 提高Kubernetes的GPU利用率
提高Kubernetes的GPU利用率
為了實現可擴展的數據中心性能, NVIDIA GPU 已成為必備產品。
NVIDIA GPU 由數千個計算核支持的并行處理能力對于加速不同行業的各種應用至關重要。目前,跨多個行業的計算密集型應用程序使用 GPU :
高性能計算,如航空航天、生物科學研究或天氣預報
使用 AI 改進搜索、推薦、語言翻譯或交通(如自動駕駛)的消費者應用程序
醫療保健,如增強型醫療成像
財務,如欺詐檢測
娛樂,如視覺效果
此范圍內的不同應用程序可能有不同的計算要求。訓練巨型人工智能模型,其中 GPU 批處理并行處理數百個數據樣本,使 GPU 在訓練過程中得到充分利用。然而,許多其他應用程序類型可能只需要 GPU 計算的一小部分,從而導致大量計算能力的利用不足。
在這種情況下,為每個工作負載提供適當大小的 GPU 加速是提高利用率和降低部署運營成本的關鍵,無論是在本地還是在云中。
為了解決 Kubernetes ( K8s )集群中 GPU 利用率的挑戰, NVIDIA 提供了多種 GPU 并發和共享機制,以適應廣泛的用例。最新添加的是新的 GPU 時間切片 API ,現在在 Kubernetes 中廣泛可用,具有 NVIDIA K8s 設備插件 0.12.0 和 NVIDIA GPU 操作符 1.11 。它們共同支持多個 GPU 加速工作負載的時間分割,并在單個 NVIDIA GPU 上運行。
在深入研究這一新功能之前,這里有一些關于您應該考慮共享 GPU 的用例的背景知識,并概述了所有可用的技術。
何時共享 NVIDIA GPU
以下是共享 GPU 資源以提高利用率的一些示例工作負載:
低批量推理服務 ,它只能在 GPU 上處理一個輸入樣本
高性能計算( HPC )應用 ,例如模擬光子傳播,在 CPU (讀取和處理輸入)和 GPU (執行計算)之間平衡計算。由于 CPU 核心性能的瓶頸,一些 HPC 應用程序可能無法在 GPU 部分實現高吞吐量。
ML 模型探索的交互式開發 使用 Jupyter 筆記本電腦
基于 Spark 的數據分析應用程序 ,其中一些任務或最小的工作單元同時運行,并受益于更好的 GPU 利用率
可視化或脫機渲染應用程序 這可能是突發性的
希望使用任何可用的 GPU 進行測試的 連續集成/連續交付( CICD )管道
在本文中,我們將探討在 Kubernetes 集群中共享 NVIDIA GPU 訪問權限的各種技術,包括如何使用這些技術以及在選擇正確方法時需要考慮的權衡。
GPU 并發機制
NVIDIA GPU 硬件結合 CUDA 編程模型,提供了許多不同的并發機制,以提高 GPU 的利用率。這些機制包括從編程模型 API (應用程序需要更改代碼以利用并發)到系統軟件和硬件分區(包括虛擬化),這對應用程序是透明的(圖 1 )。
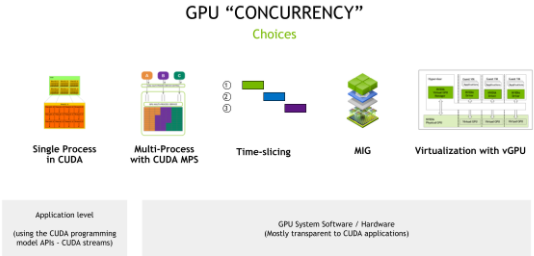
圖 1 GPU 并發機制
CUDA 流
CUDA 的異步模型意味著您可以使用 CUDA 流,通過單個 CUDA 上下文(類似于 GPU 端的主機進程)并發執行許多操作。
流是一種軟件抽象,它表示一系列命令,這些命令可能是按順序執行的計算內核、內存拷貝等的組合。在兩個不同流中啟動的工作可以同時執行,從而實現粗粒度并行。應用程序可以使用 CUDA 流和 優先級 流管理并行性。
CUDA 流最大化了推理服務的 GPU 利用率,例如,通過使用流并行運行多個模型。您可以縮放相同的模型,也可以提供不同的模型。有關更多信息,請參閱 異步并發執行 。
與 streams 的權衡是,這些 API 只能在單個應用程序中使用,因此提供了有限的硬件隔離,因為所有資源都是共享的,并且可以在各種流之間進行錯誤隔離。
時間分片
在處理多個 CUDA 應用程序時,每個應用程序都可能沒有充分利用 GPU 的資源,您可以使用簡單的超額訂閱策略來利用 GPU 的時間切片調度器。從 Pascal 體系結構開始, compute preemption 支持這一點。這種技術有時被稱為暫時 GPU 共享,在不同的 CUDA 應用程序之間切換上下文確實會帶來成本,但一些未充分利用的應用程序仍然可以從該策略中受益。
由于 CUDA 11.1 ( R455 +驅動程序), CUDA 應用程序的時間片持續時間可通過nvidia-smi實用程序:
$ nvidia-smi compute-policy --help Compute Policy -- Control and list compute policies. Usage: nvidia-smi compute-policy [options] Options include: [-i | --id]: GPU device ID's. Provide comma separated values for more than one device [-l | --list]: List all compute policies [ | --set-timeslice]: Set timeslice config for a GPU: 0=DEFAULT, 1=SHORT, 2=MEDIUM, 3=LONG [-h | --help]: Display help information
當許多不同的應用程序在 GPU 上進行時間切片時,時間切片的折衷是增加延遲、抖動和潛在的內存不足( OOM )情況。這一機制是我們在本文第二部分重點關注的。
CUDA 多進程服務
您可以進一步使用前面描述的超額預訂策略 CUDA MPS 。 當每個進程太小而無法使 GPU 的計算資源飽和時, MPS 允許來自不同進程(通常是 MPI 列)的 CUDA 內核在 GPU 上并發處理。與時間切片不同, MPS 允許來自不同進程的 CUDA 內核在 GPU 上并行執行。
CUDA 的較新版本(自 CUDA 11.4 +以來)增加了更多細粒度資源調配,能夠指定 MPS 客戶端可分配內存量(CUDA_MPS_PINNED_DEVICE_MEM_LIMIT)和可用計算量(CUDA_MPS_ACTIVE_THREAD_PERCENTAGE)的限制。有關這些調諧旋鈕用法的更多信息,請參閱 Volta MPS 執行資源調配 。
與 MPS 的權衡是錯誤隔離、內存保護和服務質量( QoS )的限制。所有 MPS 客戶端仍然共享 GPU 硬件資源。你今天可以通過 Kubernetes (庫伯內特斯)訪問 CUDA 議員,但 NVIDIA 計劃在未來幾個月改善對議員的支持。
多實例 GPU ( MIG )
迄今為止討論的機制要么依賴于使用 CUDA 編程模型 API (如 CUDA 流)對應用程序的更改,要么依賴于 CUDA 系統軟件(如時間切片或 MPS )。
使用 MIG ,基于 NVIDIA 安培體系結構的 GPU ,例如 NVIDIA A100 ,可以為 CUDA 應用程序安全劃分多達七個獨立的 GPU 實例,為多個應用程序提供專用的 GPU 資源。這些包括流式多處理器( SMs )和 GPU 引擎,如復制引擎或解碼器,為不同的客戶端(如進程、容器或虛擬機( VM ))提供定義的 QoS 和故障隔離。
當對 GPU 進行分區時,可以在單個 MIG 實例中使用之前的 CUDA 流、 CUDA MPS 和時間切片機制。
有關更多信息,請參閱 MIG 用戶指南 和 MIG 支持 Kubernetes 。
使用 vGPU 實現虛擬化
NVIDIA vGPU 使具有完全輸入輸出內存管理單元( IOMMU )保護的虛擬機能夠同時直接訪問單個物理 GPU 。除了安全性之外, NVIDIA v GPU 還帶來了其他好處,如通過實時虛擬機遷移進行虛擬機管理,能夠運行混合的 VDI 和計算工作負載,以及與許多行業虛擬機監控程序的集成。
在支持 MIG 的 GPU 上,每個 GPU 分區都作為 VM 的單根 I / O 虛擬化( SR-IOV )虛擬功能公開。所有虛擬機都可以并行運行,而不是分時間運行(在不支持 MIG 的 GPU 上)。
表 1 總結了這些技術,包括何時考慮這些并發機制。

在這種背景下,本文的其余部分將重點介紹使用 Kubernetes 中新的時間切片 API 超額訂閱 GPU 。
Kubernetes 中的時間切片支持
NVIDIA GPU 是 推廣為 通過 設備插件框架 作為 Kubernetes 中的可調度資源。然而,此框架僅允許將設備(包括 GPU (作為nvidia.com/gpu)作為整數資源進行廣告,因此不允許過度訂閱。在本節中,我們將討論一種使用時間切片在 Kubernetes 中超額訂閱 GPU 的新方法。
