 深入淺出Prompt Learning要旨及常用方法
深入淺出Prompt Learning要旨及常用方法
近年來 NLP 學術領域發展真是突飛猛進,剛火完對比學習(contrastive learning),又有更火的提示學習 prompt learning。眾所周知,數據標注數據很大程度上決定了 AI 算法上限,并且成本非常高,無論是對比學習還是提示學習都著重解決少樣本學習而提出,甚至在沒有標注數據的情況下,也能讓模型表現比較好的效果。本文主要介紹 prompt learning 思想和目前常用的方法。
NLP的訓練范式有哪些
目前學術界一般將 NLP 任務的發展分為四個階段即 NLP 四范式: 1. 第一范式:基于傳統機器學習模型的范式,如 tf-idf 特征 + 樸素貝葉斯等機器算法; 2. 第二范式:基于深度學習模型的范式,如 word2vec 特征 + LSTM 等深度學習算法,相比于第一范式,模型準確有所提高,特征工程的工作也有所減少; 3. 第三范式:基于預訓練模型 + finetuning 的范式,如 BERT + finetuning 的 NLP 任務,相比于第二范式,模型準確度顯著提高,但是模型也隨之變得更大,但小數據集就可訓練出好模型; 4. 第四范式:基于預訓練模型 + Prompt + 預測的范式,如 BERT + Prompt 的范式相比于第三范式,模型訓練所需的訓練數據顯著減少。
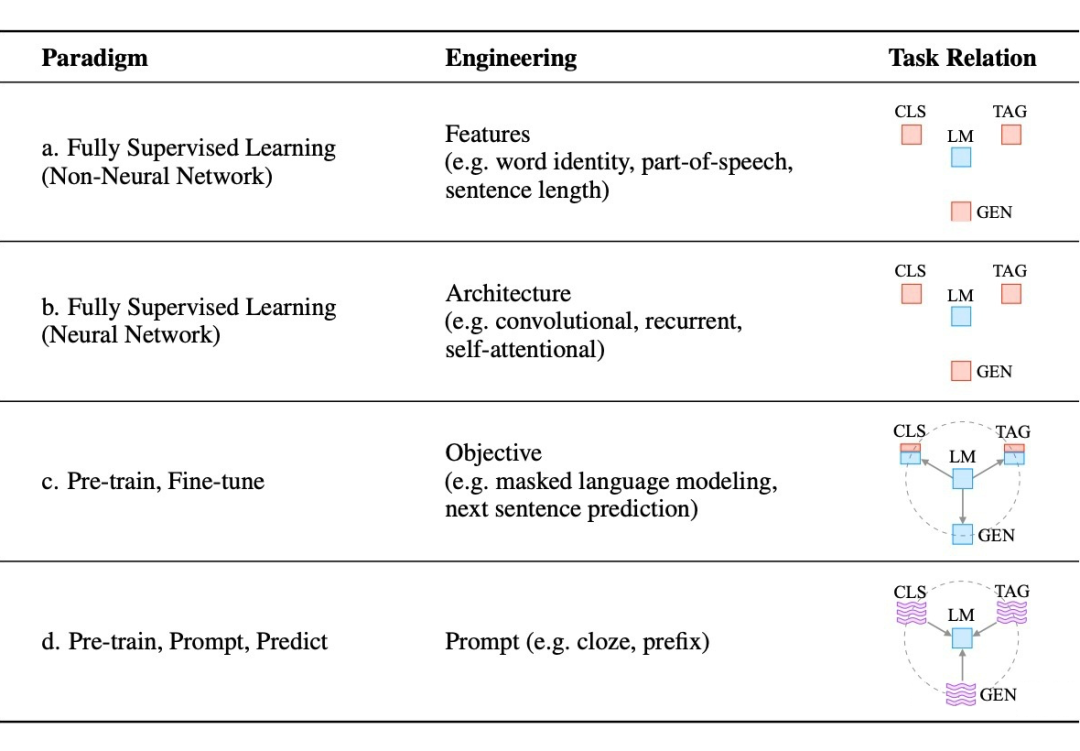
