") 介紹大模型高效訓(xùn)練所需要的主要技術(shù)
介紹大模型高效訓(xùn)練所需要的主要技術(shù)
本文分為三部分介紹了大模型高效訓(xùn)練所需要的主要技術(shù),并展示當(dāng)前較為流行的訓(xùn)練加速庫(kù)的統(tǒng)計(jì)。
引言:隨著BERT、GPT等預(yù)訓(xùn)練模型取得成功,預(yù)訓(xùn)-微調(diào)范式已經(jīng)被運(yùn)用在自然語(yǔ)言處理、計(jì)算機(jī)視覺(jué)、多模態(tài)語(yǔ)言模型等多種場(chǎng)景,越來(lái)越多的預(yù)訓(xùn)練模型取得了優(yōu)異的效果。為了提高預(yù)訓(xùn)練模型的泛化能力,近年來(lái)預(yù)訓(xùn)練模型的一個(gè)趨勢(shì)是參數(shù)量在快速增大,目前已經(jīng)到達(dá)萬(wàn)億規(guī)模。
但如此大的參數(shù)量會(huì)使得模型訓(xùn)練變得十分困難,于是不少的相關(guān)研究者和機(jī)構(gòu)對(duì)此提出了許多大模型高效訓(xùn)練的技術(shù)。本文將分為三部分來(lái)介紹大模型高效訓(xùn)練所需要的主要技術(shù):并行訓(xùn)練技術(shù)、顯存優(yōu)化技術(shù)和其他技術(shù)。文章最后會(huì)展示當(dāng)前較為流行的訓(xùn)練加速庫(kù)的統(tǒng)計(jì)。歡迎大家批評(píng)指正,相互交流。
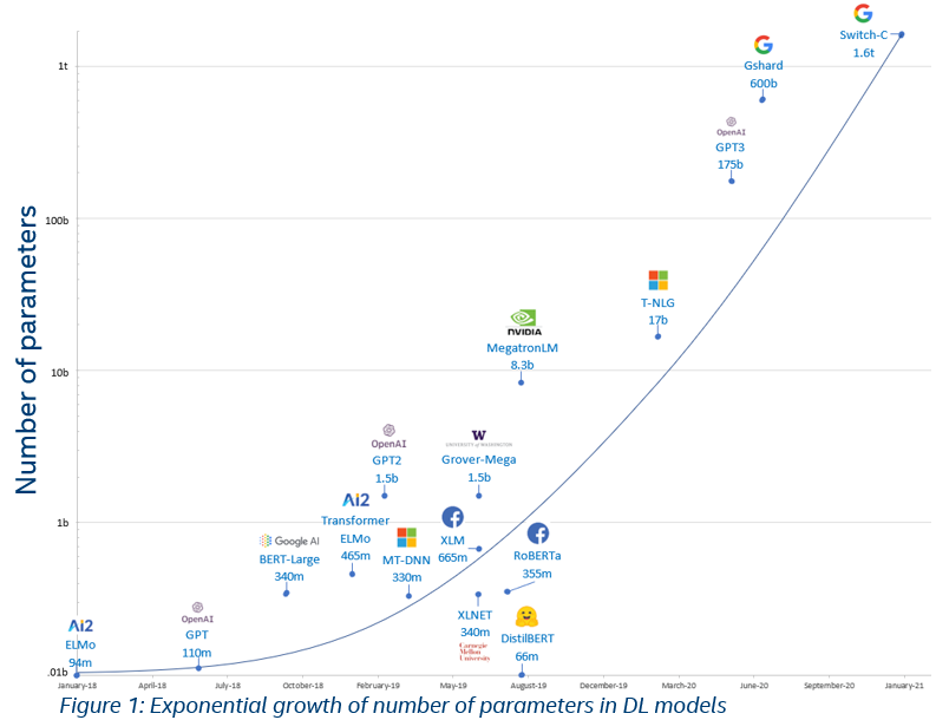
預(yù)訓(xùn)練模型參數(shù)量增長(zhǎng)趨勢(shì)
一、并行訓(xùn)練技術(shù):
并行訓(xùn)練技術(shù)主要是如何使用多塊顯卡并行訓(xùn)練模型,主要可以分為三種并行方式:數(shù)據(jù)并行(Data Parallel)、張量并行(Tensor Parallel)和流水線并行(Pipeline Parallel)。
數(shù)據(jù)并行(Data Parallel)
數(shù)據(jù)并行是目前最為常見(jiàn)和基礎(chǔ)的并行方式。這種并行方式的核心思想是對(duì)輸入數(shù)據(jù)按 batch 維度進(jìn)行劃分,將數(shù)據(jù)分配給不同GPU進(jìn)行計(jì)算。
在數(shù)據(jù)并行里,每個(gè)GPU上存儲(chǔ)的模型、優(yōu)化器狀態(tài)是完全相同的。當(dāng)每塊GPU上的前后向傳播完成后,需要將每塊GPU上計(jì)算出的模型梯度匯總求平均,以得到整個(gè)batch的模型梯度。
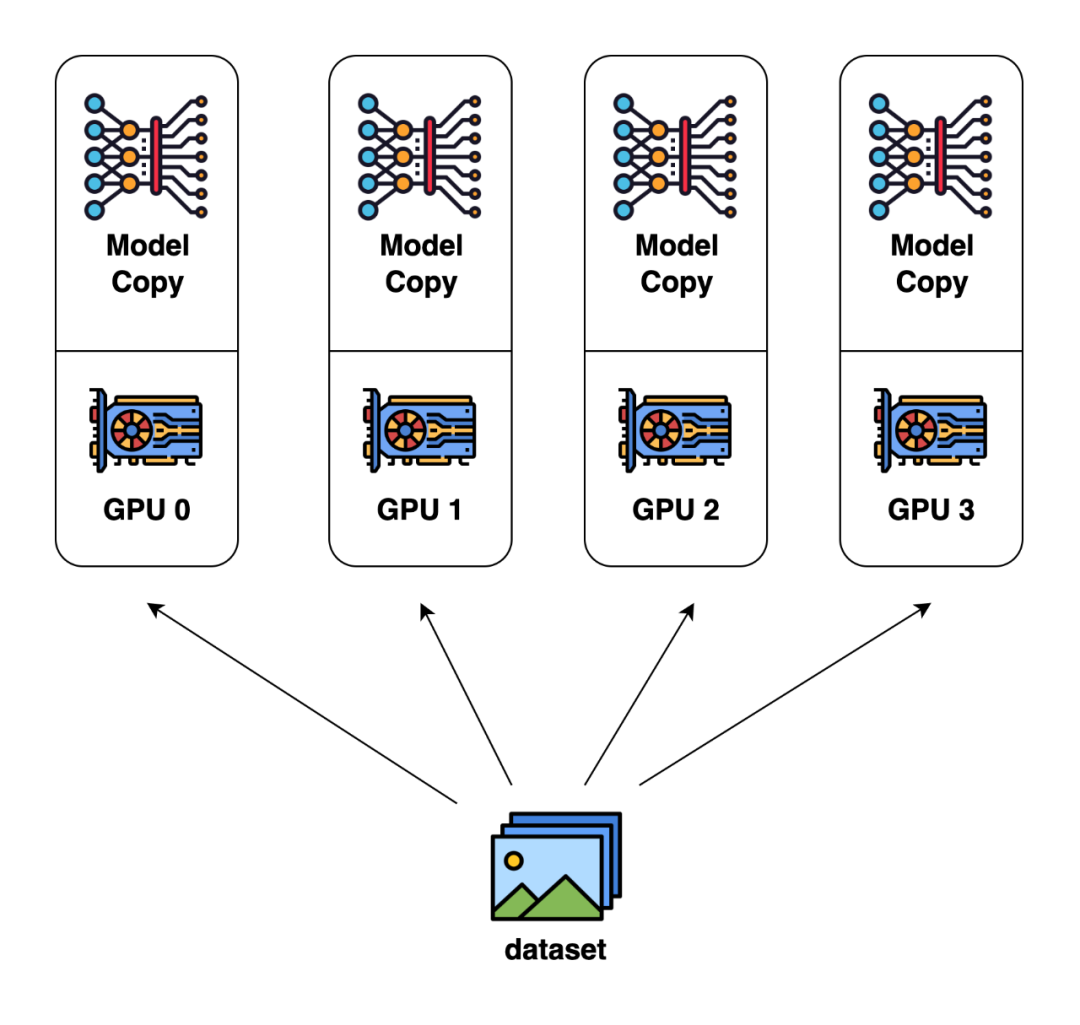
