 1464572 4.54 javaAverage: 0 16066 236.46 0.00 2678332 71020 0.22 cmagentAverage: 995 20955 0.30 0.00 6312520 1408040 4.37 javaAverage: 995 20956 0.20 0.00 6093764 1505028 4.67 javaAverage: 0 23936 0.10 0.00 5302416 110804 0.34 javaAverage: 0 24406 0.70 0.00 10211672 2361304 7.32 javaAverage: 0 26870 1.40 0.00 1470212 36084 0.11 promtail- UID
- PID
- Minflt/s : 每秒次缺頁錯誤次數 (minor page faults),虛擬內存地址映射成物理內存地址產生的 page fault 次數
- Majflt/s : 每秒主缺頁錯誤次數 (major page faults), 虛擬內存地址映射成物理內存地址時,相應 page 在 swap 中
- VSZ virtual memory usage : 該進程使用的虛擬內存 KB 單位
- RSS : 該進程使用的物理內存 KB 單位
- %MEM : 內存使用率
- Command : 該進程的命令 task name
4、查看具體進程使用情況
pidstat -T ALL -r -p 20955 1 1003:12:16 PM UID PID minflt/s majflt/s VSZ RSS %MEM Command03:12:17 PM 995 20955 0.00 0.00 6312520 1408040 4.37 java
03:12:16 PM UID PID minflt-nr majflt-nr Command03:12:17 PM 995 20955 0 0 java-End-
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
緩沖區
+關注
關注
0文章
36瀏覽量
9322 -
數據
+關注
關注
8文章
7241瀏覽量
91033 -
SWAP
+關注
關注
0文章
51瀏覽量
13154 -
堆棧
+關注
關注
0文章
183瀏覽量
20043 -
Redis
+關注
關注
0文章
385瀏覽量
11325
發布評論請先 登錄
相關推薦
熱點推薦
HBase性能優化方法總結
,不要滿額配置地使用網絡,否則在高負載時,會影響HBase應用系統的性能。3. 操作系統操作系統的選擇應考慮是否支持HBase,通常情況下選擇Linux操作系統。4. 本地文件系統本地Linu
發表于 04-20 17:16
Linux系統的性能優化策略
近年來,世界上許多大軟件公司紛紛推出各種Linux服務器系統及Linux下的應用軟件。目前,Linux 已可以與各種傳統的商業操作系統分庭抗禮,在服務器市場,占據了相當大的份額。本文分別從磁盤調優,文件系統,內存管理以及編譯
發表于 07-16 06:23
基于Linux的Socket網絡編程的性能優化
基于Linux的Socket網絡編程的性能優化
隨著Intenet的日益發展和普及,網絡在嵌入式系統中應用非常廣泛,越來越多的嵌入式設備采用Linux操作系統。
發表于 10-22 20:48
?1163次閱讀



Linux CPU的性能應該如何優化
在Linux系統中,由于成本的限制,往往會存在資源上的不足,例如 CPU、內存、網絡、IO 性能。本文,就對 Linux 進程和 CPU 的原理進行分析,總結出 CPU
Linux神優化Zen3:性能高出15%
Intel、AMD相愛相殺50年,現在兩家是打得不可開交,然后在某些領域兩邊可能還是天作之合。對Linux用戶來說,AMD的Zen3處理器現在是最好的CPU,而最佳系統則是Intel的Clear

Linux 性能優化總結!1
應用負載角度:直接影響了產品終端的用戶體驗
* 系統資源角度:資源使用率、飽和度等
性能問題的本質就是系統資源已經到達瓶頸,但請求的處理還不夠快,無法支撐更多的請求。性能分析實際上就是找出應用或系統的瓶頸,設法去避免或緩解它們。