在整個 NLP 領域,你會發現整個發展是朝著精度更高、少監督,甚至無監督的方向發展的,而 Prompt Learning 是目前學術界向這個方向進軍最新也是最火的研究成果。 為什么需要提示學習 為什么呢?要提出一個好的方式那必然是用來解決另一種方式存在的缺陷或不足,那我們就先從它的上一個范式來說起,就是預訓練模型 PLM + finetuning 范式常用的是 BERT+ finetuning:
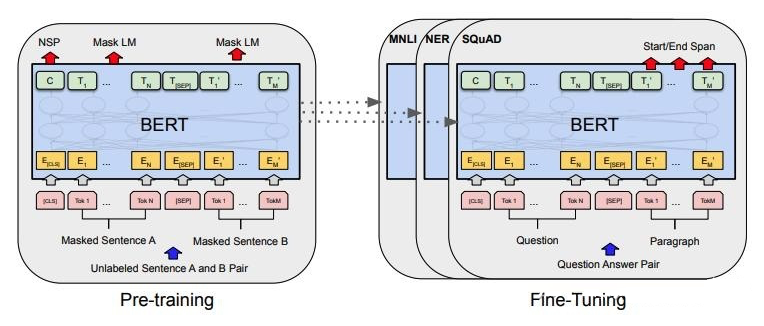
這種范式是想要預訓練模型更好的應用在下游任務,需要利用下游數據對模型參數微調;首先,模型在預訓練的時候,采用的訓練形式:自回歸、自編碼,這與下游任務形式存在極大的 gap,不能完全發揮預訓練模型本身的能力 必然導致:較多的數據來適應新的任務形式——>少樣本學習能力差、容易過擬合
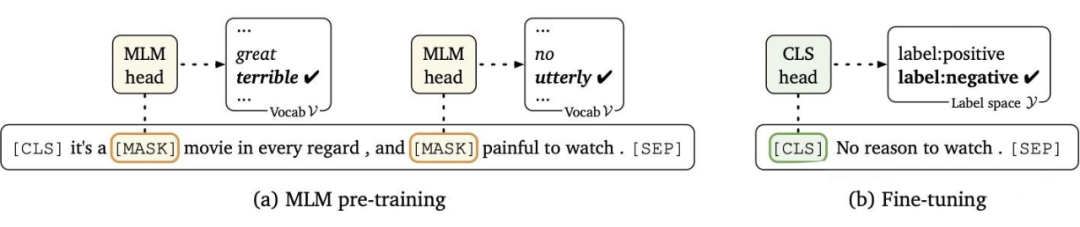
▲ 上下游任務形式存在gap 其次,現在的預訓練模型參數量越來越大,為了一個特定的任務去 finetuning 一個模型,然后部署于線上業務,也會造成部署資源的極大浪費。
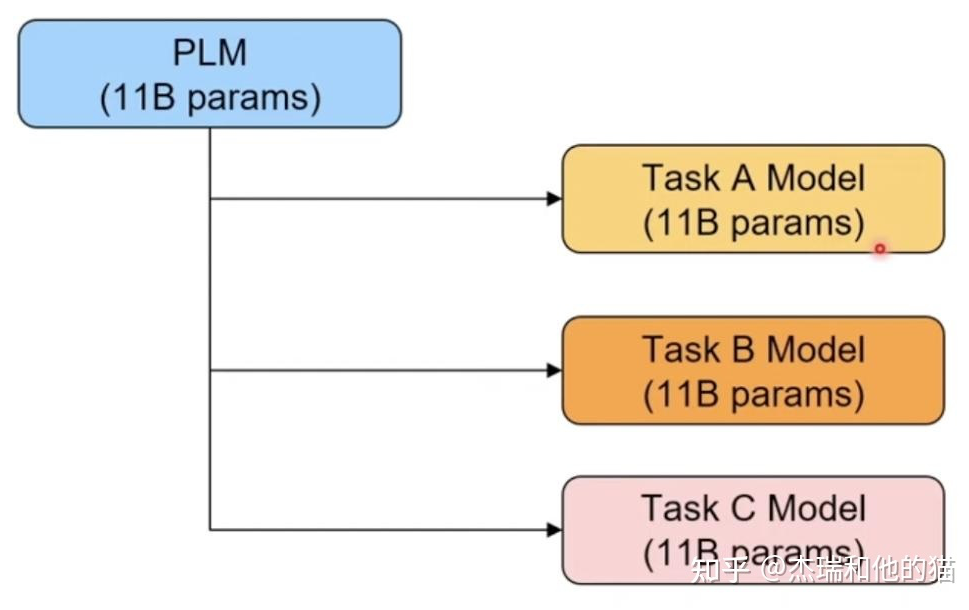
▲ 模型專用性特定任務微調導致部署成本過高
提示學習是什么
首先我們應該有的共識是:預訓練模型中存在大量知識;預訓練模型本身具有少樣本學習能力。 GPT-3 提出的 In-Context Learning,也有效證明了在 Zero-shot、Few-shot 場景下,模型不需要任何參數,就能達到不錯的效果,特別是近期很火的 GPT3.5 系列中的 ChatGPT。

