") OpenAI推出AI真假鑒別工具,成功率僅有26%
OpenAI推出AI真假鑒別工具,成功率僅有26%

很多人也許已經(jīng)忘記,ChatGPT 正式發(fā)布時間是去年 11 月底,到現(xiàn)在才剛剛兩個月,但它掀起的熱潮卻已引發(fā)科技公司紛紛跟進,催生了獨角獸創(chuàng)業(yè)公司,還讓學(xué)術(shù)界修改了論文接收的要求。
在 ChatGPT 引發(fā) AI 領(lǐng)域「是否要禁用」大討論之后,OpenAI 的真假鑒別工具終于來了。
1 月 31 日 OpenAI 官宣了區(qū)分人類作品和 AI 生成文本的識別工具上線,該技術(shù)旨在識別自家的 ChatGPT、GPT-3 等模型生成的內(nèi)容。然而分類器目前看起來準(zhǔn)確性堪憂:OpenAI 在博客里指出 AI 識別 AI 高置信度正確率約為 26%。但該機構(gòu)認為,當(dāng)它與其他方法結(jié)合使用時,可以有助于防止 AI 文本生成器被濫用。
「我們提出分類器的目的是幫助減少人工智能生成的文本造成的混淆。然而它仍然有一些局限性,因此它應(yīng)該被用作其他確定文本來源方法的補充,而不是作為主要的決策工具,」OpenAI 發(fā)言人通過電子郵件對媒體介紹道。「我們正通過這個初始分類器獲取有關(guān)此類工具是否有用的反饋,并希望在未來分享改進的方法。」
最近科技領(lǐng)域隨著圍繞生成式 AI,尤其是文本生成 AI 的熱情正在不斷增長,但相對的是人們對于濫用的擔(dān)憂,批評者呼吁這些工具的創(chuàng)造者應(yīng)該采取措施減輕其潛在的有害影響。
面對海量的 AI 生成內(nèi)容,一些行業(yè)立刻作出了限制,美國一些最大的學(xué)區(qū)已禁止在其網(wǎng)絡(luò)和設(shè)備上使用 ChatGPT,擔(dān)心會影響學(xué)生的學(xué)習(xí)和該工具生成的內(nèi)容的準(zhǔn)確性。包括 Stack Overflow 在內(nèi)的網(wǎng)站也已禁止用戶共享 ChatGPT 生成的內(nèi)容,稱人工智能會讓用戶在正常的討論中被無用內(nèi)容淹沒。
