 深度學習模型的部署方法
深度學習模型的部署方法
當我們辛苦收集數據、數據清洗、搭建環境、訓練模型、模型評估測試后,終于可以應用到具體場景,但是,突然發現不知道怎么調用自己的模型,更不清楚怎么去部署模型! 這也是今天“計算機視覺研究院”要和大家分享的內容,部署模型需要考慮哪些問題,考慮哪些步驟及現在常用的部署方法! 今天內容較多,感興趣的請收藏慢慢閱讀!
1
背景
當我們辛苦收集數據、數據清洗、搭建環境、訓練模型、模型評估測試后,終于可以應用到具體場景,但是,突然發現不知道怎么調用自己的模型,更不清楚怎么去部署模型!
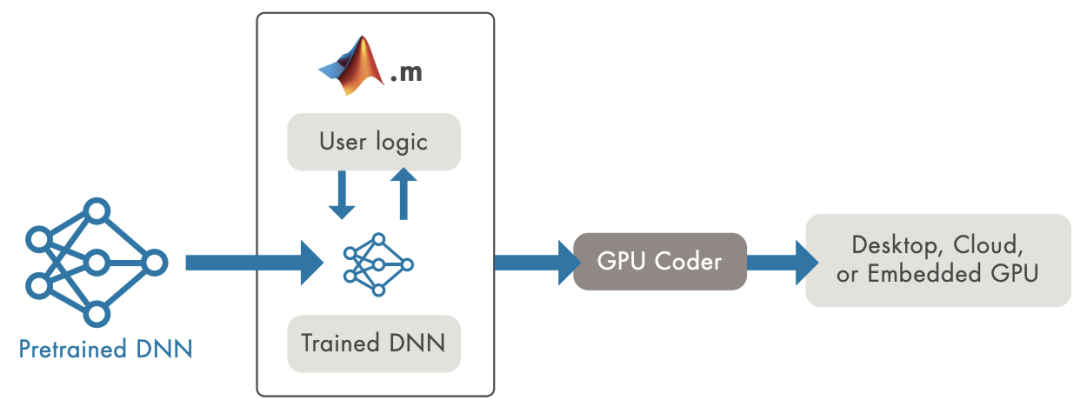
使用GPU Coder生成整個端到端應用程序的代碼
將深度學習模型部署到生產環境面臨兩大挑戰:
我們需要支持多種不同的框架和模型,這導致開發復雜性,還存在工作流問題。數據科學家開發基于新算法和新數據的新模型,我們需要不斷更新生產環境
如果我們使用英偉達GPU提供出眾的推理性能。首先,GPU是強大的計算資源,每GPU運行一個模型可能效率低下。在單個GPU上運行多個模型不會自動并發運行這些模型以盡量提高GPU利用率
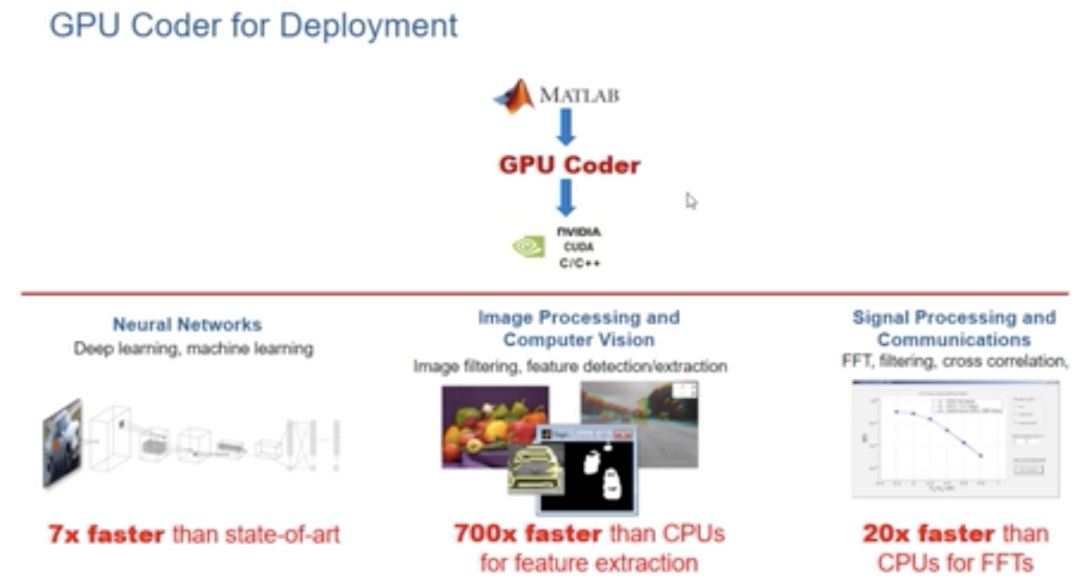
Matlab案例
能從數據中學習,識別模式并在極少需要人為干預的情況下做出決策的系統令人興奮。深度學習是一種使用神經網絡的機器學習,正迅速成為解決對象分類到推薦系統等許多不同計算問題的有效工具。然而,將經過訓練的神經網絡部署到應用程序和服務中可能會給基礎設施經理帶來挑戰。多個框架、未充分利用的基礎設施和缺乏標準實施,這些挑戰甚至可能導致AI項目失敗。今天就探討了如何應對這些挑戰,并在數據中心或云端將深度學習模型部署到生產環境。
一般來說,我們應用開發人員與數據科學家和IT部門合作,將AI模型部署到生產環境。數據科學家使用特定的框架來訓練面向眾多使用場景的機器/深度學習模型。我們將經過訓練的模型整合到為解決業務問題而開發的應用程序中。然后,IT運營團隊在數據中心或云端運行和管理已部署的應用程序。
2
部署需求
02:24
以下需求講解轉自于《知乎-田子宸》
鏈接:https://www.zhihu.com/question/329372124/answer/743251971
需求一:簡單的demo演示,只看看效果
caffe、tf、pytorch等框架隨便選一個,切到test模式,拿python跑一跑就好,順手寫個簡單的GUI展示結果;高級一點,可以用CPython包一層接口,然后用C++工程去調用
需求二:要放到服務器上去跑,不要求吞吐和時延
caffe、tf、pytorch等框架隨便選一個,按照官方的部署教程,老老實實用C++部署,例如pytorch模型用工具導到libtorch下跑。這種還是沒有脫離框架,有很多為訓練方便保留的特性沒有去除,性能并不是最優的。另外,這些框架要么CPU,要么NVIDIA GPU,對硬件平臺有要求,不靈活;還有,框架是真心大,占內存(tf還占顯存),占磁盤。
需求三:放到服務器上跑,要求吞吐和時延(重點是吞吐)
這種應用在互聯網企業居多,一般是互聯網產品的后端AI計算,例如人臉驗證、語音服務、應用了深度學習的智能推薦等。由于一般是大規模部署,這時不僅僅要考慮吞吐和時延,還要考慮功耗和成本。所以除了軟件外,硬件也會下功夫。
