 FRNet:上下文感知的特征強化模塊
FRNet:上下文感知的特征強化模塊
論文標題:Enhancing CTR Prediction with Context-Aware Feature Representation Learning
收錄會議:
SIGIR 2022
論文鏈接:
https://arxiv.org/abs/2204.08758
簡介與主要貢獻
目前大多數提升點擊率預估效果的模型主要是通過建模特征交互,但是如何設計有效的特征交互結構需要設計人員對數據特點以及結構設計等方面有很強的要求。目前的以建模特征交互為主的模型可以總結為三層范式:embedding layer, feature interaction layer, 以及 prediction layer。大多數論文改進集中在 Featrue interaction layer。
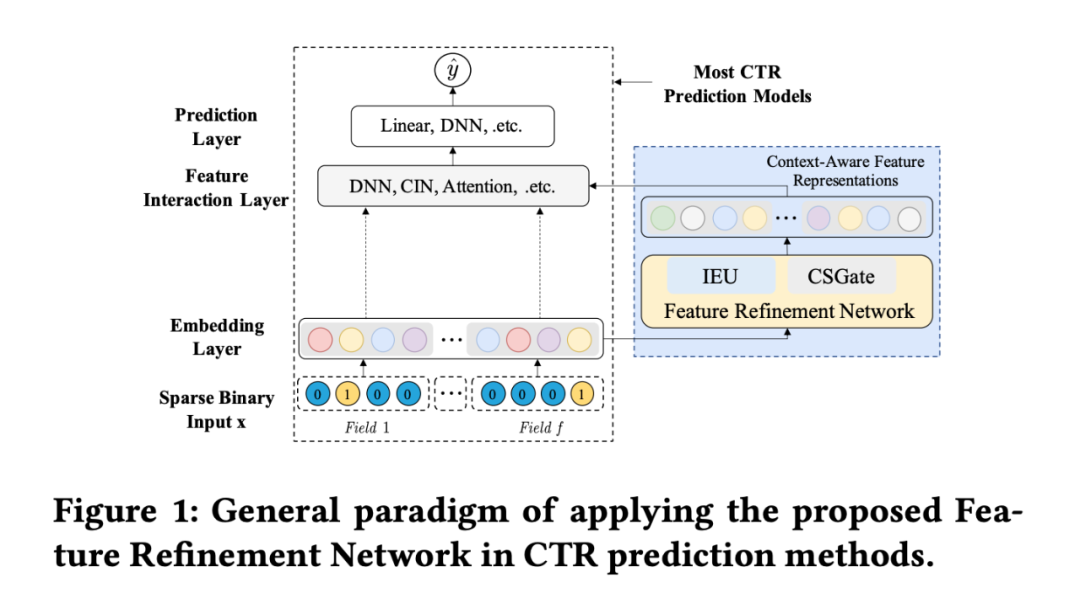
然而大部分的模型都存在一個問題:對于一個相同的特征,他們僅僅學到了一個固定的特征表示,而沒有考慮到這個特征在不同實例中不同上下文環境下的重要性。例如實例 1:{female, white, computer, workday} 和實例 2:{female, red, lipstick, workday} 中,特征 “female” 在這兩個實例中的重要性(對最后的預測結果的影響或者與其他特征的關系)是不同的,因此在輸入特征交互層之前我們就可以調整特征 “female” 的重要性或者是表示。