這些情況突出了 AI 識別工具的必要性。雖然效果不盡如人意,但 OpenAI AI 文本分類器(OpenAI AI Text Classifier)在架構(gòu)上實現(xiàn)了和 GPT 系列的對標(biāo)。它和 ChatGPT 一樣是一種語言模型,是根據(jù)來自網(wǎng)絡(luò)的許多公開文本示例進行訓(xùn)練的。與 ChatGPT 不同的是,它經(jīng)過微調(diào)可以預(yù)測一段文本由 AI 生成的可能性 —— 不僅來自 ChatGPT,也包括來自任何文本生成 AI 模型的內(nèi)容。
具體來說,OpenAI 在來自五個不同組織(包括 OpenAI 自己)的 34 個文本生成系統(tǒng)的文本上訓(xùn)練了 AI 文本分類器。這些內(nèi)容與維基百科中相似(但不完全相同)的人工文本、從 Reddit 上共享的鏈接中提取的網(wǎng)站以及為 OpenAI 文本生成系統(tǒng)收集的一組「人類演示」配對。
需要注意的是,OpenAI 文本分類器不適用于所有類型的文本。被檢測的內(nèi)容至少需要 1000 個字符,或大約 150 到 250 個單詞。它沒有論文檢測平臺那樣的查重能力 —— 考慮到文本生成人工智能已被證明會照抄訓(xùn)練集里的「正確答案」,這是一個非常難受的限制。OpenAI 表示,由于其英語前向數(shù)據(jù)集,它更有可能在兒童或非英語語言書寫的文本上出錯。
在評估一段給定的文本是否由 AI 生成時,檢測器不會正面回答是或否。根據(jù)其置信度,它會將文本標(biāo)記為「非常不可能」由 AI 生成(小于 10% 的可能性)、「不太可能」由 AI 生成(在 10% 到 45% 之間的可能性)、「不清楚它是否是」AI 生成(45% 到 90% 的機會)、「可能」由 AI 生成(90% 到 98% 的機會)或「很有可能」由 AI 生成(超過 98% 的機會)。