硬件上,比如使用推理專用的NVIDIA P4、寒武紀MLU100等。這些推理卡比桌面級顯卡功耗低,單位能耗下計算效率更高,且硬件結構更適合高吞吐量的情況。
軟件上,一般都不會直接上深度學習框架。對于NVIDIA的產品,一般都會使用TensorRT來加速。TensorRT用了CUDA、CUDNN,而且還有圖優化、fp16、int8量化等。
需求四:放在NVIDIA嵌入式平臺上跑,注重時延
比如PX2、TX2、Xavier等,參考上面,也就是貴一點。
需求五:放在其他嵌入式平臺上跑,注重時延
硬件方面,要根據模型計算量和時延要求,結合成本和功耗要求,選合適的嵌入式平臺。
比如模型計算量大的,可能就要選擇帶GPU的SoC,用opencl/opengl/vulkan編程;也可以試試NPU,不過現在NPU支持的算子不多,一些自定義Op多的網絡可能部署不上去;
對于小模型,或者幀率要求不高的,可能用CPU就夠了,不過一般需要做點優化(剪枝、量化、SIMD、匯編、Winograd等)。在手機上部署深度學習模型也可以歸在此列,只不過硬件沒得選,用戶用什么手機你就得部署在什么手機上。
上述部署和優化的軟件工作,在一些移動端開源框架都有人做掉了,一般拿來改改就可以用了,性能都不錯。
需求六:上述部署方案不滿足你的需求
比如開源移動端框架速度不夠——自己寫一套。比如像商湯、曠世、Momenta都有自己的前向傳播框架,性能應該都比開源框架好。只不過自己寫一套比較費時費力,且如果沒有經驗的話,很有可能費半天勁寫不好
粉絲福利:
MATLAB的使用 GPU Coder 將深度學習應用部署到 NVIDIA GPU上 鏈接:https://ww2.mathworks.cn/videos/implement-deep-learning-applications-for-nvidia-gpus-with-gpu-coder-1512748950189.html NVIDIA Jetson上的目標檢測生成和部署CUDA代碼 鏈接:https://ww2.mathworks.cn/videos/generate-and-deploy-cuda-code-for-object-detection-on-nvidia-jetson-1515438160012.html
3
部署舉例
作者:糖心他爸 鏈接:https://www.zhihu.com/question/329372124/answer/809058784
選擇嵌入式部署的場景來進行分析
一般從離線訓練到在線部署,我們需要依賴離線訓練框架(靜態圖:tensorflow、caffe,動態圖:pytorch、mxnet等),靜態圖工業部署成熟坑少,動態圖靈活便捷、預研方便,各有各的好處;還需要依賴在線inference的框架(如阿里的MNN、騰訊的NCNN等等,一般不建議你自己去摳neon等simd底層的東西),能大大縮減你的部署周期,畢竟公司里面工期為王!
選定了上述工具鏈以后,剩下的就是我們問題所關心的如何部署,或者說的是部署流程。
一般流程分為如下幾步:
模型設計和訓練
針對推斷框架的模型轉換
模型部署
