 一文詳解百度、谷歌、京東、騰訊在分布式網絡訓練下的聯邦學習解決方案
一文詳解百度、谷歌、京東、騰訊在分布式網絡訓練下的聯邦學習解決方案
隨著機器學習、隱私計算、高性能計算、深度學習訓練、差分隱私的快速發展,如今的人工智能仍然面臨兩大挑戰。一是在大多數行業中,數據以孤島的形式存在;另一個是加強數據隱私和安全。為這些挑戰提出了一個可能的解決方案:安全聯邦學習。其中包括橫向聯邦學習、縱向聯邦學習和聯邦遷移學習。
聯邦學習(Federated Learning)是一種分布式機器學習技術,其核心思想是通過在多個擁有本地數據的數據源之間進行分布式模型訓練,在不需要交換本地個體或樣本數據的前提下,僅通過交換模型參數或中間結果的方式,構建基于虛擬融合數據下的全局模型,從而實現數據隱私保護和數據共享計算的平衡,即“數據可用不可見”、“數據不動模型動”的應用新范式。許多客戶端(例如移動設備或整個組織)在中央服務器(例如服務提供商)的編排下協同訓練一個模型,同時保持訓練數據的分散。聯邦學習體現了集中數據收集和最小化的原則,可以減輕許多由傳統的、集中的機器學習和數據科學方法造成的系統性隱私風險和成本。
聯邦學習涉及在大規模分布式網絡中訓練機器學習模型。雖然聯合平均(fedavg)是在此設置中訓練非凸模型的主要優化方法,但在跨統計異構設備(即每個設備以非相同的時尚。眾所周知的 fedprox 框架來解決統計異質性,它包含了 fedavg 作為一個特例。通過一種新穎的設備相異性假設為 fedprox 提供收斂保證,能夠表征網絡中的異質性,最后,對一套聯合數據集進行了詳細的實證評估,證明了廣義 fedprox 框架相對于 fedavg 在異構網絡中學習的魯棒性和穩定性有所提高。
聯邦學習科研論文成果現狀
一、論文發表量復合年增長率為 40%
基于 AMiner 系統,通過關鍵詞組在標題和摘要中檢索 2016 年至 2021 年論文數據。結果顯示,研究時段內聯邦學習相關論文共計 4576 篇, 自 2016 年被提出以來,研究論文數量逐年增多, 到 2021 年的復合年增長率為 40.78%,相關論文趨勢如下圖所示。
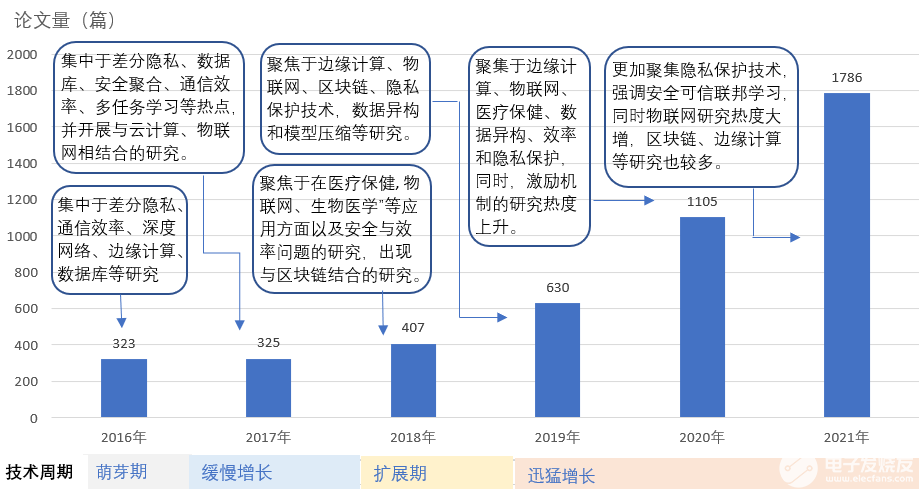
聯邦學習研究論文趨勢(2016-2021 年)
二、論文發布量以中美兩國為引領
根據論文作者所在機構所屬國家進行排序分析,發現近年來聯邦學習論文發布量 TOP 10 國家依次是中國、美國、英國、俄羅斯、德國、印度、澳大利亞、加拿大、日本和法國。相關論文量較突出的國家是中國(1245 篇)和美國(1175 篇)詳細信息如下圖所示。
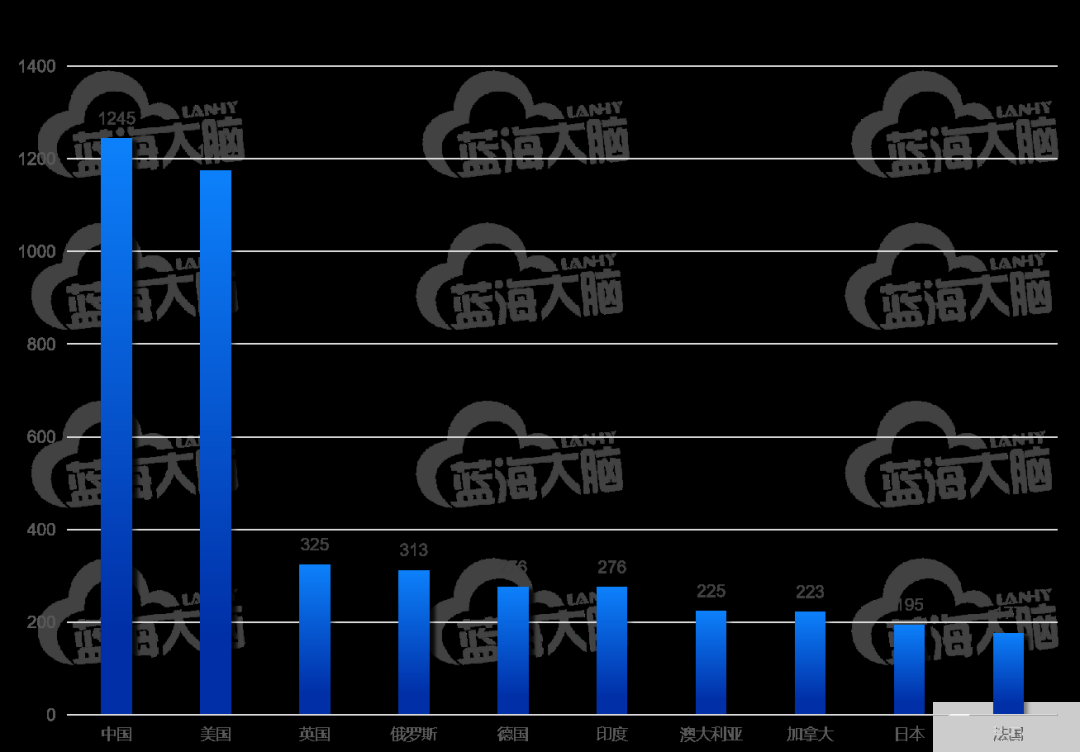
聯邦學習論文發表量 TOP 10 國家(2016-2021 年)
三、研究熱點涵蓋應用、系統和模型設計、安全隱私三個領域
1、總體研究熱點
