 源1.0在數學推理任務方面的解決方案和表現
源1.0在數學推理任務方面的解決方案和表現
“源1.0”大模型是浪潮信息發布的中文巨量模型,參數量高達2457億,在中文語言能力理解和生成評測基準CUGE總榜中取得榜首,并獲得語言理解(篇章級)、語言生成、對話交互、多語言、數學推理等5項評測最佳成績。其中在數學推理評測中,源1.0大模型完成1000道小學數學應用題,以76.9的高分大幅領先。
數學對邏輯和推理能力有極強的要求,以往大模型在數學領域表現欠佳。源1.0為何能取得這么好的成績?本文將介紹數學推理任務的背景、研究現狀,以及源1.0在數學推理任務方面的解決方案和表現。
數學單詞問題的研究背景及意義
數學單詞問題,即Math Word Problem(MWP),其主要目標是根據自然語言文字描述的內容解決相應的數學問題。也就是說,對于給定的數學問題,模型需要理解相關文字的數學含義,并推理出正確的表達式。
一個典型的MWP示例如下。
 問題:“快車和慢車同時從相距450千米的兩城相對開出,4.5小時后兩車還相距90千米,快車和慢車的速度比為9:7,慢車每小時行多少千米?”
問題:“快車和慢車同時從相距450千米的兩城相對開出,4.5小時后兩車還相距90千米,快車和慢車的速度比為9:7,慢車每小時行多少千米?”
表達式:(450-90)/4.5*7/(9+7)
結果:35
不難發現,該題目除了要求模型能夠理解基本的加減乘除法之外,還需要理解什么是比例問題。此外,若將問題中的“相對開出”改為“相反方向開出”,將會導致問題的數學邏輯大相徑庭。如何讓模型分辨出語言表達上的差異,并正確地推理出對應的表達式是MWP任務的基本要求。
需要注意的是,在上面的MWP中,表達式中所需的數字量均可以在問題中找到,但在某些情況下,表達式中所需要的數字量并不會全部包含在問題中。例如,在含有分數的MWP示例中(如下紅框中所示),需要根據題目中的數學邏輯,在表達式中額外添加相應的數字量“1”。同樣的問題還常見于計算圓的周長或面積時,需要額外添加數字量“3.14”。
問題:“一根電線長80米,第一次截去的全長的2/5,第二次截去了余下的1/4,這根電線還剩多少米?”
表達式:80*(1-2/5-(1-2/5)*1/4)
結果:36
毫無疑問,MWP任務給模型的語言理解能力和數學推理能力都帶來了極大的挑戰,如何解決MWP任務也是NLP領域的研究熱點之一。
數字單詞問題的研究現狀
實際上,直到2016年MWP的任務精度仍然比較有限。關于MWP任務在2016年之前的研究在此不作細述,相關綜述可參考論文:
How well do Computers Solve Math Word Problems? Large-Scale Dataset Construction and Evaluation (Huang et al., ACL 2016)
近幾年,借助DNN解決MWP任務的方法顯著提升了MWP任務精度,這些方法大致可以分為以下三類:基于seq2seq模型、基于seq2tree模型和基于預訓練模型。
|基于seq2seq模型