雖然把整個流程分成三步,但三者之間是相互聯系、相互影響的。首先第一步的模型設計需要考慮推斷框架中對Op的支持程度,從而相應的對網絡結構進行調整,進行修改或者裁剪都是經常的事情;模型轉換也需要確認推斷框架是否能直接解析,或者選取的解析媒介是否支持網絡結構中的所有Op,如果發現有不支持的地方,再權衡進行調整。
下面我給大家推薦幾個部署案例,很多case在產品部署中都有應用, 離線訓練框架主要使用tensorflow、mxnet,在線inference框架我主要使用阿里MNN。案例請參考下面鏈接:
靜態圖的部署流程:
實戰MNN之Mobilenet SSD部署(含源碼)
https://zhuanlan.zhihu.com/p/70323042
詳解MNN的tf-MobilenetSSD-cpp部署流程
https://zhuanlan.zhihu.com/p/70610865
詳解MNN的tflite-MobilenetSSD-c++部署流程
https://zhuanlan.zhihu.com/p/72247645
基于tensorflow的BlazeFace-lite人臉檢測器
https://zhuanlan.zhihu.com/p/79047443
BlazeFace: 亞毫秒級的人臉檢測器(含代碼)
https://zhuanlan.zhihu.com/p/73741766
動態圖的部署流程:
PFLD-lite:基于MNN和mxnet的嵌入式部署
https://zhuanlan.zhihu.com/p/80051906
整合mxnet和MNN的嵌入式部署流程
https://zhuanlan.zhihu.com/p/75742333
整合Pytorch和MNN的嵌入式部署流程
https://zhuanlan.zhihu.com/p/76605363
4
深度學習模型部署方法
出處:智云視圖 鏈接:https://www.zhihu.com/question/329372124/answer/1243127566 主要介紹offline的部署方法
主要分兩個階段,第一個階段是訓練并得到模型,第二個階段則是在得到模型后,在移動端進行部署。本文主要講解的為第二階段。
訓練模型
在第一階段訓練模型中,已經有很成熟的開源框架和算法進行實現,但是為了能部署到移動端,還需要進行壓縮加速。
壓縮網絡
目前深度學習在各個領域輕松碾壓傳統算法,不過真正用到實際項目中卻會有很大的問題:
計算量非常巨大
模型占用很高內存
由于移動端系統資源有限,而深度學習模型可能會高達幾百M,因此很難將深度學習應用到移動端系統中去。
壓縮方法
綜合現有的深度模型壓縮方法,它們主要分為四類:
基于參數修剪和共享的方法針對模型參數的冗余性,試圖去除冗余和不重要的項。基于低秩因子分解的技術使用矩陣/張量分解來估計深度學習模型的信息參數。基于傳輸/緊湊卷積濾波器的方法設計了特殊的結構卷積濾波器來降低存儲和計算復雜度。知識蒸餾方法通過學習一個蒸餾模型,訓練一個更緊湊的神經網絡來重現一個更大的網絡的輸出。
一般來說,參數修剪和共享,低秩分解和知識蒸餾方法可以用于全連接層和卷積層的CNN,但另一方面,使用轉移/緊湊型卷積核的方法僅支持卷積層。低秩因子分解和基于轉換/緊湊型卷積核的方法提供了一個端到端的流水線,可以很容易地在CPU/GPU環境中實現。相反參數修剪和共享使用不同的方法,如矢量量化,二進制編碼和稀疏約束來執行任務,這導致常需要幾個步驟才能達到目標。
移動端部署
