") 為什么要使用Redis做緩存?
為什么要使用Redis做緩存?
1、為什么要使用Redis做緩存?
緩存的好處
使用緩存的目的就是提升讀寫性能。而實(shí)際業(yè)務(wù)場(chǎng)景下,更多的是為了提升讀性能,帶來更高的并發(fā)量。
Redis的好處
- 讀取速度快,單機(jī)輕松10W+并發(fā)。
- 支持多種數(shù)據(jù)結(jié)構(gòu),包括字符串、列表、集合、有序集合、哈希等
- 擁有其他豐富的功能,主從復(fù)制、集群、數(shù)據(jù)持久化等
- 可以實(shí)現(xiàn)其他功能,消息隊(duì)列、分布式鎖等
基于 Spring Boot + MyBatis Plus + Vue & Element 實(shí)現(xiàn)的后臺(tái)管理系統(tǒng) + 用戶小程序,支持 RBAC 動(dòng)態(tài)權(quán)限、多租戶、數(shù)據(jù)權(quán)限、工作流、三方登錄、支付、短信、商城等功能
- 項(xiàng)目地址:https://github.com/YunaiV/ruoyi-vue-pro
- 視頻教程:https://doc.iocoder.cn/video/
2、為什么Redis單線程模型效率也能那么高?
- C語言實(shí)現(xiàn),效率高: C語言程序運(yùn)行時(shí)要比其他語言編寫的程序快得多,因?yàn)樗半x底層機(jī)器很近”
- 單線程的優(yōu)勢(shì): 使用了單線程后可以省去多線程的CPU上下文會(huì)切換的時(shí)間,也不用去考慮鎖導(dǎo)致的性能消耗等問題,可維護(hù)性高
- Pipeline: Redis主要受限于內(nèi)存和網(wǎng)絡(luò),幾乎不會(huì)占用太多CPU。利用pipeline操作,減少命令在網(wǎng)絡(luò)上的傳輸時(shí)間,將多次網(wǎng)絡(luò)IO縮減為一次網(wǎng)絡(luò)IO
- 存儲(chǔ)實(shí)現(xiàn)優(yōu)化: Redis的基礎(chǔ)數(shù)據(jù)結(jié)構(gòu)每一種至少有2種及2種以上的實(shí)現(xiàn),在不同的大小或長(zhǎng)度下選用適合的數(shù)據(jù)類型,達(dá)到極致的存儲(chǔ)效率,從而提高寫入和讀取速度
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 實(shí)現(xiàn)的后臺(tái)管理系統(tǒng) + 用戶小程序,支持 RBAC 動(dòng)態(tài)權(quán)限、多租戶、數(shù)據(jù)權(quán)限、工作流、三方登錄、支付、短信、商城等功能
3、Redis6.0為什么要引入多線程呢?
多線程只是針對(duì)IO線程,執(zhí)行命令還是單線程。
Redis服務(wù)器可以處理80,000到100,000QPS,對(duì)于80%的公司來說,單線程的Redis已經(jīng)足夠使用了。但隨著越來越復(fù)雜的業(yè)務(wù)場(chǎng)景,有些公司動(dòng)不動(dòng)就上億的交易量,因此需要更大的QPS。
所以Redis作者在6.0引入了多線程,性能提升至少一倍以上。當(dāng)然集群方案也可以解決更大QPS的問題,但是集群方案還是有一些問題的:
- 常見集群方案是對(duì)數(shù)據(jù)進(jìn)行分區(qū)并采用多個(gè)服務(wù)器,但該方案有非常大的缺點(diǎn),例如要管理的Redis服務(wù)器太多,維護(hù)代價(jià)大
- 某些適用于單個(gè)Redis服務(wù)器的命令不適用于數(shù)據(jù)分區(qū)
- 數(shù)據(jù)分區(qū)無法解決熱點(diǎn)讀/寫問題;數(shù)據(jù)傾斜、重新分配變得更加復(fù)雜等等
4、Redis常見數(shù)據(jù)結(jié)構(gòu)以及使用場(chǎng)景
字符串(String)