總體來看,基于 AMiner 系統的論文熱詞分析,發現 2016-2021 年聯邦學習領域的研究熱點 TOP 10 按熱度遞減依次包括:Internet of Things(物聯網)、blockchain(區塊鏈)、edge computing ( 邊緣計算 )、optimization (優化)、deep network(深度網絡)、aggregation(聚合)、differential privacy(差分隱私)、healthcare(醫療保健)、Multiparty Computation(多方計算)、reinforcement learning(強化學習)等,如圖所示。可見,在研究時段內,聯邦學習的主要研究熱點是關于應用及相關算法模型。
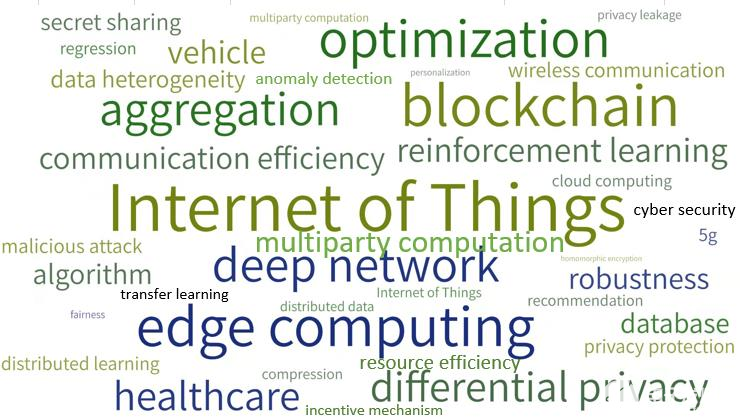
2016-2021 年聯邦學習領域研究熱點詞云圖
2、主題熱點趨勢
通過 TF-IDF 算法對所研究時段內每一年的聯邦學習主題相關論文數量進行計算,獲取論文數量 TOP 30 的熱點詞,然后聚合成聯邦學習的應用 (application)、系統和模型設計(system and model design ) 和安全隱私( secure and privacy)三個主題領域的研究熱點集。這三個細分主題的研究趨勢呈現出如下特征。
在應用研究領域,聯邦學習的研究熱點按照總熱度由高到低依次包括物聯網(Internet of things)、邊緣計算( edge computing )、 醫療保健 (healthcare)、車輛交互(vehicle)、無線通信( wireless communication )、 數據庫 (database)、以及推薦 (recommendation),詳細信息如圖所示。
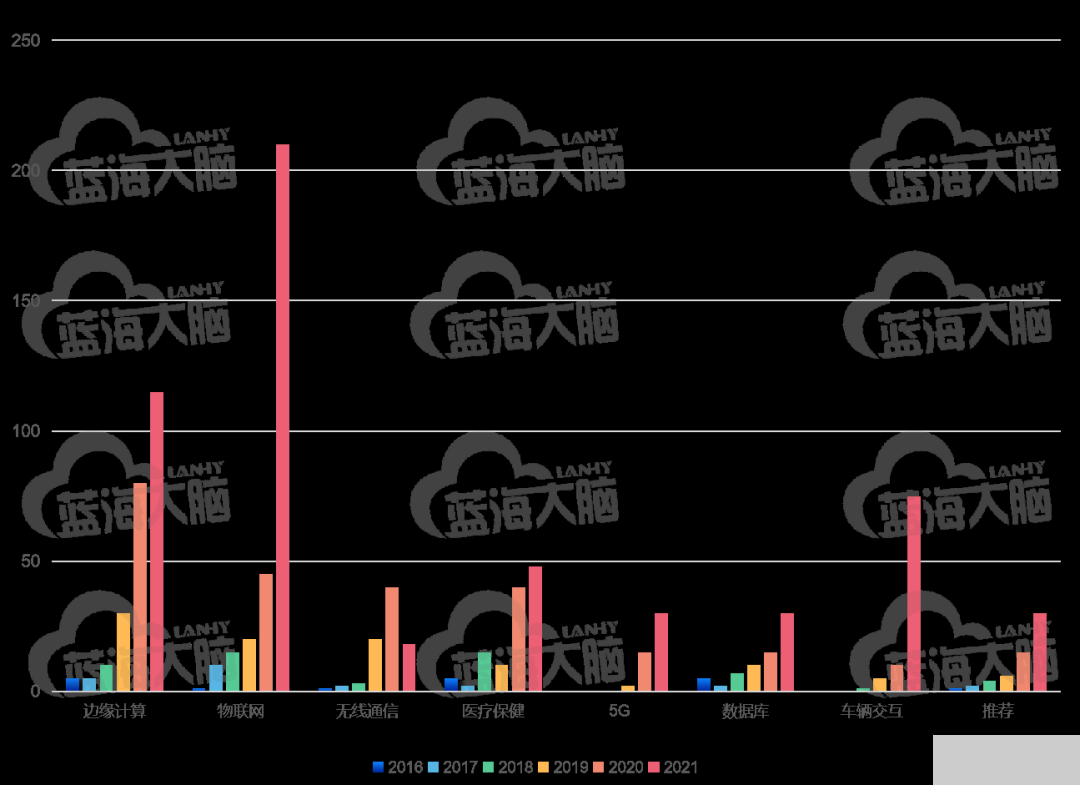
聯邦學習在應用方面的研究熱點趨勢(2016-2021 年)
關于聯邦學習在系統和模型設計方面的研究熱點趨勢情況如圖所示。由圖可見,截止目前,在系統和模型設計方面研究熱點依照熱度遞減分別是優化(optimization)、聚合(aggregation)、魯棒性( robustness ) 、 通信效率 ( communication efficiency )、異構 (heterogeneity)、公平性(fairness)、資源效率 (resource efficiency)和激勵機制(incentive mechanism)。優化主題曾經在 2016 和 2017 年研究熱度最高,經過 2018-2020 年的熱度相對弱化后,在 2021 年再度成為最熱門的研究主題。
2017 年,資源效率和公平性相關主題研究開始嶄露頭角
2018 年,通信效率相關研究占據熱度榜第一
2019 年,熱度最高的是與安全聚合相關研究, 同時,對聯邦學習(數據和系統)異構的研究大幅 提升
2020 年,與異構相關研究上升為最熱門,和激勵機制相關的研究數量大幅提升
2021 年,與優化和聚合相關主題研究上升幅度顯著。
從熱度持續性看,聚合、優化、魯棒性、激勵機制和公平性的相關研究在研究時段內一直保持著不同程度的熱度上揚
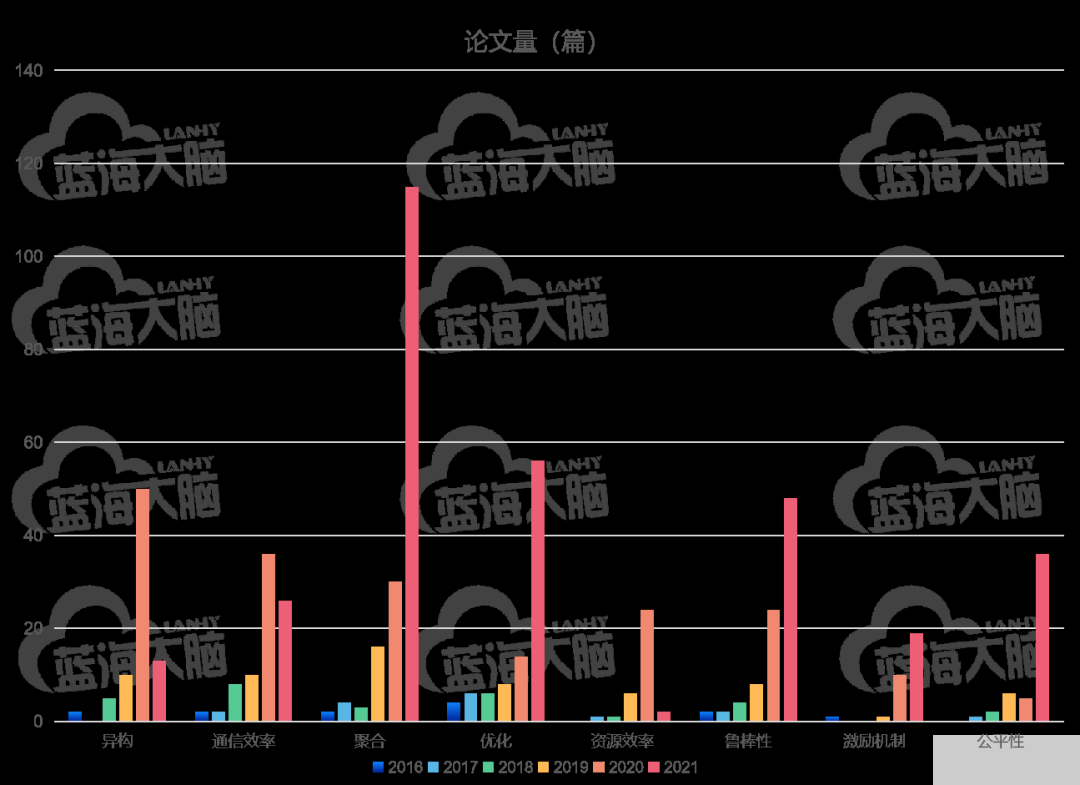