現有的工作已經注意到了這個問題,例如 IFM、DIFM 等,但是他們僅僅在不同的實例中為相同特征賦予不同的權重(vector-level weights),導致不同實例中的相同特征的表示存在嚴格的線性關系,而這顯然是不太合理的。
另一方面,本文希望一個理想的特征細化模塊應該識別重要的跨實例上下文信息,并學習不同上下文下顯著不同的表示。
給出了一個例子:{female, red, lipstick, workday} and {female, red, lipstick, weekend},在這兩個實例匯總,如果使用self-attention(在 CTR 中很常用的模塊,來識別特征之間的關系),那么因為 “female”和“red”以及“lipstick”的關系比“workday”或者“weekend”的更加緊密,所以在兩個實例中,都會賦予“red”和“lipstick”更大的注意力權重,而對“workday”或者“weekend”的權重都很小。但是用戶的行為會隨著“workday”到“weekend”的變化而變化。
因此本文提出了一個模型無關的模塊 Feature Refinement Network(FRNet)來學習上下文相關的特征表示,能夠使得相同的特征在不同的實例中根據與共現特征的關系以及完整的上下文信息進行調整。主要貢獻如下:
本文提出了一個名為 FRNet 的新模塊,它是第一個通過將原始和互補的特征表示與比特級權值相結合來學習上下文感知特征表示的工作。
FRNet 可以被認為是許多 CTR 預測方法的基本組成部分,可以插入在 embedding layer 之后,提高 CTR 預測方法的性能。
