 GPU引擎增強了超聲檢測到的大腦運動計算
GPU引擎增強了超聲檢測到的大腦運動計算
多普勒超聲是一種醫學超聲模式,用于觀察沿超聲探頭發出的軸或由此類探頭掃描的平面區域的運動。雖然多普勒超聲通常用于檢查血流,但它也可用于檢測組織微搏。這種組織脈動起源于低速血液灌注,其周期性且與每次心跳同步。研究人員報告了亞微米水平的運動敏感性。了解這些腦組織脈動可能有助于識別大腦中的出血或缺血(缺乏血流)。
測量組織位移
科學家經常使用換能器來發射和檢測高頻聲波。將高壓發射脈沖施加到換能器內部的壓電晶體上,以產生短脈沖的超聲波能量。當這種超聲波脈沖在組織中傳播時,它會遇到不同組織結構之間的界面。在這些結點處,超聲波脈沖中的一些能量被反射為回聲,而另一些則繼續傳播到組織更深處。每個波分量的相對大小是組織之間聲阻抗不匹配程度的函數。具有相似成分的組織區域具有低程度的不匹配,因此允許更多的超聲脈沖穿透更深。
在這項研究中,我們使用2 MHz超聲波來檢查大腦。這個頻率足夠低,可以穿透顱骨,但又足夠高,可以提供來自血流和組織的容易檢測到的回聲。2 MHz處的波長(λ)約為0.8 mm,這比我們觀察到的組織運動大一個數量級以上。識別隨時間推移的相位變化允許在微米級用該波長檢測組織運動。π的相變導致多普勒樣品體積的位移為λ/4,或約0.2 mm。可以輕松完成分辨率為 π/1,000 的角度測量,從而產生等于或低于微米的位移分辨率。
本應用中使用的系統工作在2 MHz載波頻率和以6.25 kHz脈沖重復頻率發射的八周期發射突發。透射脈沖串尺寸導致軸向分辨率(樣品體積)約為3 mm。軸向分辨率不應與上一段中討論的位移計算的角度分辨率混淆。當超聲波脈沖在組織中傳播時,它跟蹤散射體的運動。重要的是,樣品體積尺寸不能與獨立移動的組織元件的大小不匹配;否則,多個移動組織單元可能導致凈位移為零。此外,由于散射體在一組超聲脈沖中的去相關,小樣品體積中的大組織偏移將產生不確定性。
每個脈沖重復周期的多普勒頻移信號是通過放大接收到的回波并使用16位A/D轉換器以32 MSps的速度將其數字化,然后在現成的DSP卡(TigerSHARC引擎)中解調和抽取來獲得的。因此,每個脈沖周期從 5,120 個回波樣本開始,并轉換為 320 個解調的 IQ 值,以 0.4 mm 的間隔均勻分布(即載波的 λ/2)。然后將這 320 個 IQ 值重新采樣到 64 個 IQ 樣本中,這些樣本以 1.1 mm 的間隔對 20 至 90 mm 的深度范圍進行分層。以這種方式,在每個柵極深度以6.250 kHz的頻率對復雜的多普勒頻移信號進行采樣。
64 個門中每個門的局部大腦運動都是通過夾克在 MATLAB 中通過夾克使用具有夾克數據類型的 NVIDIA GTX 280 顯卡計算的。位移由使用公式1計算的IQ信號的未包裝瞬時相位推導出來。等式2捕獲了相位和位移之間的關系。
等式 1
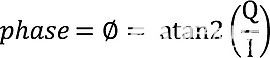
等式 2
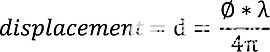
圖1所示的16個門以4.5 mm的間隔距離探頭20至90 mm。這些門是64個樣品門的子集,每個門都處理成位移波形。圖1中的所有位移波形共享一個公共x軸,該軸以秒為單位表示時間。y 軸以微米為單位顯示每條曲線的局部位移大小。