目前,很多公司都推出了開源的移動端深度學習框架,基本不支持訓練,只支持前向推理。這些框架都是 offline 方式,它可確保用戶數據的私有性,可不再依賴于因特網連接。
Caffe2
2017年4月19日 Facebook在F8開發者大會上推出Caffe2。項目是專門為手機定制的深度框架,是在caffe2 的基礎上進行遷移的,目的就是讓最普遍的智能設備——手機也能廣泛高效地應用深度學習算法。
開源地址: facebookarchive/caffe2
TensorFlow Lite
2017年5月17日 Goole在I/O大會推出TensorFlow Lite,是專門為移動設備而優化的 TensorFlow 版本。TensorFlow Lite 具備以下三個重要功能:
輕量級(Lightweight):支持機器學習模型的推理在較小二進制數下進行,能快速初始化/啟動
跨平臺(Cross-platform):可以在許多不同的平臺上運行,現在支持 Android 和 iOS
快速(Fast):針對移動設備進行了優化,包括大大減少了模型加載時間、支持硬件加速
模塊如下:
TensorFlow Model: 存儲在硬盤上已經訓練好的 TensorFlow 模型
TensorFlow Lite Converter: 將模型轉換為 TensorFlow Lite 文件格式的程序
TensorFlow Lite Model File: 基于 FlatBuffers 的模型文件格式,針對速度和大小進行了優化。
TensorFlow Lite 目前支持很多針對移動端訓練和優化好的模型。
Core ML
2017年6月6日 Apple在WWDC大會上推出Core ML。對機器學習模型的訓練是一項很重的工作,Core ML 所扮演的角色更多的是將已經訓練好的模型轉換為 iOS 可以理解的形式,并且將新的數據“喂給”模型,獲取輸出。抽象問題和創建模型雖然并不難,但是對模型的改進和訓練可以說是值得研究一輩子的事情,這篇文章的讀者可能也不太會對此感冒。好在 Apple 提供了一系列的工具用來將各類機器學習模型轉換為 Core ML 可以理解的形式。籍此,你就可以輕松地在你的 iOS app 里使用前人訓練出的模型。這在以前可能會需要你自己去尋找模型,然后寫一些 C++ 的代碼來跨平臺調用,而且難以利用 iOS 設備的 GPU 性能和 Metal (除非你自己寫一些 shader 來進行矩陣運算)。Core ML 將使用模型的門檻降低了很多。
Core ML 在背后驅動了 iOS 的視覺識別的 Vision 框架和 Foundation 中的語義分析相關 API。普通開發者可以從這些高層的 API 中直接獲益,比如人臉圖片或者文字識別等。這部分內容在以前版本的 SDK 中也存在,不過在 iOS 11 SDK 中它們被集中到了新的框架中,并將一些更具體和底層的控制開放出來。比如你可以使用 Vision 中的高層接口,但是同時指定底層所使用的模型。這給 iOS 的計算機視覺帶來了新的可能。
MACE

小米開源了深度學習框架MACE,有幾個特點:異構加速、匯編級優化、支持各種框架的模型轉換。
有了異構,就可以在CPU、GPU和DSP上跑不同的模型,實現真正的生產部署,比如人臉檢測、人臉識別和人臉跟蹤,可以同時跑在不同的硬件上。小米支持的GPU不限于高通,這點很通用,很好,比如瑞芯微的RK3299就可以同時發揮出cpu和GPU的好處來。