在討論新的 API 之前,我們將介紹一種新的機制,用于使用配置文件配置 NVIDIA Kubernetes 設備插件。
新配置文件支持
Kubernetes 設備插件提供了許多配置選項,這些選項可以設置為命令行選項或環境變量,例如設置 MIG 策略、設備枚舉等。類似地, gpu-feature-discovery ( GFD )使用類似的選項來生成標簽來描述 GPU 節點。
隨著配置選項變得越來越復雜,您可以使用配置文件將這些選項表示為 Kubernetes 設備插件和 GFD ,然后將其部署為configmap對象,并在啟動期間應用于插件和 GFD 吊艙。
配置選項在 YAML 文件中表示。在以下示例中,您將各種選項記錄在名為dp-example-config.yaml的文件中,該文件是在/tmp下創建的。
$ cat << EOF > /tmp/dp-example-config.yaml version: v1 flags: migStrategy: "none" failOnInitError: true nvidiaDriverRoot: "/" plugin: passDeviceSpecs: false deviceListStrategy: "envvar" deviceIDStrategy: "uuid" gfd: oneshot: false noTimestamp: false outputFile: /etc/kubernetes/node-feature-discovery/features.d/gfd sleepInterval: 60s EOF
然后,通過指定配置文件的位置并使用gfd.enabled=true選項啟動 GFD 來啟動 Kubernetes 設備插件:
$ helm install nvdp nvdp/nvidia-device-plugin \ --version=0.12.2 \ --namespace nvidia-device-plugin \ --create-namespace \ --set gfd.enabled=true \ --set-file config.map.config=/tmp/dp-example-config.yaml
動態配置更改
默認情況下,該配置應用于所有節點上的所有 GPU 。 Kubernetes 設備插件允許指定多個配置文件。通過覆蓋節點上的標簽,可以逐個節點覆蓋配置。
Kubernetes 設備插件使用一個 sidecar 容器來檢測所需節點配置中的更改,并重新加載設備插件,以便新配置能夠生效。在以下示例中,您為設備插件創建了兩種配置:一種默認配置應用于所有節點,另一種配置可根據需要應用于 100 個 GPU 節點。
$ helm install nvdp nvdp/nvidia-device-plugin \ --version=0.12.2 \ --namespace nvidia-device-plugin \ --create-namespace \ --set gfd.enabled=true \ --set-file config.map.default=/tmp/dp-example-config-default.yaml \ --set-file config.map.a100-80gb-config=/tmp/dp-example-config-a100.yaml
然后,只要覆蓋節點標簽, Kubernetes 設備插件就可以對配置進行動態更改,如果需要,可以在每個節點的基礎上進行配置:
$ kubectl label node \ --overwrite \ --selector=nvidia.com/gpu.product=A100-SXM4-80GB \ nvidia.com/device-plugin.config=a100-80gb-config
時間切片 API
為了支持 GPU 的時間切片,可以使用以下字段擴展配置文件的定義:
version: v1 sharing: timeSlicing: renameByDefault:failRequestsGreaterThanOne: resources: - name: replicas: ...
