 用于加速嵌入式視覺和推理的開放標準
用于加速嵌入式視覺和推理的開放標準

機器學習領域的不斷發展為部署利用神經網絡推理的設備和應用程序創造了新的機會,這些設備和應用程序具有前所未有的基于視覺的功能和準確性水平。但是,快速發展的領域已經讓位于處理器、加速器和庫的混亂局面。本文介紹了開放互操作性標準及其在降低成本和降低在實際產品中使用推理和視覺加速的障礙方面的作用。
每個行業都需要開放標準,通過增加生態系統元素之間的互操作性來降低成本和縮短上市時間。開放標準和專有技術具有復雜且相互依存的關系。專有 API 和接口通常是達爾文式的試驗場,并且可以在聰明的市場領導者手中保持主導地位,這也是理所當然的。強大的開放標準源于行業對成熟技術的更廣泛需求,可以提供健康、激勵的競爭。從長遠來看,不受任何一家公司控制或依賴于任何一家公司的開放標準通常可以成為行業向前發展的連續性線索,因為技術、平臺和市場地位不斷變化和發展。
Khronos Group 是一個非營利性標準聯盟,任何公司都可以加入,擁有超過 150 名成員。所有標準組織的存在都是為了為競爭者提供一個安全的場所,讓他們為了所有人的利益進行合作。Khronos Group 的專業領域是創建開放、免版稅的 API 標準,使軟件應用程序庫和引擎能夠利用硅加速的力量來滿足要求苛刻的用例,例如 3D 圖形、并行計算、視覺處理和推理。
創建嵌入式機器學習應用程序
許多互操作部分需要協同工作來訓練神經網絡并將其成功部署在嵌入式加速推理平臺上——如圖 1 所示。有效的神經網絡訓練通常需要大型數據集,使用浮點精度并在強大的 GPU 上運行- 加速臺式機或云端。訓練完成后,經過訓練的神經網絡將被引入為快速張量操作優化的推理運行時引擎,或將神經網絡描述轉換為可執行代碼的機器學習編譯器。無論使用引擎還是編譯器,最后一步都是在從 GPU 到專用張量處理器的各種加速器架構之一上加速推理代碼。
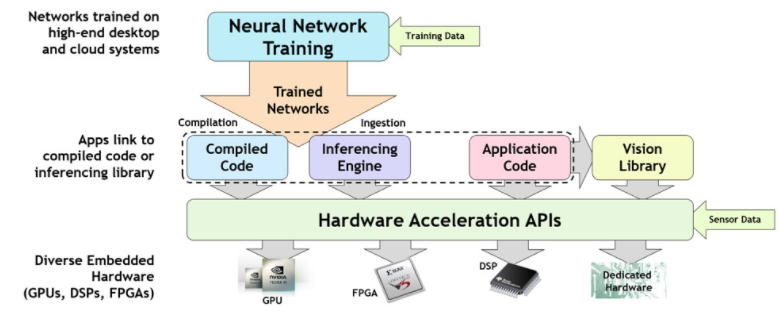
圖 1. 訓練神經網絡并將其部署在加速推理平臺上的步驟
那么,行業開放標準如何幫助簡化這一過程呢?圖 2. 說明了在視覺和推理加速領域中使用的 Khronos 標準。總的來說,隨著處理器頻率擴展讓位于并行編程作為以可接受的成本和功率水平提供所需性能的最有效方式,人們對所有這些標準的興趣越來越大。
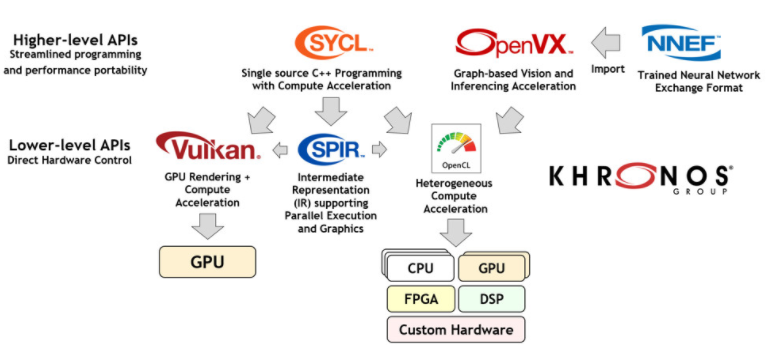
圖 2. 用于加速視覺和推理應用程序和引擎的 Khronos 標準
從廣義上講,這些標準可以分為兩組:高級和低級。高級 API 側重于易于編程,具有跨多個硬件架構的有效性能可移植性。相比之下,低級 API 提供對硬件資源的直接、顯式訪問,以實現最大的靈活性和控制。每個項目都必須了解最適合其開發需求的 API 級別。此外,高級 API 通常會在其實現中使用低級 API。
讓我們更詳細地了解其中的一些 Khronos 標準。