看起來和圖像識別的 AI 很像,除了準(zhǔn)確程度。根據(jù) OpenAI 的說法,分類器錯誤地將人類編寫的文本標(biāo)記為 AI 編寫的文本的概率為 9%。
一番試用之后,效果的確不大行
OpenAI 宣稱其 AI 文本分類器的成功率約為 26%,一些網(wǎng)友上手試用之后,發(fā)現(xiàn)識別效果果然不行。
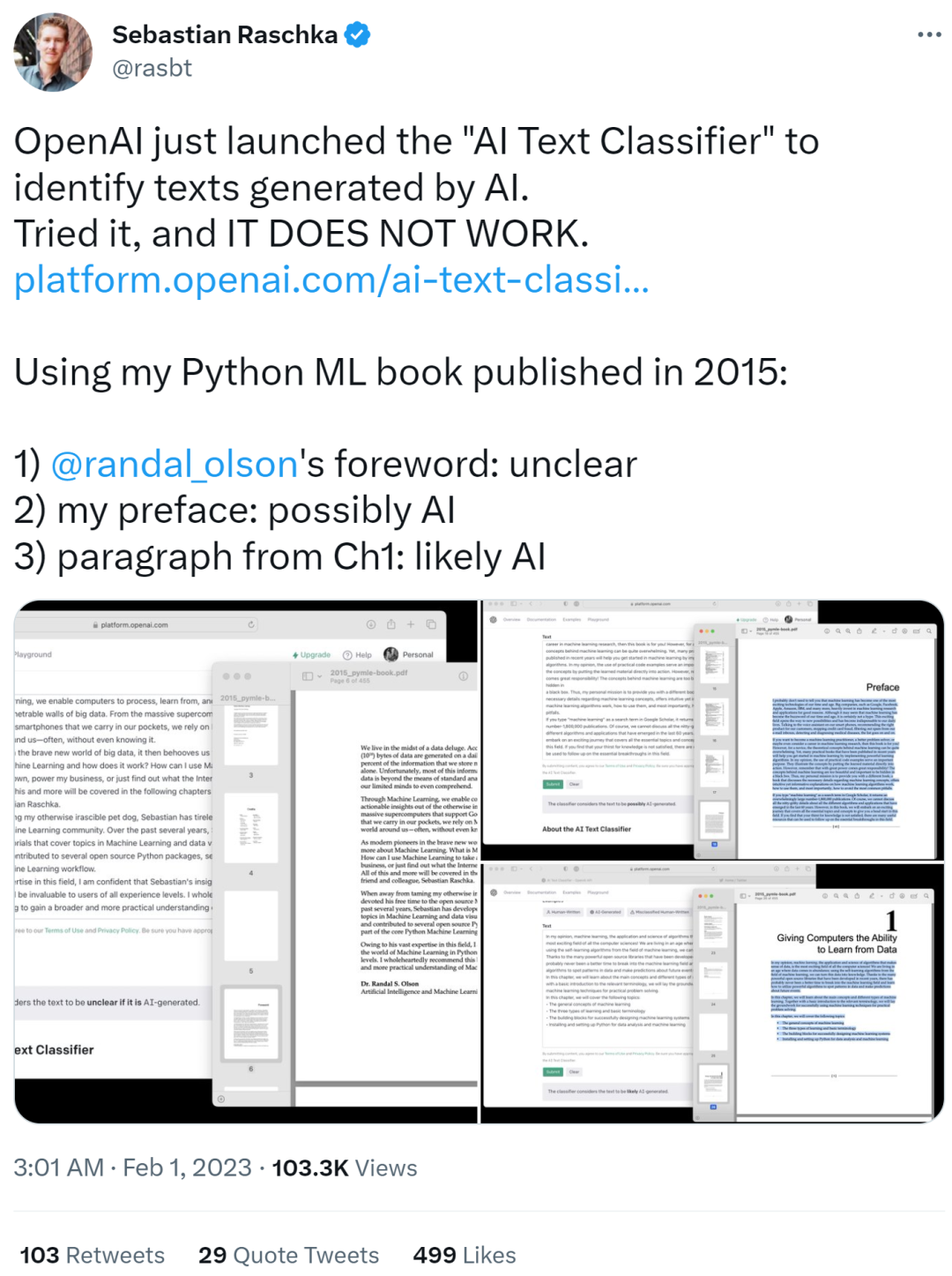
知名 ML 和 AI 研究人員 Sebastian Raschka 試用之后,給出了「It does not work」的評價。他使用其 2015 年初版的 Python ML 書籍作為輸入文本,結(jié)果顯示如下。
Randy Olson 的 foreword 部分被識別為不清楚是否由 AI 生成(unclear)
他自己的 preface 部分被識別為可能由 AI 生成(possibly AI)
第一章的段落部分被識別為很可能由 AI 生成(likely AI)
Sebastian Raschka 對此表示,這是一個有趣的例子,但自己已經(jīng)為將來可能因離譜的論文識別結(jié)果而受到懲罰的學(xué)生感到難過了。
因此他提議,如果要部署這樣的模型,請共享一個混淆矩陣。不然如果教育者采用這一模型進行評分,則可能會對現(xiàn)實世界造成傷害。此外還應(yīng)該增加一些有關(guān)誤報和漏報的透明度。
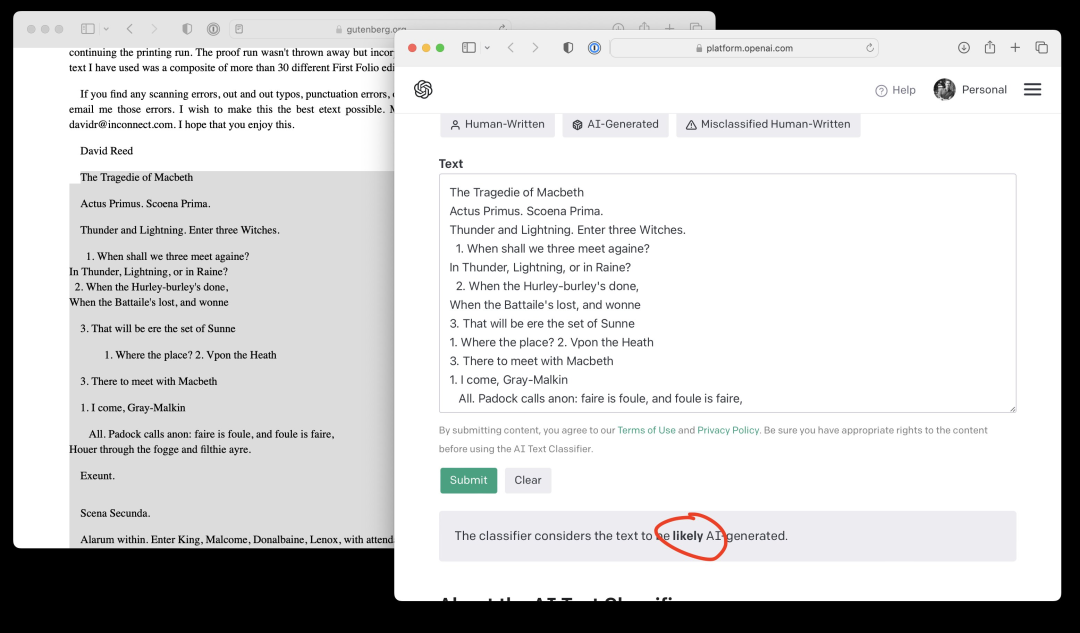
此外,Sebastian Raschka 輸入了莎士比亞《麥克白》第一頁的內(nèi)容,OpenAI AI 文本分類器給出的結(jié)果竟然是很可能由 AI 生成。簡直離譜!