Prompt Learning 的本質: 將所有下游任務統一成預訓練任務;以特定的模板,將下游任務的數據轉成自然語言形式,充分挖掘預訓練模型本身的能力。 本質上就是設計一個比較契合上游預訓練任務的模板,通過模板的設計就是挖掘出上游預訓練模型的潛力,讓上游的預訓練模型在盡量不需要標注數據的情況下比較好的完成下游的任務,關鍵包括 3 個步驟:
設計預訓練語言模型的任務
設計輸入模板樣式(Prompt Engineering)
設計 label 樣式及模型的輸出映射到 label 的方式(Answer Engineering)
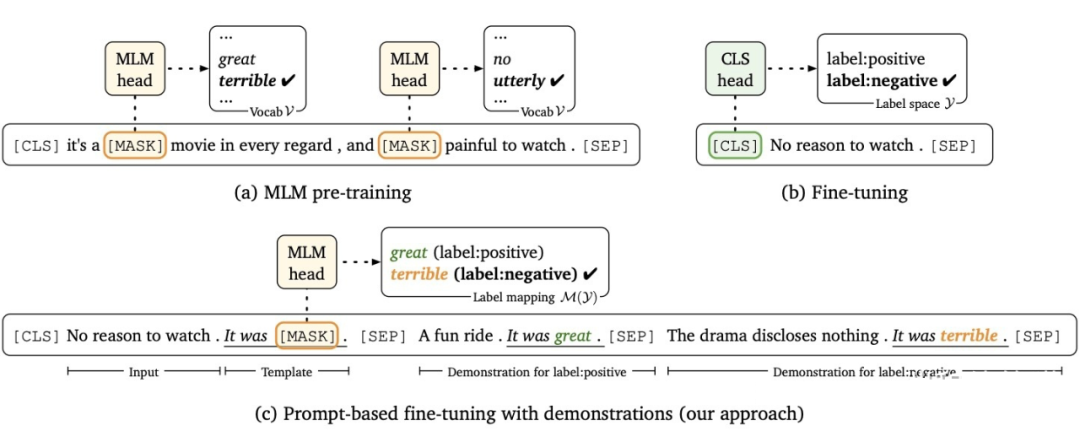
Prompt Learning 的形式: 以電影評論情感分類任務為例,模型需根據輸入句子做二分類: 原始輸入:特效非常酷炫,我很喜歡。 Prompt 輸入:提示模板 1:特效非常酷炫,我很喜歡。這是一部 [MASK] 電影;提示模板 2:特效非常酷炫,我很喜歡。這部電影很 [MASK] 提示模板的作用就在于:將訓練數據轉成自然語言的形式,并在合適的位置 MASK,以激發預訓練模型的能力。
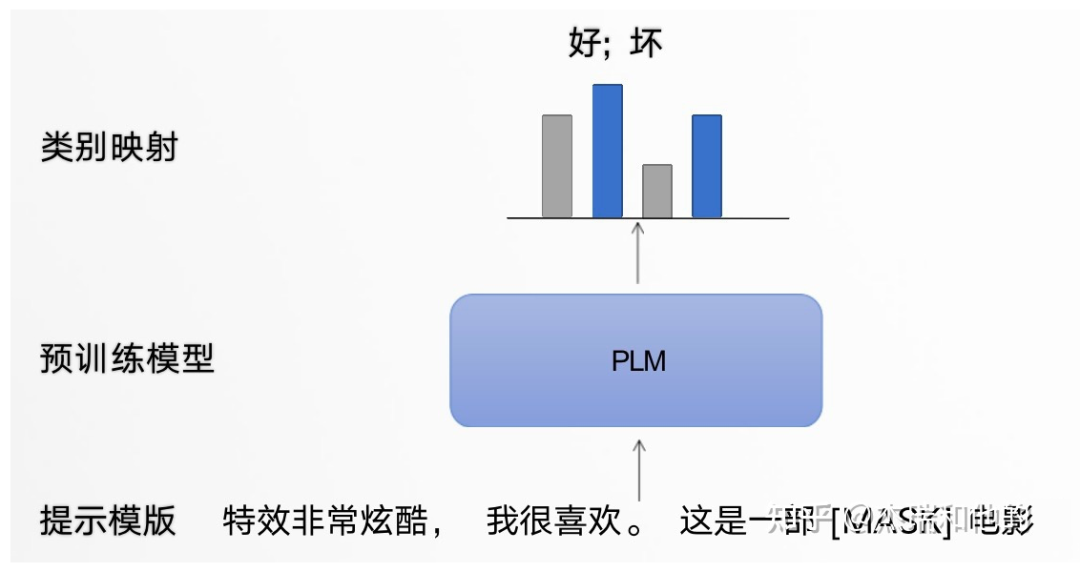
▲ 提示學習模板框架 類別映射 / Verbalizer:選擇合適的預測詞,并將這些詞對應到不同的類別。
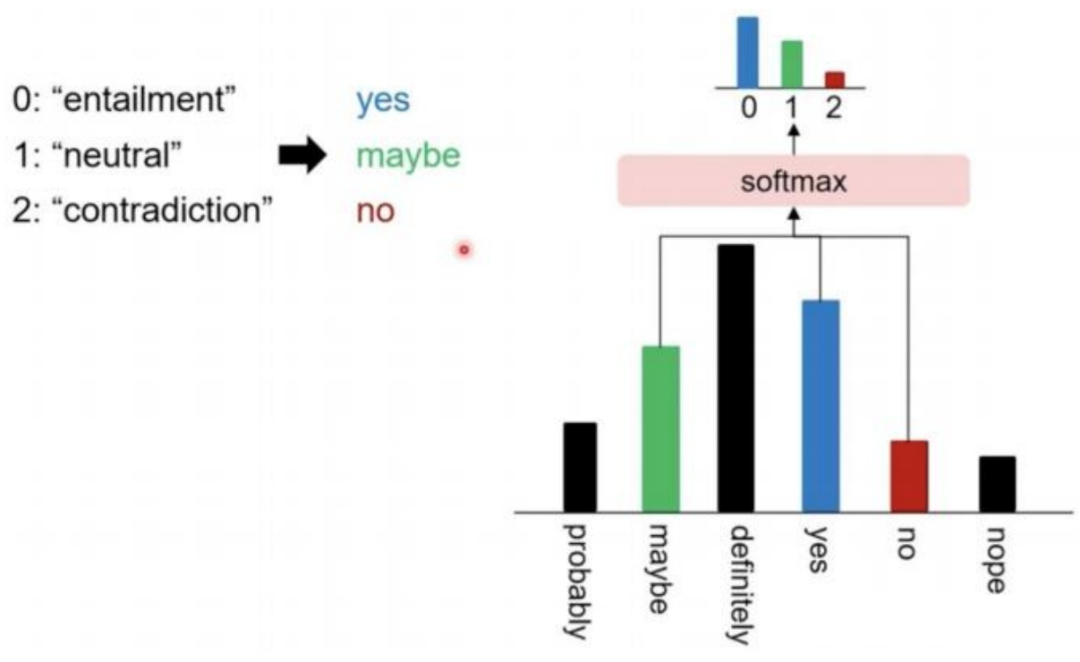