MACE 是專門為移動設備優化的深度學習模型預測框架,MACE 從設計之初,便針對移動設備的特點進行了專門的優化:
速度:對于放在移動端進行計算的模型,一般對整體的預測延遲有著非常高的要求。在框架底層,針對ARM CPU進行了NEON指令級優化,針對移動端GPU,實現了高效的OpenCL內核代碼。針對高通DSP,集成了nnlib計算庫進行HVX加速。同時在算法層面,采用Winograd算法對卷積進行加速。
功耗:移動端對功耗非常敏感,框架針對ARM處理器的big.LITTLE架構,提供了高性能,低功耗等多種組合配置。針對Adreno GPU,提供了不同的功耗性能選項,使得開發者能夠對性能和功耗進行靈活的調整。
系統響應:對于GPU計算模式,框架底層對OpenCL內核自適應的進行分拆調度,保證GPU渲染任務能夠更好的進行搶占調度,從而保證系統的流暢度。
初始化延遲:在實際項目中,初始化時間對用戶體驗至關重要,框架對此進行了針對性的優化。
內存占用:通過對模型的算子進行依賴分析,引入內存復用技術,大大減少了內存的占用。
模型保護:對于移動端模型,知識產權的保護往往非常重要,MACE支持將模型轉換成C++代碼,大大提高了逆向工程的難度。
此外,MACE 支持 TensorFlow 和 Caffe 模型,提供轉換工具,可以將訓練好的模型轉換成專有的模型數據文件,同時還可以選擇將模型轉換成C++代碼,支持生成動態庫或者靜態庫,提高模型保密性。
目前MACE已經在小米手機上的多個應用場景得到了應用,其中包括相機的人像模式,場景識別,圖像超分辨率,離線翻譯(即將實現)等。
開源地址:XiaoMi/mace
MACE Model Zoo
隨著MACE一起開源的還有MACE Model Zoo項目,目前包含了物體識別,場景語義分割,圖像風格化等多個公開模型。
鏈接: XiaoMi/mace-models
FeatherCNN和NCNN
FeatherCNN 由騰訊 AI 平臺部研發,基于 ARM 架構開發的高效神經網絡前向計算庫,核心算法已申請專利。該計算庫支持 caffe 模型,具有無依賴,速度快,輕量級三大特性。該庫具有以下特性:
無依賴:該計算庫無第三方組件,靜態庫或者源碼可輕松部署于 ARM 服務器,和嵌入式終端,安卓,蘋果手機等移動智能設備。
速度快:該計算庫是當前性能最好的開源前向計算庫之一,在 64 核 ARM 眾核芯片上比 Caffe 和 Caffe2 快 6 倍和 12 倍,在 iPhone7 上比 Tensorflow lite 快 2.5 倍。
輕量級:該計算庫編譯后的后端 Linux 靜態庫僅 115KB , 前端 Linux 靜態庫 575KB , 可執行文件僅 246KB 。
FeatherCNN 采用 TensorGEMM 加速的 Winograd 變種算法,以 ARM 指令集極致提升 CPU 效率,為移動端提供強大的 AI 計算能力。使用該計算庫可接近甚至達到專業神經網絡芯片或 GPU 的性能,并保護用戶已有硬件投資。

NCNN 是一個為手機端極致優化的高性能神經網絡前向計算框架。ncnn 從設計之初深刻考慮手機端的部署和使用。無第三方依賴,跨平臺,手機端 cpu 的速度快于目前所有已知的開源框架。基于 ncnn,開發者能夠將深度學習算法輕松移植到手機端高效執行,開發出人工智能 APP,將 AI 帶到你的指尖。ncnn 目前已在騰訊多款應用中使用,如QQ,Qzone,微信,天天P圖等。
