") 設(shè)計(jì)師如何應(yīng)對(duì) AI 的內(nèi)存瓶頸
設(shè)計(jì)師如何應(yīng)對(duì) AI 的內(nèi)存瓶頸

懷疑論者對(duì)當(dāng)前人工智能技術(shù)的批評(píng)之一是內(nèi)存瓶頸——由于無(wú)法加速處理器和內(nèi)存之間的數(shù)據(jù)移動(dòng)——阻礙了有用的現(xiàn)實(shí)世界應(yīng)用程序。
用于在數(shù)據(jù)中心訓(xùn)練 AI 模型的 AI 加速器需要可用的最高內(nèi)存帶寬。在理想情況下,整個(gè)模型可以存儲(chǔ)在處理器中,這種方法可以消除等式中的片外存儲(chǔ)器。這是不可能的,因?yàn)樽畲蟮哪P涂梢詼y(cè)量數(shù)十億或數(shù)萬(wàn)億個(gè)參數(shù)。
過(guò)去的系統(tǒng)內(nèi)存受限,而今天的數(shù)據(jù)中心架構(gòu)使用各種技術(shù)來(lái)克服內(nèi)存瓶頸。
高帶寬內(nèi)存
一種流行的解決方案是使用高帶寬內(nèi)存 (HBM),它涉及通過(guò)硅中介層將 4、8 或 12 個(gè) DRAM 裸片的 3D 堆棧連接到處理器。該技術(shù)的最新版本 HBM2E 具有比其前身更快的每針信號(hào)速率,每針高達(dá) 3.6 Gb/s,從而提高了帶寬。三星和 SK 海力士各自提供 8 個(gè)芯片 HBM2E 堆棧,總?cè)萘繛?16 GB,提供 460 GB/s 帶寬(相比之下,DDR5 為 2.4 GB/s,GDDR6 為 64 GB/s,SK Hynix 表示)。HBM3 旨在將速度和容量推得更高。

英偉達(dá)的 A100 數(shù)據(jù)中心 GPU,帶有六層 HBM2E 內(nèi)存(出于良率原因,僅使用了五層)(來(lái)源:英偉達(dá))
最新版本的 Nvidia 旗艦數(shù)據(jù)中心 GPU A100提供 80 GB 的 HBM2E 性能和 2 TB/s 的內(nèi)存帶寬。A100 包含五個(gè) 16-GB DRAM 堆棧,加入一個(gè)使用 HBM2 的 40-GB 版本,總帶寬為 1.6 TB/s。兩者之間的差異使深度學(xué)習(xí)推薦模型的 AI 模型訓(xùn)練速度提高了三倍,這是一種已知的內(nèi)存消耗。
