 一種利用任何形式的先驗策略來改進初始化強化學習任務的探索的方法
一種利用任何形式的先驗策略來改進初始化強化學習任務的探索的方法
強化學習可以用于訓練一種策略,使其能夠在試錯的情況下來完成任務,但強化學習面臨的最大挑戰就是,如何在具有艱難探索挑戰的環境中從頭學習策略。比如,考慮到 adroit manipulation 套件中的 door-binary-v0 環境所描述的設置,其中強化學習智能體必須在三維空間中控制一只手來打開放在它前面的門。
由于智能體沒有收到任何中間獎勵,它無法衡量自己離完成任務有多遠,所以只能在空間里隨機探索,直至門被打開為止。鑒于這項任務所需的時間以及對其進行精準的控制,這種可能性微乎其微。
對于這樣的任務,我們可以通過使用先驗信息來規避對狀態空間的隨機探索。這種先驗信息有助于智能體了解環境的哪些狀態是好的,應該進一步探索。
我們可以利用離線數據(即由人類演示者、腳本策略或其他強化學習智能體收集的數據),對策略進行訓練,并將之用于初始化新的強化學習策略。如果采用神經網絡來表達策略,則需要將預訓練好的神經網絡復制到新的強化學習策略中。這一過程使得新的強化學習策略看起來就像是預訓練好的。但是,用這種幼稚的方式來進行新的強化學習通常是行不通的,尤其是基于值的強化學習方法,如下所示。
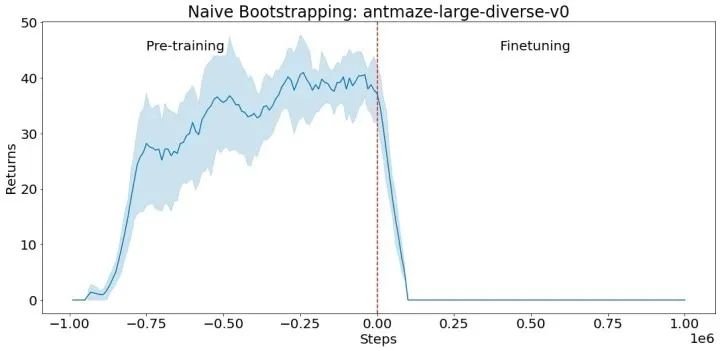
用離線數據在 antmaze-large-diverse-v0 D4RL 環境中對一種策略進行預訓練(負向步驟對應預訓練)。然后,我們使用該策略來初始化 actor-crittic 的微調(從第 0 步開始的正向步驟),以該預訓練的策略作為初始 actor。crittic 是隨機初始化的。由于未經訓練的 critic 提供了一個糟糕的學習信號,并導致良好的初始策略被遺忘,所以 actor 的性能會立即下降,并且不會恢復。
有鑒于此,我們在“跳躍式強化學習”(Jump-Start Reinforcement Learning,JSRL)中,提出了一種可以利用任意一種與現存在的策略對任意一種強化學習算法進行初始化的元算法。
JSRL 在學習任務時采用了兩種策略:一種是指導策略,另一種是探索策略。探索策略是一種強化學習策略,通過智能體從環境中收集的新經驗進行在線訓練,而指導策略是一種預先存在的任何形式的策略,在在線訓練中不被更新。在這項研究中,我們關注的是指導策略從演示中學習的情景,但也可以使用許多其他類型的指導策略。JSRL 通過滾動指導策略創建了一個學習課程,然后由自我改進的探索策略跟進,其結果是與競爭性的 IL+RL 方法相比較或改進的性能。
JSRL 方法
指導策略可以采取任何形式:它可以是一種腳本化的策略,一種用于強化學習訓練的策略,甚至是一個真人演示者。唯一的要求是,指導策略要合理(也就是優于隨機探索),而且可以根據對環境的觀察來選擇行動。理想情況下,指導策略可以在環境中達到較差或中等的性能,但不能通過額外的微調來進一步改善自己。然后,JSRL 允許我們利用這個指導策略的進展,從而提到它的性能。
在訓練開始時,我們將指導策略推出一個固定的步驟,使智能體更接近目標狀態。然后,探索策略接手,繼續在環境中行動以達到這些目標。隨著探索策略性能的提高,我們逐漸減少指導策略的步驟,直到探索策略完全接管。這個過程為探索策略創建了一個起始狀態的課程,這樣在每個課程階段,它只需要學習達到之前課程階段的初始狀態。
這個任務是讓機械臂拿起藍色木塊。指導策略可以將機械臂移動到木塊上,但不能將其拾起。它控制智能體,直到它抓住木塊,然后由探索策略接管,最終學會拿起木塊。隨著探索策略的改進,指導策略對智能體的控制越來越少。
與 IL+RL 基線的比較
由于 JSRL 可以使用先前的策略來初始化強化學習,一個自然的比較是模仿和強化學習(IL+RL)方法,該方法在離線數據集上進行訓練,然后用新的在線經驗對預訓練的策略進行微調。我們展示了 JSRL 在 D4RL 基準任務上與具有競爭力的 IL+RL 方法的比較情況。這些任務包括模擬的機器人控制環境,以及來自人類演示者的離線數據集、計劃者和其他學到的策略。在 D4RL 任務中,我們重點關注困難的螞蟻迷宮和 adroit dexterous manipulation 環境。