FRNet 表現出了極強集兼容性和有效性。
FRNet模塊
FRNet模型主要包含兩個模塊:
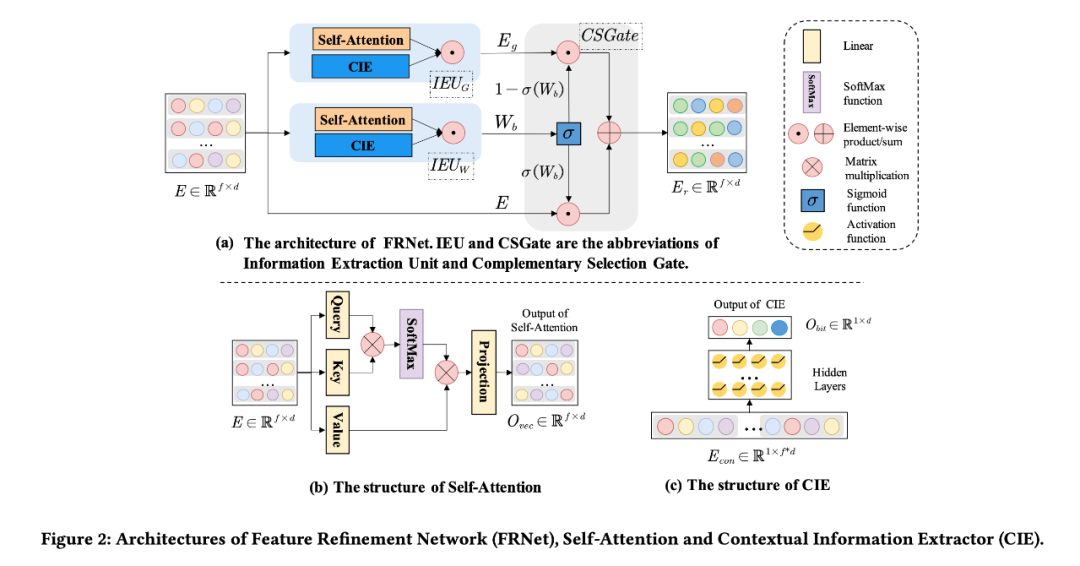
Information Extraction Unit (IEU):IEU 主要是來捕獲上下文相關的信息(Self-Attention unit)以及特征之間的關系信息(Contextual Information Extractor)來共同學習上下文相關的信息。再 Integration unit 進行融合。
Complementary Selection Gate (CSGate):CSGate 可以自適應融合原始的和互補的特征表示,這種融合是在 bit-level 級別上的。
2.1 IEU
通過對以往模型的總結,FRNet 主要通過學習特征間的關系(vector-level)以及上下文相關的信息(bit-level)的信息來學習最后的 context-aware representation。首先在在 IEU 中使用以下兩個模塊:
Self-Attention unit:self-attention 善于學習特征之間的關聯信息。FRNet 中使用了一個基本的 Self-attention 結構。
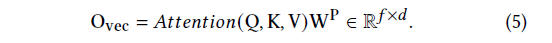
Contextual Information Extractor:在 motivation 部分提到過,self-attention 雖然擅長學習特征之間的關系,但是無法學習整體的上下文信息。所以特地使用了一個簡單的 DNN 模塊來提取不同實例的上下文信息。一個之間的理由是 DNN 可以關注到所有的特征信息(bit-level 信息)。
