") RapidIO針對低延遲處理器連接進行優(yōu)化
RapidIO針對低延遲處理器連接進行優(yōu)化

隨著摩爾定律繼續(xù)推動處理器的性能和集成,對更高速互連的需求也在持續(xù)增長。今天的互連通常運動速度從 10 Gbps 到 80 Gbps 不等,并且具有達到每秒數百千兆位的路線圖。
在爭取越來越快的互連速度的競賽中,一些話題很少被討論,包括支持的事務類型、通信延遲和開銷,以及可以輕松支持的拓撲類型。設計人員傾向于認為所有互連都是平等的,并且具有僅基于峰值帶寬的品質因數。
現實完全不同。正如針對通用、信號處理、圖形和通信應用優(yōu)化的不同形式的處理器一樣,互連也針對不同的連接問題進行設計和優(yōu)化。互連通常可以解決其設計的問題,并且可以投入使用以解決其他應用程序,但在這些應用程序中效率會降低。
RapidIO 設計目標
在這種情況下查看 RapidIO 是有啟發(fā)性的。RapidIO 旨在用作低延遲處理器互連,用于需要高可靠性、低延遲和確定性操作的嵌入式系統。它旨在將來自不同制造商的不同類型的處理器連接到一個系統中。正因為如此,RapidIO 已在無線基礎設施設備中得到廣泛應用,其中需要將通用、數字信號、FPGA 和通信處理器結合在一個緊密耦合的系統中,具有低延遲和高可靠性。
RapidIO 的使用模型需要提供對內存到內存事務的支持,包括原子讀取-修改-寫入操作。為滿足這些要求,RapidIO 提供了無需軟件干預即可實現的遠程直接內存訪問 (RDMA)、消息傳遞和信令結構。例如,在 RapidIO 系統中,處理器可以發(fā)出加載或存儲事務,或者集成的 DMA 引擎可以在兩個內存位置之間傳輸數據。這些操作在其源或目標地址所在的 RapidIO 結構中執(zhí)行,并且通常無需任何軟件干預即可發(fā)生。從處理器看來,它們與普通的內存事務沒有什么不同。
RapidIO 還旨在支持點對點交易。假設系統中有多個主機或主處理器,并且這些處理器需要通過共享內存、中斷和消息相互通信。在 RapidIO 網絡中可以配置多個處理器(最高 16K),每個處理器都有自己的完整地址空間。
RapidIO 還在交換機和端點的功能之間提供了清晰的分界線。RapidIO 交換機僅根據明確的源/目標地址對和明確的優(yōu)先級做出切換決策。這允許 RapidIO 端點添加新的事務類型,而無需更改或增強交換設備。
比較互連
隨著越來越多的系統被集成到單個硅片上,PCI Express (PCIe) 和以太網正在集成到片上系統 (SoC) 中。然而,這種集成并沒有改變這些互連提供的事務的性質(參見圖 1)。
圖 1: RapidIO、PCI Express 和以太網為連接處理器、I/O 和系統提供了不同的選項。
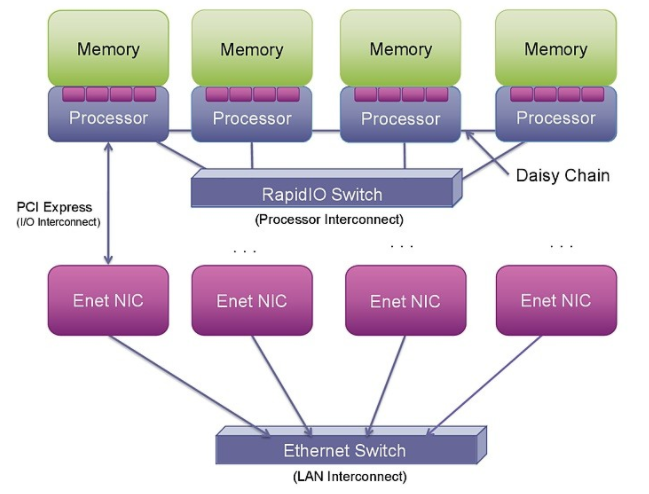
PCIe 本身并不支持點對點處理器連接。使用 PCIe 進行這種連接可能非常復雜,因為它被設計為外圍組件互連(因此是 PCI)。它旨在將外圍設備(通常是 I/O 和圖形芯片等從屬設備)連接到主主機處理器。它不是作為處理器互連設計的,而是作為 PCI 總線的串行版本。從 PCI 構建多處理器互連需要超越基本 PCI 規(guī)范的步驟,以創(chuàng)建在多個主機或根處理器之間映射地址空間和設備標識符的新機制。迄今為止,執(zhí)行此操作的提議機制——高級交換 (AS)、非透明橋接 (NTB) 或多根 I/O 虛擬化 (MR-IOV)——都沒有在商業(yè)上取得成功。