SYCL - C++ 單源異構編程
SYCL(發音為“鐮刀”)使用 C++ 模板庫來調度標準 ISO C++ 應用程序的選定部分以卸載處理器。SYCL 使復雜的 C++ 機器學習框架和庫能夠直接編譯并加速到在許多情況下優于手動調整代碼的性能水平。如圖 3 所示,默認情況下,SYCL 是通過較低級別的 OpenCL 標準 API 實現的:將用于加速的代碼提供給 OpenCL,而剩余的主機代碼則通過系統的默認 CPU 編譯器提供。
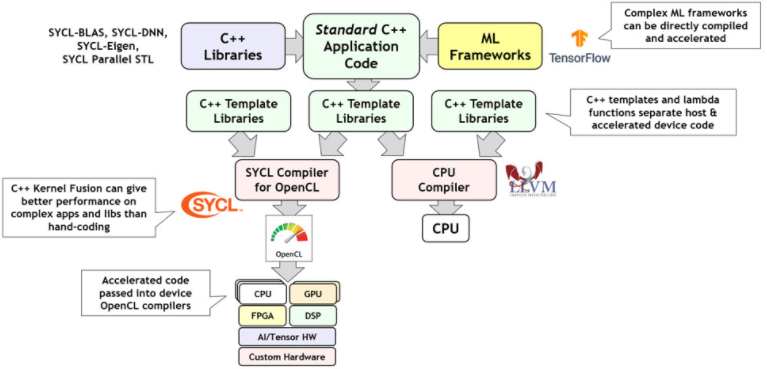
圖 3. SYCL 將標準 C++ 應用程序拆分為 CPU 和 OpenCL 加速代碼
越來越多的 SYCL 實現,其中一些使用專有后端,例如 NVIDIA 的 CUDA 用于加速代碼。值得注意的是,英特爾的新 oneAPI Initiative 包含一個名為 DPC++ 的并行 C++ 編譯器,它是基于 OpenCL 的符合 SYCL 實現。
NNEF——神經網絡交換格式
當今使用的神經網絡訓練框架有數十種,包括 Torch、Caffe、TensorFlow、Theano、Chainer、Caffe2、PyTorch 和 MXNet 等等,并且都使用專有格式來描述他們訓練的網絡。還有數十種甚至數百種嵌入式推理處理器進入市場。迫使許多硬件供應商理解和導入如此多的格式是一個典型的碎片問題,可以通過如圖 4 所示的開放標準來解決。
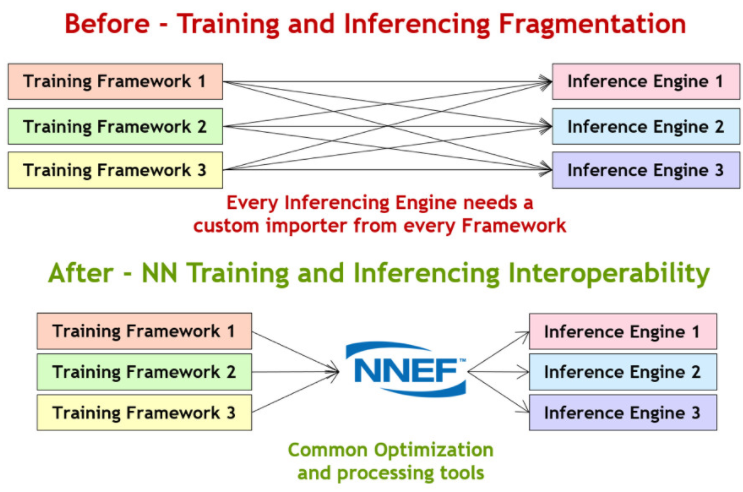
圖 4. NNEF 神經網絡交換格式通過推理加速器簡化訓練網絡的攝取
NNEF 文件格式旨在在網絡訓練和推理芯片領域之間架起一座有效的橋梁——Khronos 久經考驗的多公司治理模型讓硬件社區對格式如何以一種滿足開發處理器工具鏈和框架的公司,通常在安全關鍵市場。
NNEF 并不是業界唯一的神經網絡交換格式,ONNX 是由 Facebook 和微軟共同創立的開源項目,是一種被廣泛采用的格式,主要專注于訓練框架之間的網絡交換。NNEF 和 ONNX 是互補的,因為 ONNX 跟蹤培訓創新和機器學習研究社區的快速變化,而 NNEF 的目標是嵌入式推理硬件供應商,這些供應商需要一種具有更深思熟慮的路線圖演變的格式。Khronos 圍繞 NNEF 發起了一個不斷發展的開源工具生態系統,包括來自關鍵框架的導入器和導出器以及一個模型動物園,以使硬件開發人員能夠測試他們的推理解決方案。
OpenVX – 便攜式加速視覺處理
OpenVX(VX 代表“視覺加速”)通過提供圖形級抽象來簡化視覺和推理軟件的開發,使程序員能夠通過連接一組函數或“節點”來構建他們所需的功能。這種高級抽象使芯片供應商能夠非常有效地優化他們的 OpenVX 驅動程序,以便在幾乎任何處理器架構上高效執行。隨著時間的推移,OpenVX 在原始視覺節點旁邊添加了推理功能——畢竟神經網絡只是另一個圖!通過將 NNEF 訓練的網絡直接導入 OpenVX 圖中,OpenVX 和 NNEF 之間的協同作用越來越大,如圖 5 所示。