使用場(chǎng)景
- 計(jì)數(shù): 使用Redis 作為計(jì)數(shù)的基礎(chǔ)工具,它可以實(shí)現(xiàn)快速計(jì)數(shù)、查詢緩存的功能,同時(shí)數(shù)據(jù)可以異步落地到其他數(shù)據(jù)源
- 共享Session: 使用Redis將用戶的Session進(jìn)行集中管理,避免在訪問分布式服務(wù)時(shí)Session不存在導(dǎo)致重新登錄
- 限速: 短信接口不被頻繁訪問,例如一分鐘不能超過5次
哈希(Hash)
Java里提供了HashMap,Redis中也有類似的數(shù)據(jù)結(jié)構(gòu),就是哈希類型。但是要注意,哈希類型中的映射關(guān)系叫作field-value,注意這里的value是指field對(duì)應(yīng)的值,不是鍵對(duì)應(yīng)的值。
使用場(chǎng)景
哈希類型比較適宜存放對(duì)象類型的數(shù)據(jù),我們可以比較下,如果數(shù)據(jù)庫中表記錄user為:
| id | name | age |
|---|---|---|
| 1 | test1 | 18 |
| 2 | test2 | 20 |
使用String類型
setuser:1{"id":1,"name":"test1","age":18};
優(yōu)點(diǎn):簡(jiǎn)單直觀,每個(gè)鍵對(duì)應(yīng)一個(gè)值
缺點(diǎn):鍵數(shù)過多,占用內(nèi)存多,用戶信息過于分散
使用hash類型
hmsetuser:1nametest1age18
hmsetuser:2nametest2age20
優(yōu)點(diǎn):簡(jiǎn)單直觀,使用合理可減少內(nèi)存空間消耗
列表(list)
列表( list)類型是用來存儲(chǔ)多個(gè)有序的字符串,a、b、c、c、b四個(gè)元素從左到右組成了一個(gè)有序的列表,列表中的每個(gè)字符串稱為元素(element),一個(gè)列表最多可以存儲(chǔ)(2^32-1)個(gè)元素(4294967295)。

使用場(chǎng)景
- 每個(gè)用戶有屬于自己的文章列表,需要分頁展示文章列表。
- 消息隊(duì)列,Redis的lpush+rpop命令組合即可實(shí)現(xiàn)阻塞隊(duì)列。
集合(set)

集合( set)類型也是用來保存多個(gè)的字符串元素,但和列表類型不一樣的是,集合中不允許有重復(fù)元素,并且集合中的元素是無序的,不能通過索引下標(biāo)獲取元素。
使用場(chǎng)景
集合類型比較典型的使用場(chǎng)景是標(biāo)簽(tag)。例如一個(gè)用戶可能對(duì)娛樂、體育比較感興趣,另一個(gè)用戶可能對(duì)歷史、新聞比較感興趣,這些興趣點(diǎn)就是標(biāo)簽。有了這些數(shù)據(jù)就可以得到喜歡同一個(gè)標(biāo)簽的人,以及用戶的共同喜好的標(biāo)簽,這些數(shù)據(jù)對(duì)于用戶體驗(yàn)以及增強(qiáng)用戶黏度比較重要。
除此之外,集合還可以通過生成隨機(jī)數(shù)進(jìn)行比如抽獎(jiǎng)活動(dòng),以及社交圖譜等等。
有序集合(ZSET)
有序集合給每個(gè)元素設(shè)置一個(gè)分?jǐn)?shù)(score)作為排序的依據(jù)。提供了獲取指定分?jǐn)?shù)和元素范圍查詢、計(jì)算成員排名等功能,合理的利用有序集合,能幫助我們?cè)趯?shí)際開發(fā)中解決很多問題。
適合場(chǎng)景
有序集合比較典型的使用場(chǎng)景就是排行榜系統(tǒng)。例如視頻網(wǎng)站需要對(duì)用戶上傳的視頻做排行榜,榜單的維度可能是多個(gè)方面的:按照時(shí)間、按照播放數(shù)量、按照獲得的贊數(shù)。
5、pipeline有什么好處,為什么要用 pipeline?