同時(shí),數(shù)據(jù)中心 CPU 正在利用 HBM 帶寬。Intel 的下一代 Xeon 數(shù)據(jù)中心 CPU Sapphire Rapids 將 HBM 引入 Xeon 系列。它們是英特爾首款使用專(zhuān)為 AI 等矩陣乘法工作負(fù)載設(shè)計(jì)的新 AMX 指令擴(kuò)展的數(shù)據(jù)中心 CPU。他們還可以使用片外 DDR5 DRAM 或 DRAM 加 HBM。
“通常,CPU 針對(duì)容量進(jìn)行了優(yōu)化,而加速器和 GPU 針對(duì)帶寬進(jìn)行了優(yōu)化,”英特爾高級(jí)首席工程師 Arijit Biswas 在最近的 Hot Chips 演示中說(shuō)。“然而,隨著模型大小呈指數(shù)級(jí)增長(zhǎng),我們看到對(duì)容量和帶寬的持續(xù)需求沒(méi)有權(quán)衡取舍。Sapphire Rapids 通過(guò)原生支持這兩者來(lái)做到這一點(diǎn)。” 通過(guò)內(nèi)存分層進(jìn)一步增強(qiáng)了該方法,“其中包括對(duì)軟件可見(jiàn)的 HBM 和 DDR 的支持,以及使用 HBM 作為 DDR 支持的緩存的軟件透明緩存,”Biswas 補(bǔ)充道。
Sapphire Rapids 的首席工程師 Nevine Nassif 告訴EE Times,HBM 版本是以犧牲芯片面積為代價(jià)的。
“[HBM 兼容] 模具略有不同,”Nassif 指出。“還有一個(gè)不同于 DDR5 控制器的 HBM 控制器。在沒(méi)有 HBM 的 Sapphire Rapids 版本中,我們?cè)谛酒囊粋€(gè)區(qū)域添加了用于加密、壓縮等的加速器。所有這些都消失了——除了數(shù)據(jù)流加速器——而 HBM 控制器取而代之。最重要的是,我們必須對(duì)網(wǎng)格進(jìn)行一些更改,以支持 HBM 的帶寬要求,”她補(bǔ)充道。
除了 CPU 和 GPU,HBM 在數(shù)據(jù)中心 FPGA 中也很受歡迎。例如,英特爾的 Stratix 和賽靈思 Versal FPGA 都有 HBM 版本,一些 AI ASIC 也使用它。騰訊支持的數(shù)據(jù)中心 AI ASIC 開(kāi)發(fā)商 Enflame 將 HBM 用于其 DTU 1.0 設(shè)備,該設(shè)備針對(duì)云 AI 訓(xùn)練進(jìn)行了優(yōu)化。80 Tflops (FP16/BF16) 芯片使用兩個(gè) HBM2 堆棧,通過(guò)片上網(wǎng)絡(luò)提供 512 GB/s 帶寬。