也就是說,對于sharing.timeSlicing.resources下的每個命名資源,現在可以為該資源類型指定多個副本。
此外,如果renameByDefault=true,則每個資源都會在名稱下播發《reZEDZ_insteadofismpl_E H1-31。
對于向后兼容性,failRequestsGreaterThanOne標志默認為 false 。它控制 POD 是否可以請求多個 GPU 資源。一個以上的 GPU 請求并不意味著 pod 會按比例獲得更多的時間片,因為 GPU 調度器當前為 GPU 上運行的所有進程提供相等的時間份額。
failRequestsGreaterThanOne標志配置插件的行為,將一個 GPU 的請求視為訪問請求,而不是獨占資源請求。
創建新的超額訂閱資源時, Kubernetes 設備插件會將這些資源分配給請求的作業。當兩個或多個作業落在同一 GPU 上時,這些作業會自動使用 GPU 的時間切片機制。該插件不提供任何其他額外的隔離好處。
GFD 應用的標簽
對于 GFD ,應用的標簽取決于renameByDefault=true。無論renameByDefault的設置如何,始終應用以下標簽:
nvidia.com/.replicas =
但是,當renameByDefault=false時,nvidia.com/《resource-name》.product標簽也會添加以下后綴:
nvidia.com/gpu.product =-SHARED
使用這些標簽,您可以選擇共享或非共享 GPU ,就像您傳統上選擇一個 GPU 模型而不是另一個模型一樣。也就是說,SHARED注釋確保可以使用nodeSelector對象將吊艙吸引到在其上共享 GPU 的節點。此外, POD 可以確保它們降落在使用新副本標簽將 GPU 劃分為所需比例的節點上。
超額認購示例
下面是一個使用時間切片 API 過度訂閱 GPU 資源的完整示例。在本例中,您將遍歷 Kubernetes 設備插件和 GFD 的其他配置設置,以設置 GPU 超額訂閱并使用指定的資源啟動工作負載。
考慮以下配置文件:
version: v1 sharing: timeSlicing: resources: - name: nvidia.com/gpu replicas: 5 ...
如果將此配置應用于具有八個 GPU 的節點,則插件現在將向 Kubernetes 播發 40 個nvidia.com/gpu資源,而不是八個。如果設置了renameByDefault: true選項,則將播發 40 個nvidia.com/gpu.shared 資源,而不是 8 個nvidia.com/gpu資源。
您可以在以下示例配置中啟用時間切片。在本例中,超額認購 GPU 2 倍:
$ cat << EOF > /tmp/dp-example-config.yaml version: v1 flags: migStrategy: "none" failOnInitError: true nvidiaDriverRoot: "/" plugin: passDeviceSpecs: false deviceListStrategy: "envvar" deviceIDStrategy: "uuid" gfd: oneshot: false noTimestamp: false outputFile: /etc/kubernetes/node-feature-discovery/features.d/gfd sleepInterval: 60s sharing: timeSlicing: resources: - name: nvidia.com/gpu replicas: 2 EOF
設置舵圖存儲庫:
$ helm repo add nvdp https://nvidia.github.io/k8s-device-plugin \ && helm repo update
現在,通過指定前面創建的配置文件的位置來部署 Kubernetes 設備插件:
$ helm install nvdp nvdp/nvidia-device-plugin \ --version=0.12.2 \ --namespace nvidia-device-plugin \ --create-namespace \ --set gfd.enabled=true \ --set-file config.map.config=/tmp/dp-example-config.yaml
由于節點只有一個物理 GPU ,您現在可以看到設備插件發布了兩個可分配的 GPU :
$ kubectl describe node ... Capacity: cpu: 4 ephemeral-storage: 32461564Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 16084408Ki nvidia.com/gpu: 2 pods: 110 Allocatable: cpu: 4 ephemeral-storage: 29916577333 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 15982008Ki nvidia.com/gpu: 2 pods: 110
接下來,部署兩個應用程序(在本例中為 FP16 CUDA GEMM 工作負載),每個應用程序都請求一個 GPU 。觀察到應用程序上下文在 GPU 上切換,因此在 T4 上僅實現大約一半的 FP16 峰值帶寬。