數(shù)據(jù)并行(圖片來(lái)自 Colossal-AI 的文檔)
目前 PyTorch 已經(jīng)支持了數(shù)據(jù)并行 [1]:
https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html
張量并行(Tensor Parallel)
在訓(xùn)練大模型的時(shí)候,通常一塊GPU無(wú)法儲(chǔ)存一個(gè)完整的模型。張量并行便是一種使用多塊GPU存儲(chǔ)模型的方法。
與數(shù)據(jù)并行不同的是,張量并行是針對(duì)模型中的張量進(jìn)行拆分,將其放置到不同的GPU上。比如說(shuō)對(duì)于模型中某一個(gè)線性變換Y=AX,對(duì)于矩陣A有按列拆解和按行拆解兩種方式:
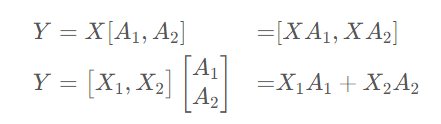
我們可以將矩陣A1和A2分別放置到兩塊不同的GPU上,讓兩塊GPU分別計(jì)算兩部分矩陣乘法,最后再在兩張卡之間進(jìn)行通信便能得到最終的結(jié)果。
同理也可以將這種方法推廣到更多的GPU上,以及其他能夠拆分的算子上。
下圖是Megatron-LM[2] 在計(jì)算 MLP 的并行過(guò)程,它同時(shí)采用了這兩種并行方式:
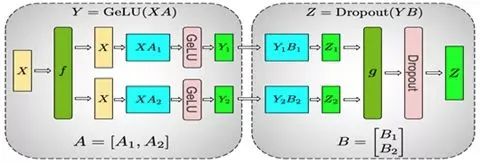
整個(gè)MLP的輸入X先會(huì)復(fù)制到兩塊GPU上,然后對(duì)于矩陣A采取上面提到的按列劃分的方式,在兩塊GPU上分別計(jì)算出第一部分的輸出Y1和Y2。
接下來(lái)的 Dropout 部分的輸入由于已經(jīng)按列劃分了,所以對(duì)于矩陣B則采取按行劃分的方式,在兩塊GPU上分別計(jì)算出Z1和Z2。最后在兩塊GPU上的Z1和Z2做All-Reduce來(lái)得到最終的Z。
以上方法是對(duì)矩陣的一維進(jìn)行拆分,事實(shí)上這種拆分方法還可以擴(kuò)展到二維甚至更高的維度上。在Colossal-AI中,他們實(shí)現(xiàn)了更高維度的張量并行:
https://arxiv.org/abs/2104.05343 https://arxiv.org/abs/2105.14500 https://arxiv.org/abs/2105.14450
對(duì)于序列數(shù)據(jù),尤洋團(tuán)隊(duì)還提出了Sequence Parallel來(lái)實(shí)現(xiàn)并行:
https://arxiv.org/abs/2105.13120
流水線并行(Pipeline Parallel)
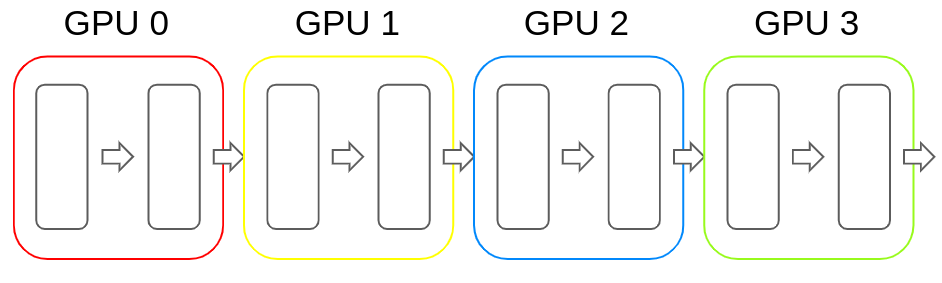