該方法是由Wang Yan等學者[1]首次應用在MWP任務上,并在大規模多題型的數據集(Math23K)上取得了顯著的效果(對于Math23K數據集將在后續內容中進行說明)。該方法本質上是采用Encoder-Decoder(enc-dec)結構直接完成了從“問題”到“表達式”的映射。值得一提的是,前述的Math23K數據集規模較大題型較多(約22000道),是目前MWP任務評測的benchmark。
此外,通過設計不同的Encoder和Decoder結構可以得到改進后的seq2seq方法。不過令人驚訝的是,Transformer結構的enc-dec并未在Math23K數據集上表現出明顯的優勢;而采用LSTM結構作為enc-dec的LSTMVAE方法表現最佳。
|基于seq2tree模型
基于Seq2tree模型實際上是基于seq2seq模型的變種,簡單來說,就是將number-mapping后的表達式轉化為樹結構作為模型訓練的輸出(如圖1所示),由于父節點與子節點處的數學符號以及連接方式是固定的,這種方式能夠有效地限制表達式的多樣性。這里,表達式的多樣性可以理解為針對同一個問題可以列出不同的表達式,例如n1+n2-n3還可以寫成n2+n1-n3或者n1+(n2-n3)。
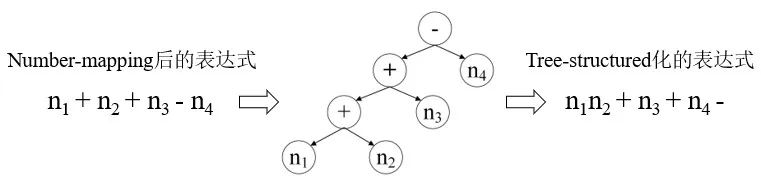
圖1 樹結構化的表達式生成示意
在前述基礎下,基于seq2tree模型的MWP任務解決方法應運而生,其核心思想是將原先的decoder被替換成了tree-based decoder。至此,MWP任務解決思路似乎主要集中在如何替換encoder和decoder問題上。例如,Wang Lei等學者又調整了encoder結構,提出了Graph2tree的方法并且在Math23K任務上精度高達75%。
|基于預訓練模型
Wang Lei等學者[3]發現BERTGen和RoBERTGen(Dec:BERT、RoBERT;Enc:Transformer)在Math23K數據集上表現較為優秀(76.9%)。此外,他們還驗證了GPT-2模型在Math23K數據集上的表現(74.3%),結果稍遜于基于BERT模型的方法,這可能是GPT-2模型結構的原因(Decoder結構)。
|其他MWP任務解決方法
根據前述方法,可以看到的是encoder采用BERT模型較好,decoder采用tree-based方式較好,若將兩者結合形成BERT encoder + tree-based decoder[4],其在Math23K數據集上的精度達到了驚人的84.4%,是目前Math23K任務的baseline。
此外,在眾多MWP任務解決方法中Recall and learn方法[5]是十分值得一提的。該方法跳出了經典的enc-dec結構,通過模擬人腦在解決問題時的類比能力,推理出數學問題的表達式,最終該方法在Math23K任務上的精度能夠達到82.3%。
“源1.0”大模型的MWP任務解決方案
需要指出的是,盡管構建單個技能模型在一定程度上能夠較好地完成MWP任務,但現有技能模型絕大多數仍采用的是encoder-decoder結構,針對類似decoder結構下(如GPT-2)的模型數值推理能力的研究仍然較少。此外,從實現通用人工智能的目標來看,提升通用大模型的數值推理能力是十分必要的。
