 CXL對數據中心的意義
CXL對數據中心的意義

CXL(Compute Express Link)將成為一種變革性技術,將重新定義數據中心的架構和構建方式。這是因為 CXL 為跨芯片的緩存一致性、內存擴展和內存池提供了標準化協議。在本文中,我們將重點介紹微軟正在做的事情,以幫助大家了解CXL對數據中心的意義。
數據中心是一件非常昂貴的事情。微軟表示,他們高達50% 的服務器成本僅來自 DRAM。所需的資本支出是巨大的,但您構建的服務器并不是同質的。工作負載不是靜態的。它們在不斷地成長和進化。計算資源、DRAM、NAND 和網絡類型的組合將根據工作負載而變化。
一刀切的模式是行不通的,這就是為什么您會看到云提供商擁有數十種甚至數百種不同的實例類型。這些正在嘗試針對不同的工作負載優化硬件產品。即便如此,許多用戶最終還是為他們真正不需要的東西付費。
實例選擇并不完美,這些實例與硬件的匹配也不完美。隨之而來的是平臺級內存擱淺問題。服務器配置為不合適的實例類型場景。
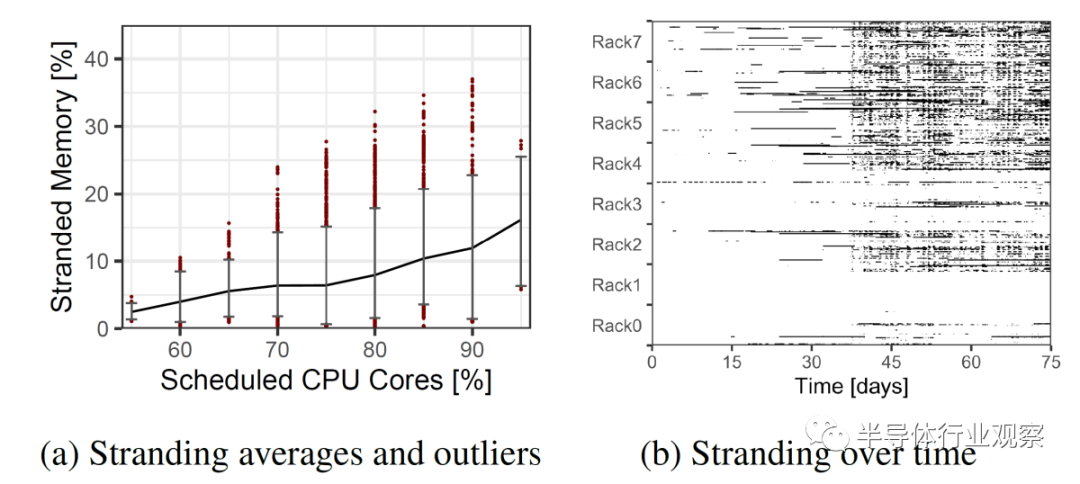
這個問題的解決方案是內存池。多個服務器可以共享一部分內存,并且可以動態地將其分配給不同的服務器。與其過度地配置服務器,不如將它們配置為更接近平均 DRAM 與內核的比率,并且可以通過內存池來解決客戶的過多 DRAM 需求。此內存池將通過 CXL 協議進行通信。未來,隨著對 CXL 協議的修訂,服務器甚至可以共享相同的內存來處理相同的工作負載,這將進一步減少 DRAM 需求。
擁有大規模應用程序的復雜運營商可以通過向其開發人員提供具有不同帶寬和延遲的多層內存來解決這個問題。這對于亞馬遜、谷歌、微軟和其他公司運營的公共云環境來說是站不住腳的。
Microsoft 概述了與公共云環境中的內存池有關的 3 個主要功能挑戰。無法修改客戶工作負載,包括guest操作系統。內存池系統還必須與虛擬化加速技術兼容,例如直接將 I/O 設備分配給 VM 和 SR-IOV。池化還必須可用于商用硬件。
在過去他們也試過內存池,但它需要自定義硬件設計、更改 VM guest并依賴頁面錯誤。這種組合使其無法部署在云中。這就是 CXL 的用武之地。英特爾、AMD 和多個 Arm 合作伙伴已經加入了該標準。帶有 CXL 的 CPU 將于今年晚些時候開始問世。此外,三星、美光和 SKHynix 三大 DRAM 制造商也都承諾支持該標準。
即使有硬件供應商的廣泛支持,仍有很多問題需要回答。在硬件方面:應該如何構建內存池以及如何平衡池大小與較大池的較高延遲?在軟件方面:如何管理這些池并將池暴露給guest操作系統,云工作負載可以容忍多少額外的內存延遲?