燧發(fā)DTU 1.0數(shù)據(jù)中心AI加速芯片有兩層HBM2內(nèi)存(來(lái)源:燧發(fā))
每美元的性能
雖然 HBM 為數(shù)據(jù)中心 AI 加速器所需的片外內(nèi)存提供了極高的帶寬,但仍然存在一些值得注意的問(wèn)題。
Graphcore 就是其中之一。在他的 Hot Chips 演示中,Graphcore 首席技術(shù)官 Simon Knowles 指出,在大型 AI 模型中更快的計(jì)算需要內(nèi)存容量和內(nèi)存帶寬。雖然其他人使用 HBM 來(lái)提高容量和帶寬,但權(quán)衡包括 HBM 的成本、功耗和熱限制。
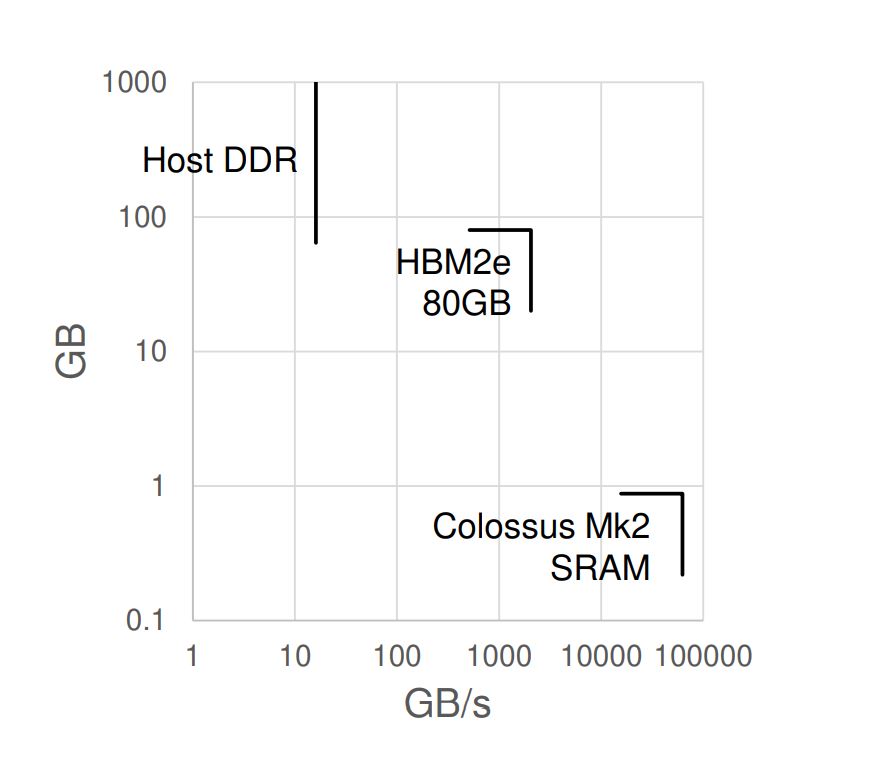
Graphcore 對(duì)不同內(nèi)存技術(shù)的容量和帶寬的比較。當(dāng)其他人嘗試使用 HBM2E 解決這兩個(gè)問(wèn)題時(shí),Graphcore 在其 Colossus Mk2 AI 加速器芯片上使用了主機(jī) DDR 內(nèi)存和片上 SRAM 的組合(來(lái)源:Graphcore)
Graphcore 的第二代智能處理單元 (IPU)改為使用其大型片上 896 MiB SRAM 來(lái)支持為其 1,472 個(gè)處理器內(nèi)核提供所需的內(nèi)存帶寬。Knowles 說(shuō),這足以避免卸載 DRAM 所需的更高帶寬。為了支持內(nèi)存容量,太大而無(wú)法在芯片上安裝的 AI 模型使用服務(wù)器級(jí) DDR 形式的低帶寬遠(yuǎn)程 DRAM。該配置連接到主機(jī)處理器,允許中型模型分布在 IPU 集群中的 SRAM 上。
鑒于該公司以每美元性能為基礎(chǔ)推廣其 IPU ,Graphcore 拒絕 HBM 的主要原因似乎是成本。
“與 AI 處理器集成的 HBM 的凈成本是每字節(jié)服務(wù)器級(jí) DDR 成本的 10 倍以上,”他說(shuō)。“即使容量適中,HBM 也主導(dǎo)著處理器模塊的成本。如果 AI 計(jì)算機(jī)可以使用 DDR,它可以部署更多 AI 處理器,但總擁有成本相同。”