Redis客戶端執(zhí)行一條命令分為如下4個(gè)部分:1)發(fā)送命令2)命令排隊(duì)3)命令執(zhí)行4)返回結(jié)果。
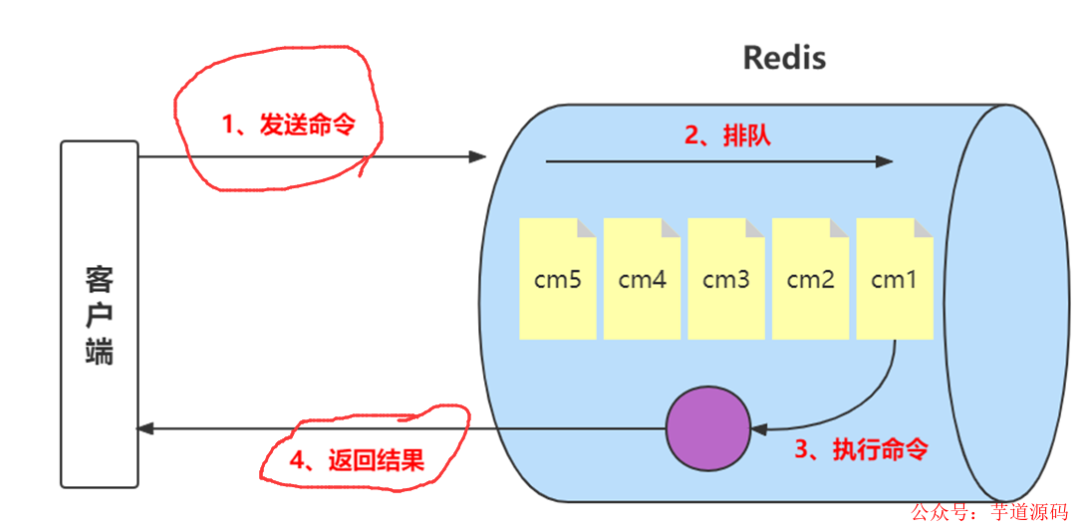
其中1和4花費(fèi)的時(shí)間稱為Round Trip Time (RTT,往返時(shí)間),也就是數(shù)據(jù)在網(wǎng)絡(luò)上傳輸?shù)臅r(shí)間,占用了絕大多的時(shí)間。
舉個(gè)例子:Redis的客戶端和服務(wù)端兩地直線距離約為800公里,那么1次RTT時(shí)間=800 x2/ ( 300000×2/3 ) =8毫秒,(光在真空中傳輸速度為每秒30萬公里,這里假設(shè)光纖為光速的2/3 )。而Redis命令真正執(zhí)行的時(shí)間通常在微秒(1000微妙=1毫秒)級(jí)別,所以才會(huì)有Redis性能瓶頸是網(wǎng)絡(luò)這樣的說法。
Pipeline(流水線)機(jī)制能改善上面這類問題,它能將一組Redis命令進(jìn)行組裝,通過一次RTT傳輸給Redis,再將這組Redis命令的執(zhí)行結(jié)果按順序返回給客戶端。
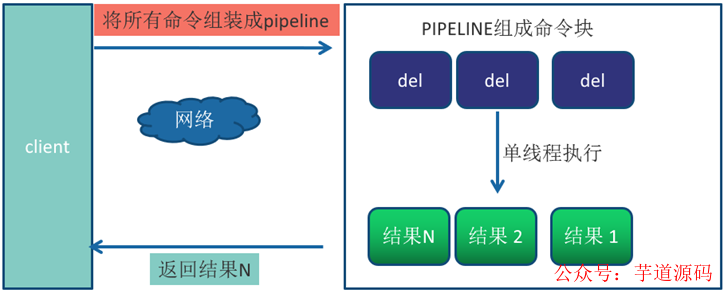
非Pipeline和Pipeline執(zhí)行10000次set操作的效果,在執(zhí)行時(shí)間上的比對(duì)如下:

差距有100多倍,可以得到如下兩個(gè)結(jié)論:
- Pipeline減少了網(wǎng)絡(luò)的開銷,執(zhí)行速度一般比逐條執(zhí)行要快。
- 客戶端和服務(wù)端的網(wǎng)絡(luò)延時(shí)越大,Pipeline的效果越明顯。
6、Redis官方為什么不提供 Windows版本?
目前Linux版本已經(jīng)相當(dāng)穩(wěn)定,而且用戶量很大,開發(fā)windows版本,反而會(huì)帶來兼容性等問題。
7、Redis 持久化方式有哪些?以及有什么區(qū)別?