在分布層:提供者應如何在具有 CXL 內存的機器上調度 VM,內存中的哪些項目應存儲在池中與直接連接的內存中,它們能否預測內存行為和延遲敏感性有助于產生更好的性能,如果是,準確度如何這些是預測嗎?
微軟提出了這些問題,并試圖回答這些問題。我們將在這里概述他們的發現。他們的第一代的解決方案架構取得了令人印象深刻的成果。
隨著未來 CXL 版本的推出和延遲降低,這些收益可能會進一步擴大。
首先是硬件層。Microsoft 使用直接連接到 8 到 32 個插槽 CPU 的多端口外部存儲器對此進行了測試。內存擴展是通過連接 CXL 的外部內存控制器 (EMC) 完成的,該控制器具有四個 80 位 ECC DDR5 池 DRAM 通道和多個 CXL 鏈路,以允許多個 CPU 插槽訪問內存。此 EMC 管理請求并跟蹤分配給各個主機的各個內存區域的所有權。
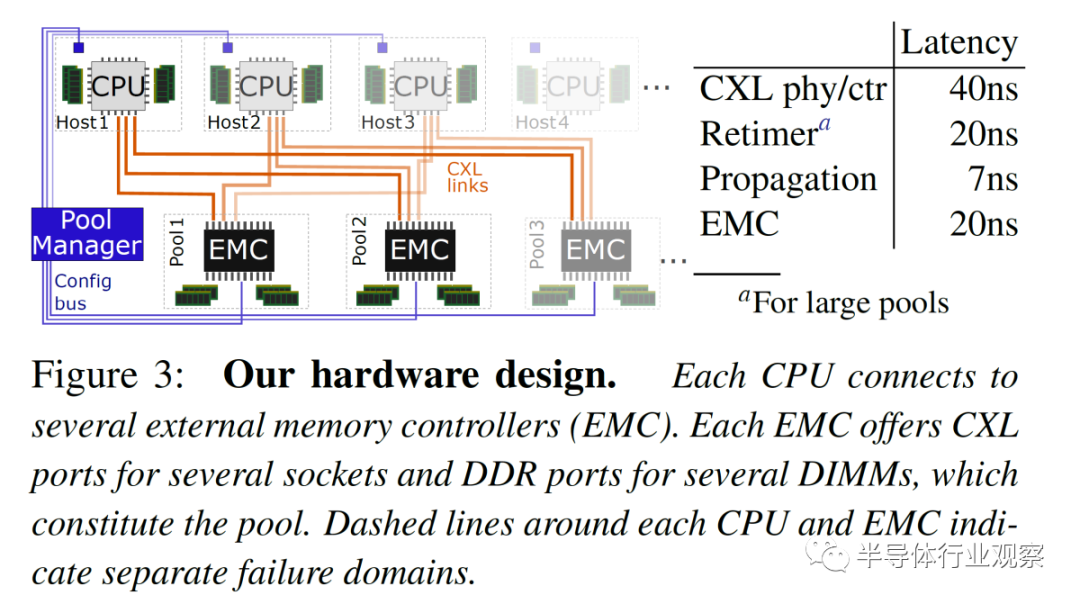
CXL x8 通道的帶寬約為 DDR5 內存通道的帶寬。每個 CPU 都有自己更快的本地內存,但它也可以訪問具有更高延遲的 CXL 池化內存,相當于單個 NUMA 躍點。跨 CXL 控制器和 PHY、可選重定時器、傳播延遲和外部存儲器控制器的延遲增加了 67ns 到 87ns。
