 谷歌提出Flan-T5,一個模型解決所有NLP任務
谷歌提出Flan-T5,一個模型解決所有NLP任務
「論文」: Scaling Instruction-Finetuned Language Models
「地址」: https://arxiv.org/abs/2210.11416
「模型」: https://huggingface.co/google/flan-t5-xxl
1. Flan-T5是什么
「Flan-T5」是Google最新的一篇工作,通過在超大規模的任務上進行微調,讓語言模型具備了極強的泛化性能,做到單個模型就可以在1800多個NLP任務上都能有很好的表現。這意味著模型一旦訓練完畢,可以直接在幾乎全部的NLP任務上直接使用,實現「One model for ALL tasks」,這就非常有誘惑力!
這里的Flan指的是(Instruction finetuning),即"基于指令的微調";T5是2019年Google發布的一個語言模型了。注意這里的語言模型可以進行任意的替換(需要有Decoder部分,所以「不包括BERT這類純Encoder語言模型」),論文的核心貢獻是提出一套多任務的微調方案(Flan),來極大提升語言模型的泛化性。
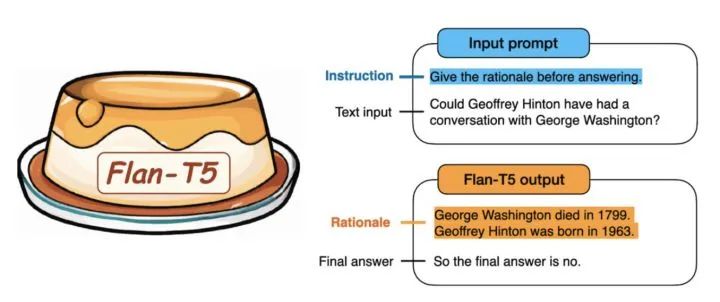
例如下面文章中的例子,模型訓練好之后,可直接讓模型做問答:
「模型輸入」是:"Geoffrey Hinton和George Washington這兩個人有沒有交談過?在回答之前想一想原因。“
「模型返回」是:Geoffrey Hinton是一個計算機科學家,出生在1947年;而George Washington在1799年去世。所以這兩個不可能有過交談。所以答案時“沒有”。
2. 怎么做的
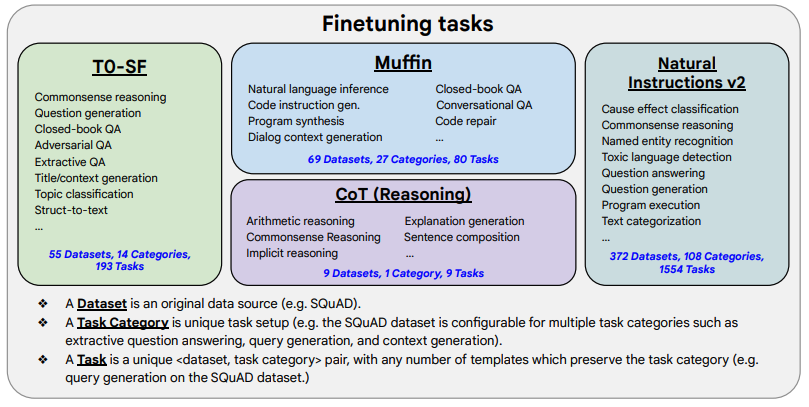
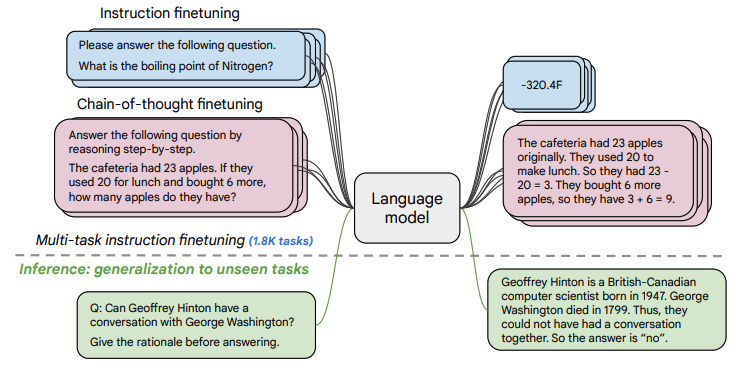
(1) 「任務收集」:工作的第一步是收集一系列監督的數據,這里一個任務可以被定義成<數據集,任務類型的形式>,比如“基于SQuAD數據集的問題生成任務”。需要注意的是這里有9個任務是需要進行推理的任務,即Chain-of-thought (CoT)任務。