Redis 提供兩種持久化機(jī)制 RDB 和 AOF 機(jī)制
RDB
RDB(Redis DataBase)持久化是把當(dāng)前進(jìn)程數(shù)據(jù)生成快照保存到硬盤的過程。所謂內(nèi)存快照,就是指內(nèi)存中的數(shù)據(jù)在某一個(gè)時(shí)刻的狀態(tài)記錄。
優(yōu)點(diǎn):
- 只有一個(gè)文件 dump.rdb,方便持久化。
- 容災(zāi)性好,一個(gè)文件可以保存到安全的磁盤。
- 相對(duì)于數(shù)據(jù)集大時(shí),比AOF的啟動(dòng)效率更高。
缺點(diǎn):
數(shù)據(jù)安全性低。RDB是間隔一段時(shí)間進(jìn)行持久化,如果持久化之間Redis發(fā)生故障,會(huì)發(fā)生數(shù)據(jù)丟失。所以這種方式更適合數(shù)據(jù)要求不嚴(yán)謹(jǐn)?shù)臅r(shí)候。
AOF
AOF(append only file)持久化:以獨(dú)立日志的方式記錄每次寫命令,重啟時(shí)再重新執(zhí)行AOF文件中的命令達(dá)到恢復(fù)數(shù)據(jù)的目的。AOF的主要作用是解決了數(shù)據(jù)持久化的實(shí)時(shí)性,目前已經(jīng)是Redis持久化的主流方式。
缺點(diǎn):
- AOF 文件比 RDB 文件大,且恢復(fù)速度慢。
- 數(shù)據(jù)集大的時(shí)候,比 RDB 啟動(dòng)效率低。
8、什么是Redis事務(wù)?原理是什么?
Redis 中的事務(wù)是一組命令的集合,將一組需要一起執(zhí)行的命令放到multi和exec兩個(gè)命令之間。multi 命令代表事務(wù)開始,exec命令代表事務(wù)結(jié)束。它可以保證一次執(zhí)行多個(gè)命令,每個(gè)事務(wù)是一個(gè)單獨(dú)的隔離操作,事務(wù)中的所有命令都會(huì)序列化、按順序地執(zhí)行。
但是要注意Redis的事務(wù)功能很弱。在事務(wù)回滾機(jī)制上,Redis只能對(duì)基本的語法錯(cuò)誤進(jìn)行判斷。
如下,當(dāng)語法命令錯(cuò)誤時(shí),會(huì)造成整個(gè)事務(wù)無法執(zhí)行,事務(wù)內(nèi)的操作都沒有執(zhí)行:
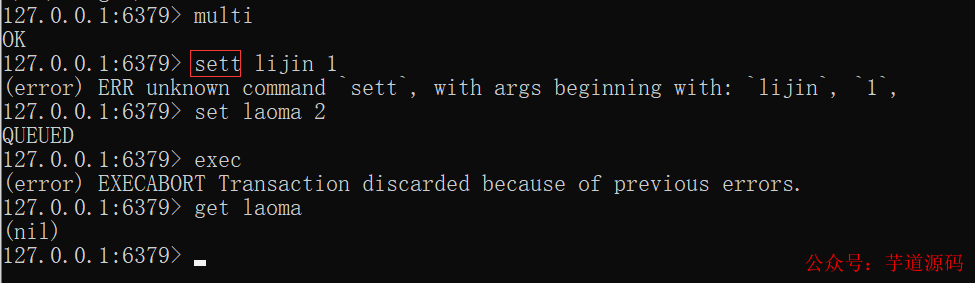
如下,當(dāng)命令錯(cuò)誤時(shí),雖然有異常提示,但是事務(wù)執(zhí)行成功。

9、如何在100個(gè)億URL中快速判斷某URL是否存在?
