 阿里達摩院提出ABPN:高清人像美膚模型
阿里達摩院提出ABPN:高清人像美膚模型
一、論文&代碼
論文:
https://openaccess.thecvf.com/content/CVPR2022/papers/Lei_ABPN_Adaptive_Blend_Pyramid_Network_for_Real-Time_Local_Retouching_of_CVPR_2022_paper.pdf
模型&代碼:
https://www.modelscope.cn/models/damo/cv_unet_skin-retouching/summary
二、背景
隨著數字文化產業的蓬勃發展,人工智能技術開始廣泛應用于圖像編輯和美化領域。其中,人像美膚無疑是應用最廣、需求最大的技術之一。傳統美顏算法利用基于濾波的圖像編輯技術,實現了自動化的磨皮去瑕疵效果,在社交、直播等場景取得了廣泛的應用。然而,在門檻較高的專業攝影行業,由于對圖像分辨率以及質量標準的較高要求,人工修圖師還是作為人像美膚修圖的主要生產力,完成包括勻膚、去瑕疵、美白等一系列工作。通常,一位專業修圖師對一張高清人像進行美膚操作的平均處理時間為1-2分鐘,在精度要求更高的廣告、影視等領域,該處理時間則更長。
相較于互娛場景的磨皮美顏,廣告級、影樓級的精細化美膚給算法帶來了更高的要求與挑戰。一方面,瑕疵種類眾多,包含痘痘、痘印、雀斑、膚色不均等,算法需要對不同瑕疵進行自適應地處理;另一方面,在去除瑕疵的過程中,需要盡可能的保留皮膚的紋理、質感,實現高精度的皮膚修飾;最后也是十分重要的一點,隨著攝影設備的不斷迭代,專業攝影領域目前常用的圖像分辨率已經達到了4K甚至8K,這對算法的處理效率提出了極其嚴苛的要求。為此,我們以實現專業級的智能美膚為出發點,研發了一套高清圖像的超精細局部修圖算法ABPN,在超清圖像中的美膚與服飾去皺任務中都實現了很好的效果與應用。
三、相關工作
3.1 傳統美顏算法
傳統美顏算法的核心就是讓皮膚區域的像素變得更平滑,降低瑕疵的顯著程度,從而使皮膚看起來更加光滑。一般來說,現有的美顏算法可劃分為三步:1)圖像濾波算法,2)圖像融合,3)銳化。整體流程如下:
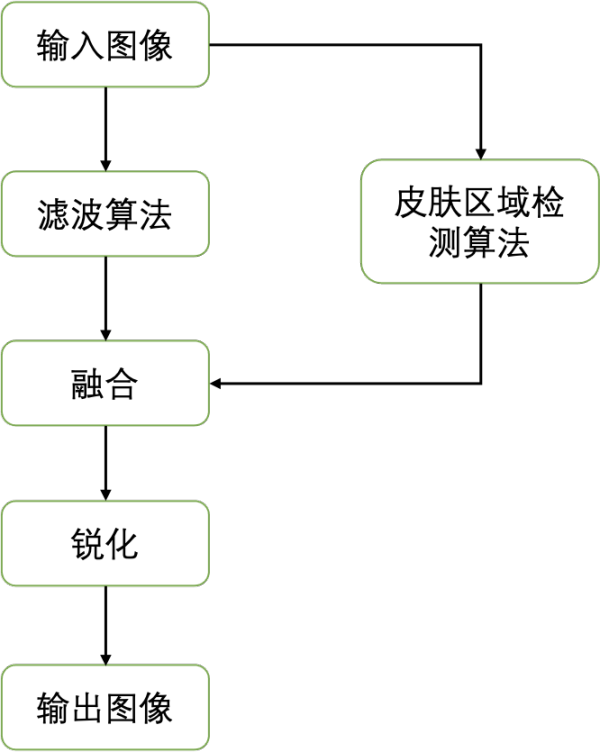
其中為了實現皮膚區域的平滑,同時保留圖像中的邊緣,傳統美顏算法首先使用保邊濾波器(如雙邊濾波、導向濾波等)來對圖像進行處理。不同于常用的均值濾波、高斯濾波,保邊濾波器考慮了不同區域像素值的變化,對像素變化較大的邊緣部分以及變化較為平緩的中間區域像素采取不同的加權,從而實現對于圖像邊緣的保留。而后,為了不影響背景區域,分割檢測算法通常被用于定位皮膚區域,引導原圖與平滑后的圖像進行融合。最后,銳化操作可以進一步提升邊緣的顯著性以及感官上的清晰度。下圖展示了目前傳統美顏算法的效果:

原圖像來自unsplash[31]
從效果來看,傳統美顏算法存在兩大問題:1)對于瑕疵的處理是非自適應的,無法較好的處理不同類型的瑕疵。2)平滑處理造成了皮膚紋理、質感的丟失。這些問題在高清圖像中尤為明顯。
3.2 現有深度學習算法
為了實現皮膚不同區域、不同瑕疵的自適應修飾,基于數據驅動的深度學習算法似乎是更好的解決方案。考慮任務的相關性,我們對Image-to-Image Translation、Photo Retouching、Image Inpainting、High-resolution Image Editing這四類現有方法對于美膚任務的適用性進行了討論和對比。
3.2.1 Image-to-Image Translation
圖像翻譯(Image-to-Image Translation)任務最開始由pix2pix[1]所定義,其將大量計算機視覺任務總結為像素到像素的預測任務,并且提出了一個基于條件生成對抗網絡的通用框架來解決這類問題。基于pix2pix[1],各類方法被陸續提出以解決圖像翻譯問題,其中包括利用成對數據(paired images)的方法[2,3,4,5]以及利用非成對數據(unpaired images)的方法[6,7,8,9]。一些工作聚焦于某些特定的圖像翻譯任務(比如語義圖像合成[2,3,5],風格遷移等[9,10,11,12]),取得了令人印象深刻效果。然而,上述大部分的圖像翻譯主要關注于圖像到圖像的整體變換,缺乏對于局部區域的注意力,這限制了其在美膚任務中的表現。
3.2.2 Photo Retouching
受益于深度卷積神經網絡的發展,基于學習的方法[13,14,15,16]近年來在修圖領域展現了出色的效果。然而,與大多數圖像翻譯方法相似的是,現有的retouching算法主要聚焦于操控圖像的一些整體屬性,比如色彩、光照、曝光等。很少關注局部區域的修飾,而美膚恰恰是一個局部修飾任務(Local Photo Retouching),需要在修飾目標區域的同時,保持背景區域不動。
3.2.3 Image Inpainting
圖像補全(image inpainting)算法常用于對圖像缺失的部分進行補全生成,與美膚任務有著較大的相似性。憑借著強大的特征學習能力,基于深度生成網絡的方法[17,18,19,20]這些年在inpainting任務中取得了巨大的進步。然而,inpainting方法依賴于目標區域的mask作為輸入,而在美膚以及其他局部修飾任務中,獲取精確的目標區域mask本身就是一個非常具有挑戰性的任務。因而,大部分的image inpainting任務無法直接用于美膚。近年來,一些blind image inpainting的方法[21,22,23]擺脫了對于mask的依賴,實現了目標區域的自動檢測與補全。盡管如此,同大多數其他image inpainting方法一樣,這些方法存在兩個問題:a)缺乏對于目標區域紋理及語義信息的充分利用,b)計算量較大,難以應用于超高分辨率圖像。