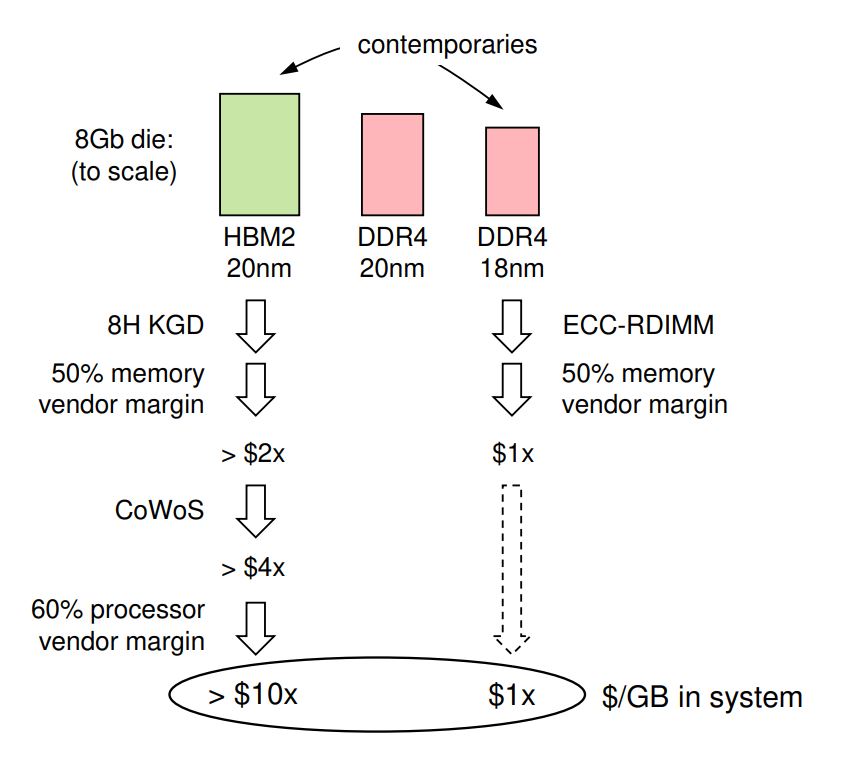
Graphcore 對(duì) HBM2 與 DDR4 內(nèi)存的成本分析顯示,前者的成本是后者的 10 倍。(來(lái)源:Graphcore)
據(jù) Knowles 稱,40 GB 的 HBM 有效地將封裝的標(biāo)線大小處理器的成本提高了三倍。Graphcore 的 8 GB HBM2 與 8 GB DDR4 的成本細(xì)分估計(jì) HBM 芯片的尺寸是 DDR4 芯片的兩倍(將 20-nm HBM 與 Knowles 認(rèn)為是同時(shí)代的 18-nm DDR4 進(jìn)行比較),從而增加了制造成本. 然后是 TSV 蝕刻、堆疊、組裝和封裝的成本,以及內(nèi)存和處理器制造商的利潤(rùn)率。
“DDR DIMM 不會(huì)發(fā)生這種邊距堆疊,因?yàn)橛脩艨梢灾苯訌膬?nèi)存制造商處采購(gòu),”Knowles 說(shuō)。“事實(shí)上,可插拔的計(jì)算機(jī)組件生態(tài)系統(tǒng)出現(xiàn)的一個(gè)主要原因是為了避免保證金堆積。”
走得更遠(yuǎn)
從 Hot Chips 的隱形模式中脫穎而出,Esperanto 提供了另一種解決內(nèi)存瓶頸問(wèn)題的方法。該公司的 1000 核 RISC-V AI 加速器針對(duì)的是超大規(guī)模推薦模型推理,而不是上面提到的 AI 訓(xùn)練工作負(fù)載。
世界語(yǔ)的創(chuàng)始人兼執(zhí)行主席戴夫·迪策爾指出,數(shù)據(jù)中心推理不需要巨大的片上內(nèi)存。“我們的客戶不想要 250 MB 的芯片,”Ditzel 說(shuō)。“他們想要 100 MB——他們想用推理做的所有事情都適合 100 MB。任何比這更大的東西都需要更多。”
Ditzel 補(bǔ)充說(shuō),客戶更喜歡將大量 DRAM 與處理器放在同一張卡上,而不是在芯片上。“他們建議我們:'只需將所有內(nèi)容都放到卡上,然后使用您的快速接口。然后,只要您能夠比通過(guò) PCIe 總線更快地獲得 100 GB 的內(nèi)存,這就是勝利。”