傳統(tǒng)數(shù)據(jù)結(jié)構(gòu)HashMap
可以將值映射到 HashMap 的 Key,然后可以在 O(1) 的時(shí)間復(fù)雜度內(nèi)返回結(jié)果,效率極高。
但是 HashMap 的實(shí)現(xiàn)也有缺點(diǎn),例如存儲(chǔ)容量占比高,考慮到負(fù)載因子的存在,通常空間是不能被用滿的,舉個(gè)例子如果一個(gè)1000萬個(gè)int類型,會(huì)占據(jù)HashMap多少空間呢?1.2個(gè)G。實(shí)際上,1000萬個(gè)int型,只需要40M左右空間,占比3%,1000萬個(gè)Integer,需要161M左右空間,占比13.3%。可見一旦值很多例如上億的時(shí)候,那HashMap 占據(jù)的內(nèi)存大小就變得很可觀了。
如果整個(gè)網(wǎng)頁黑名單系統(tǒng)包含100億個(gè)網(wǎng)頁URL,在數(shù)據(jù)庫查找是很費(fèi)時(shí)的,并且如果每個(gè)URL空間為64B,那么需要內(nèi)存為640GB,一般的服務(wù)器很難達(dá)到這個(gè)需求。
布隆過濾器
1970 年布隆提出了一種布隆過濾器的算法,用來判斷一個(gè)元素是否在一個(gè)集合中。這種算法由一個(gè)二進(jìn)制數(shù)組和一個(gè) Hash 算法組成。
相比于傳統(tǒng)的 List、Set、Map 等數(shù)據(jù)結(jié)構(gòu),它更高效、占用空間更少,但是缺點(diǎn)是其返回的結(jié)果是概率性的,而不是確切的。
布隆過濾器廣泛應(yīng)用于網(wǎng)頁黑名單系統(tǒng)、垃圾郵件過濾系統(tǒng)、爬蟲網(wǎng)址判重系統(tǒng)等,Google 著名的分布式數(shù)據(jù)庫 Bigtable 使用了布隆過濾器來查找不存在的行或列,以減少磁盤查找的IO次數(shù),Google Chrome瀏覽器使用了布隆過濾器加速安全瀏覽服務(wù)。
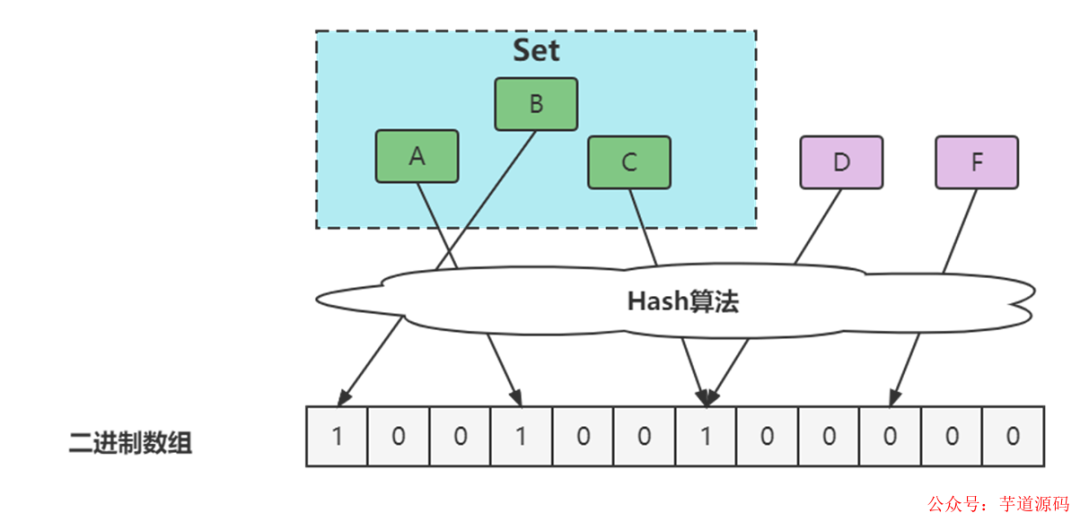
布隆過濾器的誤判問題
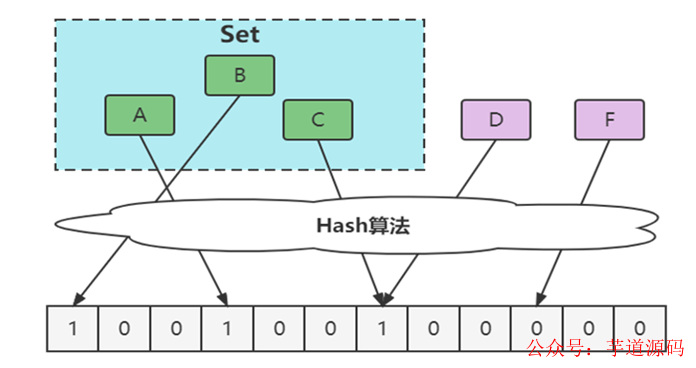
- 通過hash計(jì)算在數(shù)組上,因?yàn)閔ash沖突實(shí)際上可能不在,如下圖中的D。
- 通過hash計(jì)算在數(shù)組上,因?yàn)閿?shù)組中已存在,不能確定在不在,如下圖中的C。
優(yōu)化方案
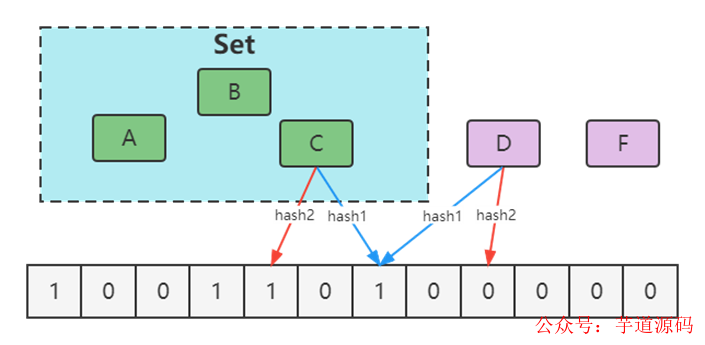
- 增大數(shù)組(預(yù)估適合值)
- 增加hash函數(shù),通過兩次Hash算法,都為1時(shí)確定為存在。
10、Redis的數(shù)據(jù)結(jié)構(gòu)組織?