▲ 類別映射 通過構建提示學習樣本,只需要少量數據的 Prompt Tuning,就可以實現很好的效果,具有較強的零樣本/少樣本學習能力。
常見的提示學習方法
4.1 硬模板方法
4.1.1硬模板-PET(Pattern Exploiting Training) PET 是一種較為經典的提示學習方法,和之前的舉例一樣,將問題建模成一個完形填空問題,然后優化最終的輸出詞。雖然 PET 也是在優化整個模型的參數,但是相比于傳統的 Finetuning 方法,對數據量需求更少。 建模方式: 以往模型只要對 P(l|x) 建模就好了(l 是 label),但現在加入了 Prompt P 以及標簽映射(作者叫 verbalizer),所以這個問題就可以更新為:
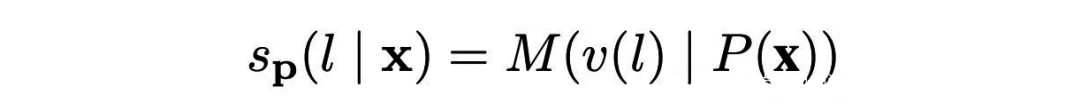
其中 M 表示模型,s 相當于某個 prompt 下生成對應 word 的 logits。再通過 softmax,就可以得到概率:
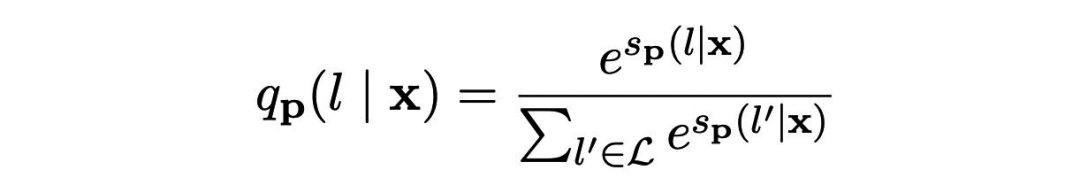
作者在訓練時又加上了 MLM loss,進行聯合訓練。
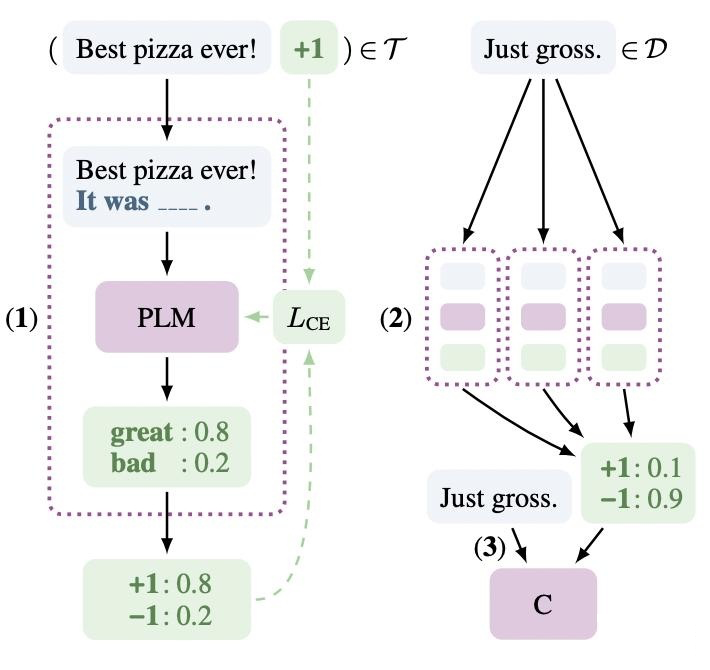
▲ 訓練架構 具體的做法:
在少量監督數據上,給每個 Prompt 訓練一個模型;
對于無監督數據,將同一個樣本的多個 prompt 預測結果進行集成,采用平均或加權(根據 acc 分配權重)的方式,再歸一化得到概率分布,作為無監督數據的 soft label ;