聯邦學習系統和模型設計方面的研究熱點趨勢(2016-2021 年)
在安全隱私方面,聯邦學習研究主題依據總熱度遞減依次包括區塊鏈(blockchain)、差分隱私 (differential privacy)、 安全多方計算 (multiparty computation)、 惡意攻擊 (malicious attack)、 隱私泄露 (privacy leakage)、 同態加密 (homomorphic encryption)、網絡安全(cyber security)以及 容錯(fault tolerance),具體熱度趨勢情況如圖所示。在研究時段內,區塊鏈、差分隱私、多方計算、惡意攻擊、隱私泄露和同態加密的研究熱度總體持續逐年上漲。
2016 年,研究最熱的是對聯邦學習中惡意攻擊的研究
2017 年,研究最熱的是差分隱私
2018 年,研究最熱的是安全多方計算所涉及數據安全和隱私保護技術,與區塊鏈結合的相關研究雖然于 2018 年出現但快速成為 2019 年至 2021 年最熱的研究主題
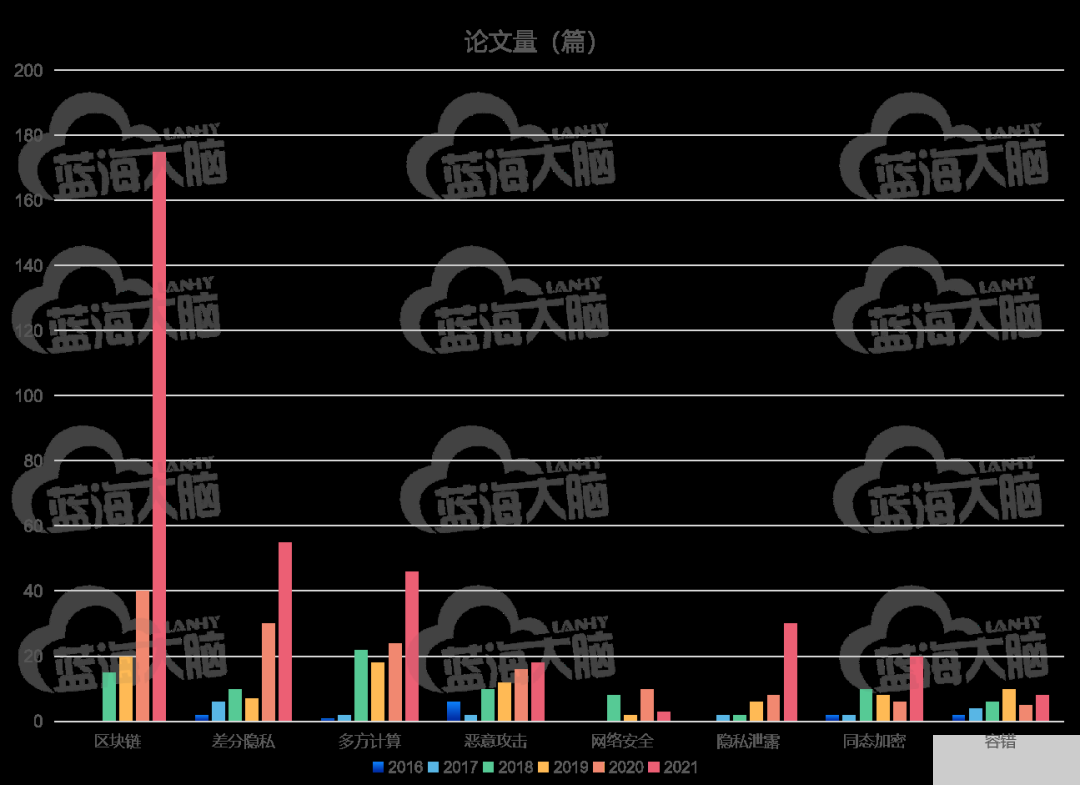
聯邦學習安全隱私方面的研究熱點趨勢(2016-2021 年)
四、高被引論文分析
根據聯邦學習領域論文被引用量進行排序,選取了排名前 3%的論文作為具有重大學術影響的高被引論文進行相關的作者及其所隸屬機構與國家等特征分析。數據顯示,本年度聯邦學習領域高被引論文的最低被引次數是 120 次,是去年高被引論文最低被引次數的 3 倍,反映出該領域論文的整體學術影響力大幅提升。
1、六成以上高被引論文來自中美兩國
根據論文第一作者所在機構的所屬國家進行統計分析,發現聯邦學習的近年來高被引論文發表主要是來自于美國和中國。其中,美國的高被引論文占 39.2%,雖然較上期下降了 1 個百分點,但仍為全球最多;中國的高被引論文占 26.4%,雖仍居于全球第二位,但數量比上期增加了近 10 個百分 點;德國、英國、澳大利亞與新加坡也擁有一定數量的高被引論文;其余國家所發表高被引論文的占比均低于 4%,詳細信息如圖所示。
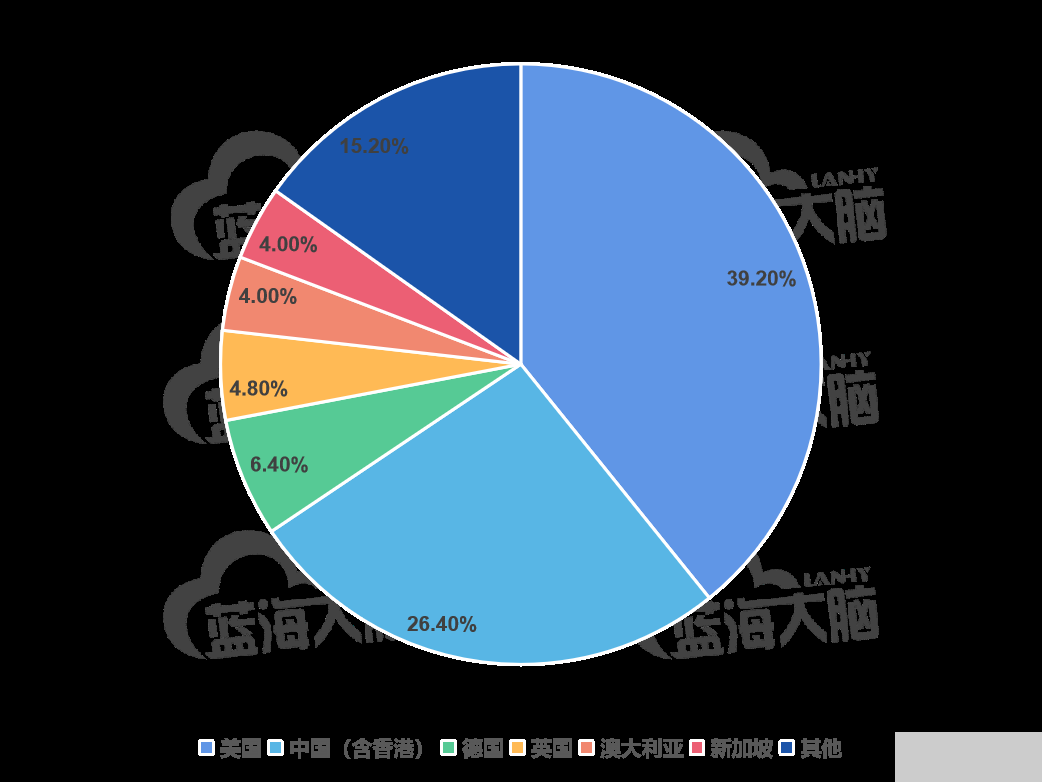
聯邦學習高被論文國家分布(2016-2021 年)
2、美國的論文被引用量全球顯著領先
聯邦學習相關論文總引用量 TOP 10 國家是美國、中國、澳大利亞、德國、新加坡、英國、印度、日本、以色列和波蘭,具體信息如圖所示。其中,美國的論文總被引用量明顯高于其他國家,其較上期增長 1.6 倍,仍占據榜首;中國的論文被引用量較上期增長近 3 倍,保持第二位置。印度、以色列和波蘭是本期新進入前十的國家,上期居于前十的沙特阿拉伯、韓國和瑞士本期未能進入前十。
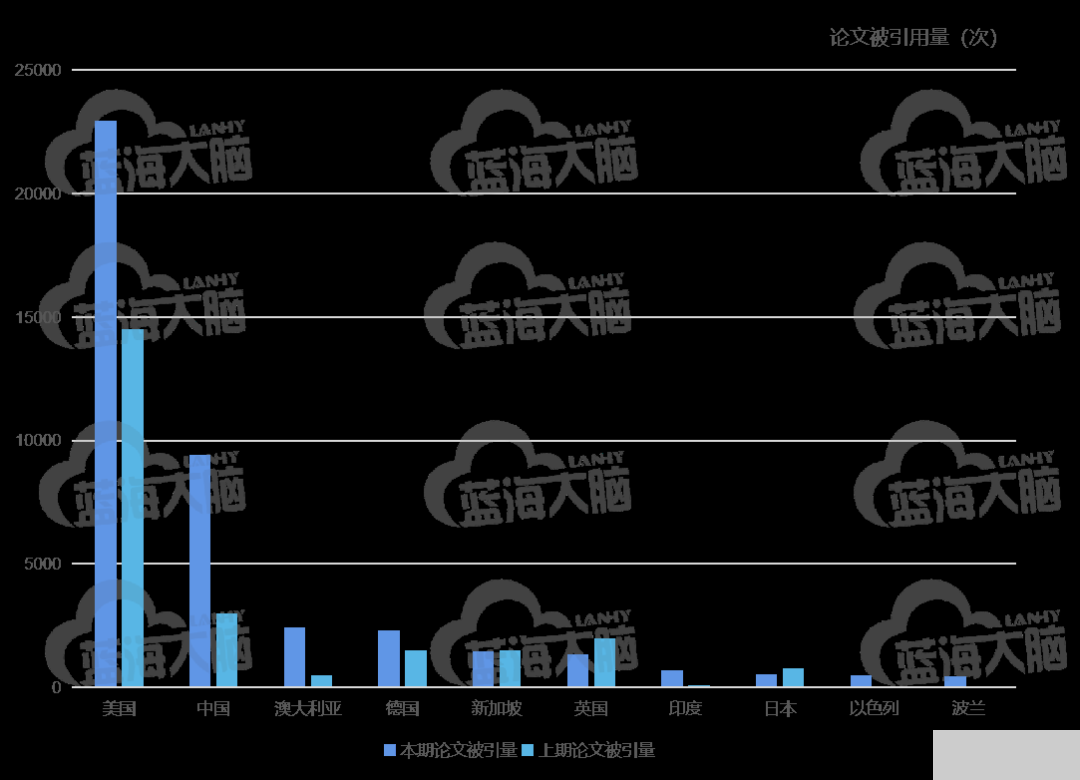
聯邦學習論文引用量 TOP 10 國家(2016-2021 年)