下圖顯示了當前本地 DRAM 的固定百分比(10%、30% 和 50%)切換到池化資源。池化內存與本地內存的百分比越大,節省的 DRAM 就越多。就 DRAM 節省而言,增加Socket數量會很快消失。
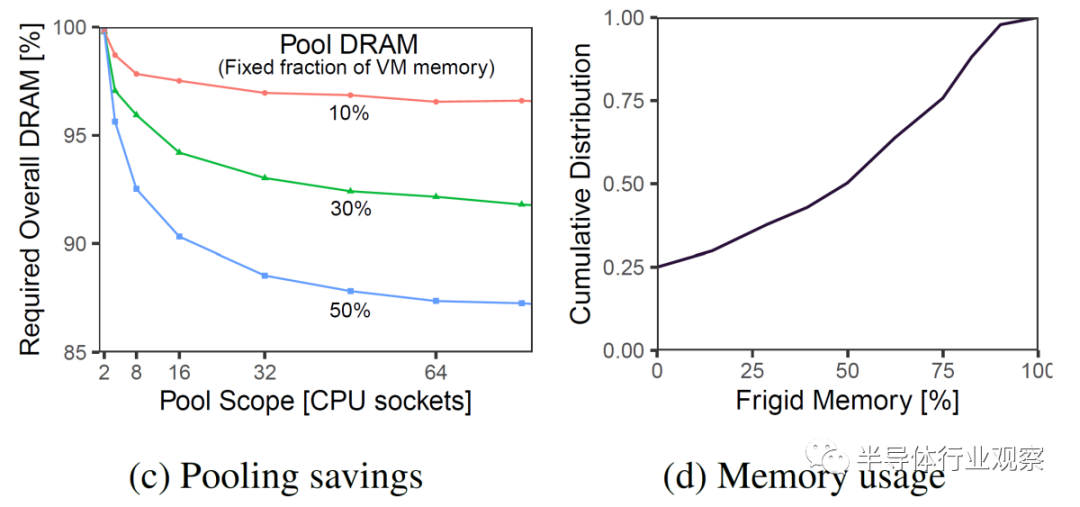
雖然更大的池大小和更多的socket看起來是最好的選擇,但這里有更多的性能和延遲影響。如果池大小降為 4 到 8 個 CPU 插槽,則不需要重定時器。這將延遲從 87ns 降低到 67ns。此外,在這些較小的插槽數中,EMC 可以直接連接到所有 CPU 插槽。
更大的 32 個插槽池將 EMC 連接到不同的 CPU 子集。這將允許在更多數量的 CPU 插槽之間共享,同時保持 CPU 端口的 EMC 設備數量固定。這里需要重定時器,這導致每個方向的延遲為 10ns。
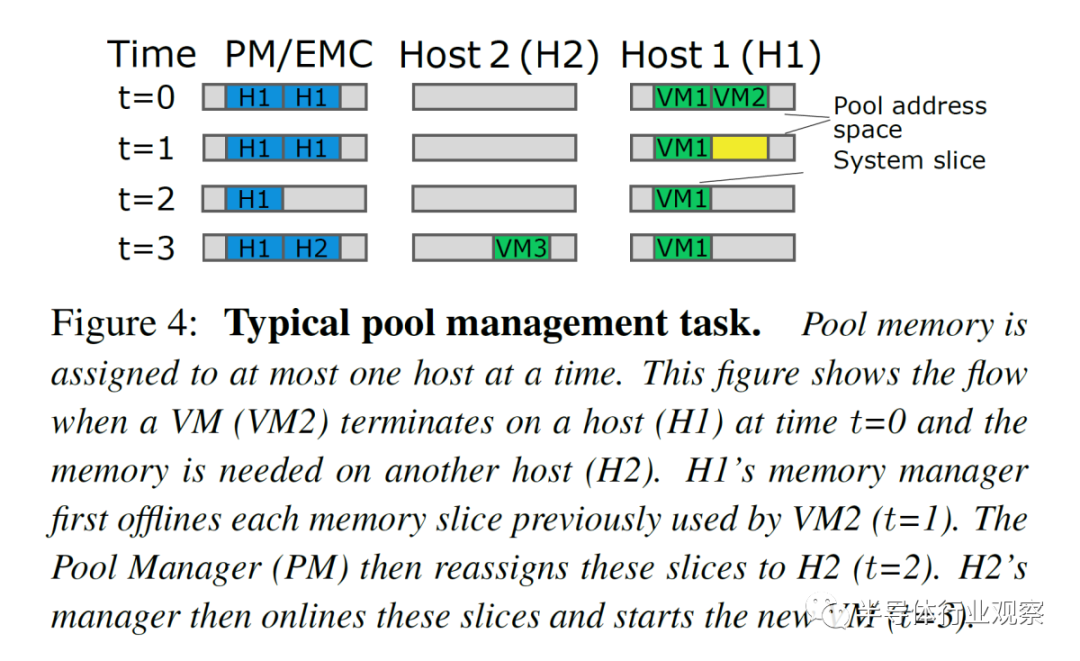
在軟件方面,解決方案相當巧妙。
Microsoft 經常部署多插槽系統。在大多數情況下,VM 足夠小,它們完全適合單個 NUMA 節點、內核和內存。Azure 的管理程序嘗試將所有核心和內存放在單個 NUMA 節點上,但在極少數情況下(2% 的時間),VM 有一部分資源跨越socket。這不會暴露給用戶。
