 微調前給預訓練模型參數增加噪音提高效果的方法
微調前給預訓練模型參數增加噪音提高效果的方法
寫在前面
昨天看完NoisyTune論文,做好實驗就來了。一篇ACL2022通過微調前給預訓練模型參數增加噪音提高預訓練語言模型在下游任務的效果方法-NoisyTune,論文全稱《NoisyTune: A Little Noise Can Help You Finetune Pretrained Language Models Better》。
paper地址:https://aclanthology.org/2022.acl-short.76.pdf
由于僅加兩行代碼就可以實現,就在自己的數據上進行了實驗,發現確實有所提高,為此分享給大家;不過值得注意的是,「不同數據需要加入噪音的程度是不同」,需要自行調參。
模型
自2018年BERT模型橫空出世,預訓練語言模型基本上已經成為了自然語言處理領域的標配,「pretrain+finetune」成為了主流方法,下游任務的效果與模型預訓練息息相關;然而由于預訓練機制以及數據影響,導致預訓練語言模型與下游任務存在一定的Gap,導致在finetune過程中,模型可能陷入局部最優。
為了減輕上述問題,提出了NoisyTune方法,即,在finetune前加入給預訓練模型的參數增加少量噪音,給原始模型增加一些擾動,從而提高預訓練語言模型在下游任務的效果,如下圖所示,
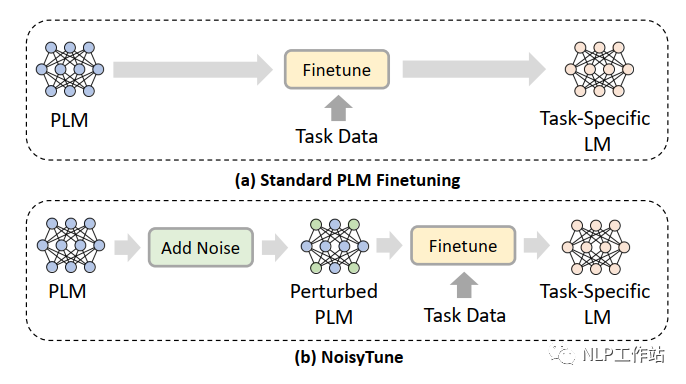
通過矩陣級擾動(matrix-wise perturbing)方法來增加噪聲,定義預訓練語言模型參數矩陣為,其中,表示模型中參數矩陣的個數,擾動如下:
其中,表示從到范圍內均勻分布的噪聲;表示控制噪聲強度的超參數;表示標準差。
代碼實現如下:
forname,parainmodel.namedparameters():
model.statedict()[name][:]+=(torch.rand(para.size())?0.5)*noise_lambda*torch.std(para)
這種增加噪聲的方法,可以應用到各種預訓練語言模型中,可插拔且操作簡單。
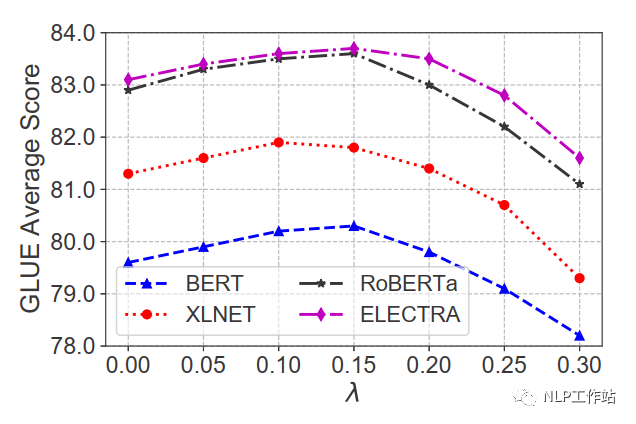
