") RDMA RoCEv2、AWS SRD/EFA和阿里云HPCC
RDMA RoCEv2、AWS SRD/EFA和阿里云HPCC
編者按:
本文是《軟硬件融合——超大規(guī)模云計算架構創(chuàng)新之路》圖書內容的節(jié)選。云計算系統(tǒng)持續(xù)解構,東西向網絡流量激增,服務器堆棧延遲問題凸顯。要想提升數(shù)據(jù)中心網絡性能,大體上通過如下措施:
(1)網絡容量升級,例如整個網絡從25Gbps升級到100Gbps;
(2)輕量協(xié)議棧,數(shù)據(jù)中心網絡是局域網絡,距離短/延遲敏感,不需要復雜的用于全球互聯(lián)的TCP/IP協(xié)議棧;
(3)網絡協(xié)議處理硬件加速;
(4)高性能軟硬件交互:高效交互協(xié)議 + PMD + PF/VF/MQ;
(5)擁塞控制:低延遲、高可靠性(低性能抖動)、高網絡利用率。
案例:RDMA RoCEv2、AWS SRD/EFA和阿里云HPCC。
1 高速網絡接口RDMA/RoCEv2
RDMA是一整套高性能網絡傳輸技術的集合,不僅僅是軟件和硬件的接口。RDMA的軟件和硬件接口,并沒有形成如同存儲NVMe那樣非常嚴格的標準。本節(jié)通過RDMA以及RoCEv2的相關介紹,使大家對高性能網絡傳輸接口以及協(xié)議棧有個整體的認識。
1.1 基本概念
RDMA(Remote Direct Memory Access,遠程直接內存訪問)是一種高帶寬、低延遲、低CPU消耗的網絡互聯(lián)技術,克服了傳統(tǒng)TCP/IP網絡的許多困難。RDMA技術體現(xiàn)在:
Remote(遠程):數(shù)據(jù)在網絡中的兩個節(jié)點之間傳輸。
Direct(直接):不需要內核參與,傳輸?shù)乃刑幚矶夹遁d到NIC硬件中完成。
Memory(內存):數(shù)據(jù)直接在兩個節(jié)點的應用程序的虛擬內存間傳輸;不需要額外的復制和緩存。
Access(訪問):訪問操作有send/receive、read/write等。
如圖1,RoCE(RDMA over Converaged Ethernet)v1是基于現(xiàn)有Ethernet網絡實現(xiàn)RDMA的一項技術。RoCEv1允許在現(xiàn)有以太網基礎上實現(xiàn)RDMA技術,實現(xiàn)接近InfiniBand的性能和延遲指標,但不需要將現(xiàn)有網絡基礎設施升級成昂貴的InfiniBand,節(jié)約了大量的支出。RoCEv2基于標準網絡的以太網(Ethernet PHY/MAC)、網絡層(IP)和傳輸層(UDP)協(xié)議,這可以使得RoCEv2的網絡流量可以經過傳統(tǒng)的網絡路由器路由。
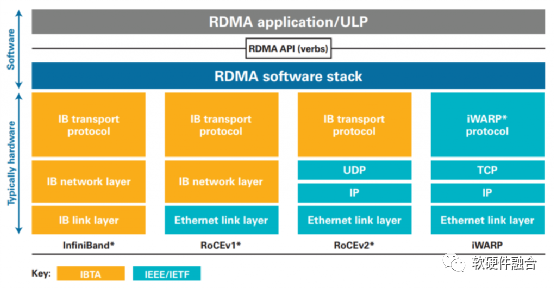
圖1 RDMA所使用的InfiniBand、RoCEv1/v2、iWARP技術對比
1.2 RoCE分層
RoCEv2是當前數(shù)據(jù)中心比較流行的RDMA技術,我們以RoCEv2為例,介紹RoCE的系統(tǒng)分層。
如圖2所示,RoCEv2自下而上分為:
以太網層:標準的Ethernet協(xié)議,即網絡五層協(xié)議物理層和數(shù)據(jù)鏈路層。
網絡層(IP):即網絡五層協(xié)議中的網絡層。
傳輸層(UDP):即網絡五層協(xié)議中的傳輸層(選用UDP協(xié)議而不是TCP協(xié)議)。
IB傳輸層(Transport Layer):IB傳輸層負責數(shù)據(jù)包的分發(fā)、分割、通道復用和傳輸服務。接收方會確認數(shù)據(jù)包,然后把確認信息發(fā)動到發(fā)送方,發(fā)送方會根據(jù)這些確認信息更新完成隊列。
RDMA硬件數(shù)據(jù)引擎層(Data Engine Layer):負責內存隊列和RDMA硬件之間工作/完成請求的數(shù)據(jù)傳輸?shù)取?/p>
RDMA接口驅動層:負責RDMA硬件的配置管理,負責隊列和內存的管理,負責工作請求添加到工作隊列中,負責完成請求的處理等。
Verbs API層:接口驅動的封裝。管理連接狀態(tài)、管理內存和隊列訪問、提交工作給RDMA硬件、從RDMA硬件獲取工作和事件。
ULP層:OFED ULP(Upper Layer Protocol,上層協(xié)議)軟件庫,提供了各種軟件協(xié)議的RDMA verbs支持,讓上層應用可以無縫移植到RDMA平臺。
應用層:分為兩類,RDMA原生的應用,基于RDMA verbs API開發(fā);另外,OFA提供了可以無縫兼容已有應用的OFED協(xié)議棧,讓已有的應用可以無縫的使用RDMA功能。
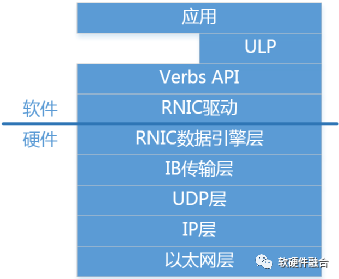
圖2 RoCEv2分層
1.3 RDMA接口
RDMA并沒有約束嚴格的軟硬件接口,各家的實現(xiàn)各有不同,只需要支持RDMA的隊列機制即可。Verbs API則是開源的標準的接口,具體的軟硬件接口實現(xiàn)需要通過驅動對接到Verbs API。
a.RDMA工作隊列
軟件驅動和硬件設備的交互通常基于生產者消費者模型,這樣能夠實現(xiàn)異步的交互,實現(xiàn)軟件和硬件的解耦。RDMA接口中驅動和設備的交互也是如此,RDMA軟硬件共享的隊列數(shù)據(jù)結構稱為工作隊列(Work Queue)。
如圖3所示,工作隊列是軟件驅動和硬件RDMA交互的共享Queue。驅動負責把工作請求(Work Request)添加到工作隊列,成為工作隊列中的一項,稱為工作隊列項(Work Queue Element)。RDMA硬件設備會負責WQE在內存和硬件之間的傳輸,并且通過RDMA網絡最終把WQE送到接收方的工作隊列中去。最后,接收方RDMA硬件會反饋確認信息給到發(fā)送方RDMA硬件,發(fā)送方RDMA硬件會根據(jù)確認信息生成完成隊列項(Completion Queue Element)發(fā)送到內存的完成隊列(Completion Queue)。
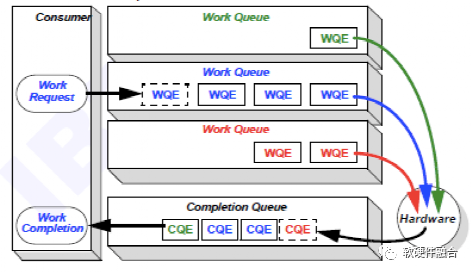
圖3 RDMA數(shù)據(jù)傳輸模型——工作隊列
RDMA Queue類型有:
發(fā)送隊列(Send Queue):用于發(fā)送數(shù)據(jù)消息。
接收隊列(Receive Queue):用于接收輸入的數(shù)據(jù)消息。