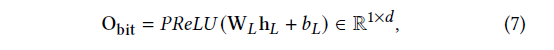
以上兩個單元分別學習了特征之間的關系,對輸入信息進行壓縮,保存了特征的上下文信息。接下來通過一個 Integration unit 對這兩部分信息進行融合:
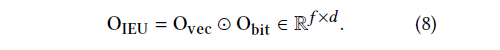
可以看到每個實例只有一個上下文信息維度為 d,而經過 self-attention 之后的關系信息維度是 f*d。所以融合之后相當于賦予了每個特征上下文信息,而這部分信息僅僅 self-attention 是無法獲取的。
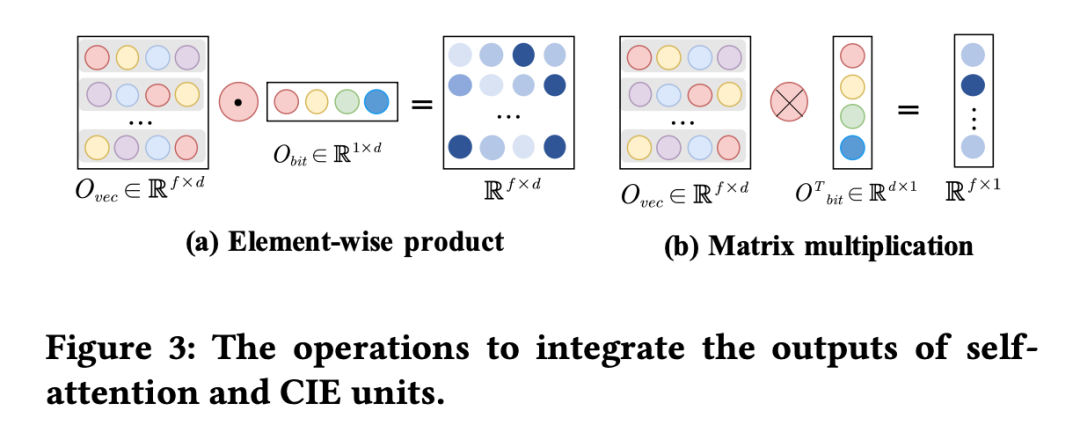
2.2 CSGate
從圖 2 中可以看到,本文使用了兩個 IEU 模型,其中 模塊學習了一組 complementary feature representaion , 學習了一組權重矩陣 。基于 、 以及原始的特征表示 ,FRNet 通過一個選擇門獲得了最后的 context-aware feature representation:
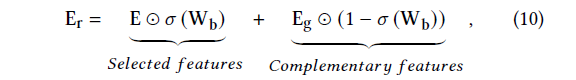
公式主要分為兩部分:
Selected features:首先最后的結果并沒有完全舍棄原有的特征表示 E,但是也沒有像 ResNet 那樣將原始表示 E 直接保留,而是通過權重矩陣進行自適應的選擇。