3.2.4 High-resolution Image Editing
為了實現高分辨率圖像的編輯,[15,24,25,26]等方法通過將主要的計算量從高分辨率圖轉移到低分辨率圖像中,以減輕空間和時間的負擔。盡管在效率上取得了出色的表現,由于缺乏對于局部區域的關注,其中大部分方法都不適用于美膚這類局部修飾任務。
綜上,現有的深度學習方法大都難以直接應用于美膚任務中,主要原因在于缺乏對局部區域的關注或者是計算量較大難以應用于高分辨率圖像。
四、基于自適應混合金字塔的局部修圖框架
美膚本質在于對圖像的編輯,不同于大多數其他圖像轉換任務的是,這種編輯是局部的。與其相似的還有服飾去皺,商品修飾等任務。這類局部修圖任務具有很強的共通性,我們總結其三點主要的困難與挑戰:1)目標區域的精準定位。2)具有全局一致性以及細節保真度的局部生成(修飾)。3)超高分辨率圖像處理。為此,我們提出了一個基于自適應混合金字塔的局部修圖框架(ABPN: Adaptive Blend Pyramid Network for Real-Time Local Retouching of Ultra High-Resolution Photo, CVPR2022,[27]),以實現超高分辨率圖像的精細化局部修圖,下面我們對其實現細節進行介紹。
4.1 網絡整體結構
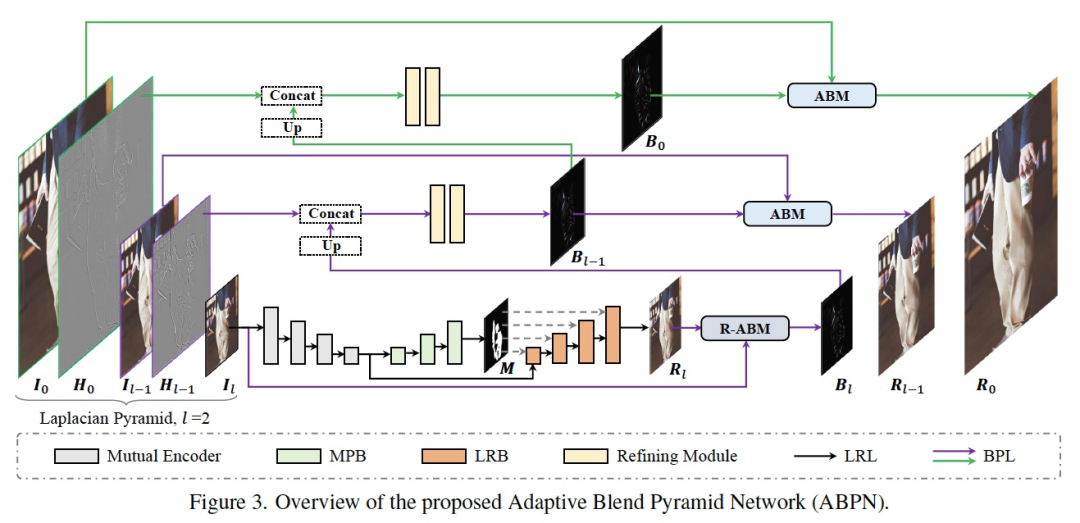
如上圖所示,網絡結構主要由兩個部分組成:上下文感知的局部修飾層(LRL)和自適應混合金字塔層(BPL)。其中LRL的目的是對降采樣后的低分辨率圖像進行局部修飾,生成低分辨率的修飾結果圖,充分考慮全局的上下文信息以及局部的紋理信息。進一步,BPL用于將LRL中生成的低分辨率結果逐步向上拓展到高分辨率結果。其中,我們設計了一個自適應混合模塊(ABM)及其逆向模塊(R-ABM),利用中間混合圖層Bi,可實現原圖與結果圖之間的自適應轉換以及向上拓展,展現了強大的可拓展性和細節保真能力。我們在臉部修飾及服飾修飾兩個數據集中進行了大量實驗,結果表明我們的方法在效果和效率上都大幅度地領先了現有方法。值得一提的是,我們的模型在單卡P100上實現了4K超高分辨率圖像的實時推理。下面,我們對LRL、BPL及網絡的訓練loss分別進行介紹。
4.2 上下文感知的局部修飾層(Context-aware Local Retouching Layer)
在LRL中,我們想要解決三中提到的兩個挑戰:目標區域的精準定位以及具有全局一致性的局部生成。如Figure 3所示,LRL由一個共享編碼器、掩碼預測分支(MPB)以及局部修飾分支(LRB)構成。
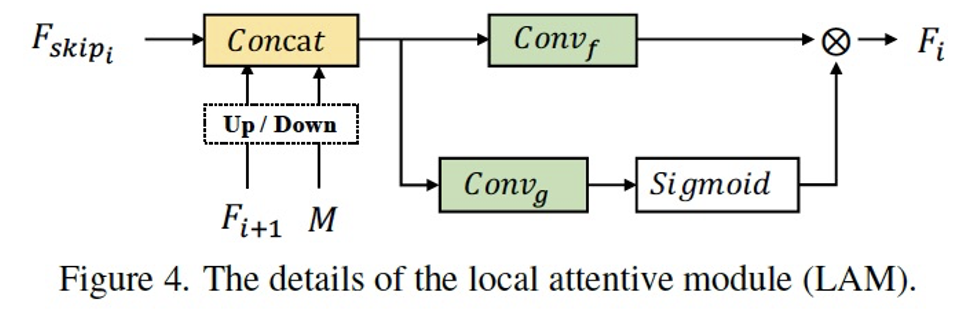