完成隊列(Completion Queue):完成隊列主要是用于實現(xiàn)RDMA操作異步的實現(xiàn)。
隊列對(Queue Pair):發(fā)送隊列和接收隊列組成一組隊列對。
b.Verbs API操作
RDMA Verbs是提供給應用程序使用的最底層的RDMA功能抽象,RoCEv2中的Verbs操作主要有兩類:
Send/Recv。類似于Client/Server結構,發(fā)送操作和接收操作協(xié)作完成,在發(fā)送方連接之前,接收方必須處于偵聽狀態(tài);發(fā)送方不知道接收方的虛擬內存位置,接收方也不知道發(fā)送方的虛擬內存地址。不同的是RDMA Send/Recv因為是直接對內存操作,因此需要提前注冊用于傳輸?shù)膬却鎱^(qū)域。
Write/Read。與Client/Server架構不同,Write/Read是請求方處于主動,響應方處于被動。請求方執(zhí)行Write/Read操作,響應方不需要做任何操作。為了能夠操作響應方的內存,請求方需要提前獲得響應方的地址和鍵值。
1.4 RDMA總結
計算機網絡中的通信延遲主要是指:處理延遲和網絡傳輸延遲。處理延遲開銷指的就是消息在發(fā)送和接收階段的處理時間。網絡傳輸延遲指的就是消息在發(fā)送和接收之間的網絡中傳輸?shù)臅r間。在通常的南北向網絡流量場景,基本都是遠距離傳輸,網絡傳輸延遲占了絕大部分,因此處理延遲問題并沒有凸顯。
隨著云計算技術的發(fā)展,需要頻繁的在集群服務器之間傳遞數(shù)據(jù)流量,數(shù)據(jù)中心中的東西向網絡流量激增。在數(shù)據(jù)中心的短距離傳輸下,網絡傳輸延遲大幅度縮小,處理延遲問題開始凸顯。另外,東西向流量本身就是流量大、延遲敏感的應用場景,這要求進一步的優(yōu)化處理延遲。如圖4,RDMA不僅僅是一種高效的用于數(shù)據(jù)傳輸?shù)能浻布涌冢且环N通過硬件實現(xiàn)網絡數(shù)據(jù)傳輸加速的軟硬件整體解決方案。
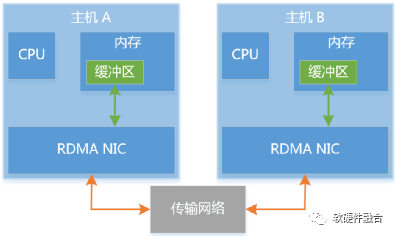
圖4 RDMA傳輸模型
跟傳統(tǒng)的TCP/IP網絡技術相比,RDMA技術的優(yōu)勢體現(xiàn)在:
更高效的協(xié)議棧:InfiniBand相比傳統(tǒng)的TCP/IP網絡協(xié)議棧更加高效,RoCEv2使用了UDP,相比TCP更高效一些。因為是用于局域網的數(shù)據(jù)傳輸,數(shù)據(jù)的丟包率會低很多,UDP有更優(yōu)的性能。
協(xié)議棧硬件卸載:整個RDMA協(xié)議棧處理完全由硬件完成,進一步提升性能,并且降低CPU資源消耗。
直接內存操作:內存一旦注冊,數(shù)據(jù)就可以直接在內存和內存之間拷貝,不需要經過內核協(xié)議棧層的發(fā)送接收方各一次的拷貝;
操作系統(tǒng) Bypass:沒有了內核協(xié)議棧,用戶空間驅動直接繞過內核,減少了操作系統(tǒng)模式切換的開銷;
異步操作:一次事務操作分為發(fā)送Request(請求)和接收Completion(完成),這樣就不會阻塞傳輸。
2 高性能網絡優(yōu)化
