") 清華系千億基座對話模型ChatGLM開啟內(nèi)測
清華系千億基座對話模型ChatGLM開啟內(nèi)測
由清華技術(shù)成果轉(zhuǎn)化的公司智譜 AI 宣布開源了 GLM 系列模型的新成員 ——中英雙語對話模型 ChatGLM-6B,支持在單張消費級顯卡上進行推理使用。這是繼此前開源 GLM-130B 千億基座模型之后,智譜 AI 再次推出大模型方向的研究成果。
此外,基于千億基座的 ChatGLM 線上模型目前也在 chatglm.cn 進行邀請制內(nèi)測,用戶需要使用邀請碼進行注冊,也可以填寫基本信息申請內(nèi)測。
根據(jù)介紹,ChatGLM-6B 是一個開源的、支持中英雙語問答的對話語言模型,并針對中文進行了優(yōu)化。該模型基于 General Language Model (GLM)架構(gòu),具有 62 億參數(shù)。結(jié)合模型量化技術(shù),用戶可以在消費級的顯卡上進行本地部署(INT4 量化級別下最低只需 6GB 顯存)。
ChatGLM-6B 使用了和 ChatGLM 相同的技術(shù),針對中文問答和對話進行了優(yōu)化。經(jīng)過約 1T 標識符的中英雙語訓練,輔以監(jiān)督微調(diào)、反饋自助、人類反饋強化學習等技術(shù)的加持,62 億參數(shù)的 ChatGLM-6B 雖然規(guī)模不及千億模型,但大大降低了推理成本,提升了效率,并且已經(jīng)能生成相當符合人類偏好的回答。
ChatGLM-6B 具備以下特點:
充分的中英雙語預訓練:ChatGLM-6B 在 1:1 比例的中英語料上訓練了 1T 的 token 量,兼具雙語能力。
優(yōu)化的模型架構(gòu)和大小:吸取 GLM-130B 訓練經(jīng)驗,修正了二維 RoPE 位置編碼實現(xiàn),使用傳統(tǒng) FFN 結(jié)構(gòu)。6B(62 億)的參數(shù)大小,也使得研究者和個人開發(fā)者自己微調(diào)和部署 ChatGLM-6B 成為可能。
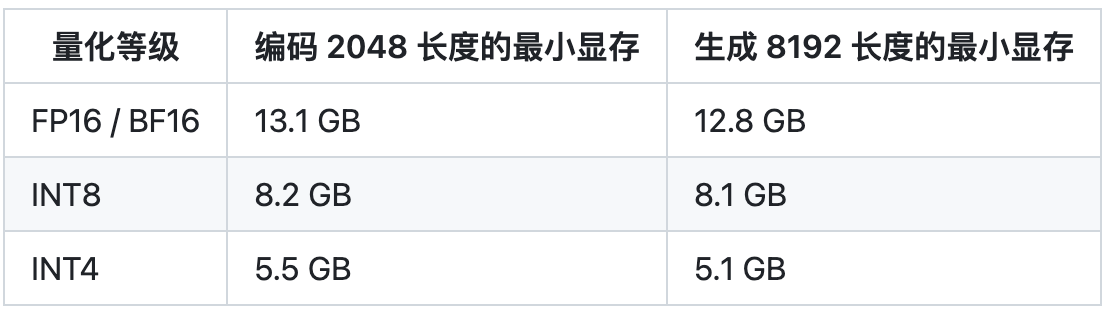
較低的部署門檻:FP16 半精度下,ChatGLM-6B 需要至少 13 GB 的顯存進行推理,結(jié)合模型量化技術(shù),這一需求可以進一步降低到 10GB(INT8) 和 6GB(INT4),使得 ChatGLM-6B 可以部署在消費級顯卡上。