從領先國家來看,美國聯邦學習被引用量最高的論文是谷歌公司研究科學家 H. Brendan Mcmahan 作為一作發表的論文 Communication-efficient learning of deep networks from decentralized data,該論文于 2016 年發表于 ArXiv e-prints (2016): arXiv- 1602,并在2017年收錄于AISTATS (International Conference on Artificial Intelligence and Statistics),目前其被引用 4534 次。中國聯邦學習總體論文引用量居于第二,其中被引用最高的論文是香港科技大學計算機科學與工程學系教授楊強為第一作者、與微眾銀行 AI 部門、北京航空航天大學計算機學院的研究人員聯合發表的 Federated Machine Learning: Concept and Applications,該文被引用量 1936 次。
多開源聯邦學習系統框架詳細介紹
一、OpenMined——PySyft
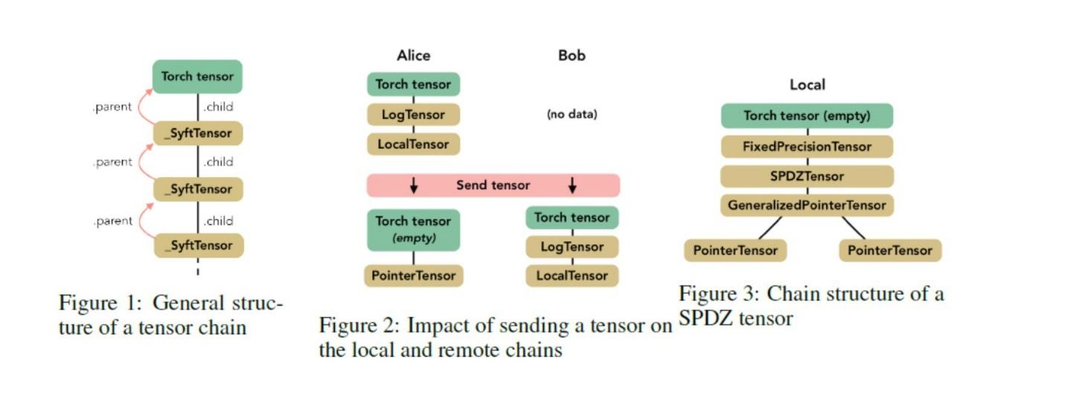
PySyft 是開源社區 OpenMined 推出的一個用于安全和私有深度學習的 Python 庫。它使用聯邦學習、差分隱私和加密計算來解耦私人和敏感數據,可以在主要的深度學習框架中使用,例如 TensorFlow 和 PyTorch。PySyft 代表在深度學習程序中啟用可靠的隱私模型的首批嘗試之一。 PySyft 的核心組件是稱為 SyftTensor 的抽象。
SyftTensors 旨在表示數據的狀態或轉換,并且可以鏈接在一起。鏈結構始終在其頭 部具有 PyTorch 張量,并且使用 child 屬性向下訪問由 SyftTensor 體現的變換或狀態,而使用 parent 屬性向上訪問由 SyftTensor 體現的變換或狀態。
二、微眾銀行——FATE
微眾銀行 AI 部門研發了FATE(Federated AI Technology Enabler)聯邦學習開源項目,是首個開源的聯邦學習工業級框架。目前 FATE 開源社區已匯聚了 700 多家企業、300 余所高校等科研機構的開發者,是國內最大的聯邦學習開源社區。
FATE 項目使用多方安全計算 (MPC) 以及同態加密 (HE) 技術構建底層安全計算協議,以此支持不同種類的機器學習的安全計算,包括邏輯回歸、樹算法、深度學習(人工神經網絡)和遷移學習等。FATE 目前支持三種類型聯邦學習算法:橫向聯邦學習、縱向聯邦學習以及遷移學習。
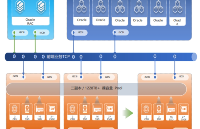
FATE 整體架構如圖所示。FATE 主倉庫包含 FederatedML 核心聯邦算法庫和多方聯邦建模 Pipeline 調度模塊 FATE-Flow,FATE 擁抱大數據生態圈,底層引擎支持使用微眾銀行自主研發的 EGGROLL 或者 Spark 進行高性能的計算。圍繞 FATE 聯邦學習生態,FATE 還提供了完整的聯邦學習生態鏈,如聯邦可視化模塊 FATE-Board、聯邦在線推理模塊 FATE-Serving、聯邦多云管理 FATECloud 等。
