") 利用Block Design加速設(shè)計
利用Block Design加速設(shè)計
一 Block Design設(shè)計方法
早期的FPGA,資源是比較有限的,設(shè)計規(guī)模相對也比較小,之前的設(shè)計流程中工程師常用的設(shè)計以HDL+Xilinx IP為結(jié)構(gòu),設(shè)計中也會顧慮到FPGA資源的節(jié)省。
隨著FPGA的資源越來越大,設(shè)計的快速構(gòu)建、易修改、隨著版本可迭代的要求越來越高。好比在早期單片機時代,C語言是主流的工具;而處理器越來越強,腳本類語言能更快構(gòu)建最終應(yīng)用。
Xilinx越來越多的例程,給出的參考設(shè)計是基于Block Design設(shè)計方法的,block design設(shè)計方法具備如下優(yōu)勢:
A. 框圖形式,直觀易懂
Block Design基于框圖的形式,搭積木+連線的方式; B. 節(jié)省大量的Coding時間
互聯(lián)總線連線,可以鼠標(biāo)單一連線。Block Design的一個IP往往可以獨立運行,比代碼的方式只是一個wrapper包含的內(nèi)容更多;
C. 可以隨著Vivado升級,快速更新IP,保持設(shè)計更新
傳統(tǒng)HDL+IP的方式,IP升級后還需要檢查對應(yīng)HDL的適配。Block Design一般來說,IP作為一個模塊升級,基本上Block Design直接升級,內(nèi)部不用再干預(yù); D. 包括大量的通用IP,可以靈活構(gòu)建設(shè)計
尤其是基于AMBA的IP,可以幫助用戶快速靈活構(gòu)建設(shè)計;
二 Block Design設(shè)計實例
如何理解Block Design設(shè)計方法、工具如何使用等問題Xilinx有詳細(xì)的文檔手冊來介紹,本文中不做介紹,本文簡單以一個實際的案例,介紹使用Block Design加速設(shè)計。
本文描述的這個設(shè)計,需要4路光纖,運行Aurora協(xié)議,各路Aurora線速率不同。最終Aurora協(xié)議的數(shù)據(jù)部分,還需要通過PCIe上傳到上位機。反過程是上位機的數(shù)據(jù),通過PCIe最終分發(fā)到4路Aurora光纖,向外傳輸。
本文描述的這個設(shè)計中的兩個要點:
1. 利用DDR做大容量緩存
有很多應(yīng)用需要用DDR做緩存,例如常見的PCIe+Aurora收發(fā),或者ADC/DAC,圖像采集卡等,兩邊速率不匹配并且累計需要的容量超過FPGA內(nèi)部FIFO的時候,需要外部的DDR做緩沖。