內存池在功能上的工作方式相同。內存設備將作為零核虛擬 zNUMA 節點公開,沒有內核,只有內存。內存偏離這個 zNUMA 內存節點,但允許溢出。粒度(granularity)是每片內存 1GB 。
分布式系統軟件層依賴于對 VM 的內存延遲敏感度的預測。未觸及的存儲被稱為“frigid memory”。Azure 估計第 50 個百分位的 VM 具有 50% 的冷(frigid)內存。這個數字似乎很圓。預計對內存延遲不敏感的 VM 完全支持池 DRAM。為內存敏感的 VM 配置了一個 zNUMA 節點,僅用于它們的冷內存。預測是在虛擬機部署時完成的,但它是異步管理的,并在檢測到預測不正確時更改虛擬機放置。
這些算法的準確性對于節省基礎設施成本至關重要。如果操作不當,性能影響可能會很大。
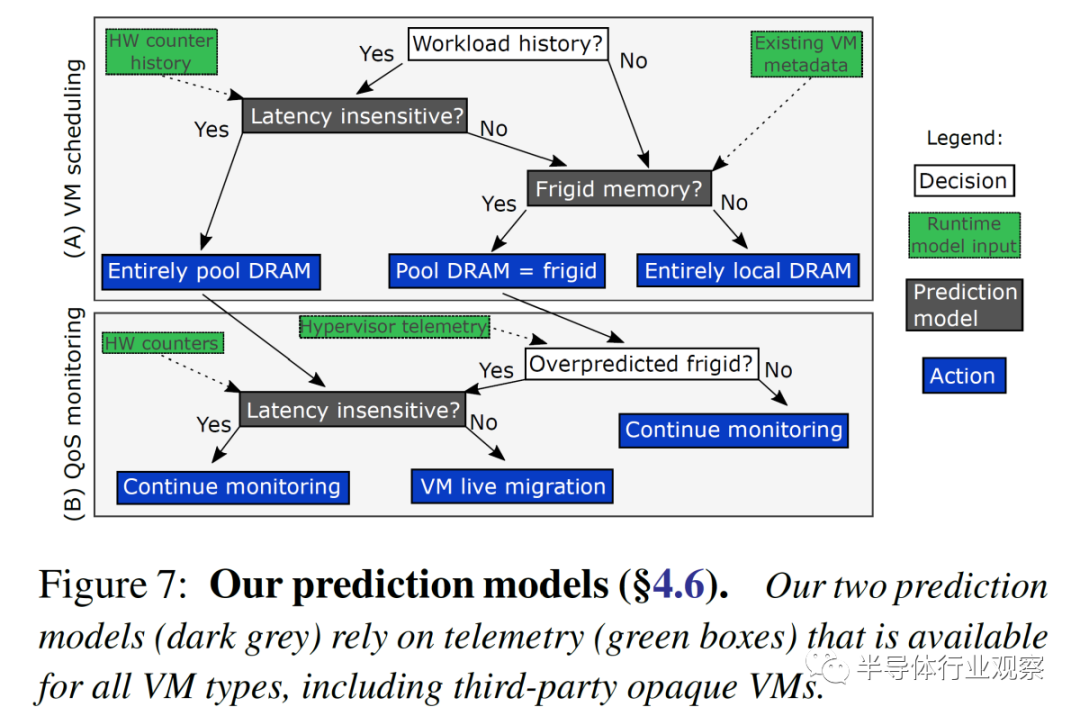
考慮到潛在的性能影響可能是巨大的,將云居民(cloud resident)的內存移動到 67ns 到 87ns 的池中是非常糟糕的。