和張量并行類似,流水線并行也是將模型分解放置到不同的GPU上,以解決單塊GPU無(wú)法儲(chǔ)存模型的問(wèn)題。和張量并行不同的地方在于,流水線并行是按層將模型存儲(chǔ)的不同的GPU上。
比如以Transformer為例,流水線并行是將連續(xù)的若干層放置進(jìn)一塊GPU內(nèi),然后在前向傳播的過(guò)程中便按照順序依次計(jì)算hidden state。反向傳播也類似。下圖便是流水線并行的示例:
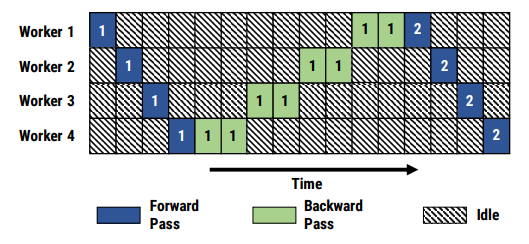
但樸素的流水線并行實(shí)現(xiàn)會(huì)導(dǎo)致GPU使用率過(guò)低(因?yàn)槊繅KGPU都要等待之前的GPU計(jì)算完畢才能開(kāi)始計(jì)算),使流水線中充滿氣泡,如下圖所示:
有兩種比較經(jīng)典的減少氣泡的流水線并行算法:GPipe[7] 和PipeDream[8]
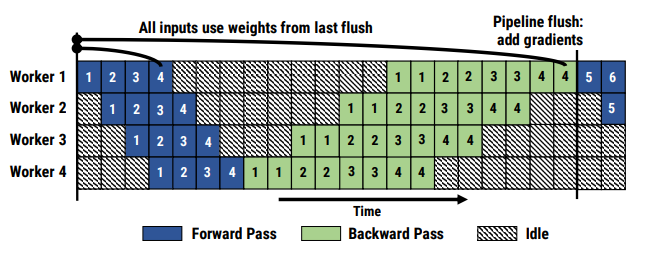
GPipe 方法的核心思想便是輸入的minibatch劃分成更小的 micro-batch,讓流水線依次處理多個(gè) micro batch,達(dá)到填充流水線的目的,進(jìn)而減少氣泡。GPipe 方法的流水線如下所示:
PipeDream 解決流水線氣泡問(wèn)題的方法則不一樣,它采取了類似異步梯度更新的策略,即計(jì)算出當(dāng)前 GPU 上模型權(quán)重的梯度后就立刻更新,無(wú)需等待整個(gè)梯度回傳完畢。相較于傳統(tǒng)的梯度更新公式:
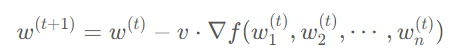
PipeDream 的更新公式為:
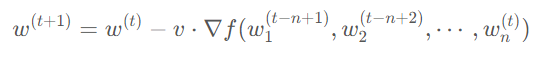
由于這種更新方式會(huì)導(dǎo)致模型每一層使用的參數(shù)更新步數(shù)不一樣多,PipeDream 對(duì)上述方法也做出了一些改進(jìn),即模型每次前向傳播時(shí),按照更新次數(shù)最少的權(quán)重的更新次數(shù)來(lái)算,即公式變?yōu)椋?/p>
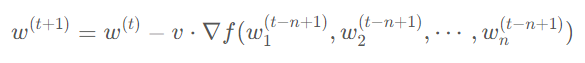
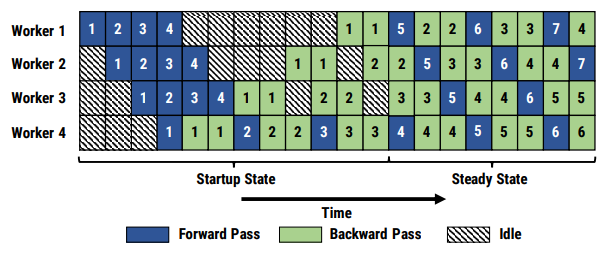
PipeDream 方法的流水線如下所示:
對(duì)比總結(jié)
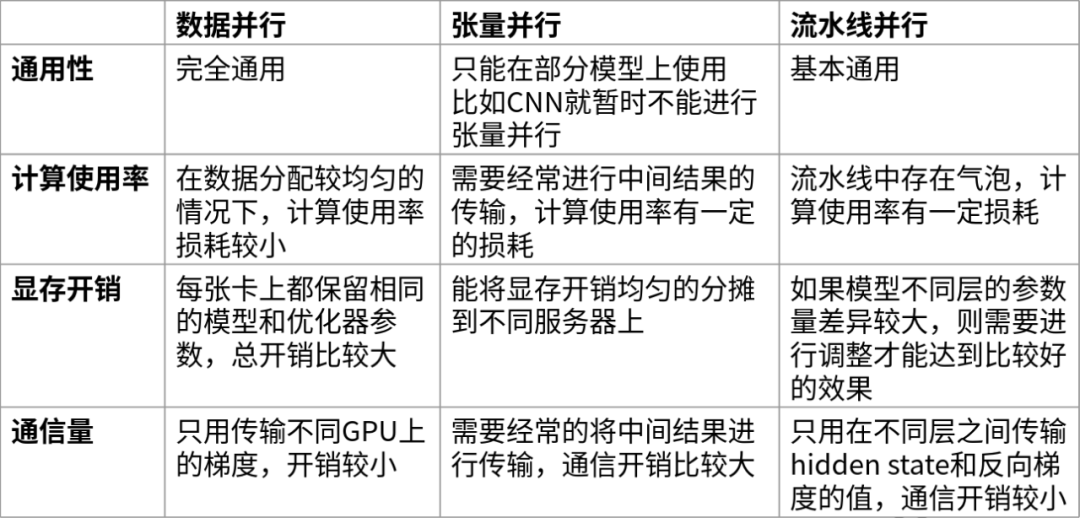
下面是對(duì)這三種并行技術(shù)從通用性、計(jì)算效率、顯存開(kāi)銷和通信量這幾個(gè)方面進(jìn)行對(duì)比。