接下來,將詳細介紹浪潮信息的“源1.0”大模型(decoder結構)在Math23K任務上的相關工作,希望能夠對提升通用大模型的數值推理能力有所啟發。“源1.0”大模型在數學推理能力方面目前位列中文語言能力評測基準CUGE榜首。
| 目標導向的問答式Prompt設計
Math23K的標準數據樣例為:
{
“text”: “某班學生參加數學興趣小組,其中,參加的男生是全班人數的20%,參加的女生是全班人數的(2/7)多2人,不參加的人數比全班人數的(3/5)少5人,全班有多少人?”,
“segmented_text”: “某班 學生 參加 數學 興趣小組 , 其中 , 參加 的 男生 是 全班 人數 的 20% , 參加 的 女生 是 全班 人數 的 (2/7) 多 2 人 , 不 參加 的 人數 比 全班 人數 的 (3/5) 少 5 人 , 全班 有 多少 人 ?”,
“equation”: “x=(5-2)/(20%+(2/7)+(3/5)-1)”,
“label”: “35”
}
其中“text”和“equation”分別對應了任務的問題和表達式信息。在嘗試過各種prompt后,最終確定的prompt設計如下。這種prompt設計將原本的問題拆分成了題干和待求解問題(“問:全班有多少人”)兩個部分,這是由于“問:”后面的內容對表達式的生成十分關鍵。例如,“全班有多少人”和“全班女生有多少人”所對應的表達式是完全不同的。
{
某班學生參加數學興趣小組,其中,參加的男生是全班人數的20%,參加的女生是全班人數的(2/7)多2人,不參加的人數比全班人數的(3/5)少5人,問:全班有多少人?答: x=(5-2)/(20%+(2/7)+(3/5)-1)
}
|相似啟發式數據增強方法
Math23K數據集的題型雖然較為豐富,但題型分布并不均勻。例如,涉及圖形周長、面積和體積類的問題顯然比其他題目類型要少,為保證模型在各類數學題型上均有較好的表現,有必要將該類型的題目擴充。
本文采用了Ape210K數據集[6]對Math23K訓練集進行擴充,Ape210K數據集是另一種較為常用的中文應用數學題集,其題型更為豐富且題量更大(訓練集約20萬道題)。然而,為保證模型在Math23K測試集上有良好的表現,并不能簡單地將Math23K和Ape210K數據集混合在一起。為保證數據增強的有效性,本文提出了一種相似啟發式數據增強方法(如圖2所示)。
該方法針對Math23K訓練集中的每一道題,首先判斷是否屬于圖形周長、面積和體積類題目。若屬于,則top-K取值為2,同時通過相似題檢索從Ape210K中召回對應的相似題;若不屬于,則top-K取值為1,同樣進行相似題檢索。最后,將找到的相似題添加至Math23K訓練集中,數據增強后的訓練集約包含42000道題。
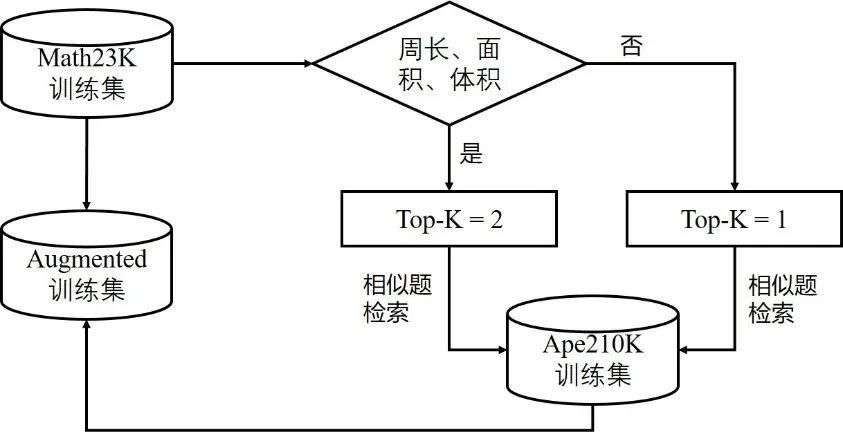
圖2 相似啟發式數據增強方法
|Reset-position-id與reset-attention-mask設計