在得到的 soft label上 finetune 一個最終模型。
4.1.2 硬模板-LM-BFF LM-BFF 是陳天琦團隊的工作,在 Prompt Tuning 基礎上,提出了 Prompt Tuning with demonstration & Auto Prompt Generation。
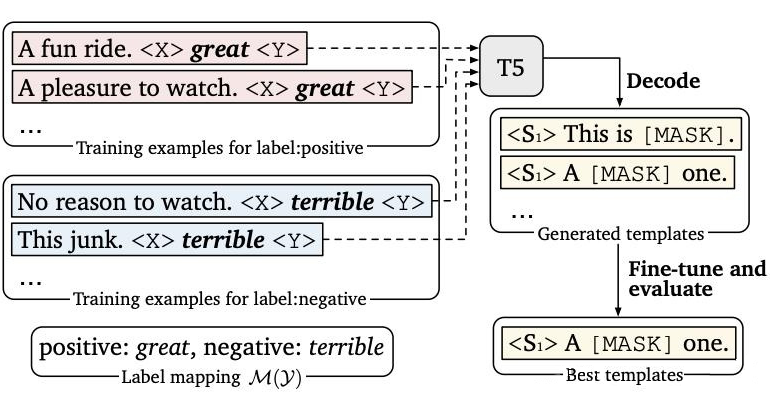
硬模板方法的缺陷: 硬模板產生依賴兩種方式:根據經驗的人工設計 & 自動化搜索。但是,人工設計的不一定比自動搜索的好,自動搜索的可讀性和可解釋性也不強。

上圖實驗結果可以看出硬模板 對于 prompt,改變 prompt 中的單個單詞會給實驗結果帶來巨大的差異,所以也為后續優化提供了方向,如索性直接放棄硬模板,去優化 prompt token embedding。
4.2軟模板方法
4.2.1 軟模板- P tuning 不再設計/搜索硬模板,而是在輸入端直接插入若干可被優化的 Pseudo Prompt Tokens,自動化地尋找連續空間中的知識模板:
不依賴人工設計
要優化的參數極少,避免了過擬合(也可全量微調,退化成傳統 finetuning)
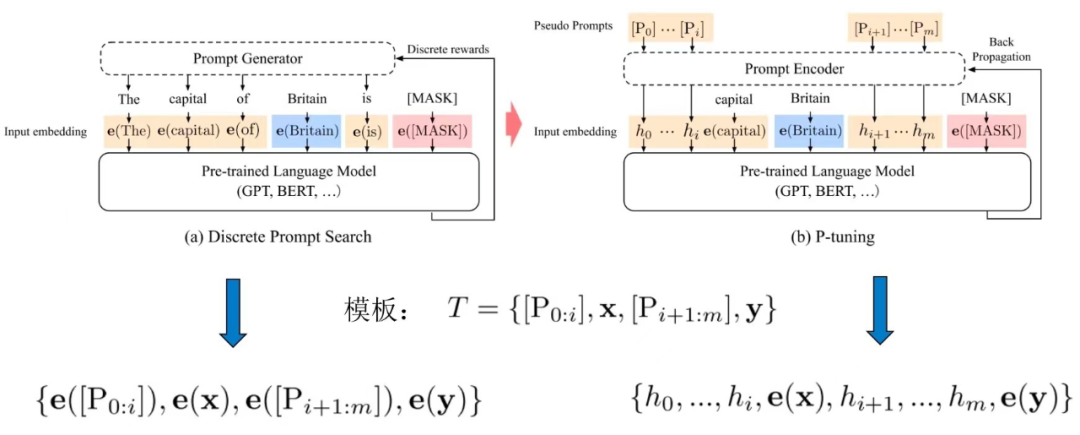