可以看出數(shù)據(jù)并行的優(yōu)勢(shì)在于通用性強(qiáng)且計(jì)算效率、通信效率較高,缺點(diǎn)在于顯存總開(kāi)銷比較大;而張量并行的優(yōu)點(diǎn)是顯存效率較高,缺點(diǎn)主要是需要引入額外的通信開(kāi)銷以及通用性不是特別好;流水線并行的優(yōu)點(diǎn)除了顯存效率較高以外,且相比于張量并行的通信開(kāi)銷要小一些,但主要缺點(diǎn)是流水線中存在氣泡。
二、顯存優(yōu)化技術(shù):
在模型訓(xùn)練的過(guò)程中,顯存主要可以分為兩大部分:常駐的模型及其優(yōu)化器參數(shù),和模型前向傳播過(guò)程中的激活值。顯存優(yōu)化技術(shù)主要是通過(guò)減少數(shù)據(jù)冗余、以算代存和壓縮數(shù)據(jù)表示等方法來(lái)降低上述兩部分變量的顯存使用量,大致可分為四大類:ZeRO技術(shù)、Offload技術(shù)、checkpoint技術(shù)以及一些節(jié)約顯存的優(yōu)化器。
ZeRO 技術(shù)
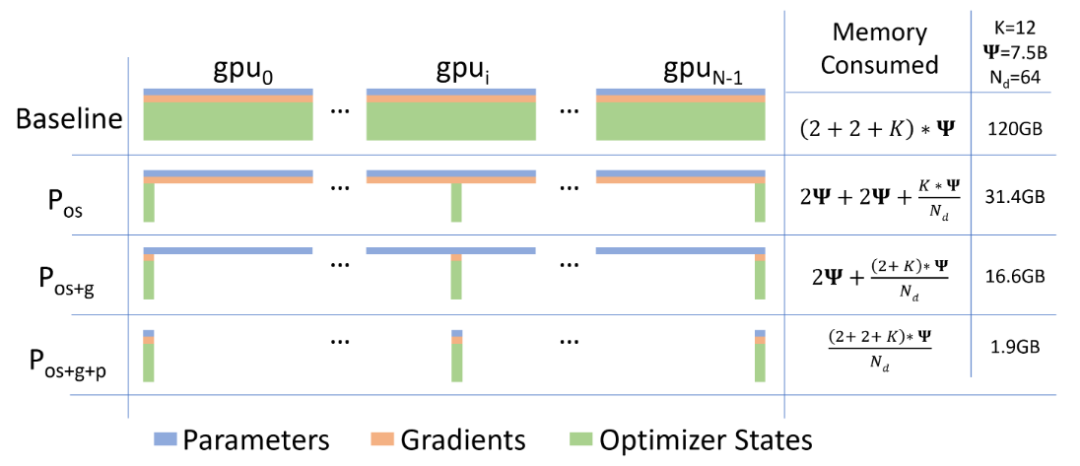
ZeRO[9] 技術(shù)是微軟的 DeepSpeed 團(tuán)隊(duì)解決數(shù)據(jù)并行的中存在的內(nèi)存冗余問(wèn)題所提出的解決方法。常駐在每塊GPU上的數(shù)據(jù)可以分為三部分:模型參數(shù),模型梯度和優(yōu)化器參數(shù)。注意到由于每張 GPU 上都存儲(chǔ)著完全相同的上述三部分參數(shù),我們可以考慮每張卡上僅保留部分?jǐn)?shù)據(jù),其余的可以從其他 GPU 上獲取。
即假如有N張卡,我們可以讓每張卡上只保存其中1/N的參數(shù),需要的時(shí)候再?gòu)钠渌?GPU 上獲取。ZeRO 技術(shù)便是分別考慮了上述三部分參數(shù)分開(kāi)存儲(chǔ)的情況,下圖中的Pos、Pos+g和Pos+g+p就分別對(duì)應(yīng)著將優(yōu)化器參數(shù)分開(kāi)存儲(chǔ)、將優(yōu)化器參數(shù)和模型梯度分開(kāi)存儲(chǔ)以及三部分參數(shù)都分開(kāi)存儲(chǔ)三種情況。
論文里不僅分析了三種情況可以節(jié)省的內(nèi)存情況,還分析出了前兩種優(yōu)化方法不會(huì)增加通信開(kāi)銷,第三種情況的通信開(kāi)銷只會(huì)增加50%。
目前Pytorch也已經(jīng)支持了類似的技術(shù):
https://engineering.fb.com/2021/07/15/open-source/fsdp/ https://pytorch.org/docs/stable/fsdp.html
Offload 技術(shù)
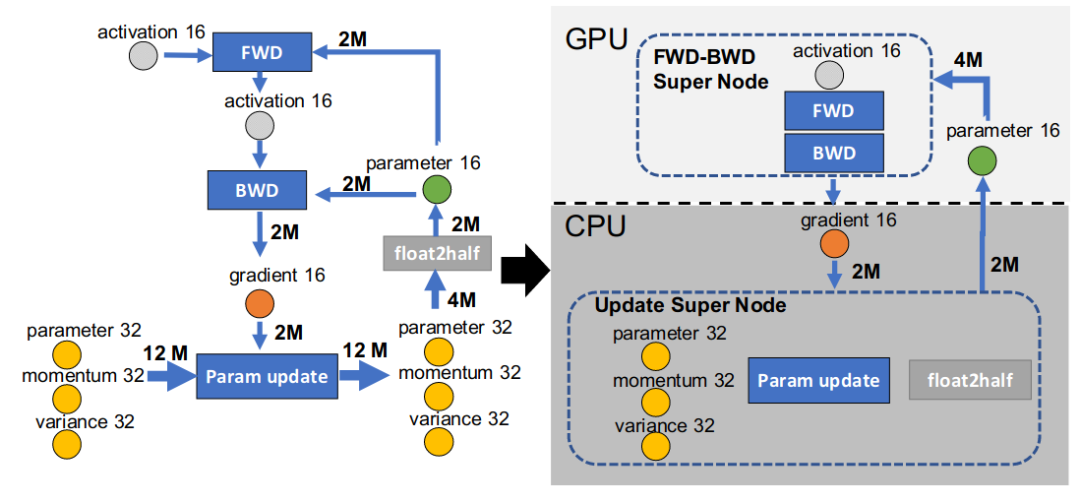