在基礎網絡、硬件加速以及網絡接口都確定的情況下,為了更充分的利用網絡容量,達到網絡的高性能的同時防止性能抖動,就需要進行網絡擁塞控制。
a.網絡擁塞控制簡介
網絡中如果存在太多的數(shù)據(jù)包,會導致數(shù)據(jù)包的延遲,并且會因為超時而丟失,從而降低了傳輸性能,這種情況稱為擁塞(Congestion) 。高性能網絡非常重要的一個方面,就是在充分利用網絡容量,提供低延遲網絡傳輸?shù)耐瑫r,盡可能的避免網絡擁塞。
如圖5(a)所示,當主機發(fā)送到網絡的數(shù)據(jù)包數(shù)量在其承載能力范圍之內時,送達的數(shù)據(jù)包數(shù)與發(fā)送的數(shù)據(jù)包數(shù)成正比例增長。隨著負載接近網絡承載能力,偶爾突發(fā)的網絡流量會導致?lián)砣罎ⅰH鐖D 8.16(b)所示,為加載的數(shù)據(jù)包和延遲的函數(shù)關系,可以看到,當加載的數(shù)據(jù)包增加到接近承載上限的時候,其延遲時間是急劇上升的。
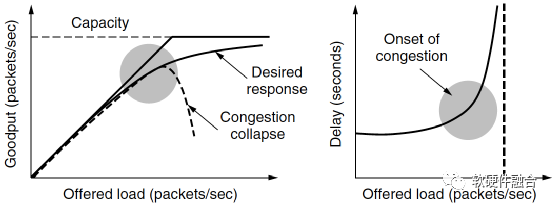
(a) 實際吞吐率的擁塞崩潰 (b) 延遲成指數(shù)上升
圖5 網絡擁塞導致的吞吐率和延遲問題
說明:擁塞控制和流量控制不是一回事:擁塞控制的目標是確保網絡能夠承載所有到達的流量,這是一個全局性的問題;相對的,流量控制只與特定的發(fā)送方和特定的接收方之間的點到點流量有關,流量控制的目標是確保一個快速的發(fā)送方不會持續(xù)地以超過接收方接收能力的速率傳輸數(shù)據(jù)。
針對擁塞所采取的辦法有很多種,根據(jù)解決方案效果的從慢到快,介紹如下:
避免擁塞的最基本方法是建立一個與流量匹配的網絡,需要根據(jù)流量的利用率增長趨勢提前升級網絡;
充分利用現(xiàn)有網絡容量,根據(jù)不同時刻的流量模式度身定制路由,這稱為流量感知的路由;
增加網絡容量需要時間,因此解決擁塞的最直接的辦法就是降低負載。比如拒絕新連接的建立,這稱為準入控制;
當擁塞即將到來前,網絡可以給造成擁塞問題的源端傳遞反饋信息,要求源端抑制它們的流量;
當一切努力均失敗,網絡不得不丟棄它無法傳遞的數(shù)據(jù)包,這稱為負載脫落。
擁塞控制算法的目標是:
更加易于避免擁塞,即找到一種優(yōu)化的帶寬分配方法。一個優(yōu)化的帶寬分配方法能帶來更好的性能,因為它能充分利用所有的可用帶寬卻能避免擁塞;
并且,此帶寬分配算法對于所有傳輸是公平的,既能保證大流量數(shù)據(jù)流的快速傳輸,又能保證小流量數(shù)據(jù)流的及時傳輸;
最后,擁塞控制算法能夠快速收斂到公平高效的帶寬分配。
b.阿里云HPCC,RDMA擁塞控制優(yōu)化
在過去的十年中,數(shù)據(jù)中心網絡的端口帶寬已從1 Gbps增長到100 Gbps,并且這種增長還在持續(xù)。越來越多的應用程序要求更低的延遲和更高的帶寬,在數(shù)據(jù)中心,有兩個重要的趨勢驅動著對高性能網絡的需求:
第一個趨勢是新的數(shù)據(jù)中心架構。例如資源解構和異構計算:在資源解構中,CPU需要與GPU、內存和磁盤等遠程資源進行高速網絡互聯(lián);在CPU和加速器解構的異構計算環(huán)境中,不同的計算芯片也需要(通過網絡)高速互連,并且延遲越小越好。