$ cat << EOF | kubectl create -f - apiVersion: v1 kind: Pod metadata: name: dcgmproftester-1 spec: restartPolicy: "Never" containers: - name: dcgmproftester11 image: nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04 args: ["--no-dcgm-validation", "-t 1004", "-d 30"] resources: limits: nvidia.com/gpu: 1 securityContext: capabilities: add: ["SYS_ADMIN"] --- apiVersion: v1 kind: Pod metadata: name: dcgmproftester-2 spec: restartPolicy: "Never" containers: - name: dcgmproftester11 image: nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04 args: ["--no-dcgm-validation", "-t 1004", "-d 30"] resources: limits: nvidia.com/gpu: 1 securityContext: capabilities: add: ["SYS_ADMIN"] EOF
現在,您可以看到在單個物理 GPU 上部署和運行的兩個容器,如果沒有新的時間切片 API ,這在 Kubernetes 是不可能的:
$ kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE default dcgmproftester-1 1/1 Running 0 45s default dcgmproftester-2 1/1 Running 0 45s kube-system calico-kube-controllers-6fcb5c5bcf-cl5h5 1/1 Running 3 32d
您可以在主機上使用nvidia-smi,通過 GPU 上的插件和上下文開關,查看兩個容器在相同的物理 GPU 上的調度:
$ nvidia-smi -L GPU 0: Tesla T4 (UUID: GPU-491287c9-bc95-b926-a488-9503064e72a1) $ nvidia-smi ...... +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 466420 C /usr/bin/dcgmproftester11 315MiB | | 0 N/A N/A 466421 C /usr/bin/dcgmproftester11 315MiB | +-----------------------------------------------------------------------------+
總結
開始利用 新的 GPU 超額訂閱支持 今天在庫伯內特斯。 Kubernetes 設備插件新版本的 Helm 圖表使您可以輕松地立即開始使用該功能。
短期路線圖包括與 NVIDIA GPU 運算符 這樣,您就可以訪問該功能,無論是使用 Red Hat 的 OpenShift 、 VMware Tanzu ,還是使用 NVIDIA LaunchPad 上的 NVIDIA 云本機核心 等調配環境。 NVIDIA 還致力于改進 Kubernetes 設備插件中對 CUDA MPS 的支持,以便您可以利用 Kubernetes 中的其他 GPU 并發機制。
關于作者
Kevin Klues 是 NVIDIA 原始云團隊的首席軟件工程師。自加入 NVIDIA 以來, Kevin 一直參與多項技術的設計和實施,包括 Kubernetes 拓撲管理器、 NVIDIA 的 Kubernetes 設備插件和 MIG 的容器/ Kubernetes 堆棧。
Kyrylo Perelygin 自 2013 年加入 NVIDIA 后,一直致力于 CUDA 的多進程服務和新的合作團隊等功能。 Kyrylo 畢業于 EPITECH ,獲得學士學位,并獲得 CSULB 碩士學位。
Pramod Ramarao 是 NVIDIA 加速計算的產品經理。他領導 CUDA 平臺和數據中心軟件的產品管理,包括容器技術。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5238瀏覽量
105757 -
gpu
+關注
關注
28文章
4909瀏覽量
130646 -
CUDA
+關注
關注
0文章
122瀏覽量
14055
發布評論請先 登錄
mes工廠管理系統:如何讓設備利用率提升50%?
DeepSeek MoE架構下的網絡負載如何優化?解鎖90%網絡利用率的關鍵策略

三星平澤晶圓代工產線恢復運營,6月沖刺最大產能利用率
源網荷儲充一體化,提高能源利用率和電網消納能力

《CST Studio Suite 2024 GPU加速計算指南》
低空載功耗,高能源利用率 BDA5-20W BOSHIDA DCDC

華納云:什么是負載均衡?優化資源利用率的策略
如何提高GPU性能
交換機內存利用率過高會是什么問題
代理IP的使用率和使用時長,主要被什么影響?

異構混訓整合不同架構芯片資源,提高算力利用率
臺積電產能分化:6/7nm降價應對低利用率,3/5nm漲價因供不應求
鎧俠產能利用率全面復蘇,218層NAND Flash即將量產
DC/AC電源模塊:提升光伏發電系統的能源利用率






 工商網監
工商網監
評論