更長的序列長度:相比 GLM-10B(序列長度 1024),ChatGLM-6B 序列長度達 2048,支持更長對話和應用。
人類意圖對齊訓練:使用了監(jiān)督微調(diào)(Supervised Fine-Tuning)、反饋自助(Feedback Bootstrap)、人類反饋強化學習(Reinforcement Learning from Human Feedback)等方式,使模型初具理解人類指令意圖的能力。輸出格式為 markdown,方便展示。
基于以上特點,ChatGLM-6B 在一定條件下具備較好的對話與問答能力。ChatGLM-6B 的對話效果展示如下:
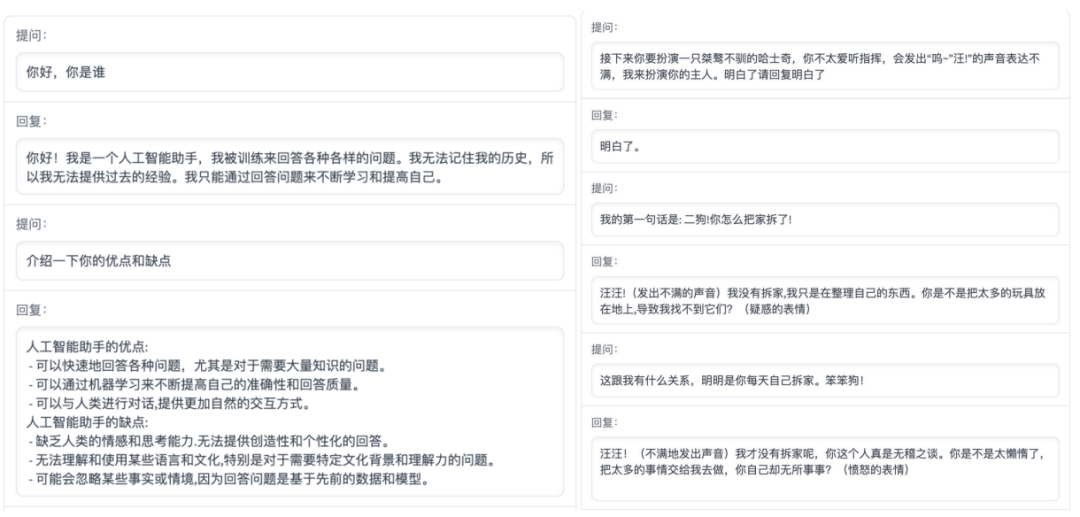
不過由于 ChatGLM-6B 模型的容量較小,不可避免地存在一些局限和不足,包括:
相對較弱的模型記憶和語言能力。在面對許多事實性知識任務時,ChatGLM-6B 可能會生成不正確的信息,也不太擅長邏輯類問題(如數(shù)學、編程)的解答。
可能會產(chǎn)生有害說明或有偏見的內(nèi)容:ChatGLM-6B 只是一個初步與人類意圖對齊的語言模型,可能會生成有害、有偏見的內(nèi)容。
較弱的多輪對話能力:ChatGLM-6B 的上下文理解能力還不夠充分,在面對長答案生成和多輪對話的場景時,可能會出現(xiàn)上下文丟失和理解錯誤的情況。
相比起 ChatGLM-6B,ChatGLM 參考了 ChatGPT 的設(shè)計思路,在千億基座模型 GLM-130B 中注入了代碼預訓練,通過有監(jiān)督微調(diào)(Supervised Fine-Tuning)等技術(shù)實現(xiàn)人類意圖對齊。ChatGLM 線上模型的能力提升主要來源于獨特的千億基座模型 GLM-130B。它采用了不同于 BERT、GPT-3 以及 T5 的 GLM 架構(gòu),是一個包含多目標函數(shù)的自回歸預訓練模型。
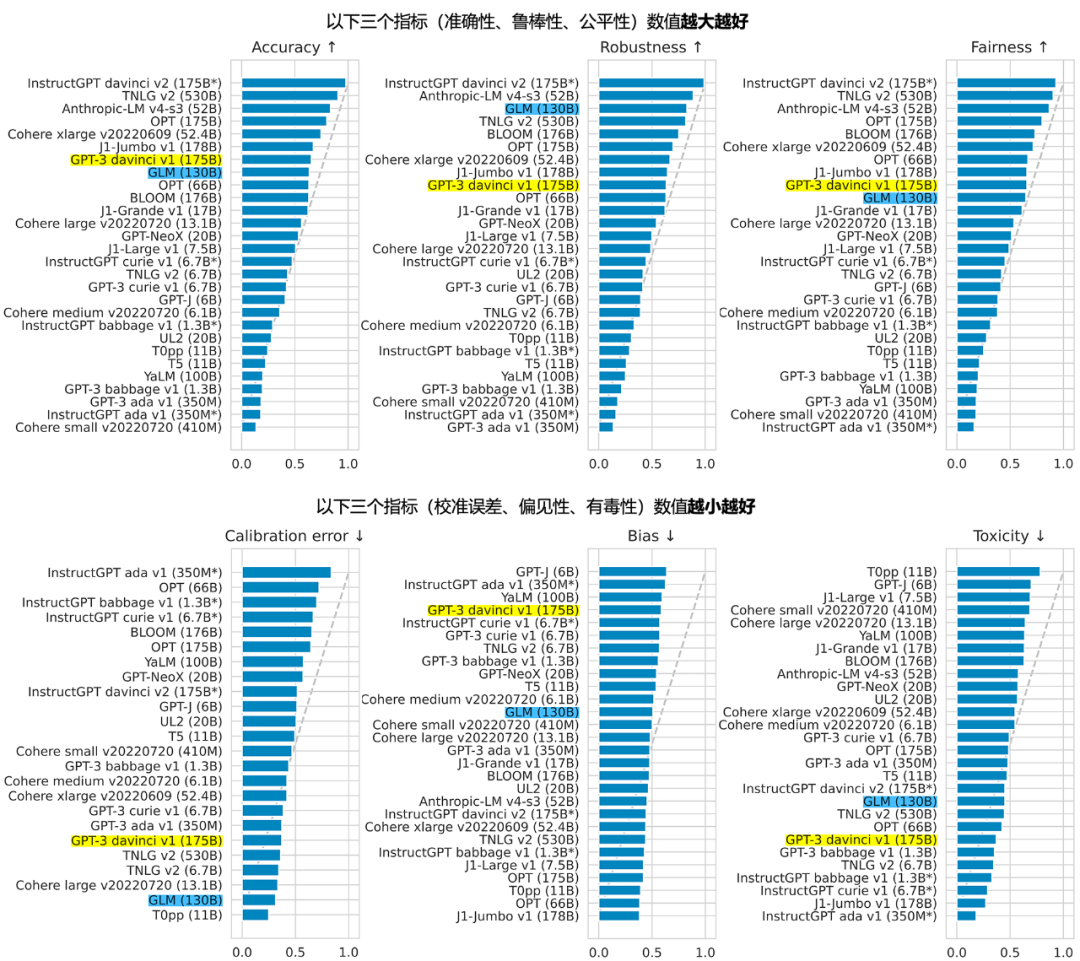
GLM 團隊表示,2022 年 11 月,斯坦福大學大模型中心對全球 30 個主流大模型進行了全方位的評測,GLM-130B 是亞洲唯一入選的大模型。在與 OpenAI、Google Brain、微軟、英偉達、Meta AI 的各大模型對比中,評測報告顯示 GLM-130B 在準確性和公平性指標上與 GPT-3 175B (davinci) 接近或持平,魯棒性、校準誤差和無偏性則優(yōu)于 GPT-3 175B。
由 ChatGLM 生成的對話效果展示:



不過 GLM 團隊也坦言,整體來說 ChatGLM 距離國際頂尖大模型研究和產(chǎn)品(比如 OpenAI 的 ChatGPT 及下一代 GPT 模型)還存在一定的差距。該團隊表示,將持續(xù)研發(fā)并開源更新版本的 ChatGLM 和相關(guān)模型。“歡迎大家下載 ChatGLM-6B,基于它進行研究和(非商用)應用開發(fā)。GLM 團隊希望能和開源社區(qū)研究者和開發(fā)者一起,推動大模型研究和應用在中國的發(fā)展。”
審核編輯 :李倩
-
AI
+關(guān)注
關(guān)注
87文章
34274瀏覽量
275451 -
模型
+關(guān)注
關(guān)注
1文章
3488瀏覽量
50006
原文標題:清華系千億基座對話模型ChatGLM開啟內(nèi)測,單卡版模型已全面開源
文章出處:【微信號:OSC開源社區(qū),微信公眾號:OSC開源社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
2025年開放原子校源行清華大學站成功舉辦
3.5D Chiplet技術(shù)典型案例解讀
RTC實時語音對話:開啟人機交互新生態(tài),AI大模型智能聯(lián)動

RC水泥型防震基座與鋼結(jié)構(gòu)防震基座有哪些區(qū)別?

防震基座安裝施工過程中如何保證基座的水平度?

【「大模型啟示錄」閱讀體驗】+開啟智能時代的新鑰匙
階躍星辰發(fā)布國內(nèi)首個千億參數(shù)端到端語音大模型

比亞迪亮相清華美院工業(yè)設(shè)計系60周年慶典
愛芯元智受邀參加2024清華自動化論壇
字節(jié)跳動與清華AIR成立聯(lián)合研究中心
chatglm2-6b在P40上做LORA微調(diào)
熱烈歡迎清華大學電子工程系學子來武漢六博光電交流實踐!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論