(2) 「形式改寫」:因為需要用單個語言模型來完成超過1800+種不同的任務,所以需要將任務都轉換成相同的“輸入格式”喂給模型訓練,同時這些任務的輸出也需要是統一的“輸出格式”。
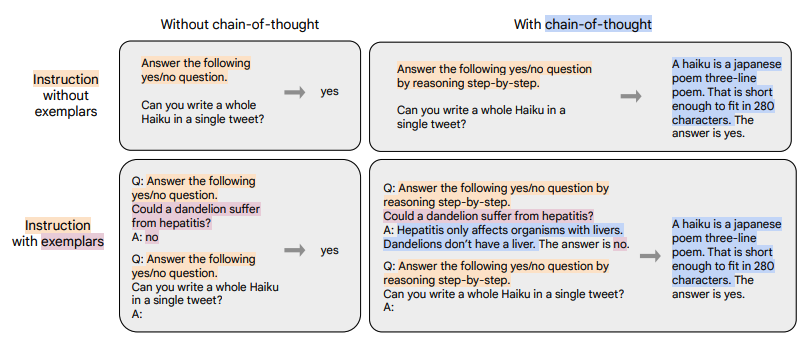
如上圖所示,根據 “是否需要進行推理 (CoT)” 以及 “是否需要提供示例(Few-shot)” 可將輸入輸出劃分成四種類型:
-
chain-of-thought : and few-shot: (圖中左上)
- 輸入:指令 + 問題
- 輸出:答案
-
chain-of-thought : and few-shot: (圖中右上)
- 輸入:指令 + CoT引導(by reasoning step by step) + 問題
- 輸出:理由 + 答案
-
chain-of-thought: and few-shot: (圖中左下)
- 輸入:指令 + 示例問題 + 示例問題回答 + 指令 + 問題
- 輸出:答案
-
chain-of-thought: and few-shot: (圖中右下)
- 輸入:指令 + CoT引導 + 示例問題 + 示例問題理由 + 示例問題回答 + 指令 + CoT引導 + 問題
- 輸出:理由 + 答案
(3) 「訓練過程」:采用恒定的學習率以及Adafactor優化器進行訓練;同時會將多個訓練樣本“打包”成一個訓練樣本,這些訓練樣本直接會通過一個特殊的“結束token”進行分割。訓練時候在每個指定的步數會在“保留任務”上進行模型評估,保存最佳的checkpoint。

盡管微調的任務數量很多,但是相比于語言模型本身的預訓練過程,計算量小了非常多,只有0.2%。所以通過這個方案,大公司訓練好的語言模型可以被再次有效的利用,我們只需要做好“微調”即可,不用重復耗費大量計算資源再去訓一個語言模型。

3. 一些結論
(1) 微調很重要
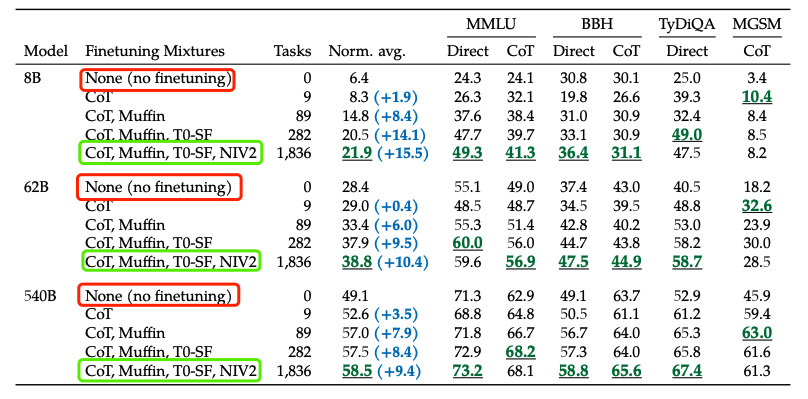
與不微調相比,通過基于指令的微調(flan)可以大幅度提高語言模型的效果。
(2) 模型越大效果越好
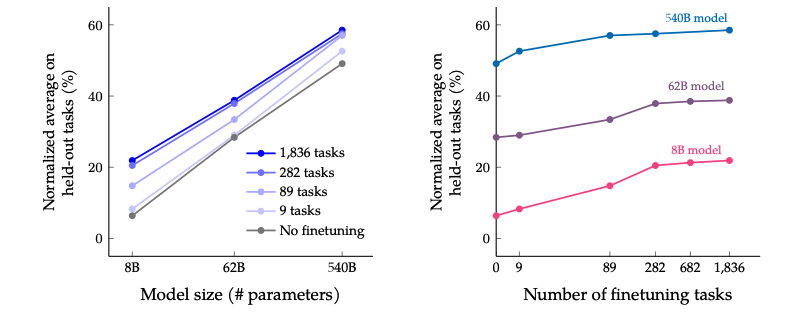
伴隨模型體積的增加(上圖左), 尤其是指數級的增加,比如從8B->62B,再從62B->540B,不論是否微調,效果都有非常顯著的提升,而且還沒有看到收斂的信號,可能如果有了 “萬億”參數的模型,效果還能繼續提升。
