") 什么是卷積神經(jīng)網(wǎng)絡(luò)(CNN)
什么是卷積神經(jīng)網(wǎng)絡(luò)(CNN)
以卷積結(jié)構(gòu)為主,搭建起來的深度網(wǎng)絡(luò)(一般都指深層結(jié)構(gòu)的)
CNN目前在很多很多研究領(lǐng)域取得了巨大的成功,例如: 語音識別,圖像識別,圖像分割,自然語言處理等。對于大型圖像處理有出色表現(xiàn)。
一般將圖片作為網(wǎng)絡(luò)的輸入,自動提取特征,并且對圖片的變形(平移,比例縮放)等具有高度不變形
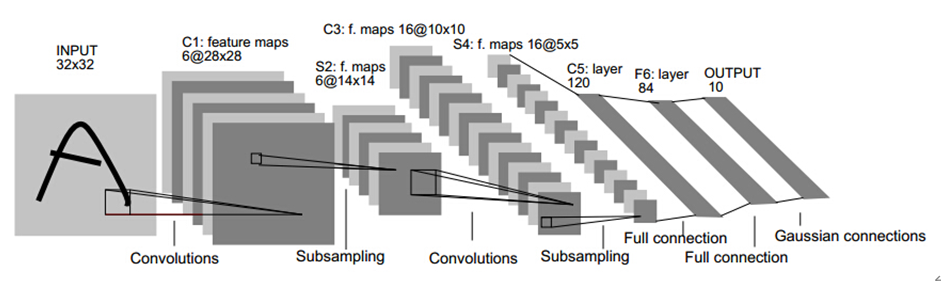
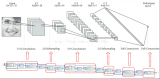
上圖是手寫識別的卷積神經(jīng)網(wǎng)絡(luò)模型,我們可以發(fā)現(xiàn)卷積神經(jīng)網(wǎng)絡(luò)的重要組成部分:
卷積層、池化層、激活層、BN層、LOSS層、其它層
卷積的基本定義
卷積就是一種運(yùn)算,是對圖像和濾波矩陣做內(nèi)積(逐個元素相乘再求和)的操作。
每一種卷積對應(yīng)一種特征。
其中濾波矩陣在深度學(xué)習(xí)中,我們稱之為卷積核。換句話說,我們一般可以將卷積看成濾波器。比如我們可以通過濾波器對圖像進(jìn)行降噪,圖像的噪點(diǎn)就是高頻信號。在圖像處理中,有很多濾波器可以供我們選擇。每一種濾波器幫助我們提取不同的特征。比如水平/垂直/對角線邊緣等等。
可以看這篇回答 ^[1]^ ,挺通俗易懂的。
卷積層
卷積的核心是卷積核,核就是一組權(quán)重,它決定了一個像素點(diǎn)如何通過周圍的其他像素點(diǎn)計(jì)算獲得新的像素點(diǎn)數(shù)值。核也被稱之為卷積矩陣,它會對一塊區(qū)域的像素做調(diào)和運(yùn)算或卷積運(yùn)算。
一般最常用為2D卷積核(k_w * k_h),如 1x1,3x3, 5x5, 7x7
卷積核的數(shù)值都是奇數(shù),因?yàn)槠鏀?shù)的卷積核有一個中心點(diǎn)

我們可以利用有中心點(diǎn)的特性來保護(hù)圖片位置信息,padding時對稱。
卷積還具有 權(quán)值共享 與 局部連接(局部感受野/局部感知)的特性。
在卷積層中權(quán)值共享是用來控制參數(shù)的數(shù)量。假如在一個卷積核中,每一個感受野采用的都是不同的權(quán)重值(卷積核的值不同),那么這樣的網(wǎng)絡(luò)中參數(shù)數(shù)量將是十分巨大的。
那么感受野是什么?感受野是卷積神經(jīng)網(wǎng)絡(luò)每一層輸出的特征圖(Feature Map)上的像素點(diǎn)在原始圖像上映射的區(qū)域大小。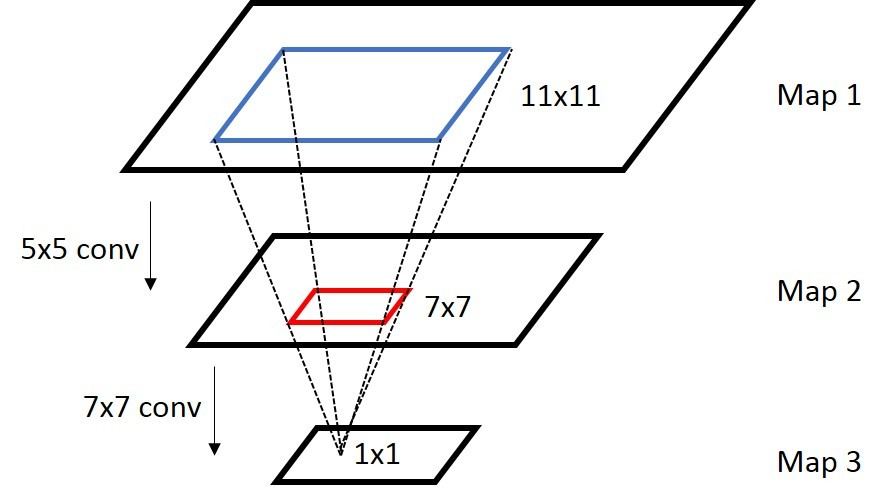 (圖片來源于網(wǎng)絡(luò),侵刪)
(圖片來源于網(wǎng)絡(luò),侵刪)
神經(jīng)網(wǎng)絡(luò)中,卷積核越大,雖然感受野越大,但參數(shù)越多,結(jié)構(gòu)就越復(fù)雜,越容易過擬合。另一方面,需要更多的數(shù)據(jù)來訓(xùn)練,訓(xùn)練的難度也會更大。所以一般我們采用小卷積核堆加的方式來,保證感知野盡量大,同時結(jié)構(gòu)盡可能簡單,降低計(jì)算量。