對于有明確的單一主機設備且其他處理器和加速器作為從設備運行的系統,PCIe 是連接的不錯選擇。然而,為了在更復雜的系統中將許多處理器連接在一起,PCIe 在拓撲結構和對等連接的支持方面存在很大限制。
許多開發(fā)人員正在尋求利用以太網作為連接系統中處理器的解決方案。在過去的 35 年中,以太網取得了長足的發(fā)展。與計算機處理速度的提高類似,其峰值帶寬也在穩(wěn)步增長。目前可用的以太網網絡接口控制器 (NIC) 卡可以支持 40 Gbps 運行,通過四對 SERDES 和 10 Gbps 信號傳輸。這樣的 NIC 卡本身包含重要的處理,能夠以這些速度傳輸和接收數據包。
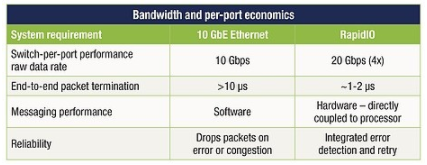
從解決方案到緊密耦合的處理器間通信,通過 NIC 發(fā)送和接收以太網數據包還有很長的路要走。與 PCIe 和以太網事務處理相關的開銷(兩個堆棧都必須在 NIC 中遍歷),加上相關的 SERDES 功能和以太網媒體訪問協議和交換增加了延遲、復雜性和更高的功耗以及系統成本可以使用更直接的連接方法(見表 1)。
表 1:以太網和 RapidIO 的比較顯示了更直接連接方法的優(yōu)勢。
將以太網用作集成嵌入式處理器互連需要對以太網媒體訪問控制器 (MAC) 以及以太網交換機設備本身進行顯著的事務加速和增強。即使有了這些增強,RDMA 操作也應該僅限于大塊交易,以分攤使用以太網的開銷。
已部署用于解決此問題的標準包括來自 Internet 工程任務組的 iWARP RDMA 協議和基于融合以太網的 RDMA (RoCE)。iWARP 和 RoCE 通常都是通過加速協處理器實現的。盡管有這種加速,但仍必須仔細管理 RDMA 事務以減少通信開銷。原因是盡管以太網提供了高帶寬,尤其是在 10 GbE 和 40 GbE 實施中,但它也具有通常以微秒為單位測量的高事務延遲。
當前的 RapidIO 應用程序
多年來,RapidIO 的價值主張已在嵌入式市場中得到廣泛認可。同樣的價值主張現在可以擴展到更主流的數據處理市場,這些市場正在演變?yōu)樾枰?a href="http://www.asorrir.com/tongxin/" target="_blank">通信網絡長期以來需要的許多相同的系統屬性。
其中使用 RapidIO 的一種眾所周知的應用是無線基站。該應用程序結合了多種形式的處理(DSP、通信和控制),必須在很短的時間內完成。處理設備之間的通信應盡可能快速和確定,以確保實現實時約束。
例如,在 4G 長期演進 (LTE) 無線網絡中,每 10 毫秒發(fā)送一次幀。這些幀包含多個并發(fā)移動會話的數據,分布在多個子載波上,由多個 DSP 設備支持。DSP 和通用處理設備之間的通信必須具有確定性和低延遲,以確保每 10 毫秒就有一個新幀準備好傳輸。同時,接收路徑必須支持來自連接到網絡的移動設備的數據。除了這種復雜性之外,系統還必須實時跟蹤移動設備的位置并管理設備的信號功率。