第二個趨勢是新的應用程序。例如運行于高速IO介質(如NVMe)上的存儲,以及在GPU和ASIC之類的加速計算設備上進行大規(guī)模機器學習訓練。這些應用程序會定期的傳輸大量數(shù)據(jù),其存儲和計算速度非常快,性能的瓶頸通常是網絡傳輸。
傳統(tǒng)的基于軟件的網絡堆棧不再能夠滿足關鍵的延遲和帶寬要求,將網絡堆棧卸載到硬件中是高速網絡中的必然方向。在數(shù)據(jù)中心中的部署RoCEv2,通過RDMA進行網絡傳輸,是當前主要的硬件卸載解決方案。不幸的是,大規(guī)模的RDMA網絡在平衡低延遲、高帶寬利用率和高穩(wěn)定性方面面臨根本的挑戰(zhàn)。經典的RDMA擁塞機制,例如DCQCN和TIMELY算法,具有一些局限性:
收斂緩慢。對于粗粒度的反饋,例如ECN(Explicit Congestion Notification,顯式擁塞通知)或RTT(Round-Trip Time,傳輸往返時間),擁塞方案無法確切知道增加或降低發(fā)送速率的程度,使用啟發(fā)式方法推測速率更新,迭代收斂到穩(wěn)定的速率。
不可避免的數(shù)據(jù)包排隊。DCQCN利用ECN標記來判斷擁塞風險,TIMELY使用RTT增加來檢測擁塞。兩個算法都是在隊列建立后,發(fā)送方才開始降低流量,這些堆積的隊列會大大增加網絡延遲。
復雜的參數(shù)調整。例如,DCQCN有15個參數(shù)可以調整,操作員在日常RDMA網絡維護中要面對復雜且耗時的參數(shù)調整,這會大大增加配置錯誤的風險,這些錯誤配置會導致不穩(wěn)定或性能下降。
HPCC(High Precision Congestion Control,高精度擁塞控制)背后的關鍵思想是利用INT(In-Network Telemetry,網絡內遙測)提供的精確的鏈路負載信息來計算準確的流量更新,HPCC在大多數(shù)情況下僅需要一個速率更新步驟。HPCC發(fā)送方可以快速提高流量以實現(xiàn)高利用率,或者降低流量以避免擁塞;HPCC發(fā)送者可以快速調整流量,以使每個鏈接的輸入速率略低于鏈接的容量,保持高鏈接利用率;由于發(fā)送速率是根據(jù)交換機直接測量的結果精確計算得出的,HPCC僅需要3個獨立參數(shù)即可調整公平性和效率。
如圖6,HPCC實現(xiàn)為由發(fā)送者驅動的擁塞控制框架。接收方確認發(fā)送方發(fā)送的每個數(shù)據(jù)包。數(shù)據(jù)包從發(fā)送方傳輸?shù)浇邮辗降倪^程中,路徑上的每個交換機都利用INT功能插入一些元數(shù)據(jù),這些數(shù)據(jù)報告了數(shù)據(jù)包出口的當前負載。當接收方收到數(shù)據(jù)包后,它將所有的元數(shù)據(jù)復制到ACK消息中。發(fā)送方根據(jù)ACK信息決定如何調整流量。
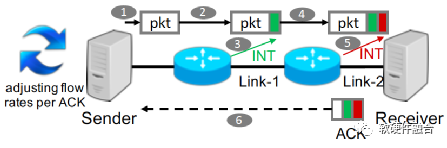
圖6 HPCC框架示意圖