Complementary features:另一方面,如果僅僅使用原有的特征也會導致模型的表達能力受限。現有的一些方法也僅僅通過分配一個權重的方法來對特征進行調整。同時僅僅分配權重沒有考慮哪些 unselected information。在計算權重的時候使用可 sigmoid 方式,如果只使用選擇的一部分信息,會導致最后的信息
“不完整”(這里有點借鑒 GRU 以及 LSTM 的設計思路)。因為我們從互補矩陣 上選擇互補的信息。
實驗分析
實驗數據集:
3.1 整體分析
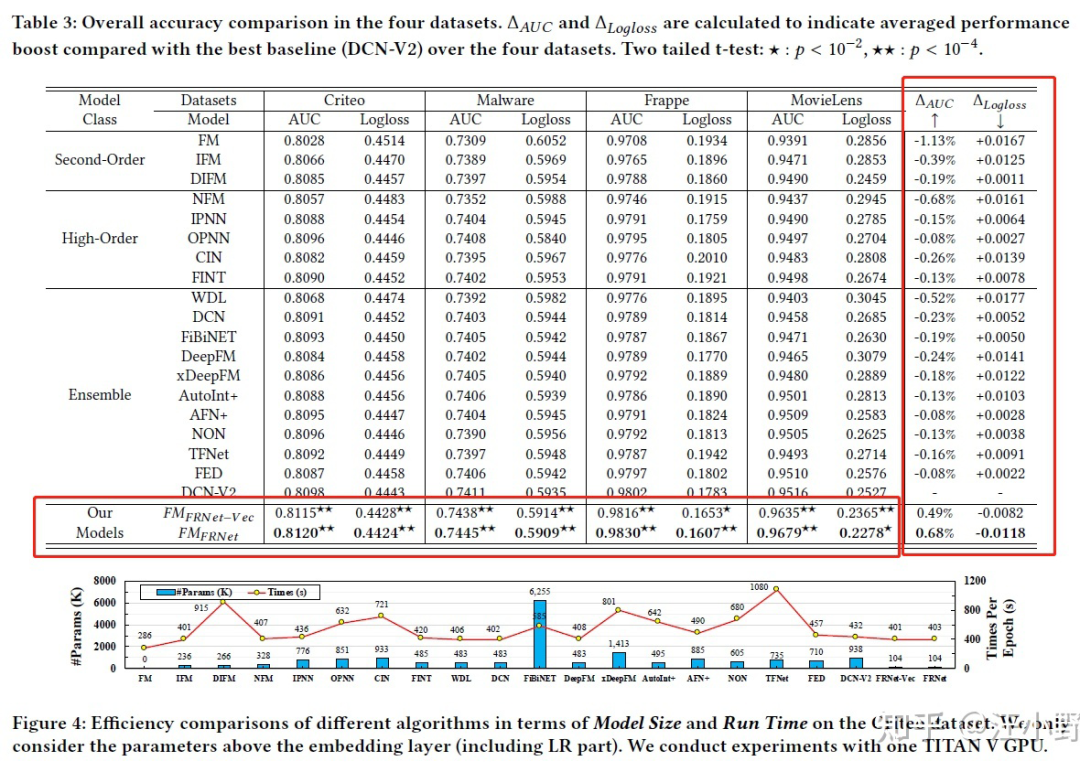
主要將 FRNet 應用到 FM 模型中說明 FRNet 的效果。 這一部分說明了 FRNet 的效果和效率。
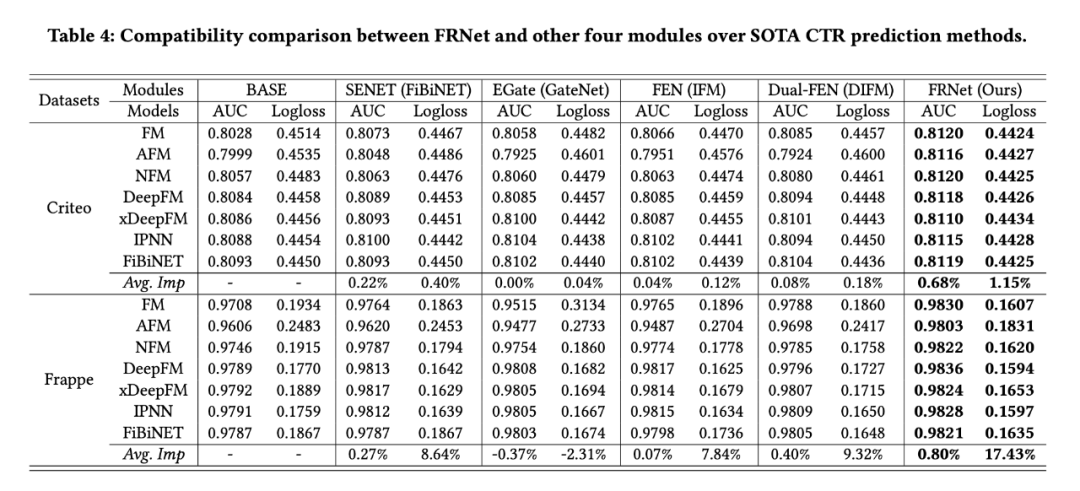
3.2 兼容性分析
將 FRNet 應用到其他模型中查看效果。 和其他模塊進行對比。
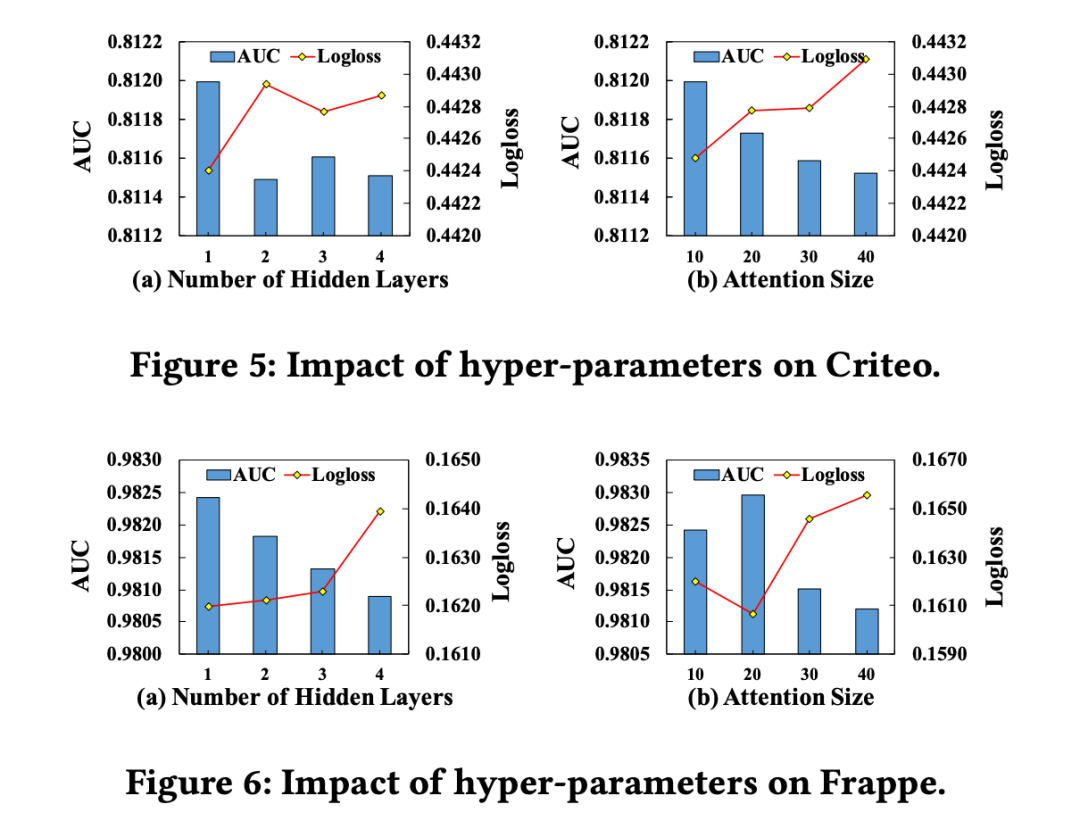
3.3 超參數分析
對 IEU 模塊中的兩個超參數進行了分析:
DNN 的層數
Self-attention 的 attention size
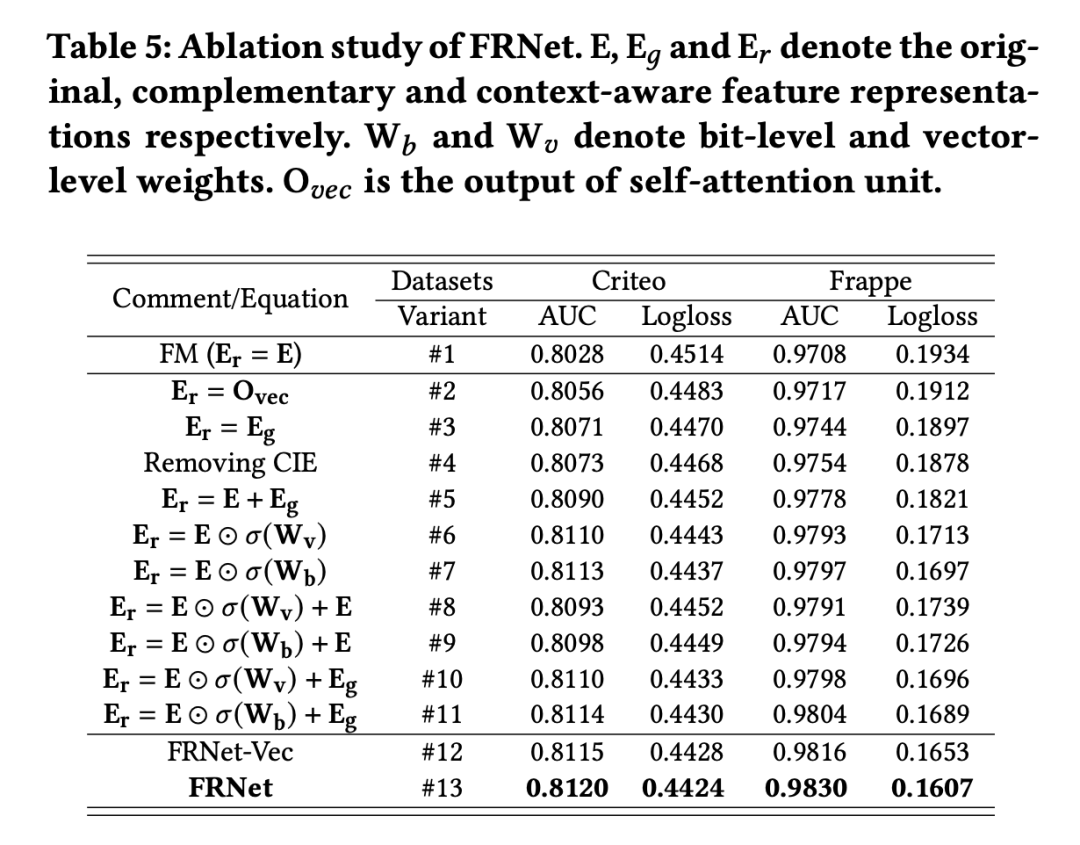
3.4 消融分析
通過消融實驗來說明 FRNet 中的設計都是有效的:
Learning context-aware feature representations是有效的。這里面所有的變式都對原始的特征進行改進,從而獲得了更好的效果(和#1對比)