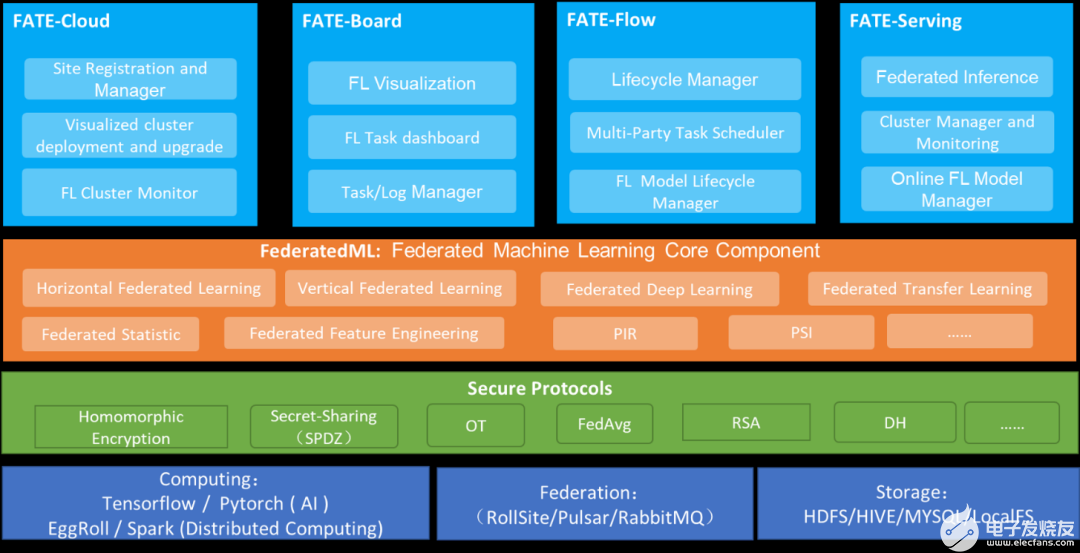
微眾銀行 FATE 系統架構
FederatedML 是 FATE 的聯邦學習算法庫模塊,提供了 20+種聯邦學習算法,支持縱向聯邦學習、橫向聯邦學習、聯邦遷移學習三種聯邦建模場景,覆蓋了工業建模的數據處理、特征變換、訓練、預測、評估的全建模流程。另外,封裝了眾多的多方安全計算協議以提供給上層算法的調度和支持聯邦學習開發者的聯邦算法開發。
FATE-Flow 為 FATE 提供了端到端聯邦建模 Pipeline 調度和管理,主要包括 DAG 定義聯邦建模 pipeline、聯邦任務生命周期管理、聯邦任務協同調度、聯邦任務追蹤、聯邦模型管理等功能,實現了聯邦建模到生產服務一體化。 FATE-Board 聯邦學習建模的可視化工具,為終端用戶提供可視化和度量模型訓練的全過程。
三、谷歌——TensorFlow Federated(TFF)
TensorFlow Federated project (TFF) 由谷歌公司開發和維護,是一個為聯邦機器學習和其他計算方法在去中心化數據集上進行實驗的開源框架。TFF 讓開發者能在自己的模型和數據上模擬實驗現有的聯邦學習算法,以及其他新穎的算法。TFF 提供的建造塊也能夠應用于去中心化數據集上,來實現非學習化的計算,例如聚合分析。
TFF 的接口有兩層構成:聯邦層(FL)應用程序接口(API)和聯邦核心(FC)API。TFF 使得開發者能夠聲明和表達聯邦計算,從而能夠將其部署于各類運行環境。 TFF 中包含的是一個單機的實驗運行過程模擬器。該聯邦學習的框架如圖所示。
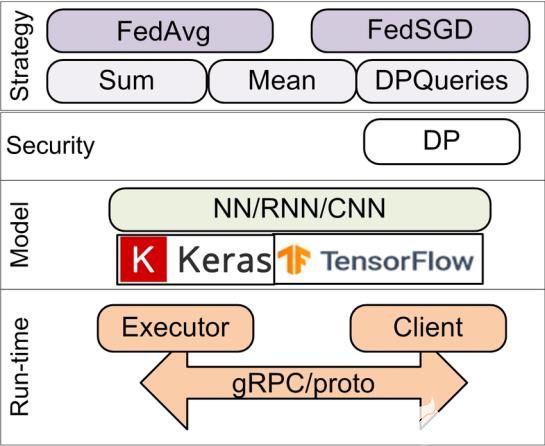
不同于分布式訓練理念,TFF 框架設計理念是以數據為主,而不是代碼分離上。在編寫模型、訓練代碼的時候,將 clients 和 server 看作一個整體,同一個文件里不需要分割開 Server 端(S 端)和 Clients 端(C 端)的代碼,C 端和 S 端的區分是在代碼邏輯層面的。也就是說,用戶在編寫 TFF 代碼時,不需要指明某段代碼是應該運行在 C 端還是 S 端)僅需要指出每個數據是儲存在C 端/S 端、是全局唯一的還是有多份拷貝的即可。類似 TF 的 non-eager 模式,當用戶編寫完模型代碼和訓練代碼后,TFF 會自動地將代碼分別放置到 clients 和 server 設備上。用戶只要關注模型架構、C&S 端交互的數據格式、聚合多 clients 模型的方式即可。
四、字節跳動——Fedlearner
字節跳動聯邦學習平臺 Fedlearner 基于字節跳動在推薦和廣告領域積累的機器學習建模技術和個性化推薦算法,可以支持多類聯邦學習模式,已經在電商、金融、教育等行業多個落地場景實際應用。
Fedlearner 聯邦學習平臺整個系統包括控制臺、訓練器、數據處理、數據存儲等模塊,各模塊對稱部署在參與聯邦的雙方的集群上,透過代理互相通信,實現訓練。
五、百度——PaddleFL