將 Esperanto 的方法與其他數(shù)據(jù)中心推理加速器進(jìn)行比較,Ditzel 說(shuō)其他人專(zhuān)注于消耗整個(gè)功率預(yù)算的單個(gè)巨型處理器。這家初創(chuàng)公司堅(jiān)持認(rèn)為,世界語(yǔ)的方法——安裝在雙 M.2 加速卡上的多個(gè)低功耗處理器——可以更好地使用片外內(nèi)存。單芯片競(jìng)爭(zhēng)對(duì)手“引腳數(shù)量非常有限,因此他們必須采用 HBM 之類(lèi)的產(chǎn)品才能在少量引腳上獲得非常高的帶寬,但 HBM 確實(shí)很昂貴,而且很難獲得,而且功率很高,”他說(shuō)。
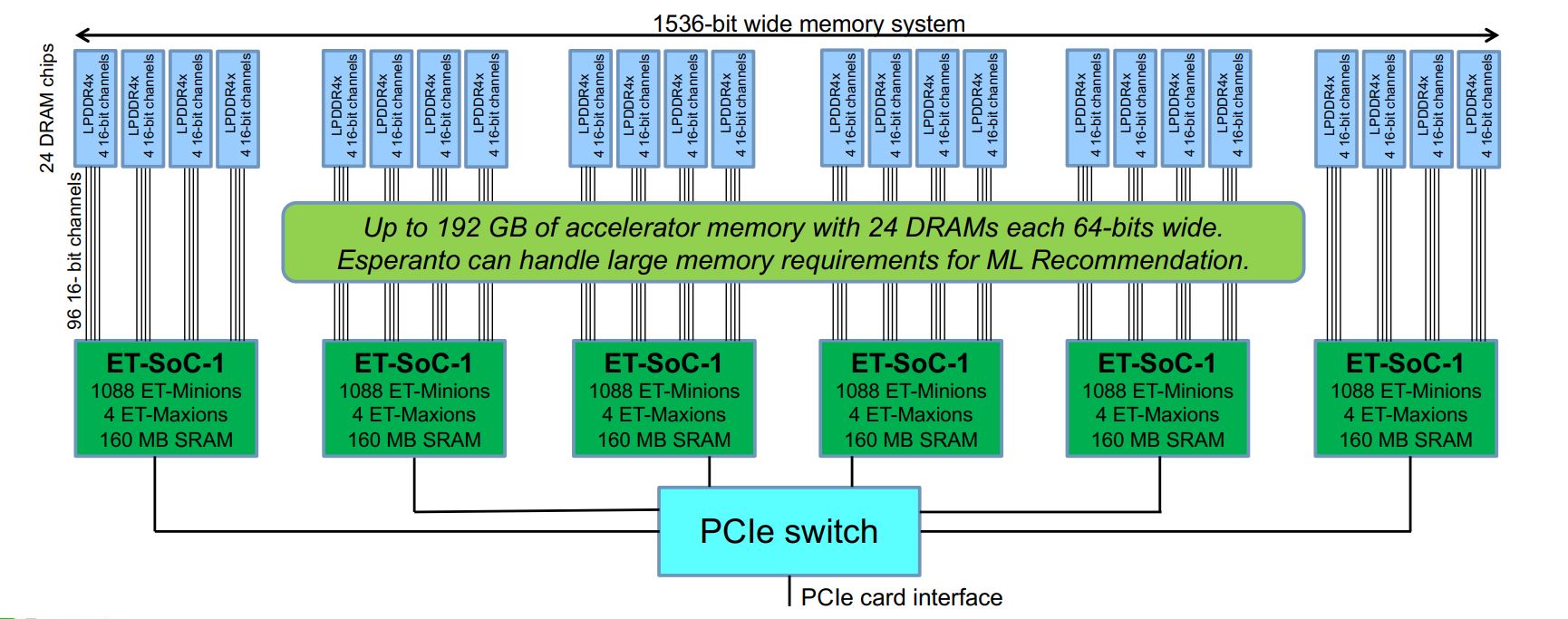
Esperanto 聲稱通過(guò)使用六個(gè)較小的芯片而不是單個(gè)大芯片解決了內(nèi)存瓶頸,留下可用于連接 LPDDR4x 芯片的引腳(來(lái)源:Esperanto)
Esperanto 的多芯片方法使更多引腳可用于與片外 DRAM 通信。除了六個(gè)處理器芯片外,該公司還使用了 24 個(gè)專(zhuān)為手機(jī)設(shè)計(jì)的廉價(jià) LPDDR4x DRAM 芯片,在低電壓下運(yùn)行,“每比特能量與 HBM 大致相同”,Ditzel 說(shuō)。
“因?yàn)?[LPDDR4x] 的帶寬 [比 HBM] 低,我們通過(guò)更寬獲得更多帶寬,”他補(bǔ)充道。“我們?cè)诩铀倨骺ㄉ系膬?nèi)存系統(tǒng)上使用 1,500 位寬 [而單芯片競(jìng)爭(zhēng)對(duì)手] 負(fù)擔(dān)不起 1,500 位寬的內(nèi)存系統(tǒng),因?yàn)閷?duì)于每個(gè)數(shù)據(jù)引腳,你必須有幾個(gè)電源和幾個(gè)接地針,針太多了。
“我們之前處理過(guò)這個(gè)問(wèn)題,我們說(shuō),讓我們分開(kāi)吧。”
通過(guò) 822 GB/s 的內(nèi)存帶寬訪問(wèn) 192 GB 的總內(nèi)存容量。所有 64 位 DRAM 芯片的總和計(jì)算出 1536 位寬的內(nèi)存系統(tǒng),分成 96 個(gè) 16 位通道以更好地處理內(nèi)存延遲。這一切都符合 120 W 的功率預(yù)算。