Cross-feature relationships and contextual information 是必要的。#2中學習了特征之間的關系,超過了 #1。#13 和 #3 學習了 contextual information,分別超過了 #4 和 #2。
Assigning weights to original features 是合理的。#5 移除了權重信息,發現 #10 和 #11 超過了 #5。同時 #6 和 #7 超過了 #1 也說明了相同的結論。
Learning bit-level weights is more effective than learning vector-level。(#7, #9, #11, #13)超過了對應的(#6, #8, #10, #12),前者學習位級別的權重,而后者學習向量級別的權重。
Complementary Features 也是很關鍵的. 添加了輔助特征 之后 #10,#11 分別超過了 #6 和 #7。而且 #12 和 #13 分別超過了 #10 和 #11,說明給輔助特征分配權重也是必要的。
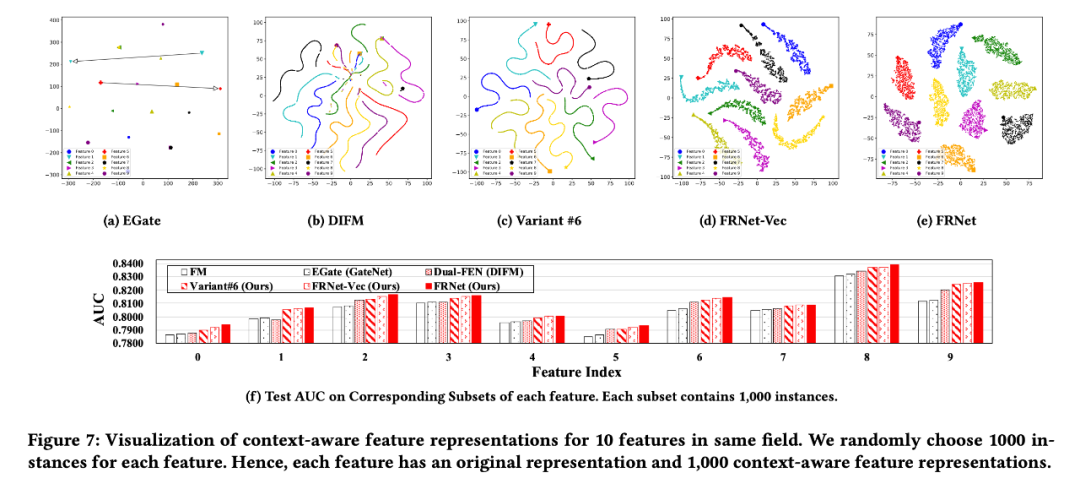
3.5 特征表示可視化分析
本文的 context-aware feature representation 總結起來就是一句話:相同的特征在不同的實例下應該有不同的表示,而且不同實例下的表示不應該有嚴格的線性關系。為了說明這一點,本文通過可視化的方式進行了說明。圖中都是同一個特征的原始表示和 1000 個不同實例中經過 FRNet(或者其他模塊)之后的表示。