Pad
pad可以讓你的輸入圖像不變小,而可以使用更深層的卷積.確保Feature Map整數(shù)倍變化,對尺度敏感的任務(wù)非常重要.
池化層
池化層的作用是對輸入的特征圖錯開行或列,壓縮特征圖大小,降低參數(shù)量和計(jì)算復(fù)雜度,也對特征進(jìn)行了壓縮,提取主要特征,將語義相似的特征融合起來,對微小的平移和形變不敏感。包括平均池化和最大池化和隨機(jī)池化,平均池化領(lǐng)域內(nèi)方差小,更多的保留圖像的背景信息,最大池化領(lǐng)域內(nèi)均值偏移大,更多的保留圖像的紋理信息,隨機(jī)池化(Stochastic Pooling)則介于兩者之間。
值得注意的是:池化層是無參的。
池化層相較于卷積層相對簡單許多。如果圖像太大的時候,就需要減少訓(xùn)練參數(shù)的數(shù)量,池化層須在隨后的卷積層之間周期性地被引進(jìn)。池化的直接目的是為了減少圖像的空間大小。池化在每一個縱深維度上獨(dú)自完成,因此圖像的縱深保持不變。取一小塊區(qū)域,比如一個55的方塊,如果是最大值池化,那就選這25個像素點(diǎn)最大的那個輸出,如果是平均值池化,就把25個像素點(diǎn)取平均輸出。這樣在原來55的一個區(qū)域,現(xiàn)在只要一個值就能表示出來了。池化操作可以看做是一種強(qiáng)制性的模糊策略,不斷強(qiáng)制模糊增加特征的旋轉(zhuǎn)不變性。這樣當(dāng)圖片無論如何旋轉(zhuǎn)時,經(jīng)過池化之后結(jié)果特征都是近似的。
激活層
激活函數(shù)(Activation Function): 如果一旦將線性分量運(yùn)用于輸入,就會需要運(yùn)用一個非線性函數(shù)來組合實(shí)現(xiàn)達(dá)到任意函數(shù)的目的。激活函數(shù)能將輸入信號轉(zhuǎn)換為輸出信號。形如f(x * W+ b)就是應(yīng)用激活函數(shù)后的輸出看起來的樣子,其中f()就是激活函數(shù)。如圖(添加激活函數(shù)后的神經(jīng)元模型):
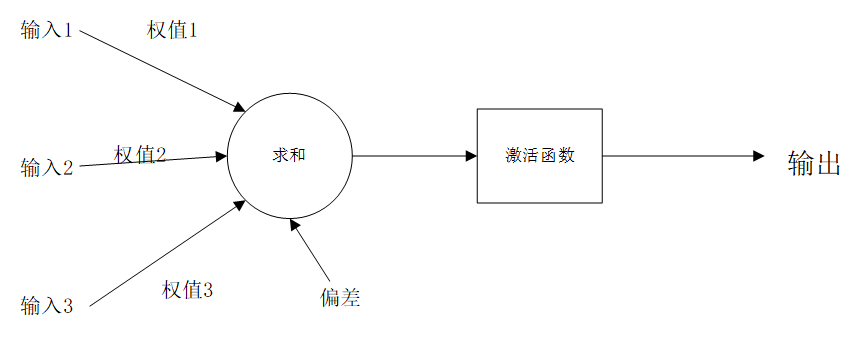
通俗點(diǎn)講:激活函數(shù) 增加網(wǎng)絡(luò)的非線性,進(jìn)而提高網(wǎng)絡(luò)的表達(dá)能力
基本的常見激活函數(shù)有Sigmoid,ReLU和Softmax,下面簡單介紹一下:
1)Sigmoid:
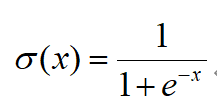
它會將輸入的數(shù)值壓縮到0到1范圍內(nèi),比較適合輸出需求為概率的情況。但它在神經(jīng)元的激活在接近0或1處時會飽和,在這些區(qū)域時的梯度幾乎為0,這就會導(dǎo)致梯度消失,這就會導(dǎo)致幾乎沒有信號能通過神經(jīng)傳回上一層神經(jīng)層。Sigmoid函數(shù)的輸出不是以零為中心的。如果是以零為中心的話,假設(shè)輸入神經(jīng)元的數(shù)據(jù)總是為正數(shù)的話,那么關(guān)于w的梯度在反向傳播的過程中,將會出現(xiàn)一種情況:要么全是正數(shù),要么全是負(fù)數(shù),這就會導(dǎo)致梯度下降,權(quán)重更新時,出現(xiàn)形如“Z”字型的下降。