ZeRO-Offload[10] 技術(shù)主要思想是將部分訓(xùn)練階段的模型狀態(tài) offload 到內(nèi)存,讓 CPU 參與部分計(jì)算任務(wù)。
為了避免 GPU 和 CPU 之間的通信開(kāi)銷,以及 CPU 本身計(jì)算效率低于 GPU 這兩個(gè)問(wèn)題的影響。Offload 的作者在分析了 adam 優(yōu)化器在 fp16 模式下的運(yùn)算流程后,考慮只將模型更新的部分下放至 CPU 計(jì)算,即讓 CPU 充當(dāng) Parameter Server 的角色。如下圖所示:
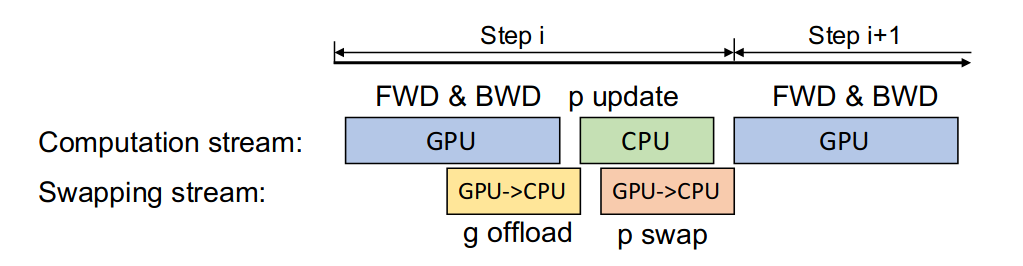
同時(shí)為了提高效率,Offload 的作者提出可以將通信和計(jì)算的過(guò)程并行起來(lái),以降低通信對(duì)整個(gè)計(jì)算流程的影響。
具體來(lái)說(shuō),GPU 在反向傳播階段,可以待梯度值填滿bucket后,一邊計(jì)算新的梯度一邊將bucket傳輸給CPU;當(dāng)反向傳播結(jié)束,CPU基本上獲取了最新的梯度值。同樣的,CPU在參數(shù)更新時(shí)也同步將已經(jīng)計(jì)算好的參數(shù)傳給GPU,如下圖所示:
最后作者也分析了多卡的情況,證明了他提出的方案具有可擴(kuò)展性。
Checkpoint 技術(shù)
在模型前向傳播的過(guò)程中,為了反向傳播計(jì)算梯度的需要,通常需要保留一些中間變量。例如對(duì)于矩陣乘法
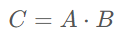
A和B的梯度計(jì)算公式如下所示
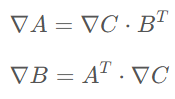
可以看出要想計(jì)算A和B的梯度就必須在計(jì)算過(guò)程中保留A和B本身。這部分為了反向傳播所保留的變量會(huì)占用不小的空間。Checkpoint技術(shù)的核心是只保留checkpoint點(diǎn)的激活值,checkpoint點(diǎn)之間的激活值則在反向傳播的時(shí)候重新通過(guò)前向進(jìn)行計(jì)算。可以看出,這是一個(gè)以算代存的折中方法。最早是陳天奇將這個(gè)技術(shù)引入機(jī)器學(xué)習(xí)中 [11]:
https://arxiv.org/abs/1604.06174
目前該方法也以及被 PyTorch 所支持。
https://pytorch.org/docs/stable/checkpoint.html
節(jié)約顯存的優(yōu)化器