總得來說,我們使用了一個多任務的結構,以實現顯式的目標區域預測,與局部修飾的引導。其中,共享編碼器的結構可以利用兩個分支的共同訓練優化特征,提高修飾分支對于目標全局的語義信息和局部的感知。大多數的圖像翻譯方法使用傳統的encoder-decoder結構直接實現局部的編輯,沒有將目標定位與生成進行解耦,從而限制了生成的效果(網絡的容量有限),相比之下多分支的結構更利于任務的解耦以及互利。在局部修飾分支LRB中我們設計了LAM(Figure 4),將空間注意力機制與特征注意力機制同時作用,以實現特征的充分融合以及目標區域的語義、紋理的捕捉。消融實驗(Figure 6)展現了各個模塊設計的有效性。
4.3 自適應混合金字塔層(Adaptive Blend Pyramid Layer)
LRL在低分辨率上實現了局部修飾,如何將修飾的結果拓展到高分辨率同時增強其細節保真度?這是我們在這部分想要解決的問題。
4.3.1 自適應混合模塊(Adaptive Blend Module)
在圖像編輯領域,混合圖層(blend layer)常被用于與圖像(base layer)以不同的模式混合以實現各種各樣的圖像編輯任務,比如對比度的增強,加深、減淡操作等。通常地,給定一張圖片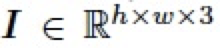 ,以及一個混合圖層
,以及一個混合圖層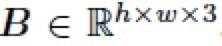 ,我們可以將兩個圖層進行混合得到圖像編輯結果
,我們可以將兩個圖層進行混合得到圖像編輯結果
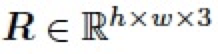
,如下:

其中 f 是一個固定的逐像素映射函數,通常由混合模式所決定。受限于轉化能力,一個特定的混合模式及固定的函數 f 難以直接應用于種類多樣的編輯任務中去。為了更好的適應數據的分布以及不同任務的轉換模式,我們借鑒了圖像編輯中常用的柔光模式,設計了一個自適應混合模塊 (ABM),如下:
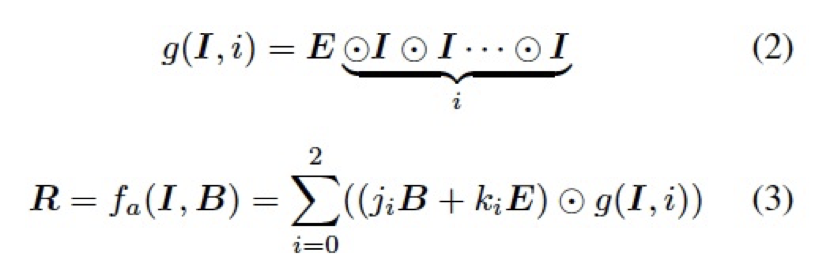
其中 表示 Hadmard product,
表示 Hadmard product,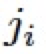 和
和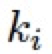 為可學習的參數,被網絡中所有的 ABM 模塊以及接下來的 R-ABM 模塊所共享,
為可學習的參數,被網絡中所有的 ABM 模塊以及接下來的 R-ABM 模塊所共享,
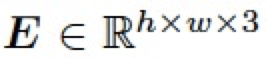
表示所有值為 1 的常數矩陣。 4.3.2 逆向自適應混合模塊(Reverse Adaptive Blend Module) 實際上,ABM 模塊是基于混合圖層 B 已經獲得的前提假設。然而,我們在 LRL 中只獲得了低分辨率的結果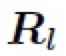 ,為了得到混合圖層 B,我們對公式 3 進行求解,構建了一個逆向自適應混合模塊 (R-ABM),如下: ?
,為了得到混合圖層 B,我們對公式 3 進行求解,構建了一個逆向自適應混合模塊 (R-ABM),如下: ?
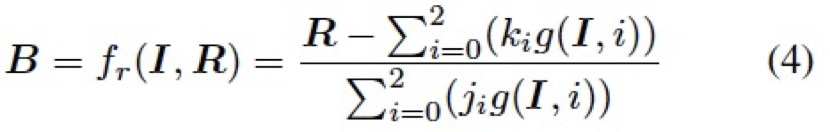
總的來說,通過利用混合圖層作為中間媒介,ABM 模塊和 R-ABM 模塊實現了圖像 I 和結果 R 之間的自適應轉換,相比于直接對低分辨率結果利用卷積上采樣等操作進行向上拓展(如 Pix2PixHD),我們利用混合圖層來實現這個目標,有其兩方面的優勢:1)在局部修飾任務中,混合圖層主要記錄了兩張圖像之間的局部轉換信息,這意味著其包含更少的無關信息,且更容易由一個輕量的網絡進行優化。2)混合圖層直接作用于原始圖像來實現最后的修飾,可以充分利用圖像本身的信息,進而實現高度的細節保真。
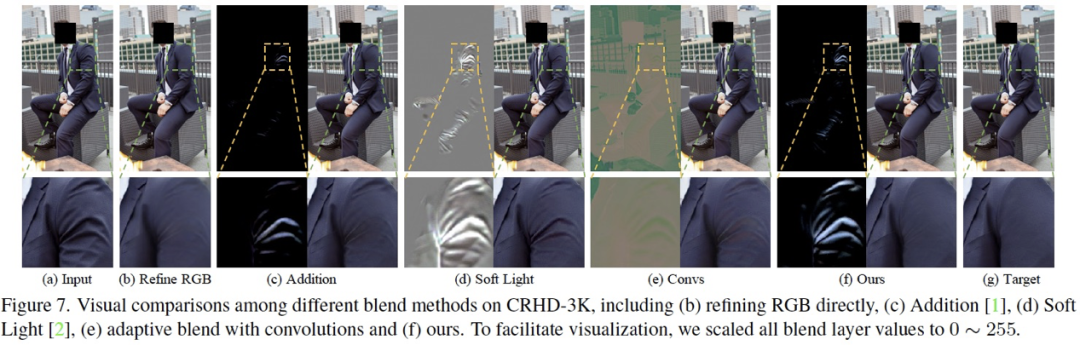
實際上,關于自適應混合模塊有許多可供選擇的函數或者策略,我們在論文中對設計的動機以及其他方案的對比進行了詳細介紹,這里不進行更多的闡述了,Figure 7 展示了我們的方法和其他混合方法的消融對比。 4.3.3 Refining Module