Linux 性能優化總結!2
大多數計算機用的主存都是動態隨機訪問內存(DRAM),只有內核才可以直接訪問物理內存。Linux內核給每個進程提供了一個獨立的虛擬地址空間,并且這個地址空間是連續的。這樣進程就可以很方便的訪問內存(虛擬內存)。
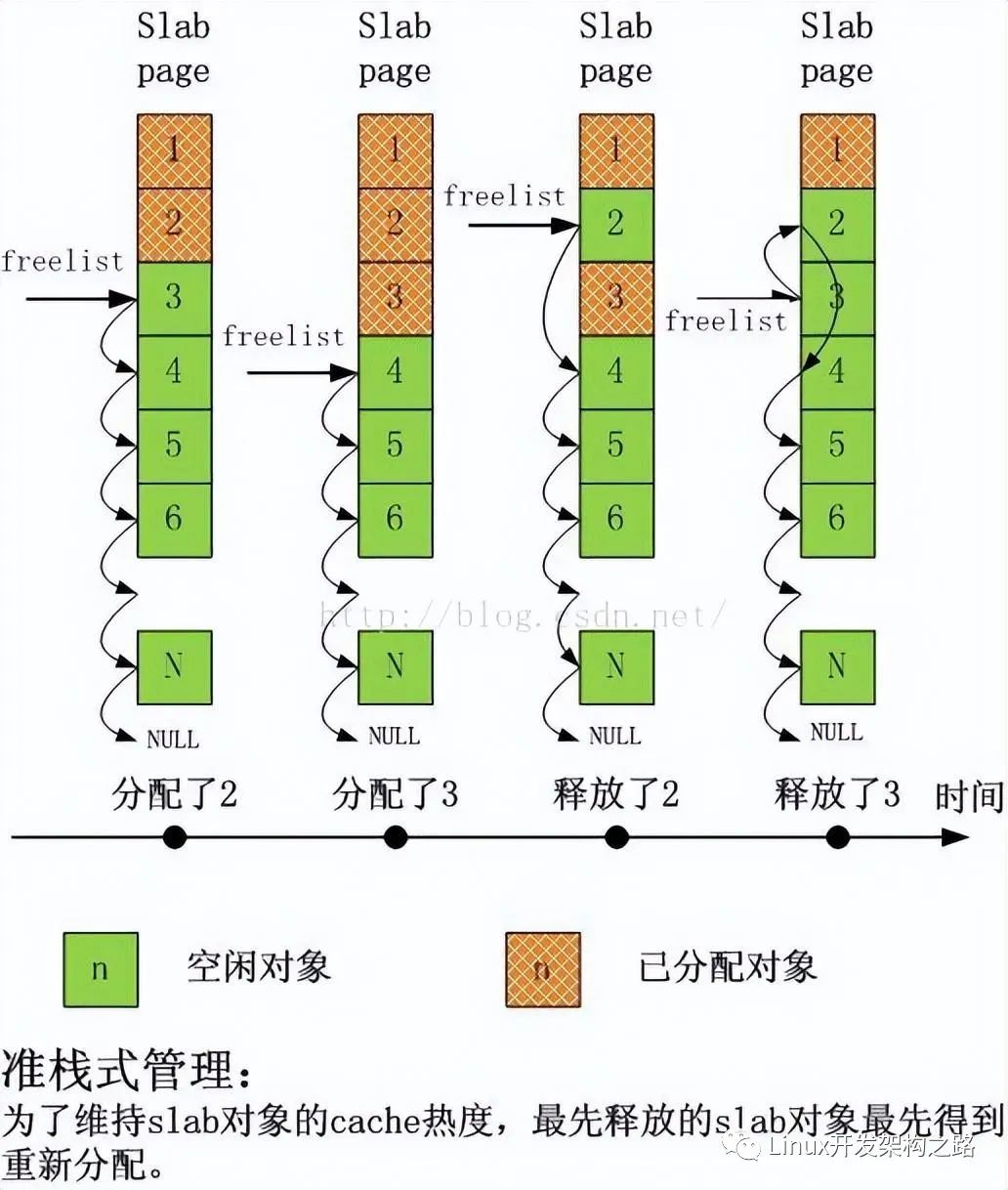
Linux內核slab性能優化的核心思想
今天分享一篇內存性能優化的文章,文章用了大量精美的圖深入淺出地分析了Linux內核slab性能優化的核心思想,slab是
性能優化之路總結
針對老項目,去年做了許多降本增效的事情,其中發現最多的就是接口耗時過長的問題,就集中搞了一次接口性能優化。本文將給小伙伴們分享一下接口優化的通用方案。 ? ? 一、接口優化方案
如何優化Linux服務器的性能
優化Linux服務器的性能是一個綜合性的任務,涉及硬件、軟件、配置、監控等多個方面。以下是一個詳細的指南,旨在幫助系統管理員和運維人員提升Linux服務器的





 工商網監
工商網監
評論