比較早期的工作是如Adafactor[12] 主要是針對(duì) Adam 進(jìn)行優(yōu)化的,它取消了 Adam 中的動(dòng)量項(xiàng),并使用矩陣分解方法將動(dòng)量方差項(xiàng)分解成兩個(gè)低階矩陣相乘來(lái)近似實(shí)現(xiàn) Adam 的自適應(yīng)學(xué)習(xí)率功能。
后來(lái)也有使用低精度量化方式存儲(chǔ)優(yōu)化器狀態(tài)的優(yōu)化器,如8 bit Optimizer[13],核心思想是將優(yōu)化器狀態(tài)量化至 8 bit 的空間,并通過(guò)動(dòng)態(tài)的浮點(diǎn)數(shù)表示來(lái)降低量化的誤差。還有更加激進(jìn)的使用 1 bit 量化優(yōu)化器的方法,如1-bit Adam[14] 和1-bit LAMB[15]。他們主要是使用壓縮補(bǔ)償方法的來(lái)減少低精度量化對(duì)模型訓(xùn)練的影響。
三、其他優(yōu)化技術(shù):
大批量?jī)?yōu)化器
在目前模型訓(xùn)練的過(guò)程中,直接使用大批量的訓(xùn)練方式可能導(dǎo)致模型訓(xùn)練不穩(wěn)定。最早有 Facebook 的研究[16] 表明,通過(guò)線性調(diào)整學(xué)習(xí)率,并配合 warmup 等輔助手段,讓學(xué)習(xí)率隨 batch 的增大而線性增大,即可在ResNet-50上將 batch size 增大至 8K 時(shí)仍不影響模型性能。
但該方法在 AlexNet 等網(wǎng)絡(luò)失效,在LARS[17] 優(yōu)化器這篇論文中,作者尤洋在實(shí)驗(yàn)中發(fā)現(xiàn)不同層的權(quán)值和其梯度的 2 范數(shù)的比值差異很大,據(jù)此基于帶動(dòng)量的SGD優(yōu)化器提出LARS優(yōu)化器。核心算法如下圖所示:

基于以上的思路,尤洋將上述方法擴(kuò)展到Adam優(yōu)化器,提出了LAMB[18] 優(yōu)化器:

FP16
FP16[19] 基本原理是將原本的32位浮點(diǎn)數(shù)運(yùn)算轉(zhuǎn)為16位浮點(diǎn)數(shù)運(yùn)算。一方面可以降低顯存使用,另一方面在 NVIDIA 的顯卡上 fp16 的計(jì)算單元比 fp32 的計(jì)算單元多,可以提升計(jì)算效率。在實(shí)際的訓(xùn)練過(guò)程中,為了保證實(shí)際運(yùn)算過(guò)程中的精度,一般還會(huì)配合動(dòng)態(tài)放縮技術(shù)。目前的主流框架都已實(shí)現(xiàn)該功能。
算子融合