傳統離散 prompt 直接將模板 T 的每個 token 映射為對應的 embedding,而 P-Tuning 將模板 T 中的 Pi(Pseudo Prompt)映射為一個可訓練的參數 hi。 優化關鍵點在于,自然語言的 hard prompt,替換為可訓練的 soft prompt;使用雙向 LSTM 對模板 T 中的 pseudo token 序列進行表征;引入少量自然語言提示的錨字符(Anchor)提升效率,如上圖的“capital”,可見 p-tuning 是 hard+soft 的形式,并不是完全的 soft 形式。 具體的做法:
初始化一個模板:The capital of [X] is [mask]
替換輸入:[X] 處替換為輸入 “Britian”,即預測 Britain 的首都
挑選模板中的一個或多個 token 作為 soft prompt
將所有 soft prompt 送入 LSTM,獲得每個 soft prompt 的隱狀態向量 h
將初始模板送入 BERT 的 Embedding Layer,所有 soft prompt 的 token embedding 用 h 代替,然后預測mask。
核心結論:基于全量數據,大模型:僅微調 prompt 相關的參數,媲美 fine-tuning 的表現。 代碼:https://github.com/THUDM/
4.2.2 軟模板- Prefix tuning P-tuning 更新 prompt token embedding 的方法,能夠優化的參數較少。Prefix tuning 希望能夠優化更多的參數,提升效果,但是又不帶來過大的負擔。雖然 prefix tuning 是在生成任務上被提出來的,但是它對 soft prompt 后續發展有著啟發性的影響。