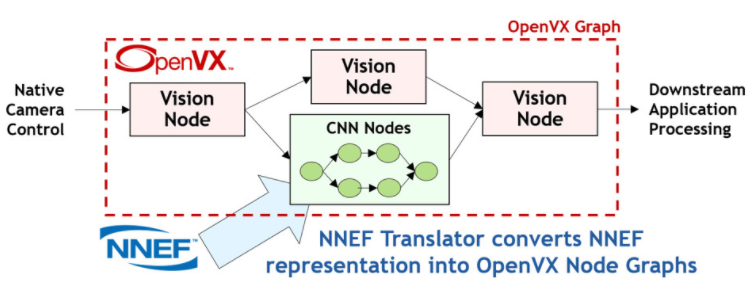
圖 5. OpenVX 圖可以描述從 NNEF 文件導入的視覺節點和推理操作的任意組合
OpenVX 1.3 于 2019 年 10 月發布,使針對垂直細分市場(例如推理)的精心挑選的規范子集能夠被實施和測試,使其符合官方標準。OpenVX 還與 OpenCL 深度集成,使程序員能夠添加自己的自定義加速節點以在 OpenVX 圖形中使用 - 提供簡單的可編程性和可定制性的獨特組合。
OpenCL – 異構并行編程
OpenCL 是一種低級標準,用于對 PC、服務器、移動設備和嵌入式設備中的各種異構處理器進行跨平臺并行編程。OpenCL 提供基于 C 和 C++ 的語言來構建內核程序,這些程序可以在具有 OpenCL 編譯器的系統中的任何處理器上并行編譯和執行,從而為程序員明確控制在哪些處理器上執行哪些內核。OpenCL 運行時協調加速器設備的發現,為選定的設備編譯內核,以復雜的同步級別執行內核并收集結果,如圖 6 所示。
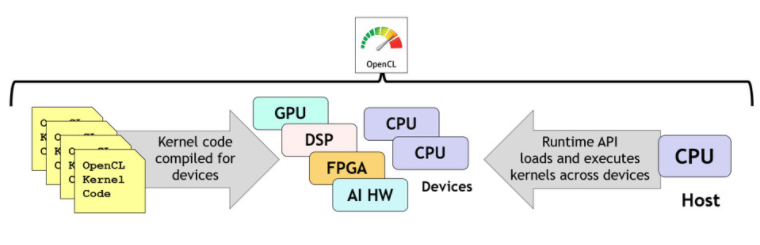
圖 6. OpenCL 使 C 或 C++ 內核程序能夠跨異構處理器的任意組合并行編譯和執行
OpenCL 在整個行業中廣泛使用,為計算、視覺和機器學習庫、引擎和編譯器提供最低的“接近金屬”執行層。
OpenCL 最初是為在高端 PC 和超級計算機硬件上執行而設計的,但在與 OpenVX 類似的演變過程中,需要 OpenCL 的處理器越來越小,精度越來越低,因為它們以邊緣視覺和推理為目標。OpenCL 工作組正在努力定義為嵌入式處理器量身定制的功能,并使供應商能夠交付針對關鍵功耗和成本敏感用例的選定功能,并且完全符合要求。
審核編輯:郭婷
-
處理器
+關注
關注
68文章
19884瀏覽量
235019 -
編譯器
+關注
關注
1文章
1661瀏覽量
50197 -
機器學習
+關注
關注
66文章
8501瀏覽量
134564
發布評論請先 登錄
Linux嵌入式和單片機嵌入式的區別?
嵌入式開發入門指南:從零開始學習嵌入式
使用Lattice mVision打造嵌入式視覺系統解決方案

嵌入式超火的方向有哪些?
嵌入式和人工智能究竟是什么關系?
什么是嵌入式?一文讀懂嵌入式主板
AMD 面向嵌入式系統推出高能效 EPYC 嵌入式 8004 系列

嵌入式主板是什么意思?嵌入式主板全面解析
飛凌嵌入式「在線文檔」功能上線 | 開放靈活,盡在掌握

嵌入式linux開發板芯片的工作原理
適用于標準化嵌入式網絡,CANopen有什么不同?
Astra? SL系列SL1680詳細介紹,嵌入式物聯網處理器





 工商網監
工商網監
評論