圖7為基于FPGA可編程NIC上的HPCC實現(xiàn),NIC提供了一個FPGA芯片,并且用了基礎的PCIe以及MAC模塊,PCIe連接到主機內存,MAC模塊連接到以太網。HPCC模塊位于PCIe和MAC之間,實現(xiàn)發(fā)送方和接收方的角色。擁塞控制(CC)模塊實現(xiàn)了發(fā)送方擁塞控制算法,它接收RX方向返回的ACK信息,根據(jù)這些信息調整發(fā)送窗口和速率,并且更新新的發(fā)送窗口和速率到流量調度器。
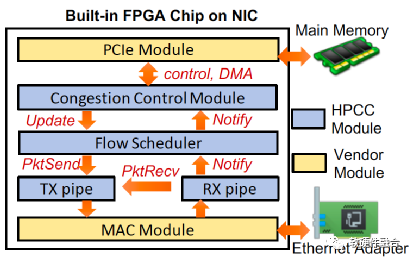
圖7 支持HPCC的FPGA NIC實現(xiàn)
通過測試平臺實驗和大規(guī)模仿真,與DCQCN、TIMELY等方案相比,HPCC對可用帶寬和擁塞的反應更快,并保持接近零的隊列。在32臺服務器測試平臺中,在50%的流量負載下HPCC在中位數(shù)保持隊列大小為零,當負載達到99%的情況下,隊列大小為22.9KB(僅需要7.3μs的排隊延遲)。與DCQCN相比,它使99%負載情況下的延遲減少了95%,而不會犧牲吞吐量。在320臺服務器的測試中,即使DCQCN和TIMELY方案頻繁發(fā)生PFC(Priority Flow Control,基于優(yōu)先級的流量控制)風暴的情況下,HPCC也不會觸發(fā)PFC暫停。
c.AWS的SRD和EFA
EFA(Elastic Fabric Adapter,彈性互聯(lián)適配器)是AWS EC2實例的一種網絡接口,EFA性能改進主要通過三項關鍵技術:
應用程序繞過操作系統(tǒng)內核直接與硬件對話,這提高了應用程序性能的穩(wěn)定性;
持續(xù)開發(fā)和調整ENA和設備驅動程序以適應新的高帶寬實例類型;
新的以云為中心的可靠性協(xié)議層,稱為SRD(Scalable Reliable Datagram,可擴展可靠數(shù)據(jù)報)。
如圖8,EFA定制的操作系統(tǒng)旁路硬件接口增強了實例間通信的性能。借助EFA,使用消息傳遞接口(MPI)的高性能計算(HPC)應用程序和使用NVIDIA集體通信庫(NCCL)的機器學習(ML)應用程序可以擴展到數(shù)千個CPU或GPU,并且,將獲得本地HPC集群的應用程序性能以及AWS云的按需彈性和靈活性。
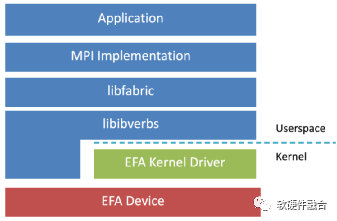
圖8 基于EFA的HPC網絡協(xié)議棧
SRD是專為AWS設計的可靠的、高性能的、低延遲的網絡傳輸。這是數(shù)據(jù)中心網絡數(shù)據(jù)傳輸?shù)囊淮沃卮蟾倪M,已實現(xiàn)為AWS第三代NITRO芯片的一個重要功能。SRD受InfiniBand可靠數(shù)據(jù)報的啟發(fā),與此同時,考慮到大規(guī)模的云計算場景下的工作負載,SRD也經過了很多的修改和改進。SRD利用了云計算的資源和特點(例如AWS的復雜多路徑主干網絡)來支持新的傳輸策略,為其在緊耦合的工作負載中發(fā)揮價值。SRD的主要功能包括:
亂序交付:取消按順序傳遞消息的約束,消除了行首阻塞,AWS在EFA用戶空間軟件堆棧中實現(xiàn)了數(shù)據(jù)包重排序處理引擎。