輸入到模型的一個batch中通常包含多道應用題,且會出現截斷等問題。為避免不同題目和表達式之間相互影響,對模型進行reset-position-id和reset-attention-mask處理。圖3示意了reset前后的對比,采用了[eod]對不同題目之間做切割,在reset-pos-id之前,其位置編碼按照從左到右的順序排列;reset-pos-id之后,位置編碼按照單個題目進行順序排列。類似的,在reset-attn-mask之前,掩碼矩陣對應的是batch尺寸的下三角矩陣;reset-attn-mask后,原先的掩碼矩陣被拆分成若干小的掩碼矩陣,每個小掩碼矩陣對應單個題目尺寸的下三角矩陣。
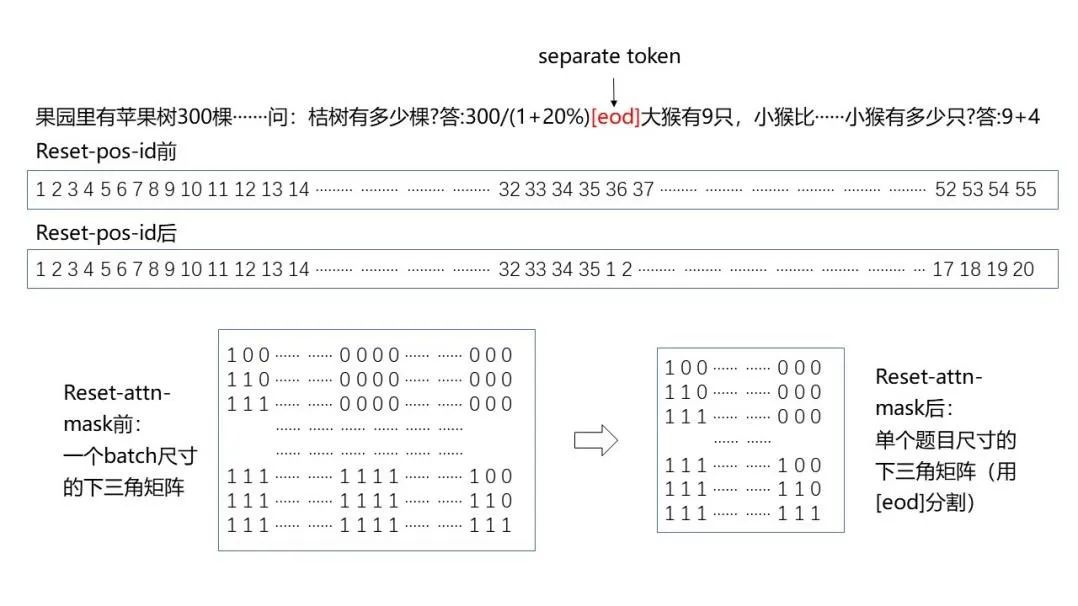
圖3 reset-pos-id和reset-attn-mask前后對比(示意)
訓練參數及結果
訓練過程的主要參數設置如下。

表1 模型訓練部分參數
在訓練了400個iteration后,模型的loss收斂至0.39(圖4)。
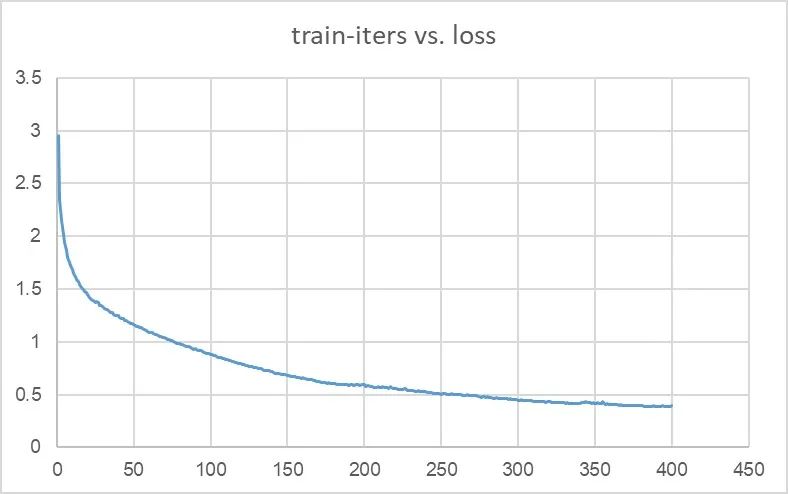
圖4 模型loss曲線
之后,在Math23K測試集上對所提方法的精度進行了測試,并與現有相關方法的結果進行對比(表2)。不難看出,與BERT、GPT-2以及CPM-2模型相比,所提方法下的“源1.0”大模型在Math23K任務上的精度最高。
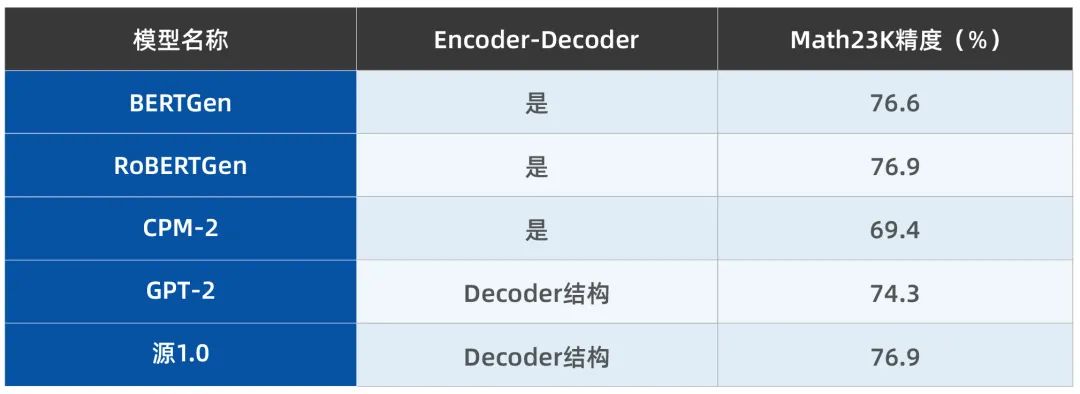
表2 源1.0模型與BERT、GPT等在Math23K測試集上的對比
(相關結果見參考文獻[4])
總結與展望
為提升decoder結構下的通用大模型在MWP任務上的精度,本文提出了一種目標導向的問答式prompt設計方法,該方法有利于引導模型建立問題與表達式之間的準確對應關系;同時提出了一種相似啟發式數據增強方法,通過相似句召回的方式對數據集進行擴充,克服了原有數據集中題型分布不均勻的問題;此外,采用了重置位置編碼和掩碼矩陣的方法,解決了單個batch中的題目之間相互影響的問題。最后,在Math23K數據集上驗證了所提方法,結果證明了“源1.0”模型有很強的數學推理能力。
審核編輯:郭婷
-
浪潮
+關注
關注
1文章
474瀏覽量
24504 -
數據集
+關注
關注
4文章
1223瀏覽量
25279
原文標題:浪潮“源”AI大模型如何求解數學應用題
文章出處:【微信號:浪潮AIHPC,微信公眾號:浪潮AIHPC】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
通過什么方法能獲得關于Ethercat方面的設計方案和設計資料
解析SMA接口在電磁兼容性方面的卓越表現

解析 SMA 接口在電磁兼容性方面的卓越表現
使用MicroPython部署中的ocrrec_image.py推理得到的輸出結果很差,如何解決呢?
芯啟源提供DPU產品與解決方案
聊聊 全面的蜂窩物聯網解決方案
OpenAI O3與DeepSeek R1:推理模型性能深度分析
了解DeepSeek-V3 和 DeepSeek-R1兩個大模型的不同定位和應用選擇
智譜推出深度推理模型GLM-Zero預覽版
阿里云開源推理大模型QwQ
Kimi發布新一代數學推理模型k0-math
高效大模型的推理綜述

NVIDIA助力麗蟾科技打造AI訓練與推理加速解決方案






 工商網監
工商網監
評論