圖 1:隨著時間的推移,可以使用2 MHz超聲束檢測大腦位移,并通過夾克在MATLAB中計算。
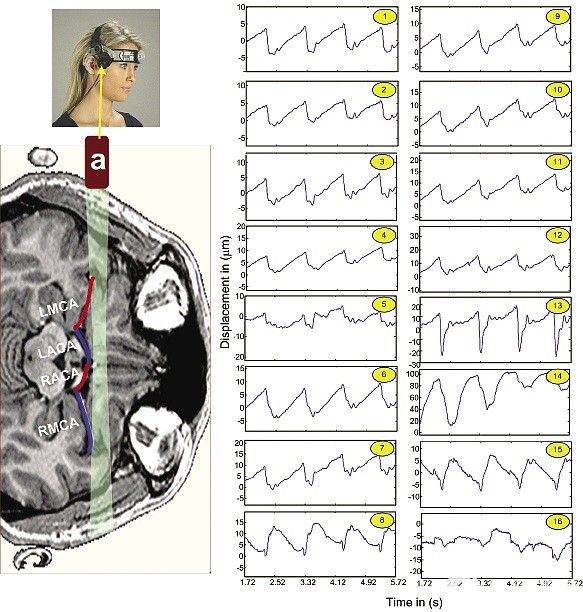
圖1的左上角顯示了Marc 600頭架,該頭架將換能器(a)牢固地放置在進入大腦的時間聲學窗口上。換能器顯示在典型大腦的MRI圖像旁邊,并疊加了與超聲束路徑相鄰的主要前動脈路徑的描繪。從威利斯環分支的動脈包括右中動脈(RMCA),右前腦動脈(RACA),左前腦動脈(LACA)和左中腦動脈(LMCA)。右側顯示了距離探頭20至90 mm的多普勒門的位移波形(在y軸處以微米為單位)與時間(在x軸處以秒為單位)。
這些腦移位圖具有很強的心臟周期存在。這些曲線還顯示位移值低至20微米,用于在舒張末期和收縮期峰值后不久測量的總偏移量。(請注意,心臟在舒張期放松,在收縮期泵血。隨著每個心臟周期,大腦通常從收縮期開始沿一個方向移位,然后從收縮期結束時向相反方向移動。在任何給定時間內觀察所有深度,都會顯示具有不同大小的正位移和負位移值,表明心臟周期中組織運動的異質性。
計算性能的基礎
本研究中使用的 GTX 280 GPU 具有 1 GB 的片上 RAM 和 240 個處理內核,能夠處理 1,000 個 GFLOPS。對于此應用,我們將數據分成 64 個多普勒門乘以 2 秒數據矩陣,從而得到 64 x 12,800 個復雜數據值的輸入矩陣。在使用 MATLAB 的 CPU 和使用夾克進行比較的 GPU 中計算位移(使用等式 1 和 2)。報告的計時測量結果在50項試驗中取平均值。
平均而言,GPU 在 51.50 毫秒內計算出位移,而 CPU 在 621.5 毫秒內執行計算。憑借其高度并行的架構,GPU 的性能比 CPU 高出 12 倍。梳理GPU計時測量結果進一步顯示,CPU和GPU之間的內存傳輸需要41毫秒(總時間的80%),而實際計算只需要10.5毫秒(總時間的20%)。
在使用 Jacket 和 GPU 技術獲得積極成果后,我們預計該軟件將為遠遠超過最先進的 DSP 性能的計算性能奠定基礎。該特征對于實時處理組織微脈搏作為深度函數至關重要,這是我們研究的基本目標。我們還希望使用Creack軟件將提高我們以有效方式設計和測試算法的能力,并有助于降低開發成本。
審核編輯:郭婷
-
轉換器
+關注
關注
27文章
8961瀏覽量
150771 -
gpu
+關注
關注
28文章
4912瀏覽量
130673
發布評論請先 登錄
GPU架構深度解析

為什么無法檢測到OpenVINO?工具套件中的英特爾?集成圖形處理單元?
OpenVINO?檢測到GPU,但網絡無法加載到GPU插件,為什么?
Aigtek功率放大器如何驅動超聲電機導軌運動

GPU加速計算平臺的優勢
GPU云計算服務怎么樣
【新品體驗】幸狐Omni3576邊緣計算套件免費試用
澎峰科技計算軟件棧與沐曦GPU完成適配和互認證
《CST Studio Suite 2024 GPU加速計算指南》
TDC1000是否對超聲換能器有要求?
使用 AMD Versal AI 引擎釋放 DSP 計算的潛力
GPU計算主板學習資料第735篇:基于3U VPX的AGX Xavier GPU計算主板 信號計算主板 視頻處理 相機信號
從檢測到信賴:一步步了解運動音響如何通過氣密性檢測儀贏得市場

VL53L8CX TOF開發(5)----運動閾值檢測






 工商網監
工商網監
評論