對于每個實驗,我們在一個離線數據集上進行訓練,然后運行在線微調。我們與專門為每個環境設計的算法進行比較,這些算法包括 AWAC、IQL、CQL 和行為克隆。雖然 JSRL 可以與任何初始指導策略或微調算法結合使用,但我們使用我們最強大的基線——IQL,作為預訓練的指導和微調。完整的 D4RL 數據集包括每個螞蟻迷宮任務的一百萬個離線轉換。每個轉換是一個格式序列(S, A, R, S'),它指定了智能體開始時的狀態(S),智能體采取的行動(A),智能體收到的獎勵(R),以及智能體在采取行動 A 后結束的狀態(S')。
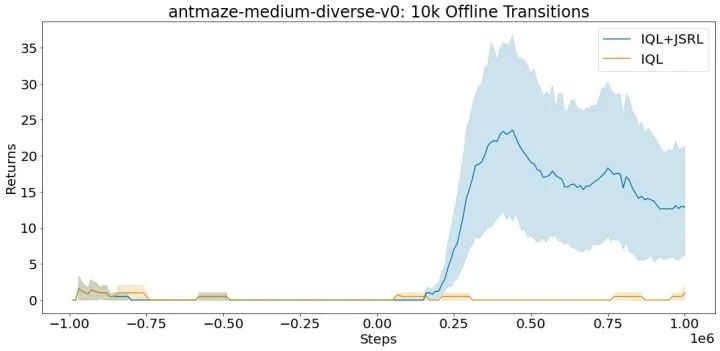
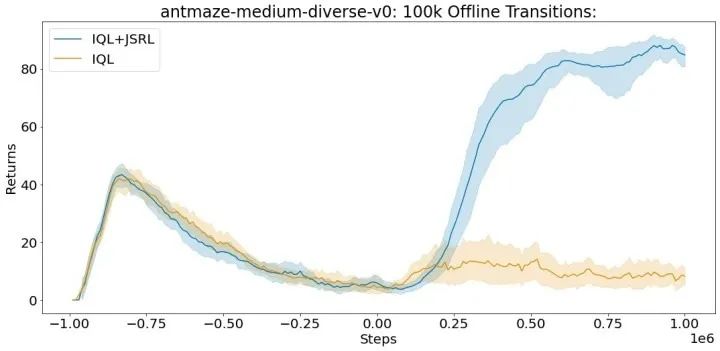
在 D4RL 基準套件的 antmaze-medium-diverse-v0 環境中的平均得分(最大值 =100)。即使在有限的離線轉換的情況下,JSRL 也可以改進。
基于視覺的機器人任務
由于維度的限制,在復雜的任務中使用離線數據特別困難,比如基于視覺的機器人操縱。連續控制動作空間和基于像素的狀態空間的高維度,給 IL+RL 方法帶來了學習良好策略所需的數據量方面的擴展挑戰。為了研究 JSRL 如何適應這種環境,我們重點研究了兩個困難的仿生機器人操縱任務:無差別抓取(即,舉起任何物體)和實例抓取(即,舉起特定的目標物體)。