算子融合實(shí)際上是將若干個(gè) CUDA 上的運(yùn)算合成一個(gè)運(yùn)算,本質(zhì)上是減少了 CUDA 上的顯存讀寫次數(shù)。舉個(gè)例子,對(duì)于一個(gè)線性層 + batch norm + activation 這個(gè)組合操作來(lái)說(shuō):
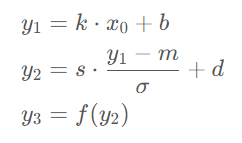
直接使用 PyTorch 實(shí)現(xiàn)的會(huì)在計(jì)算y1,y2,y3的過(guò)程中分別產(chǎn)生一次顯存的讀和寫操作,即3次讀和寫。如果將其按下面的公式合并成一個(gè)算子進(jìn)行計(jì)算,那么中間的結(jié)果可以保留在 GPU 上的寄存器或緩存中,從而將顯存讀寫次數(shù)降低至1次。
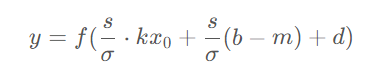
目前 PyTorch 可以使用 torch.jit.script 來(lái)將函數(shù)或 nn.Module 轉(zhuǎn)化成 TorchScript 代碼,從而實(shí)現(xiàn)算子融合。
https://pytorch.org/docs/stable/generated/torch.jit.script.html
設(shè)備通信算法
在之前介紹的模型分布式訓(xùn)練中,通常需要在不同 GPU 之間傳輸變量。在 PyTorch 的 DataParallel 中,使用的是Parameter Server架構(gòu),即存在一個(gè)中心來(lái)匯總和分發(fā)數(shù)據(jù):
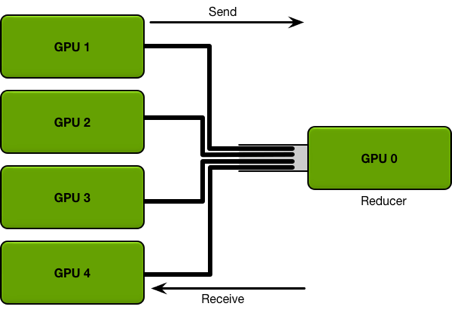
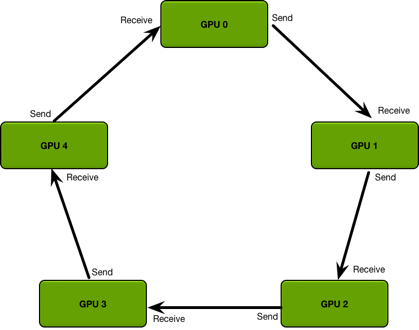
但上述方式的缺點(diǎn)是會(huì)導(dǎo)致 Parameter Server 成為通信瓶頸。之后PyTorch的Distributed DataParallel則使用了Ring All-Reduce[20] 方法,將不同的GPU構(gòu)成環(huán)形結(jié)構(gòu),每個(gè)GPU只用與環(huán)上的鄰居進(jìn)行通信:
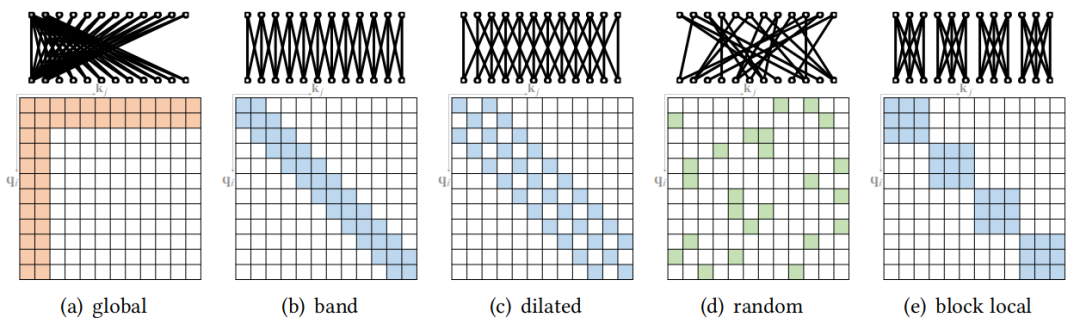
稀疏attention
稀疏Attention技術(shù)最開(kāi)始是運(yùn)用在長(zhǎng)序列的Transformer建模上的,但同時(shí)也能有效的降低模型計(jì)算的強(qiáng)度。稀疏Attention主要方法可以分為以下五類 [21]:
目前DeepSpeed已經(jīng)集成了這個(gè)功能:
https://www.deepspeed.ai/tutorials/sparse-attention/
自動(dòng)并行
目前并行訓(xùn)練技術(shù)在大模型訓(xùn)練中已被廣泛使用,通常是會(huì)將前面介紹的三種并行方法結(jié)合起來(lái)一起使用,被稱之為 3D 并行。