流水線權(quán)重
晶圓級(jí) AI 加速器公司 Cerebras 設(shè)計(jì)了一個(gè)規(guī)模遠(yuǎn)端的內(nèi)存瓶頸解決方案。在 Hot Chips 上,該公司發(fā)布了 MemoryX,這是一款用于其 CS-2 AI 加速器系統(tǒng)的內(nèi)存擴(kuò)展系統(tǒng),旨在實(shí)現(xiàn)高性能計(jì)算和科學(xué)工作負(fù)載。MemoryX 尋求能夠訓(xùn)練具有萬(wàn)億或參數(shù)的巨大 AI 模型。

Cerebras 的 MemoryX 系統(tǒng)是其 CS-2 晶圓級(jí)引擎系統(tǒng)的片外內(nèi)存擴(kuò)展,其行為就像在片上一樣(來(lái)源:Cerebras)
MemoryX 是 DRAM 和閃存的組合,其行為就像在芯片上一樣。該架構(gòu)被提升為彈性,旨在容納 4 TB 到 2.4 PB(2000 億到 120 萬(wàn)億個(gè)參數(shù)),足以容納世界上最大的 AI 模型。
Cerebras 的聯(lián)合創(chuàng)始人兼首席硬件架構(gòu)師 Sean Lie 表示,為了使其片外內(nèi)存表現(xiàn)得像片上一樣,Cerebras 優(yōu)化了 MemoryX,以消除延遲影響的方式將參數(shù)和權(quán)重?cái)?shù)據(jù)流式傳輸?shù)教幚砥鳌?/p>
“我們將內(nèi)存與計(jì)算分開(kāi),從根本上分解它們,”他說(shuō)。“通過(guò)這樣做,我們使溝通變得優(yōu)雅而直接。我們可以這樣做的原因是神經(jīng)網(wǎng)絡(luò)對(duì)模型的不同組件使用不同的內(nèi)存。因此,我們可以為每種類(lèi)型的內(nèi)存和每種類(lèi)型的計(jì)算設(shè)計(jì)一個(gè)專(zhuān)門(mén)構(gòu)建的解決方案……”
結(jié)果,這些組件被解開(kāi),從而“簡(jiǎn)化了縮放問(wèn)題,”Lie 說(shuō)。
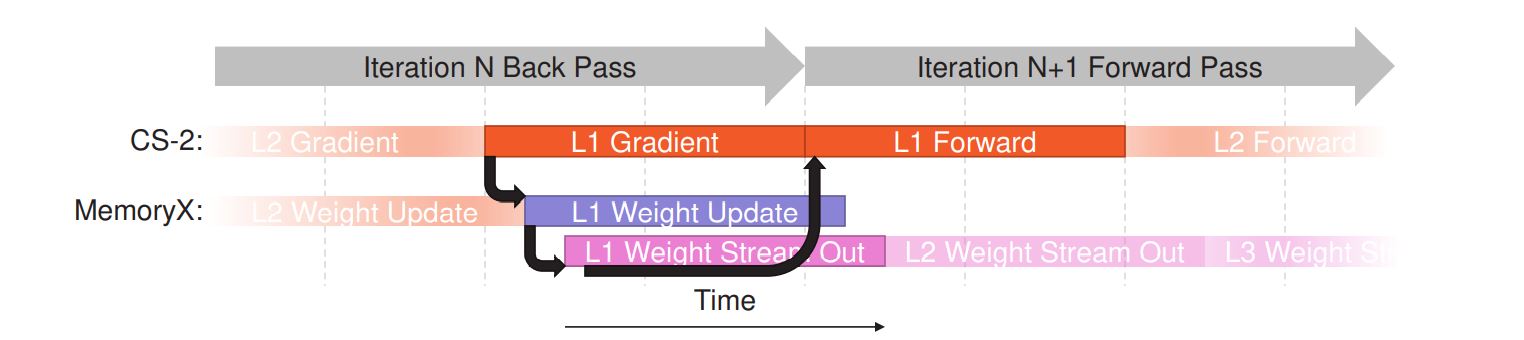
Cerebras 使用流水線在 AI 訓(xùn)練期間消除對(duì)延遲敏感的通信。(來(lái)源:大腦)
在訓(xùn)練期間,必須立即訪問(wèn)對(duì)延遲敏感的激活記憶。因此,Cerebras 將激活保留在芯片上。