早期Xilinx DDR IP的用戶接口,只提供了類似于FIFO那樣的接口,并且只有一個用戶接口。
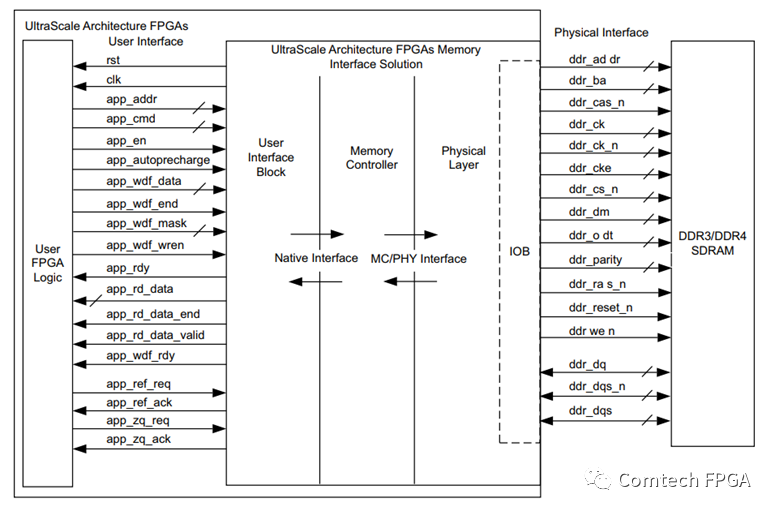
在傳統(tǒng)的RTL設(shè)計方法中,需要將DDR作為緩存,需要自己做如下設(shè)計:
A. 多數(shù)據(jù)輸入輸出的接口,將app_接口擴展多個獨立的接口,供不同的端口使用
B. 總線仲裁,多個獨立接口仲裁,按照round-robin,或者搶占式的方式提供仲裁
C. 地址管理,不同的端口深度要求不同的情況下,對應(yīng)管理不同的地址空間。
實現(xiàn)這些功能,大概需要寫這么多代碼,對一個工程師來說,這些代碼可能需要2-4周的代碼和仿真時間:
如果使用Block Design實現(xiàn),1個小時差不多就可以實現(xiàn)上面的這些內(nèi)容,在Block Design中:
A. 最右側(cè)的DDR IP 直接出AXI接口;
B. 使用AXI Smart Connect實現(xiàn)多端口擴展,自帶仲裁功能;
C. 使用DATAMOVER完成外圍FIFO數(shù)據(jù)到DDR的數(shù)據(jù)讀寫;
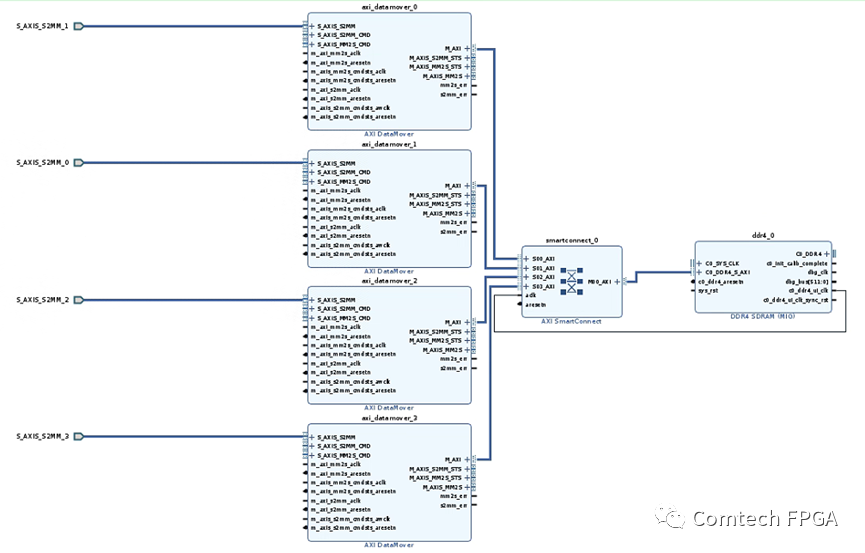
搭建這個Block只需要10分鐘,到這一步為止,剩下的工作只需要控制DATAMOVER的命令接口即可。
2. 使用XDMA直接和DDR交互
過去Xilinx 平臺設(shè)計DMA,從最早的XAPP1052,到后來一些付費的PLDA和NWlogicIP,設(shè)計復(fù)雜度不用說,哪怕購買了IP也需要一些時間融入到自己的產(chǎn)品中。
Xilinx有一個XDMA IP,這個IP的介紹和使用參考PG195。這里使用Block Design,添加XDMA。
XDMA對外有2個接口:
A. 一個是AXI_LITE接口,這里接AXI_BRAM IP,對外是一個bram接口,用作寄存器接口,控制PCIe卡內(nèi)部的寄存器;
B. 一個是AXI Memory Full接口,可以直接對接DDR空間,訪問所有的DDR部分;
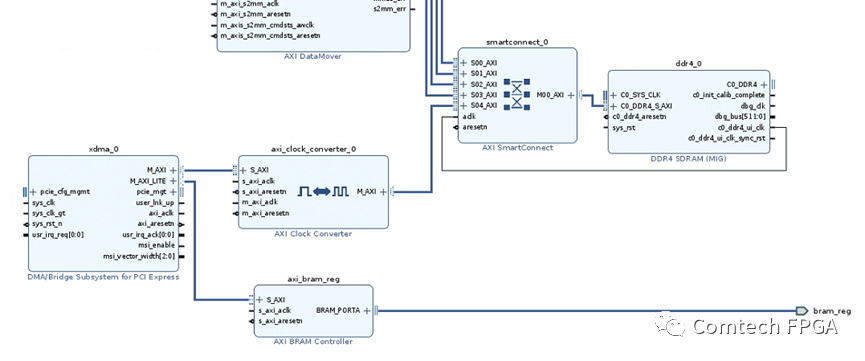
通過地址空間來看,DDR被PCIe XDMA和4路DATAMOVER共享,DATAMOVER外部接收的數(shù)據(jù)緩存在DDR空間,上位機可以直接讀走這片緩存的數(shù)據(jù),從而實現(xiàn)外部數(shù)據(jù)到上位機的過程。
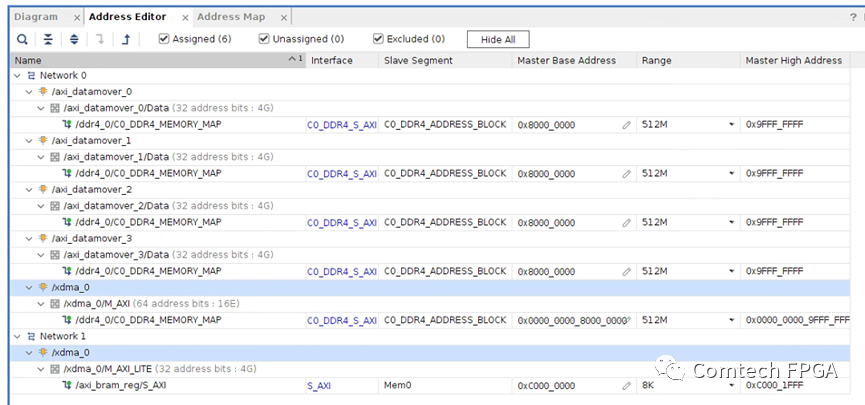
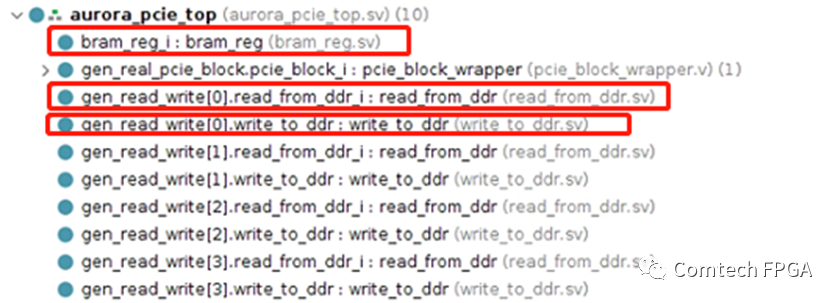