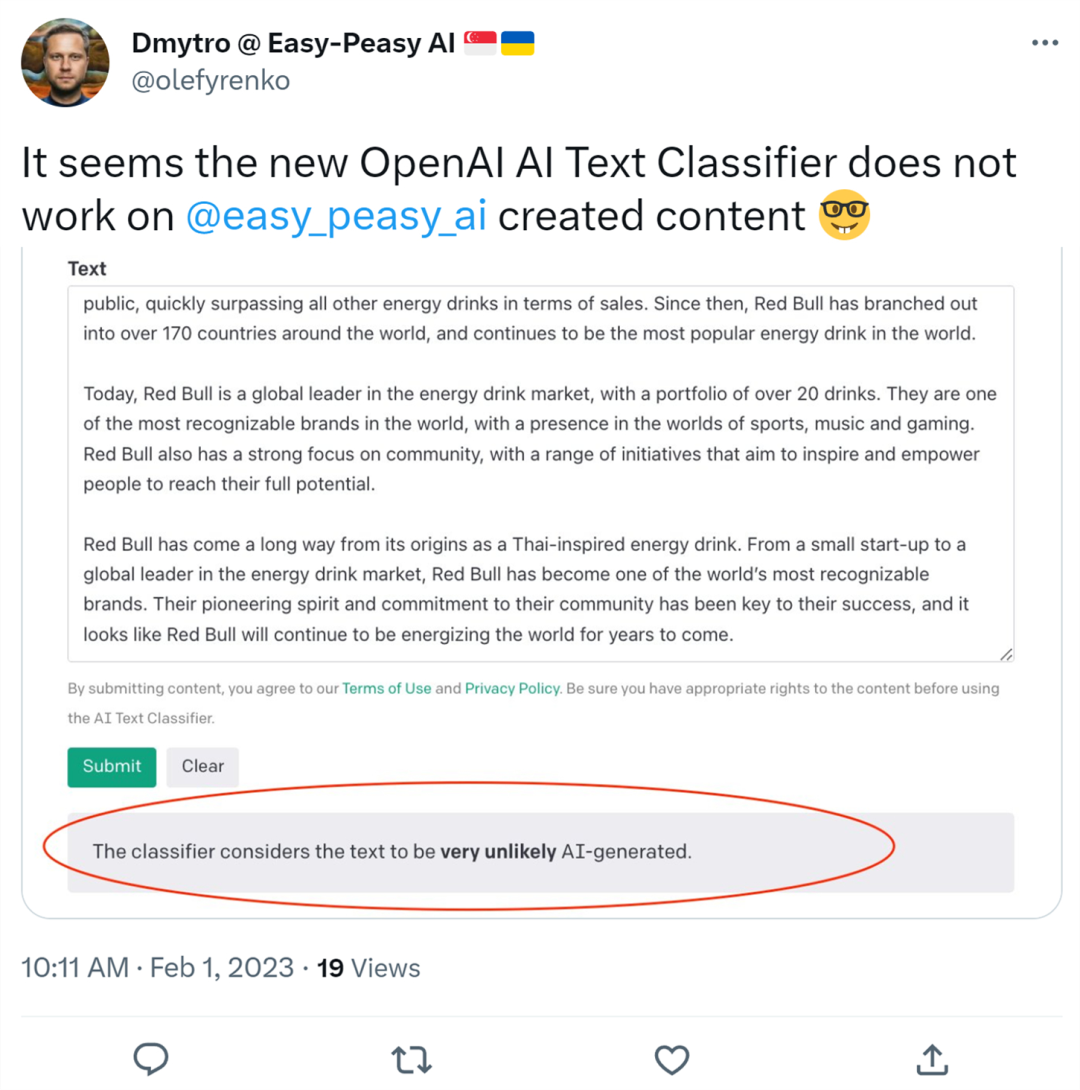
還有人上傳了 AI 寫作工具 Easy-Peasy.AI 創(chuàng)作的內(nèi)容,結(jié)果 OpenAI AI 文本分類器判定為由 AI 生成的可能性非常小。
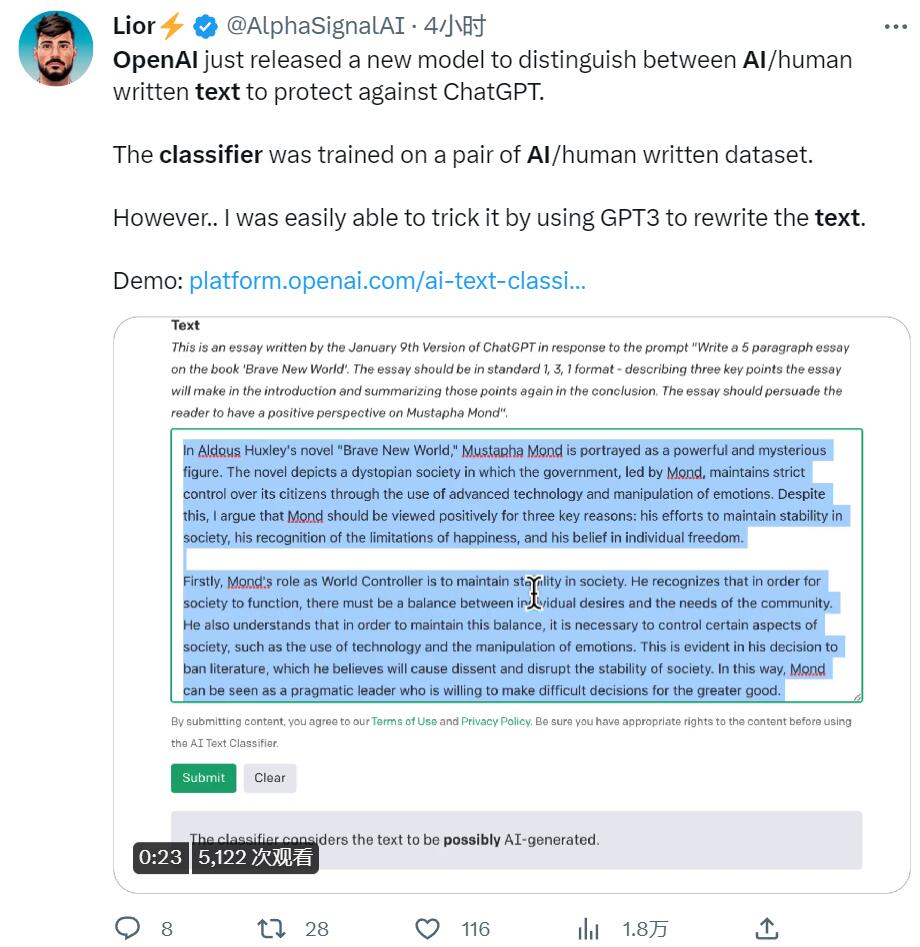
最后,有人用上了反復(fù)翻譯大法,把文本讓 GPT3 重寫一遍,也能騙過識別器。
總結(jié)一下的話就是正向識別不準(zhǔn),反向識別出錯,也無法識破一些改論文的技巧。看來,起碼在 AI 文本內(nèi)容識別這一領(lǐng)域,OpenAI 還需努力。
最近,有媒體爆料百度計劃在今年3月推出 ChatGPT 風(fēng)格的應(yīng)用程序,最初將其嵌入到其主要搜索服務(wù)中。該工具的名稱尚未確定,就像 ChatGPT 一樣允許用戶獲得對話式搜索結(jié)果。百度對此未予置評。不過,有網(wǎng)友建議,還是先做一個AI內(nèi)容真假鑒別工具吧!
審核編輯 :李倩
-
AI
+關(guān)注
關(guān)注
88文章
35065瀏覽量
279340 -
模型
+關(guān)注
關(guān)注
1文章
3517瀏覽量
50383 -
OpenAI
+關(guān)注
關(guān)注
9文章
1207瀏覽量
8891
原文標(biāo)題:ChatGPT “克星”來了!OpenAI 推出AI真假鑒別工具,成功率僅有26%
文章出處:【微信號:jbchip,微信公眾號:電子元器件超市】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
晶豐明源推出Smart DrMOS智能集成功率器件芯片

OpenAI將發(fā)布更智能GPT模型及AI智能體工具
OpenAI進軍傳媒,蘋果暫停AI新聞功能
OpenAI或?qū)?b class='flag-5'>推出o3 mini推理AI模型
OpenAI即將推出o3 mini推理AI模型
OpenAI推出AI視頻生成模型Sora
AI看點:OpenAI 世界最貴大模型 阿里將推出人工智能電商工具

OpenAI未來3周舉行12場新品發(fā)布會 我們能期待些什么? #OpenAI #人工智能 #AI
單片集成功率放大器件的工作原理是什么
單片集成功率放大器件的功率通常在多少
了解具有集成功率MOSFET的直流/直流轉(zhuǎn)換器熱阻規(guī)格

如何提高eCall碰撞測試成功率
OpenAI將推出在線搜索工具“SearchGPT”
AFE10004高度集成功率放大器數(shù)據(jù)表





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論