如下表所示,在BERT、XLNET、RoBERTa和ELECTRA上均取得不錯的效果。
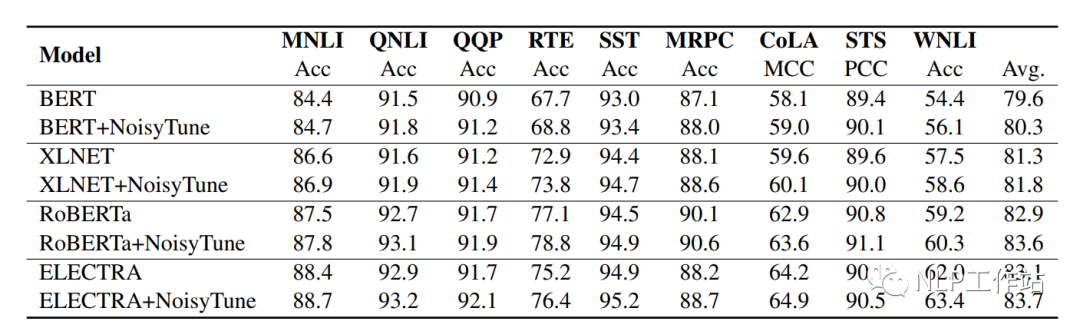
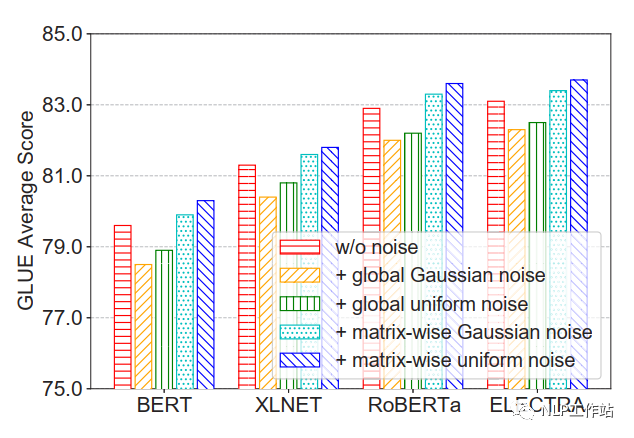
并且比較的四種不同增加噪聲的方法,發現在矩陣級均勻噪聲最優。
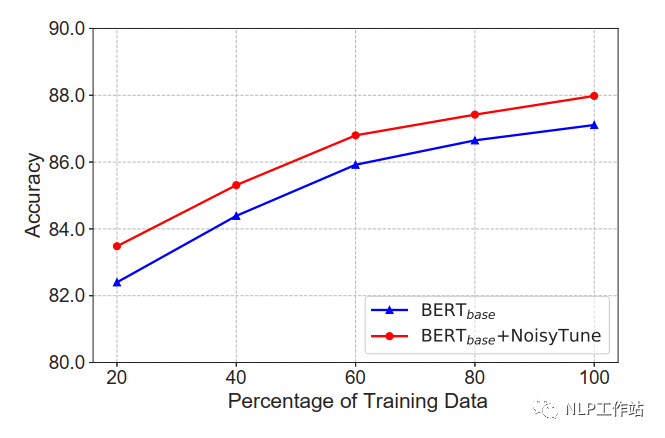
在不同數據量下,NoisyTune方法相對于finetune均有所提高。
在不同噪聲強度下,效果提升不同,對于GLUE數據集,在0.1-0.15間為最佳。
總結
蠻有意思的一篇論文,加入少量噪音,提高下游微調效果,并且可插拔方便易用,可以納入到技術庫中。
本人在自己的中文數據上做了一些實驗,發現結果也是有一些提高的,一般在0.3%-0.9%之間,但是噪聲強度在0.2時最佳,并且在噪聲強度小于0.1或大于0.25后,會比原始效果差。個人實驗結果,僅供參考。
審核編輯 :李倩
-
噪音
+關注
關注
1文章
170瀏覽量
24147 -
模型
+關注
關注
1文章
3487瀏覽量
49995 -
自然語言處理
+關注
關注
1文章
628瀏覽量
14011
原文標題:ACL2022 | NoisyTune:微調前加入少量噪音可能會有意想不到的效果
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
用PaddleNLP為GPT-2模型制作FineWeb二進制預訓練數據集

YOLOv5類中rgb888p_size這個參數要與模型推理和訓練的尺寸一致嗎?一致會達到更好的效果?
從Open Model Zoo下載的FastSeg大型公共預訓練模型,無法導入名稱是怎么回事?
使用OpenVINO?訓練擴展對水平文本檢測模型進行微調,收到錯誤信息是怎么回事?
用PaddleNLP在4060單卡上實踐大模型預訓練技術

【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀
《具身智能機器人系統》第7-9章閱讀心得之具身智能機器人與大模型
PyTorch GPU 加速訓練模型方法
直播預約 |數據智能系列講座第4期:預訓練的基礎模型下的持續學習






 工商網監
工商網監
評論