RapidIO 應用的另一個例子是半導體晶圓加工。與無線基礎設施應用類似,半導體晶圓加工具有實時限制,包括傳感器、處理和執(zhí)行器的控制回路。前沿系統通常有數百個傳感器收集信息,傳感器數據由數十到數百個處理節(jié)點處理。處理節(jié)點生成的命令發(fā)送到執(zhí)行器和交流和直流電機,以重新定位晶片和晶片成像子系統。這一切都是在頻率高達 100 kHz 或 10 微秒的循環(huán)控制循環(huán)中執(zhí)行的。像這樣的系統受益于設備之間可能的最低延遲通信。
高性能計算的未來
虛擬化、基于 ARM 的服務器和高度集成的 SoC 設備的引入正在為下一階段的高性能計算發(fā)展鋪平道路。這種演變正朝著更緊密耦合的處理器集群發(fā)展,這些集群代表為托管數百或數千臺虛擬機而構建的處理場。這些處理器集群將由多達數千個通過高性能、低延遲處理器互連連接的多核 SoC 設備組成。這種互連的效率越高,系統的性能和經濟性就越好。
PCIe 和 10 GbE 等技術不會很快消失,但它們不會成為這些未來緊密耦合計算系統的基礎。PCIe 不是一種結構,只能支持少量處理器和/或外圍設備的連接。它可以簡單地充當到結構網關設備的橋梁。雖然 10 GbE 可用作結構,但它具有重要的硬件和軟件協議處理要求。其廣泛可變的幀大小(巨型幀為 46 B 到 9,000 B)推動了對快速處理邏輯的需求,以支持多個小數據包和大型內存緩沖區(qū)以支持端點和交換機中的大數據包,從而提高了芯片成本。使用 PCIe 或 10 GbE 將限制可用的拓撲和連接,或者增加系統的成本和開銷。
實施集成的服務器、存儲和網絡系統為 OEM 提供了創(chuàng)新的機會。該創(chuàng)新的一個關鍵組成部分將是內部系統連接。RapidIO 是一項成熟的、經過充分驗證的技術,具有在該市場取得成功所需的屬性。與無線基礎設施的情況一樣,RapidIO 從早期創(chuàng)新發(fā)展成為事實上的基站互連標準,RapidIO 在服務器、存儲和高性能計算方面的最大挑戰(zhàn)將是跨越當今創(chuàng)新者和早期采用者市場的鴻溝大眾市場的擴散。
審核編輯:郭婷
-
處理器
+關注
關注
68文章
19884瀏覽量
235027 -
soc
+關注
關注
38文章
4385瀏覽量
222651 -
服務器
+關注
關注
13文章
9786瀏覽量
87907
發(fā)布評論請先 登錄
低功耗處理器的優(yōu)勢分析
如何將ADS1278通過SPI與處理器連接?
量子處理器是什么_量子處理器原理
恩智浦i.MX 94應用處理器如何變革工業(yè)和汽車連接
EE-340: SHARC處理器和Blackfin處理器的SPI連接

EE-197:ADSP-BF531/532/533 Blackfin處理器多周期指令和延遲
EE-171:ADSP-BF535 Blackfin處理器多周期指令和延遲
EE-324:Blackfin處理器的系統優(yōu)化技術
盛顯科技:解決投影融合處理器連接超時問題的步驟

盛顯科技:拼接處理器連接大屏方法是什么?

盛顯科技:投影融合處理器連接出現超時,該怎么辦?

針對TI汽車處理器新的SAFERTOS庫評估包







 工商網監(jiān)
工商網監(jiān)
評論