下圖:Sigmoid的函數(shù)圖像
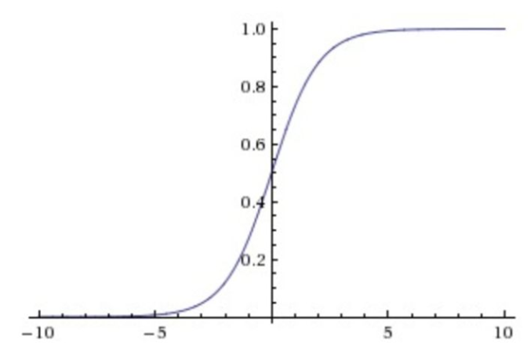
2)ReLU:
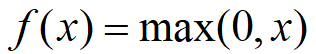
與Sigmoid激活函數(shù)相比的它具有的獨(dú)特性是:單側(cè)抑制的特性和稀疏激活性。保留了step函數(shù)的生物學(xué)啟發(fā)(只有輸入超出閥值時神經(jīng)元才會被激活) 相較于Sigmoid激活函數(shù),ReLU激活函數(shù)能夠巨大地加速隨機(jī)梯度下降的收斂的速度;但由于ReLU單元比較脆弱,可能導(dǎo)致數(shù)據(jù)多樣性的丟失,且過程是不可逆的。所以使用時,需要謹(jǐn)慎。
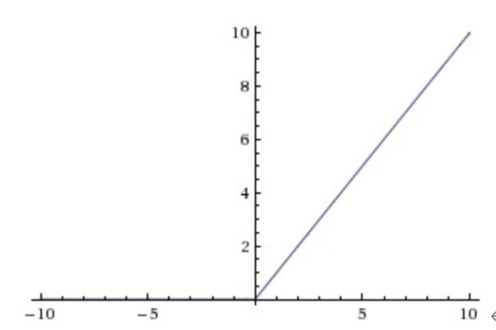
3)Softmax:
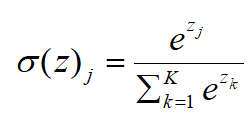
Softmax激活函數(shù)通常用于輸出層,一般用于問題的分類。與Sigmoid激活函數(shù)相比,輸出被歸一化的總和為1是唯一的區(qū)別,其他就很類似。Sigmoid激活函數(shù)會阻止有二進(jìn)制輸出,當(dāng)遇到一個多類分類問題,Softmax激活函數(shù)會簡單化為每個類分配值的過程。
BatchNorm層
通過歸一化將數(shù)據(jù)分布拉回標(biāo)準(zhǔn)正態(tài)分布,使得梯度一直處于比較大的狀態(tài);同時如果直接歸一化為均值為0方差為1的標(biāo)準(zhǔn)正太分布,就抹掉了前面學(xué)習(xí)的非線性表達(dá)能力,因此在batchnorm的實(shí)現(xiàn)過程中,增加了平移和縮放參數(shù)。保留了非線性。
BatchNorm層的優(yōu)點(diǎn):
- 減少了參數(shù)的人為選擇,使得調(diào)參更容易
- 初始化要求也沒那么高,減少了對學(xué)習(xí)率的要求,可以使用更大的學(xué)習(xí)率;
- 降低了數(shù)據(jù)之間的絕對差異,有去相關(guān)的作用,更多考慮相對差異,有利于分類;
- BN是一種正則,可以代替dropout,取消L2正則項(xiàng)參數(shù),或者采取更小的L2正則項(xiàng)約束參數(shù)。
- BN本身就是歸一化網(wǎng)絡(luò),一定程度上可以緩解過擬合,解決梯度消失問題。
全連接層
全連接層將學(xué)到的“分布式特征表示”映射到樣本標(biāo)記空間。它是在整個卷積神經(jīng)網(wǎng)絡(luò)中起到“分類器”的作用,將二維空間轉(zhuǎn)化成一維向量,將全連接層的輸出送入分類器或回歸器來做分類和回歸。
Dropout層