為了實(shí)現(xiàn)從鍵到值的快速訪問,Redis 使用了一個(gè)全局哈希表來保存所有鍵值對(duì)。一個(gè)哈希表,其實(shí)就是一個(gè)數(shù)組,數(shù)組的每個(gè)元素稱為一個(gè)哈希桶。所以,我們常說,一個(gè)哈希表是由多個(gè)哈希桶組成的,每個(gè)哈希桶中保存了鍵值對(duì)數(shù)據(jù)。
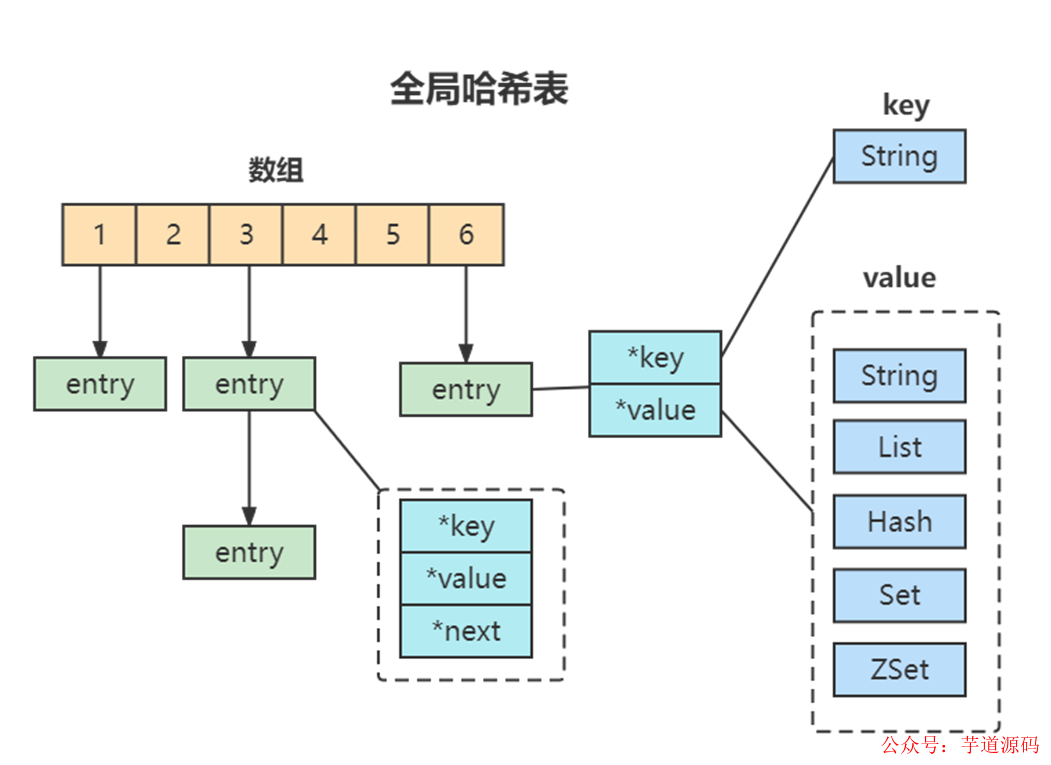
哈希表的最大好處很明顯,就是讓我們可以用 O(1) 的時(shí)間復(fù)雜度來快速查找到鍵值對(duì)。但是當(dāng)往 Redis 中寫入大量數(shù)據(jù)后,哈希表的沖突問題和 rehash 可能帶來的操作阻塞,這里的哈希沖突,兩個(gè) key 的哈希值和哈希桶計(jì)算對(duì)應(yīng)關(guān)系時(shí),正好落在了同一個(gè)哈希桶中。
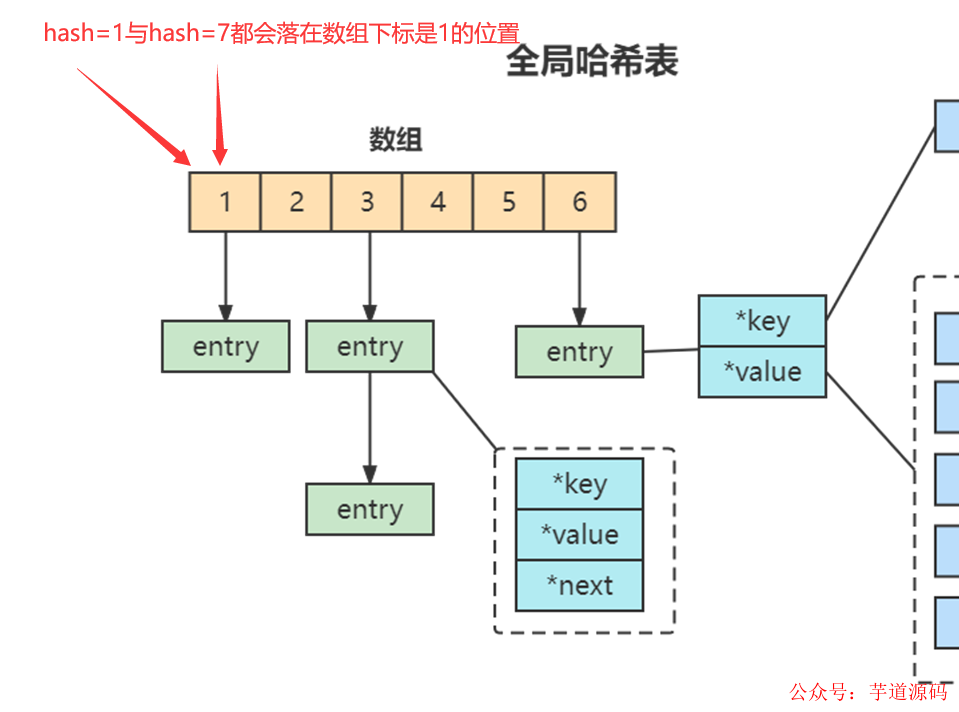
Redis 解決哈希沖突的方式,就是鏈?zhǔn)焦!f準(zhǔn)焦R埠苋菀桌斫猓褪侵竿粋€(gè)哈希桶中的多個(gè)元素用一個(gè)鏈表來保存,它們之間依次用指針連接。
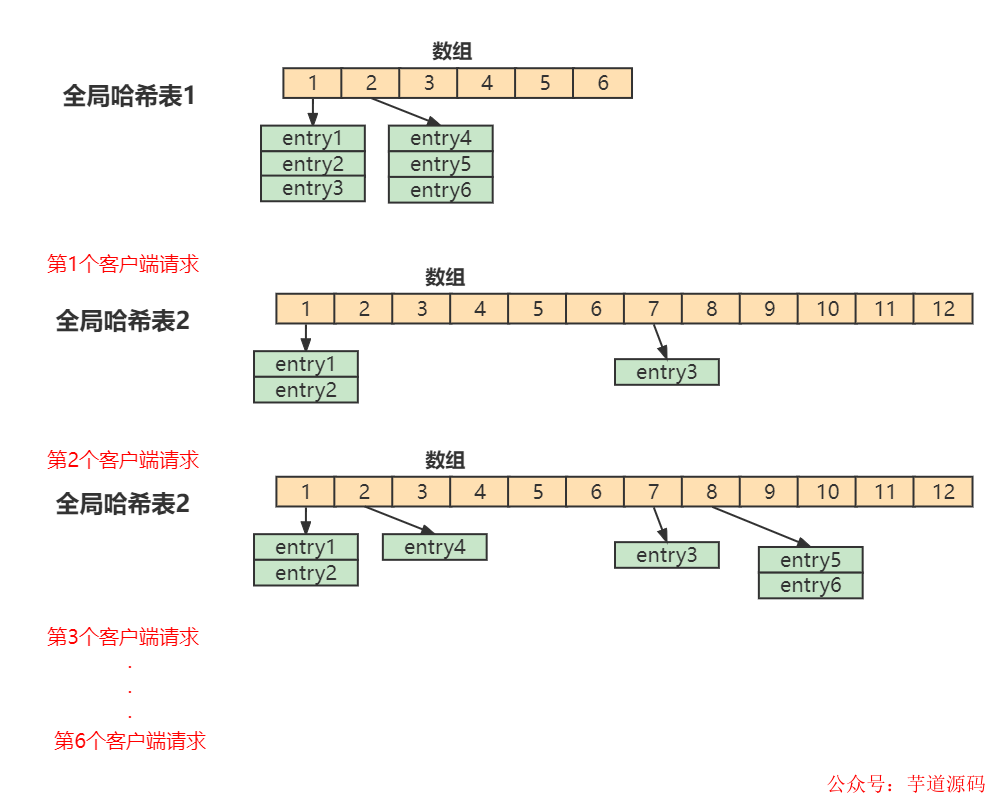
11、漸進(jìn)式rehash是什么?