Cerebras 將權(quán)重存儲(chǔ)在 MemoryX 上,然后根據(jù)需要將它們流式傳輸?shù)叫酒稀ie 說(shuō),在沒(méi)有背靠背依賴性的情況下,權(quán)重記憶的使用相對(duì)較少。這可以用來(lái)避免延遲和性能瓶頸。粗粒度流水線還避免了層之間的依賴關(guān)系;層的權(quán)重在前一層完成之前開(kāi)始流式傳輸。
同時(shí),細(xì)粒度流水線避免了訓(xùn)練迭代之間的依賴關(guān)系;后向傳播中的權(quán)重更新與同一層的后續(xù)前向傳播重疊。
“通過(guò)使用這些流水線技術(shù),權(quán)重流執(zhí)行模型可以隱藏外部權(quán)重的額外延遲,如果權(quán)重在晶圓上本地 [訪問(wèn)],我們可以達(dá)到相同的性能,”Lie 說(shuō)。
審核編輯 黃昊宇
-
內(nèi)存
+關(guān)注
關(guān)注
8文章
3121瀏覽量
75241 -
AI
+關(guān)注
關(guān)注
88文章
35065瀏覽量
279385
發(fā)布評(píng)論請(qǐng)先 登錄
拋棄8GB內(nèi)存,端側(cè)AI大模型加速內(nèi)存升級(jí)

內(nèi)存擴(kuò)展CXL加速發(fā)展,繁榮AI存儲(chǔ)

是德科技如何應(yīng)對(duì)AI數(shù)據(jù)中心擴(kuò)展瓶頸

Arm如何應(yīng)對(duì)復(fù)雜的全球AI監(jiān)管
DeepSeek推動(dòng)AI算力需求:800G光模塊的關(guān)鍵作用

【銀河講堂】AI時(shí)代,電力電子工程師如何不被替代?聽(tīng)聽(tīng)不同AI怎么說(shuō)# AI# 人工智能# deepseek
Banana Pi 發(fā)布 BPI-AI2N & BPI-AI2N Carrier,助力 AI 計(jì)算與嵌入式開(kāi)發(fā)
【Simcenter FLOEFD】利用完全嵌入CAD的CFD軟件,幫助設(shè)計(jì)師盡早評(píng)估流體流動(dòng)和傳熱,從而縮短開(kāi)發(fā)時(shí)間






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論