一個仿生機械臂被放置在一張有各種類別物體的桌子前。當機械臂舉起任何物體時,對于無差別的抓取任務,會給予稀疏的獎勵。對于實例抓取任務,只有在抓取特定的目標物體時,才會給予稀疏的獎勵。
我們將 JSRL 與能夠擴展到復雜的基于視覺的機器人環境的方法進行比較,如 QT-Opt 和 AW-Opt。每種方法都可以獲得相同的成功演示的離線數據集,并被允許運行多達 10 萬步的在線微調。
在這些實驗中,我們使用行為克隆作為指導策略,并將 JSRL 與 QT-Opt 相結合進行微調。QT-Opt+JSRL 的組合比其他所有方法改進得更快,同時獲得了最高的成功率。
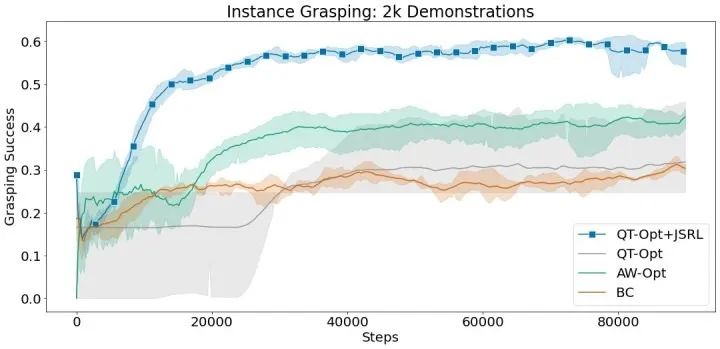
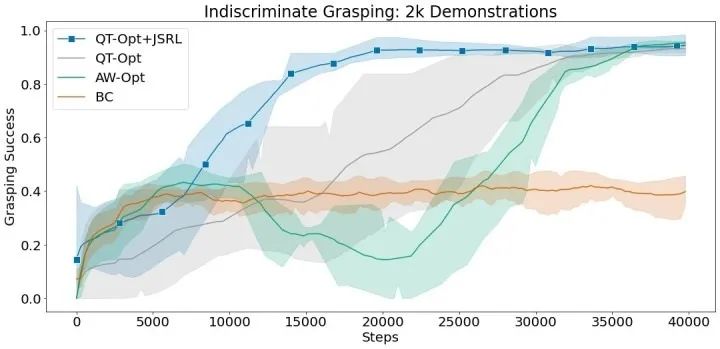
使用 2 千次成功演示,無差別和實例抓取環境的平均抓取成功率。
結語
我們提出了 JSRL,它是一種利用任何形式的先驗策略來改進初始化強化學習任務的探索的方法。我們的算法通過在預先存在的指導策略中滾動,創建了一個學習課程,然后由自我改進的探索策略跟進。探索策略的工作被大大簡化,因為它從更接近目標的狀態開始探索。隨著探索策略的改進,指導策略的影響也隨之減弱,從而形成一個完全有能力的強化學習策略。在未來,我們計劃將 JSRL 應用于 Sim2Real 等問題,并探索我們如何利用多種指導策略來訓練強化學習智能體。
審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4806瀏覽量
102728 -
智能體
+關注
關注
1文章
262瀏覽量
10948 -
強化學習
+關注
關注
4文章
269瀏覽量
11514
原文標題:如何使用先驗策略有效地初始化強化學習?
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
使用MATLAB進行無監督學習

18個常用的強化學習算法整理:從基礎方法到高級模型的理論技術與代碼實現

AFE031初始化的過程應該是什么?
EE-359:ADSP-CM40x啟動時間優化和器件初始化

ADS1220初始化遇到的幾個疑問求解
STM32F407 MCU使用SD NAND?不斷電初始化失效解決方案

如何使用 PyTorch 進行強化學習

視頻引擎初始化失敗怎么回事
Keil中變量不被初始化方法

通過強化學習策略進行特征選擇





 工商網監
工商網監
評論