EGate 無法學習不同的表示;DIFM 學到的表示存在嚴格的線性關系。而 FRNet 學到的表示同時解決了這些問題。
#6 也是學習向量級別的權重,但是和 DIFM 比可以看到,使用 IEU 學到的權重可以使得特征空間更加分明。#6 中沒有添加輔助特征,所以可以看到還是存在線性關系的,而 FRNet-vec 中添加了輔助特征,消除了線性關系。
FRNet 是學習 bit-level 的權重,而 FRNet-vec 是學習向量級別的權重,從分區的形狀可以看到 FRNet 的非線性特征更加顯著,即更加集中。
3.6 IEU可視化分析
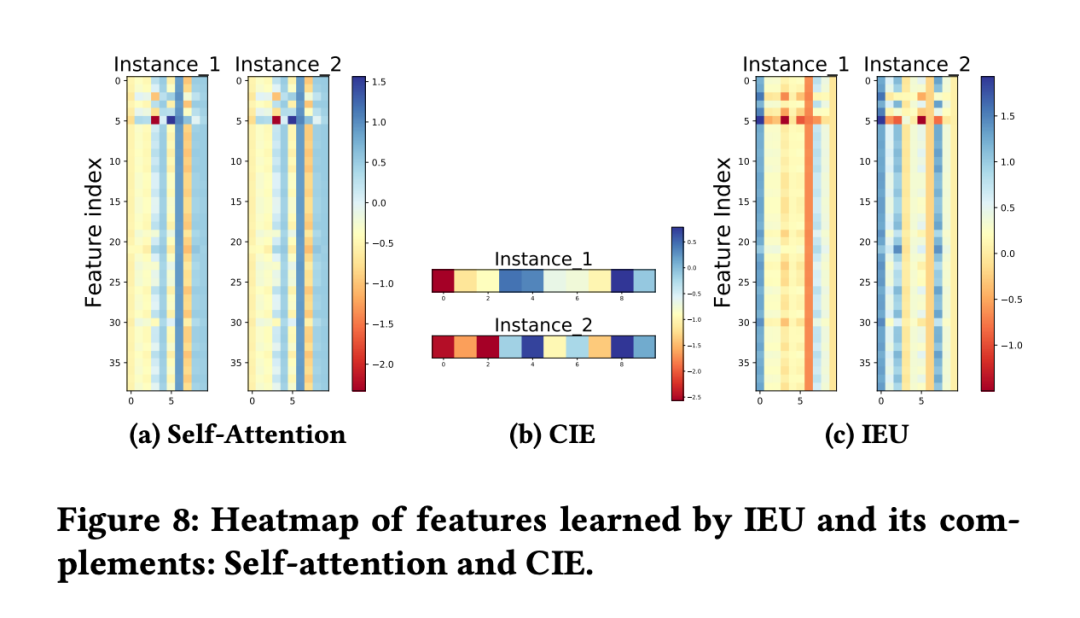
前面說到 Self-attention 中存在的問題:在大部分特征都相同的情況下,無法區分某些不重要的特征表示。在這個實驗中,選擇了兩個特征(只有一個特征是不同的,其他特征都相同),在經過 self-attention 之后,獲得的表示都是相同的。 但是在經過 CIE(DNN)壓縮之后,可以看到僅僅因為這一個特征的不同,最后獲得的表示是權重不同的,而這就是 self-attention 無法學習的上下文信息。最后 IEU 將上下文信息融合到 self-attention 中獲得了圖 8(c)的效果:兩個實例中的每一組對應特征都有顯著的差別。
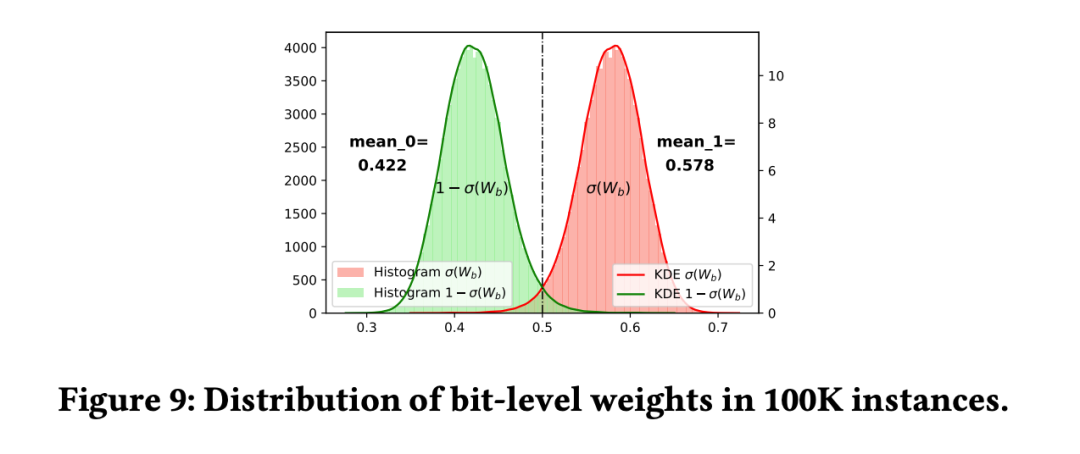
3.7 bit-level權重分析