4.4 損失函數

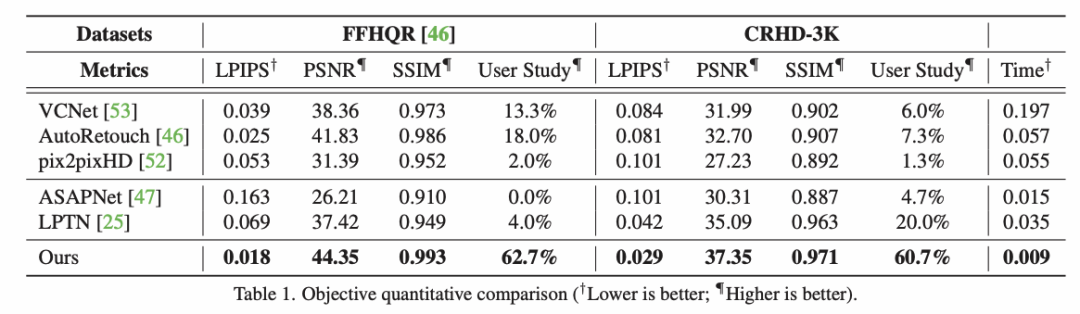
實驗結果5.1 與 SOTA 方法對比
5.2 消融實驗

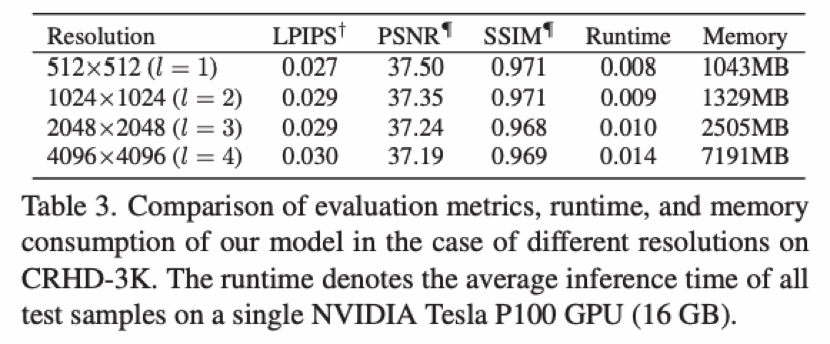
5.3 運行速度與內存消耗
效果展示 美膚效果展示:
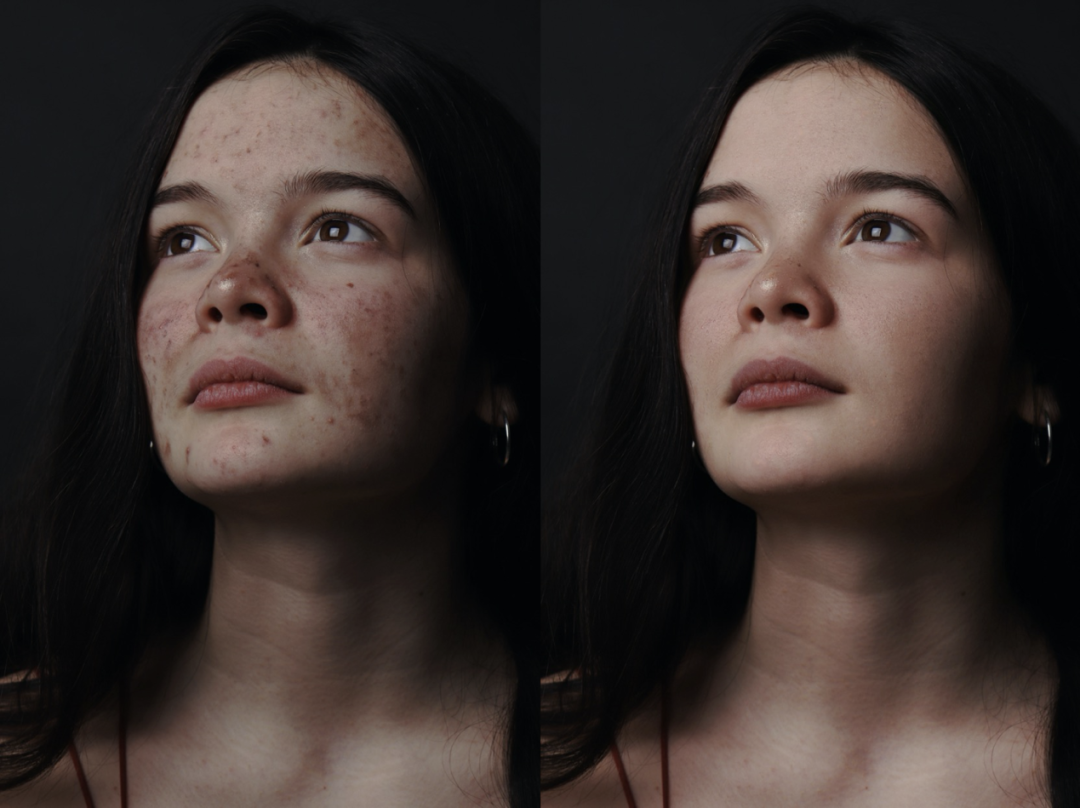
原圖像來自 unsplash [31]

原圖像來自人臉數據集 FFHQ [32]

原圖像來自人臉數據集 FFHQ [32] 可以看到,相較于傳統的美顏算法,我們提出的局部修圖框架在去除皮膚瑕疵的同時,充分的保留了皮膚的紋理和質感,實現了精細、智能化的膚質優化。進一步,我們將該方法拓展到服飾去皺領域,也實現了不錯的效果,如下:


審核編輯 :李倩
-
濾波器
+關注
關注
162文章
8076瀏覽量
181041 -
算法
+關注
關注
23文章
4699瀏覽量
94747 -
圖像
+關注
關注
2文章
1092瀏覽量
41029
原文標題:CVPR 2022 | 阿里達摩院提出ABPN:高清人像美膚模型
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
新一代視頻編解碼標準H.266走向主流 頭部視頻平臺滲透率超70%

普華基礎軟件蒞臨阿里巴巴達摩院調研交流
阿里國際站AI升級,接入DeepSeek等先進模型
阿里云通義Qwen2.5-Max模型全新升級
雷鳥創新與阿里云達成戰略合作,引領 AI大模型與AR眼鏡融合新紀元






 工商網監
工商網監
評論