PaddleFL 是一個基于百度飛槳(PaddlePaddle)的開源聯邦學習框架 。PaddleFL 提供很多聯邦學習策略及其在計算機視覺、自然語言處理、推薦算法等領域的應用,例如,橫向聯邦學習(聯邦平均、差分隱私、安全聚合)和縱向聯邦學習(帶 privc 的邏輯回歸,帶 ABY3 的神經網絡)。研究人員可以用 PaddleFL 復制和比較不同的聯邦學習算法。
此外,PaddleFL 還提供傳統機器學習訓練策略的應用,例如多任務學習、聯邦學習環境下的遷移學習、主動學習。依靠 PaddlePaddle 的大規模分布式訓練和 Kubernetes 對訓練任務的彈性調度能力,PaddleFL 可以基于全棧開源軟件輕松地部署。

PaddleFL 中主要提供兩種解決方案:Data Parallel 以及 Federated Learning with MPC (PFM)。通過 Data Parallel,各數據方可以基于經典的橫向聯邦學習策略(如 FedAvg,DPSGD等)完成模型訓練。此外,PFM 是基于多方安全計算(MPC)實現的聯邦學習方案。作為 PaddleFL 的一個重要組成部分,PFM 可以很好地支持聯邦學習,包括橫向、縱向及聯邦遷移學習等多個場景。
六、京東——九數聯邦學習 9NFL
京東自研的九數聯邦學習平臺(9NFL)于2020 年初正式上線。9NFL 平臺基于京東商業提升事業部 9N 機器學習平臺進行開發,在 9N 平臺離線訓練、離線預估、線上推斷(inference)、模型的發版等功能的基礎上,增加了多任務跨域調度、跨域高性能網絡、大規模樣本匹配、大規模跨域聯合訓練、模型分層級加密等功能。整個平臺可以支持百億級/百 T 級超大規模的樣本匹配、聯合訓練,并且針對跨域與跨公網的復雜環境,對可用性與容災設計了一系列的機制與策略,保障整個系統的高吞吐、高可用、高性能。
七、FedML.AI——FedML
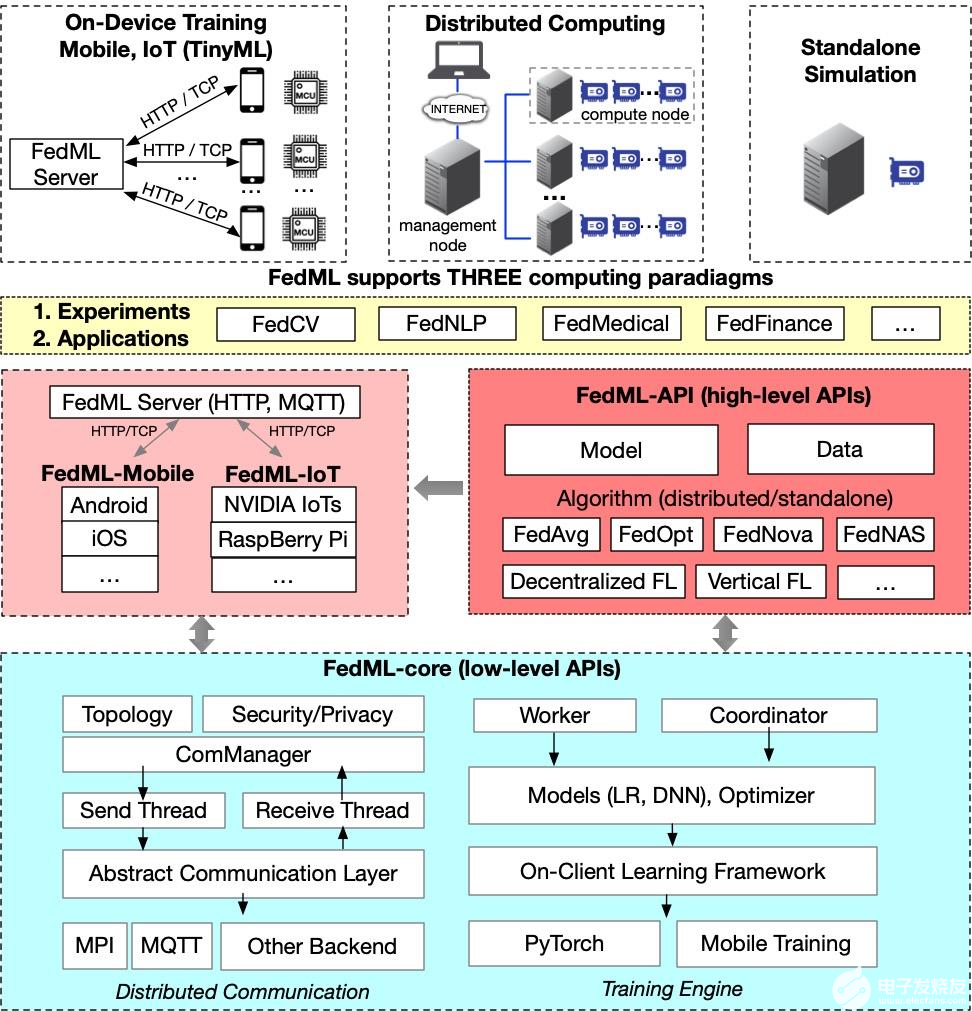
FedML 是一個以研究為導向的聯邦學習圖書館,支持分布式計算、移動/物聯網設備上訓練和獨立模擬,可促進新的聯合學習算法的開發和公平的性能比較。支持分布式計算、移動/物聯網設備上訓練和獨立模擬。
FedML 還通過靈活且通用的 API 設計和參考基準實現和促進了各種算法研究。針對非 I.I.D 設置的精選且全面的基準數據集旨在進行公平比較。 FedML 可以為聯合學習研究社區提供開發和評估算法的有效且可重復的手段。
八、臺灣人工智能實驗室——Harmonia
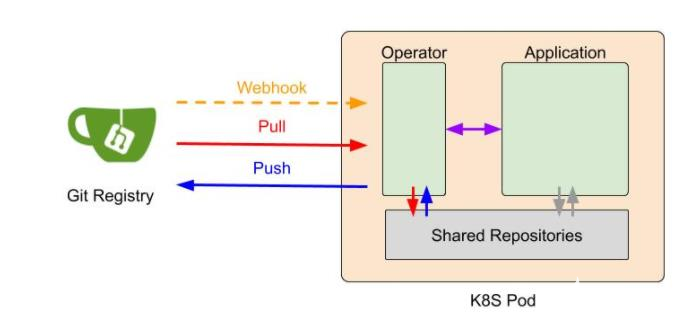
臺灣人工智能實驗室(AI Labs)開發了一個開源項目 Harmonia,旨在開發系統/基礎設施和圖書館,以簡化聯合學習的研究和生產用途。Harmonia 使用工程師熟悉的環境和語言,比如熱門的開源工具 Kubernetes、Git Large File Storage 和 GitOps 等。Harmonia 利用 Git 進行訪問控制、模型版本控制和服務器和聯合培訓 (FL)運行參與者之間的同步。FL 訓練策略、全局模型和本地模型/漸變保存在 Git 存儲庫中。這些 Git respoitroies 的更新會觸發 FL 系統狀態轉換。這將自動化 FL 培訓過程。