Redis 默認(rèn)使用了兩個(gè)全局哈希表:哈希表 1 和哈希表 2。一開始,當(dāng)你剛插入數(shù)據(jù)時(shí),默認(rèn)使用哈希表 1,此時(shí)的哈希表 2 并沒有被分配空間。隨著數(shù)據(jù)逐步增多,Redis 開始執(zhí)行 rehash。
- 給哈希表 2 分配更大的空間,例如是當(dāng)前哈希表 1 大小的兩倍
- 把哈希表 1 中的數(shù)據(jù)重新映射并拷貝到哈希表 2 中
- 釋放哈希表 1 的空間
在上面的第二步涉及大量的數(shù)據(jù)拷貝,如果一次性把哈希表 1 中的數(shù)據(jù)都遷移完,會(huì)造成 Redis 線程阻塞。在Redis 開始執(zhí)行 rehash,Redis仍然正常處理客戶端請(qǐng)求,但是要加入一個(gè)額外的處理:
- 處理第1個(gè)請(qǐng)求時(shí),把哈希表 1中的第1個(gè)索引位置上的所有 entries 拷貝到哈希表 2 中
- 處理第2個(gè)請(qǐng)求時(shí),把哈希表 1中的第2個(gè)索引位置上的所有 entries 拷貝到哈希表 2 中
如此循環(huán),直到把所有的索引位置的數(shù)據(jù)都拷貝到哈希表 2 中。這樣就巧妙地把一次性大量拷貝的開銷,分?jǐn)偟搅硕啻翁幚碚?qǐng)求的過程中,避免了耗時(shí)操作,保證了數(shù)據(jù)的快速訪問。
審核編輯 :李倩
-
數(shù)據(jù)結(jié)構(gòu)
+關(guān)注
關(guān)注
3文章
573瀏覽量
40573 -
Redis
+關(guān)注
關(guān)注
0文章
384瀏覽量
11296
原文標(biāo)題:Redis 最全面試題(2023最新版)
文章出處:【微信號(hào):芋道源碼,微信公眾號(hào):芋道源碼】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
如何使用Rust連接Redis
Redis緩存和MySQL數(shù)據(jù)不一致原因和解決方案
Redis在高速緩存系統(tǒng)中的序列化算法研究
Java 使用Redis緩存工具的詳細(xì)解說
Windows環(huán)境下使用Redis緩存工具的圖文詳細(xì)方法
redis緩存mysql數(shù)據(jù)
關(guān)于redis中數(shù)據(jù)存儲(chǔ)的機(jī)制解析
Redis常見面試題及答案
Redis緩存的異常原因及其處理辦法分析
如何在SpringBoot中解決Redis的緩存穿透等問題
Oracle與Redis Enterprise協(xié)同,作為企業(yè)緩存解決方案





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論