匯總分析了權重矩陣 在 100K 個實例中分布情況。通過均值可以看出來 57.8% 的概率選擇原始特征表示,而 42.2% 的概率選擇互補特征。
審核編輯 :李倩
-
模型
+關注
關注
1文章
3483瀏覽量
49961 -
CTR
+關注
關注
0文章
38瀏覽量
14295 -
dnn
+關注
關注
0文章
61瀏覽量
9219
原文標題:FRNet:上下文感知的特征強化模塊
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
UIAbility組件基本用法說明
S32K在AUTOSAR中使用CAT1 ISR,是否需要執行上下文切換?
為什么深度學習中的Frame per Second高于OpenVINO?演示推理腳本?
DeepSeek推出NSA機制,加速長上下文訓練與推理
dbForge Studio for PostgreSQL:PostgreSQL數據庫多功能集成開發環境
《具身智能機器人系統》第7-9章閱讀心得之具身智能機器人與大模型
Kaggle知識點:使用大模型進行特征篩選

阿里通義千問發布Qwen2.5-Turbo開源AI模型
Llama 3 在自然語言處理中的優勢
Llama 3 語言模型應用
SystemView上下文統計窗口識別阻塞原因
英特爾軟硬件構建模塊如何幫助優化RAG應用

鴻蒙Ability Kit(程序框架服務)【UIAbility組件基本用法】

鴻蒙Ability Kit(程序框架服務)【應用上下文Context】
通過強化學習策略進行特征選擇





 工商網監
工商網監
評論