FL 參與者被激活為由操作員和應用容器組成的 K8S 吊艙。操作容器負責維護 FL 系統狀態,并通過 gRPC 與應用程序容器通信。本地訓練和聚合函數封裝在應用程序容器中。此設計可在 Kubernetes 群集環境中輕松部署,并快速插件現有機器學習(ML)工作流。
非開源聯邦學習系統框架詳細介紹
一、騰訊——Angel PowerFL
Angel Power FL(原名 AngelFL)安全聯合計算是基于騰訊自研的多數據源聯合計算技術,提供安全、易用、穩定、高性能的聯邦機器學習、聯合數據分析解決方案,助力數據融合應用。它構建在 Angel 機器學習平臺上,利用 Angel--PS 支持萬億級模型訓練的能力,將很多在 Worker 上的計算提升到 PS(參數服務器)端;Angel PowerFL 為聯邦學習算法提供了計算、加密、存儲、狀態同步等基本操作接口,通過流程調度模塊協調參與方任務執行狀態,而通信模塊完成了任務訓練過程中所有數據的傳輸。
采用去中心的架構設計,全自動化流程,算法支持 LR、XGBoost、PCA、用戶自定義神經網絡模型(如 MLP、CNN、RNN、 Wide&Deep,DeepFM, DSSM 等)。Angel PowerFL 聯邦學習已經在騰訊金融云、騰訊廣告聯合建模等業務中開始落地。目前主要應用產品是騰訊云安全隱私計算。

二、京東科技——Fedlearn
京東數字科技集團(簡稱:京東數科,現名: 京東科技)于 2020 年 10 月推出自主研發的聯邦學習平臺 Fedlearn。Fedlearn 平臺具有“六位一 體”核心能力:多自研聯邦學習算法、多方同態加密、輕量級分布式架構、區塊鏈與聯邦學習融合、數據安全容器、一站式操作平臺。
京東科技 Fedlearn 平臺具有三大特點:
1、數據和模型隱私方面
不同參與方之間沒有直接交換本地數據和模型參數,而是交換更新參數所需的中間數值。為了避免從這些中間數值中恢復數據信息,采用增加擾動對這些數值進行保護,確保了數據和模型的隱私安全
2、通訊方面
引入中心化數據交換的概念,使得數據的交換獨立于參與方
3、計算架構
采用異步計算框架,提高模型訓練的速度
三、富數科技——FMPC
富數多方安全計算平臺(FMPC)是上海富數科技旗下產品,目前未開源,主要通過體驗或者服務購買方式使用 。
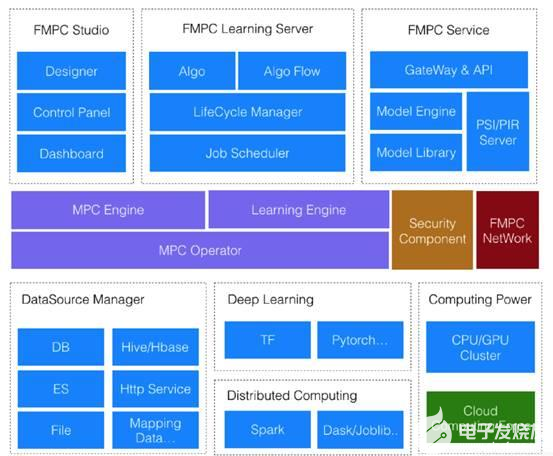
FMPC 架構具有以下特點:
1、聯邦學習
原始數據不出門,參與各方本地建模;沒有敏感數據流通,只交互中間計算結果;整個模型被保護,參與各方只有自己模型參數;私有化部署;開放 API 快速開發;支持主流機器學習算法,如 LR, DT, RF, Xgboost 等;建模速度快 3 倍;密文訓練精度誤差<1%。?
2、多方安全計算
落地應用計算量 1.1 萬+次 /天;支持多方數據安全求交;支持一次多項式;支持多方歸因統計分析;支持多方多維數據鉆取分析;私有化部署。