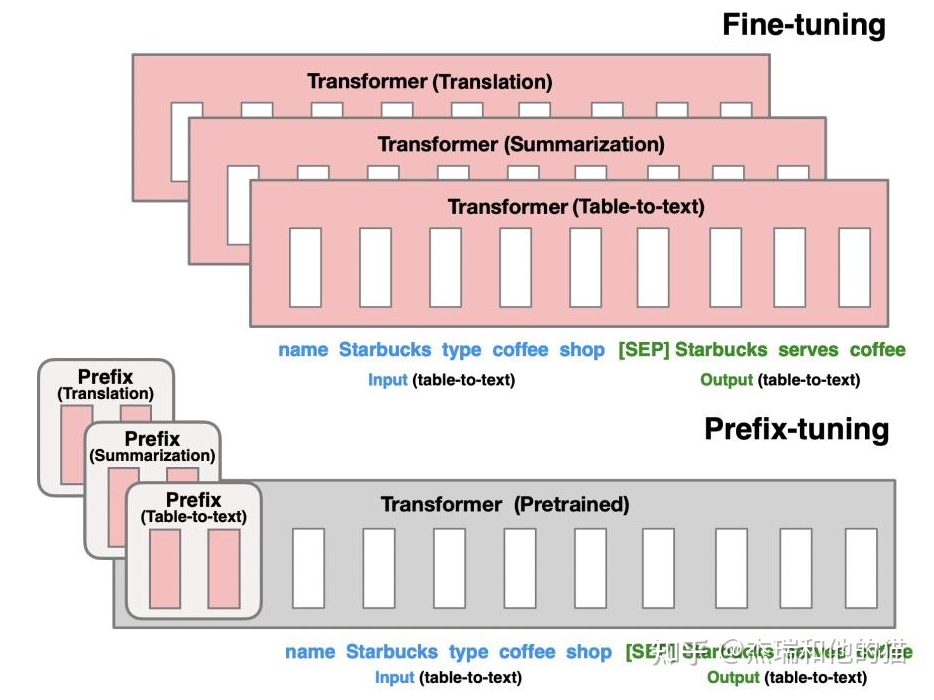
▲ 優化每一層的 Prompt token embedding,而不僅僅是輸入層
由上圖可見,模型上在每層 transformer 之前加入 prefix。特點是 prefix 不是真實的 token,而是連續向量(soft prompt),Prefix-tuning 訓練期間凍結 transformer 的參數,只更新 Prefix 的參數。 只需要存儲大型 transformer 的一個副本和學習到的特定于任務的前綴即可,為每個附加任務產生非常小的開銷。

▲ 自回歸模型
以圖上自回歸模型為例的做法:
輸入表示為 Z = [ prefix ; x ; y ]
Prefix-tuning 初始化一個訓練的 矩陣 P,用于存儲 prefix parameters
前綴部分 token,參數選擇設計的訓練矩陣,而其他部分的 token,參數則固定 且為預訓練語言模型的參數
核心結論:Prefix-tuning 在生成任務上,全量數據、大模型:僅微調 prompt 相關的參數,媲美 fine-tuning 的表現。 代碼:https://github.com/XiangLi1999/PrefixTuning
4.2.3 軟模板- Soft Prompt Tuning Soft Prompt Tuning 系統后驗證了軟模板方法的有效性,并提出:固定基礎模型,有效利用任務特定的 Soft Prompt Token,可以大幅減少資源占用,達到大模型的通用性。 