Dropout(隨機(jī)失活正則化),是一種正則化方法,通過對網(wǎng)絡(luò)某層的節(jié)點(diǎn)都設(shè)置一個被消除的概率,之后在訓(xùn)練中按照概率隨機(jī)將某些節(jié)點(diǎn)消除掉,以達(dá)到正則化,降低方差的目的。
Dropout層可以解決過擬合問題,取平均的作用,減少神經(jīng)元之間復(fù)雜的共適應(yīng)關(guān)系
常見的卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)
LeNet、AlexNet、ZFNet、VGGNet、Inception和ResNet和輕量型卷積神經(jīng)網(wǎng)絡(luò)等等(這里就不展開講了,太多了,感興趣自行研究)
卷積的概念展開來講還是太多太深奧了,數(shù)學(xué)公式一大堆,小牛這段時間就簡單學(xué)習(xí)比較常見的部分,有些原理明白但無法用直白的語言寫出來,這部分寫的很吃力也不知道該寫些什么,就把筆記和以前寫的論文部分貼了貼。后面會盡快進(jìn)入代碼部分。(這部分寫起來快自閉了- -)
參考:
《深度學(xué)習(xí)模型微服務(wù)化管理系統(tǒng)的設(shè)計(jì)與實(shí)現(xiàn)》
https://mlnotebook.github.io/post/CNN1/ https://zhuanlan.zhihu.com/p/47184529 https://blog.csdn.net/baidu_27643275/article/details/88711329 https://zhuanlan.zhihu.com/p/106142812
-
cnn
+關(guān)注
關(guān)注
3文章
354瀏覽量
22622 -
自然語言處理
+關(guān)注
關(guān)注
1文章
627瀏覽量
13998 -
卷積神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
4文章
369瀏覽量
12175
發(fā)布評論請先 登錄
使用Python卷積神經(jīng)網(wǎng)絡(luò)(CNN)進(jìn)行圖像識別的基本步驟
TF之CNN:Tensorflow構(gòu)建卷積神經(jīng)網(wǎng)絡(luò)CNN的嘻嘻哈哈事之詳細(xì)攻略
利用Keras實(shí)現(xiàn)四種卷積神經(jīng)網(wǎng)絡(luò)(CNN)可視化
卷積神經(jīng)網(wǎng)絡(luò)(CNN)是如何定義的?
卷積神經(jīng)網(wǎng)絡(luò)(CNN)的參數(shù)優(yōu)化方法
14種模型設(shè)計(jì)幫你改進(jìn)你的卷積神經(jīng)網(wǎng)絡(luò)(CNN)
卷積神經(jīng)網(wǎng)絡(luò)(CNN)的簡單介紹及代碼實(shí)現(xiàn)
卷積神經(jīng)網(wǎng)絡(luò)CNN圖解

卷積神經(jīng)網(wǎng)絡(luò)CNN架構(gòu)分析-LeNet

簡單快捷地用小型Xiliinx FPGA加速卷積神經(jīng)網(wǎng)絡(luò)CNN





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論