這兩個框架都是騰訊公司出品,FeatherCNN來自騰訊AI平臺部,NCNN來自騰訊優圖。
重點是:都開源,都只支持cpu
NCNN開源早點,性能較好,用戶較多。FeatherCNN開源晚,底子很好。
FeatherCNN開源地址:Tencent/FeatherCNN
NCNN開源地址:Tencent/ncnn
MDL

百度的mobile-deep-learning,MDL 框架主要包括模型轉換模塊(MDL Converter)、模型加載模塊(Loader)、網絡管理模塊(Net)、矩陣運算模塊(Gemmers)及供 Android 端調用的 JNI 接口層(JNI Interfaces)。其中,模型轉換模塊主要負責將 Caffe 模型轉為 MDL 模型,同時支持將 32bit 浮點型參數量化為 8bit 參數,從而極大地壓縮模型體積;模型加載模塊主要完成模型的反量化及加載校驗、網絡注冊等過程,網絡管理模塊主要負責網絡中各層 Layer 的初始化及管理工作;MDL 提供了供 Android 端調用的 JNI 接口層,開發者可以通過調用 JNI 接口輕松完成加載及預測過程。
作為一款移動端深度學習框架,需要充分考慮到移動應用自身及運行環境的特點,在速度、體積、資源占用率等方面有嚴格的要求。同時,可擴展性、魯棒性、兼容性也是需要考慮的。為了保證框架的可擴展性,MDL對 layer 層進行了抽象,方便框架使用者根據模型的需要,自定義實現特定類型的層,使用 MDL 通過添加不同類型的層實現對更多網絡模型的支持,而不需要改動其他位置的代碼。為了保證框架的魯棒性,MDL 通過反射機制,將 C++ 底層異常拋到應用層,應用層通過捕獲異常對異常進行相應處理,如通過日志收集異常信息、保證軟件可持續優化等。目前行業內各種深度學習訓練框架種類繁多,而 MDL 不支持模型訓練能力,為了保證框架的兼容性,MDL提供 Caffe 模型轉 MDL 的工具腳本,使用者通過一行命令就可以完成模型的轉換及量化過程。
開源地址:PaddlePaddle/Paddle-Lite
SNPE
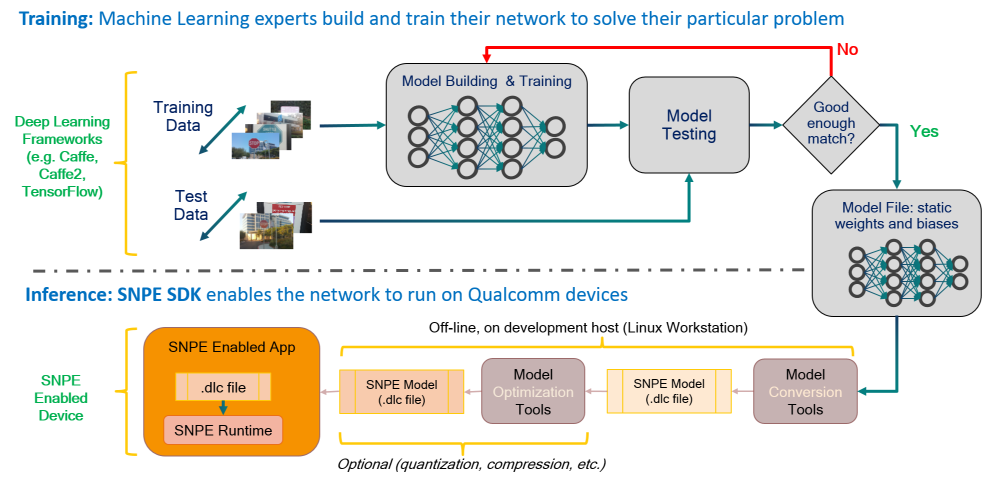
這是高通驍龍的官方SDK,不開源。主要支持自家的DSP、GPU和CPU。模型訓練在流行的深度學習框架上進行(SNPE支持Caffe,Caffe2,ONNX和TensorFlow模型。)訓練完成后,訓練的模型將轉換為可加載到SNPE運行時的DLC文件。然后,可以使用此DLC文件使用其中一個Snapdragon加速計算核心執行前向推斷傳遞。
-
gpu
+關注
關注
28文章
4912瀏覽量
130661 -
深度學習
+關注
關注
73文章
5554瀏覽量
122484
原文標題:深度學習模型原來這樣部署的!(干貨滿滿,收藏慢慢看
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
如何使用Docker部署大模型
Flexus X 實例 ultralytics 模型 yolov10 深度學習 AI 部署與應用







 工商網監
工商網監
評論