對 Prefix-tuning 的簡化,固定預訓練模型,只對下游任務的輸入添加額外的 k 個可學習的 token。這種方式在大規模預訓練模型的前提下,能夠媲美傳統的 fine-tuning 表現。
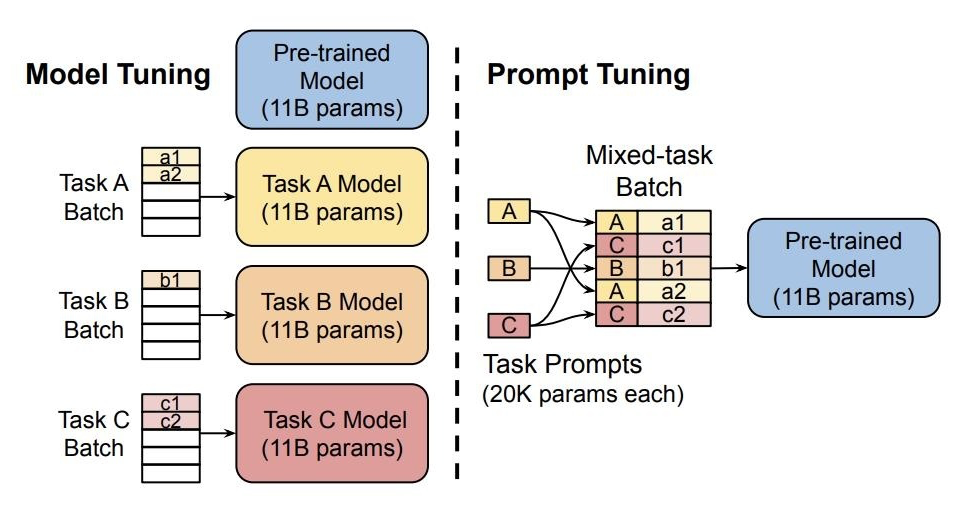
代碼:https://github.com/kipgparker/soft-prompt-tuning
總結
Prompt Learning 的組成部分
提示模板:根據使用預訓練模型,構建完形填空 or 基于前綴生成兩種類型的模板
類別映射 / Verbalizer:根據經驗選擇合適的類別映射詞
預訓練語言模型
典型的 Prompt Learning 方法總結
硬模板方法:人工設計/自動構建基于離散 token的模板
1)PET
2)LM-BFF
2. 軟模板方法:不再追求模板的直觀可解釋性,而是直接優化 Prompt Token Embedding,是向量/可學習的參數
1)P-tuning
2)Prefix Tuning
審核編輯 :李倩
-
數據
+關注
關注
8文章
7241瀏覽量
91028 -
模型
+關注
關注
1文章
3488瀏覽量
49999 -
nlp
+關注
關注
1文章
490瀏覽量
22487
原文標題:深入淺出Prompt Learning要旨及常用方法
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄







 工商網監
工商網監
評論