一個實際的PCIe Aurora光纖收發(fā)的工程,在Block Design中搭建這些框圖,外圍的代碼非常簡單。下面是一個實際的工程,4光口的Aurora收發(fā)卡,使用DDR緩存,并且使用PCIe和上位機交互。
Block Design中包含了PCIe部分,以及上面的DDR緩沖的部分,外部只需要1個DATAMOVER寫控制、1個DATAMOVER讀控制、1個寄存器接口,即完成整個設(shè)計。
三 結(jié)語
使用Block Design設(shè)計方法,主體部分都可以快速拖拽和連線完成,使得外圍所需要的的代碼大大簡化,只需要區(qū)區(qū)3個模塊代碼,完成從數(shù)據(jù)流到DDR的緩沖以及通過XDMA讀取DDR的過程,從而完成外圍接口和上位機的通訊。
這個設(shè)計可以適配很多種Stream形式的設(shè)計:
A. Aurora光纖收發(fā)卡;
B. Camera Link圖像采集卡;
C. AD/DA數(shù)據(jù)采集回放卡;
審核編輯 :李倩
-
FPGA
+關(guān)注
關(guān)注
1643文章
21954瀏覽量
613945 -
代碼
+關(guān)注
關(guān)注
30文章
4886瀏覽量
70240 -
Block
+關(guān)注
關(guān)注
0文章
26瀏覽量
14889
原文標(biāo)題:利用Block Design加速設(shè)計
文章出處:【微信號:Comtech FPGA,微信公眾號:Comtech FPGA】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
新思科技利用人工智能加速芯片設(shè)計流程
S32Design Studio出錯的原因?
安裝S32_Design_Studio_for_S32_Platform_3.6.0時出錯怎么解決?
利用NVIDIA DPF引領(lǐng)DPU加速云計算的未來
Vivado Design Suite用戶指南:邏輯仿真

ADS1191的RLD block是怎樣組合電極生成病人驅(qū)動信號的?
Design House與Fab的關(guān)系

U50的AMD Vivado Design Tool flow設(shè)置
GPU加速計算平臺是什么
FPGA加速深度學(xué)習(xí)模型的案例
請問TLV320AIC3204中Processing Block是做什么用的啊?
AMD Vivado Design Suite 2024.1全新推出
利用NVIDIA RAPIDS加速DolphinDB Shark平臺提升計算性能
利用邊沿速率加速器和自動感應(yīng)電平轉(zhuǎn)換器





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論