因此,Microsoft 在兩種情況下對 158 個工作負載進行了基準測試。一種是只有本地 DRAM 的控制。另一個是模擬 CXL 內存。應該強調的是,盡管英特爾早前聲稱其支持 Sapphire Rapids CXL 的平臺將于 2021 年底推出。或者聲稱 Sapphire Rapids 將于 2022 年初推出。因此,微軟必須模擬延遲影響。Microsoft 使用了 2 路 24C Skylake SP 系統。
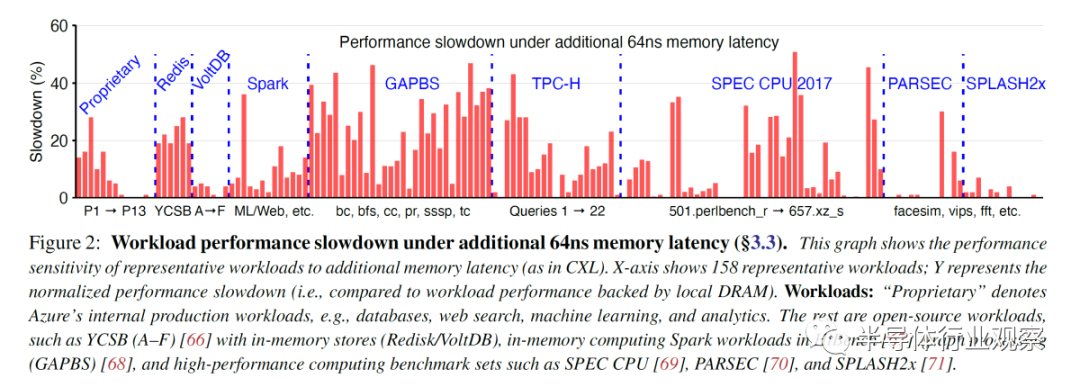
當帶寬超過 80GB/s 時,內存訪問延遲為 78ns。當一個 CPU 跨 NUMA 邊界訪問另一個 CPU 的內存時,會導致額外的 64ns 內存延遲。這非常接近外部存儲設備 (EMC) 在低插槽數系統中的 67ns 額外延遲。
20% 的工作負載沒有性能影響。另有 23% 的工作負載出現了不到 5% 的減速。25% 的工作負載嚴重減速,性能下降超過 20%,其中 12% 的工作負載甚至出現超過 30% 的性能下降。根據工作負載的本地與池內存量,該數字會發生相當大的變化。
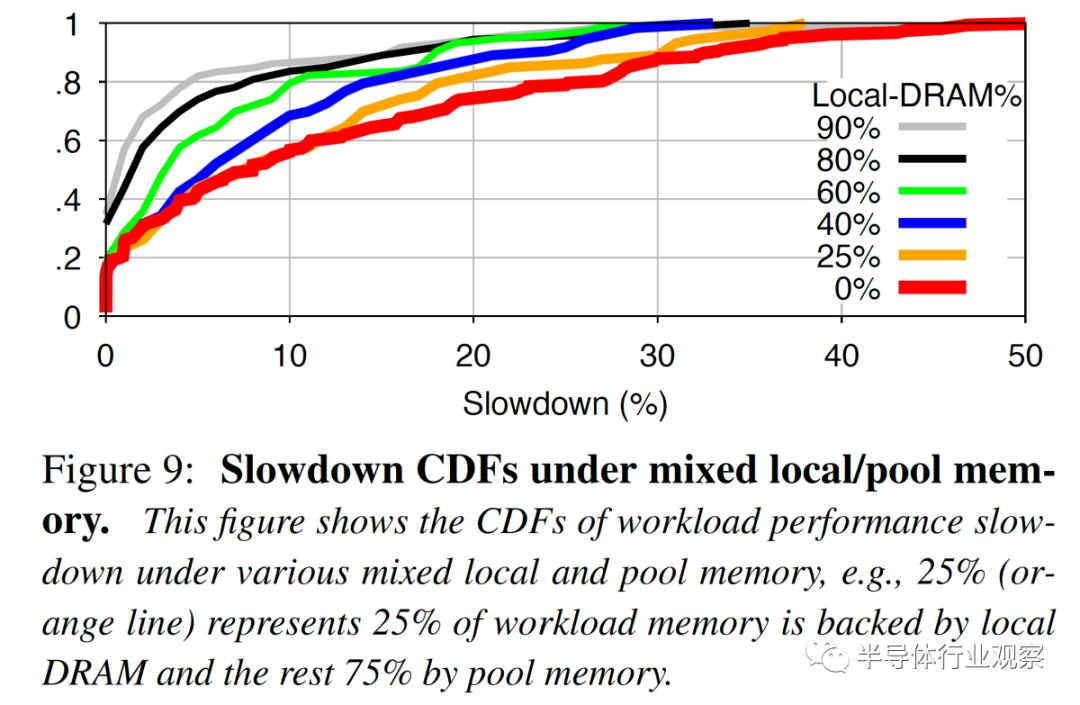
這進一步強調了預測模型的重要性。Microsoft 的基于隨機森林(random forest) ML 的預測模型更準確,并且產生的誤報減速更少。隨著更多的內存被池化,越多變得越重要。
隨著 CXL 規范的改進、延遲的降低和預測模型的改進,內存池節省的可能性可能會增長到云服務器成本的兩位數百分比
審核編輯 :李倩
-
芯片
+關注
關注
459文章
52471瀏覽量
440426 -
NAND
+關注
關注
16文章
1722瀏覽量
138107 -
數據中心
+關注
關注
16文章
5222瀏覽量
73486
原文標題:為什么看好CXL?一文看懂!
文章出處:【微信號:IC學習,微信公眾號:IC學習】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄

數據中心液冷技術和風冷技術的比較
適用于數據中心和AI時代的800G網絡
優化800G數據中心:高速線纜、有源光纜和光纖跳線解決方案


人工智能對數據中心的挑戰
這4個工作能讓數據中心保持長期穩定運行
當今數據中心新技術趨勢

數據中心對MOS管性能的要求



數據中心能耗較多 如何科學智慧化進行整體解決方案呢





 工商網監
工商網監
評論