(3) 任務越多效果越好
伴隨任務數量的增加(上圖右),模型的性能也會跟著增加,但是當任務數量超過282個之后,提升就不是很明顯了。因為繼續增加新的任務,尤其任務形式跟之前一樣,不會給模型帶來新的知識;多任務微調的本質是模型能夠更好的把從預訓練學到的知識進行表達,超過一定任務之后,繼續新增相似的任務,知識的表達能力不會繼續有很大的收益。進一步統計全部微調數據集的token數,發現只占到了預訓練數據token數的0.2%,這表明還是有很多的知識沒有在微調階段重新被激發。
(4) 混雜CoT相關的任務很重要
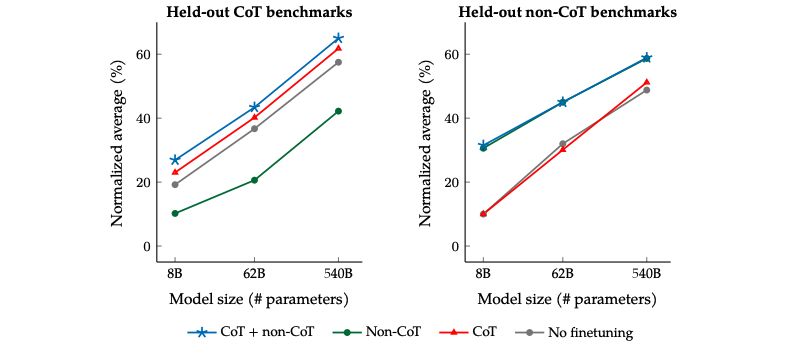
盡管在1800多個任務中只有9個需要推理再給出回答的任務(CoT任務),但是混雜了這9個任務之后對整個模型的提升很大。在針對CoT相關任務的預測上,如果在微調中混淆CoT任務能帶來明顯的提升(左圖中藍色和綠色線);在針對非CoT相關任務的預測上,如果在微調中混淆了CoT任務也不會對模型帶來傷害(右圖中藍色和綠色線)。
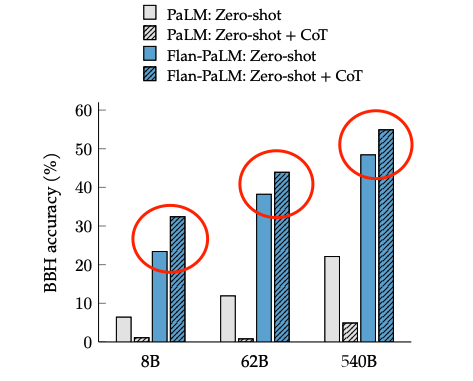
(5) 整合起來
最終在多個不同尺寸的模型上進行實驗,都可以獲得一致性的結論:引入Flan微調方案,可以很好提高語言模型在超大規模任務上的整體效果。
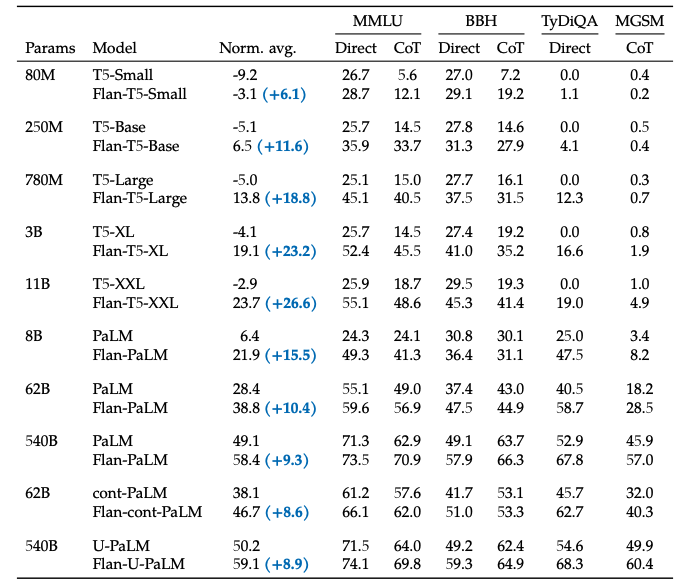
總結一下,這篇工作提出了Flan的微調框架,核心有四點:統一的輸入輸出格式(4種類型),引入chain-of-thought,大幅提高任務數量,大幅提高模型體積;實現了用一個模型來解決超過1800種幾乎全部的NLP任務,通過較低的成本,極大發掘了現有語言模型的泛化性能,讓大家看到了通用模型的希望,即「One Model for ALL Tasks」。
審核編輯 :李倩
-
Google
+關注
關注
5文章
1786瀏覽量
58647 -
模型
+關注
關注
1文章
3480瀏覽量
49948 -
nlp
+關注
關注
1文章
490瀏覽量
22466
原文標題:谷歌提出Flan-T5,一個模型解決所有NLP任務
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監
評論