等價多路徑路由(ECMP):兩個EFA實例之間可能有數(shù)百條路徑,使用大型多路徑網絡的一致性流哈希的屬性,以及SRD對網絡狀況的快速反應能力,找到消息的最有效路徑。數(shù)據(jù)包噴涂(Packet Spraying)可防止擁塞熱點,并可以從網絡故障中快速而無感地恢復。
快速的丟包響應:SRD對丟包的響應比任何高層級的協(xié)議都快得多。偶爾的數(shù)據(jù)包丟失是正常網絡操作的一部分,這不是異常情況。
可擴展的傳輸卸載:使用SRD,與其他可靠協(xié)議(如InfiniBand可靠連接IBRC)不同,一個進程可以創(chuàng)建并使用一個隊列對與任何數(shù)量的對等方進行通信。
表1為SRD和TCP、InfiniBand網絡的功能特征對比:
表1 TCP、InfiniBand以及SRD的特征比較
| TCP | Infiniband | SRD |
| 基于流 | 基于消息 | 基于消息 |
| 順序 | 順序 | 亂序 |
| 單路徑 | 單(ish)路徑 | 負載均衡的ECMP噴涂 |
| 很長的重傳超時(>50ms) |
靜態(tài)的用戶配置超時 (對數(shù)規(guī)模) |
動態(tài)估算的超時 (μs的精度) |
| 基于丟包率的擁塞控制 |
半靜態(tài)的速率限制 (支持的速率有約束的設置) |
動態(tài)速率限制 |
| 低效的軟件棧 | 受規(guī)模約束的傳輸卸載 |
可擴展的傳輸卸載 (相同數(shù)量的隊列對,與集群大小無關) |
如圖9所示,EFA非常明顯的提高了帶寬利用率(接近于線速100 Gbps),同時還明顯的減少單數(shù)據(jù)包延遲,并且基于SRD的鏈接失效的處理,其性能抖動也變得非常的小。
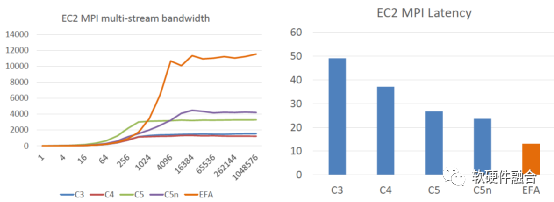
(a) EFA的帶寬性能對比 (b) EFA的延遲性能對比
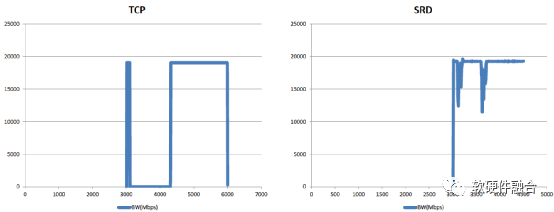
(c) SRD與TCP的性能抖動對比
圖9 EFA/SRD的HPC性能
審核編輯 :李倩
-
服務器
+關注
關注
13文章
9686瀏覽量
87280 -
協(xié)議棧
+關注
關注
2文章
145瀏覽量
34012 -
AWS
+關注
關注
0文章
435瀏覽量
25087
原文標題:高性能網絡及優(yōu)化:RDMA/RoCEv2、AWS SRD & Aliyun HPCC
文章出處:【微信號:阿寶1990,微信公眾號:阿寶1990】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
RDMA簡介3之四種子協(xié)議對比
RDMA簡介2之A技術優(yōu)勢分析
RDMA簡介1之RDMA開發(fā)必要性
阿里云爆發(fā)式的跨越

阿里云個人電腦,阿里云個人電腦的特點
阿里云官網電腦版,阿里云電腦版的下載使用教程

Arm與AWS合作深化,AWS Graviton4展現(xiàn)顯著進展
阿里云代理有哪些?
Forrester公有云評估:阿里云全球排名第二
串口服務器NE2-T1M接入阿里云教程

IEC104轉MQTT網關支持Zabbix、阿里云、華為云、亞馬遜AWS、ThingsBoard、Ignition





 工商網監(jiān)
工商網監(jiān)
評論