3、匿蹤查詢
支持 100 億+條記錄;秒級響應時間;查詢授權存證;甲方查詢信息不泄露;加密隧道避免中間留存;私有化部署。
隱私計算(聯邦學習)液冷GPU服務器
藍海大腦隱私計算(聯邦學習)大數據液冷GPU服務器基于數據隱私保護的安全建模過程提供豐富的可視化呈現,為終端用戶可視化和度量模型訓練的全過程,支持模型訓練過程全流程的跟蹤、統計和監控等,幫助模型開發人員快速搭建聯邦學習任務,可根據客戶需求深度定制開發。是一款具備高性能、高可靠、高靈活及高擴展特性的深度學習操作系統,由高性能計算加速中間件、深度學習訓練平臺及數據推理平臺三個子系統構成,為用戶提供數據處理、模型訓練、推理服務應用等完整的 AI 解決方案。
一、用戶現狀
1、數據產品相互分離
同一業務可能隨著業務發展和需求變化,同時部署不同的數據庫和數據平臺產品;此外,為了保證企業的核心競爭力,企業不斷部署新的數據庫和數據平臺產品,不斷建設、合并和遷移業務。然而,豎井建設模式使得數據產品相互分離,導致數據孤島問題,最終降低了企業的數據共享能力。
2、系統復雜性劇增
傳統的解決方案需要經過復雜耗時的ETL,將數據反復存儲在同一個存儲介質中,然后重新開發業務獲得數據計算結果。數據分散存儲在不同的數據產品中,數據結構存在差異,給跨產品數據間的關聯計算帶來了一定的難度。
3、開發運維困難
系統集成一段時間后,業務部門會推出新的業務數據庫,ETL流程需要改造。底層數據庫頻繁的業務架構調整和數據變換也會導致集成系統的失敗。面對集成系統的開發和運維難題,企業自身的技術開發能力顯然難以應對,最終集成系統的響應速度無法滿足業務的時效性需求。

二、方案優勢
1、統一平臺架構
連接企業內部各類數據源,滿足各種多樣復雜的業務需求,為企業提供平臺數據計算能力
2、極致性能
自主研發的統一分布式計算引擎可以根據不同的查詢對象,通過各種優化技術自動優化查詢,并實現毫秒級延遲
3、多數據源支持
支持傳統關系型數據庫、Nosql數據庫、MPP數據庫和大數據平臺產品
4、統一的SQL查詢
自主研發統一的SQL編譯器,通過一個標準的SQL就可以實現各個數據庫之間的關聯查詢
5、數據獨立性
實現跨數據庫、跨平臺的數據集成的同時,滿足底層數據庫的自治需求
6、安全合規
提供統一的權限體系、用戶行為審計與溯源,提供數據安全與合規保障
三、客戶收益
1、建設統一計算平臺,簡化IT系統架構,降低IT成本
2、提升企業數據共享能力,快速響應業務需求
3、提升企業信息技術架構的敏捷程度,助力企業數據數字轉型
審核編輯 黃昊宇
-
AI
+關注
關注
87文章
34274瀏覽量
275454 -
分布式
+關注
關注
1文章
980瀏覽量
75181 -
機器學習
+關注
關注
66文章
8492瀏覽量
134117 -
網絡訓練
+關注
關注
0文章
3瀏覽量
1560
發布評論請先 登錄
百度文心大模型將升級并開源
分布式通信的原理和實現高效分布式通信背后的技術NVLink的演進







 工商網監
工商網監
評論