但這些并行方式都有不少的訓(xùn)練超參數(shù),之前的一些研究者是使用手動(dòng)的方式來(lái)設(shè)置這些超參數(shù)。目前也出現(xiàn)了不少自適應(yīng)的方法來(lái)設(shè)置超參數(shù),被稱為自動(dòng)并行技術(shù)。
這些方法包括動(dòng)態(tài)規(guī)劃、蒙特卡洛方法、強(qiáng)化學(xué)習(xí)等。下面的 GitHub 倉(cāng)庫(kù)整理了一些自動(dòng)并行的代碼和論文:
https://github.com/ConnollyLeon/awesome-Auto-Parallelism
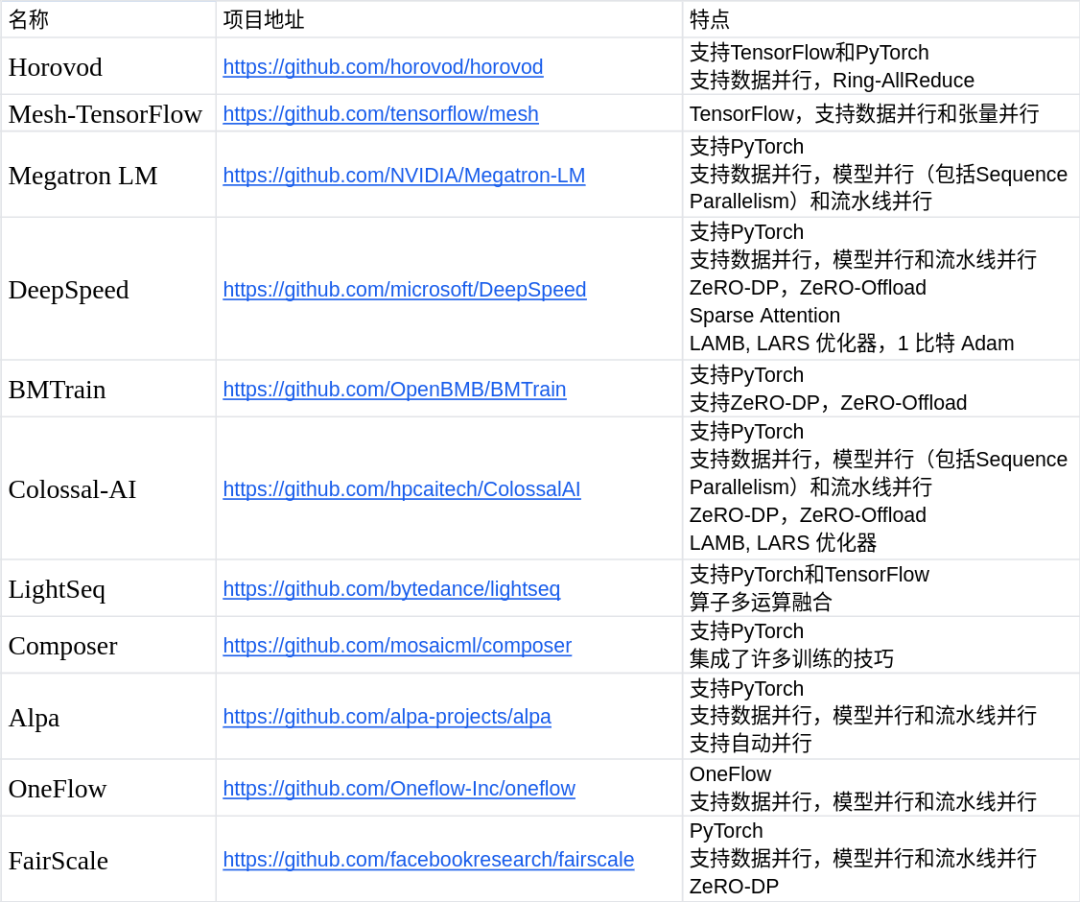
四、訓(xùn)練加速庫(kù)概覽
下面是本人對(duì)當(dāng)下比較流行的訓(xùn)練加速庫(kù)的統(tǒng)計(jì),可供大家進(jìn)行參考。
審核編輯:劉清
-
gpu
+關(guān)注
關(guān)注
28文章
4908瀏覽量
130619 -
GPT
+關(guān)注
關(guān)注
0文章
368瀏覽量
15919 -
MLP
+關(guān)注
關(guān)注
0文章
57瀏覽量
4480 -
大模型
+關(guān)注
關(guān)注
2文章
3020瀏覽量
3798
原文標(biāo)題:Huge and Efficient! 一文了解大規(guī)模預(yù)訓(xùn)練模型高效訓(xùn)練技術(shù)
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
如何在SAM時(shí)代下打造高效的高性能計(jì)算大模型訓(xùn)練平臺(tái)
芯耀輝DDR PHY訓(xùn)練技術(shù)簡(jiǎn)介
如何高效訓(xùn)練AI模型?這些常用工具你必須知道!
【大語(yǔ)言模型:原理與工程實(shí)踐】核心技術(shù)綜述
【大語(yǔ)言模型:原理與工程實(shí)踐】大語(yǔ)言模型的基礎(chǔ)技術(shù)
【大語(yǔ)言模型:原理與工程實(shí)踐】大語(yǔ)言模型的預(yù)訓(xùn)練
Pytorch模型訓(xùn)練實(shí)用PDF教程【中文】
醫(yī)療模型人訓(xùn)練系統(tǒng)是什么?
如何進(jìn)行高效的時(shí)序圖神經(jīng)網(wǎng)絡(luò)的訓(xùn)練
基于速度追蹤原理實(shí)現(xiàn)目標(biāo)模擬訓(xùn)練系統(tǒng)的設(shè)計(jì)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論