 如何區分RapidStream自動分區算法
如何區分RapidStream自動分區算法

FPGA的布局布線軟件向來跑得很慢。事實上,FPGA供應商已經花了很大的精力使其設計軟件在多核處理器上運行得更快。
最近,在ACM的FPGA 2022會議上發表了一篇題為“RapidStream: FPGA HLS設計的并行物理實現”的論文,論文中描述了一種非常有趣的方法,通過FPGA設計軟件推動HLS設計更快地運行在多核處理器上。
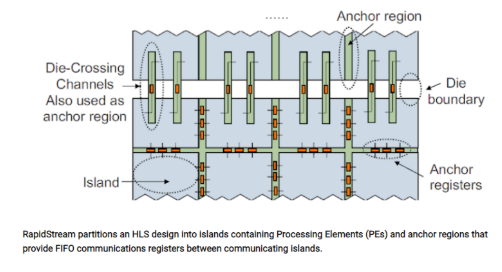
這篇論文由UCLA、AMD-Xilinx、根特大學和康奈爾大學的研究團隊撰寫,描述了RapidStream自動分區算法,將數據流設計分割成多個“island”,在劃分的island之間插入“anchor regions”,然后通過anchor regions中的寄存器將每個island的信號連起來整合到整個設計中。
所有這些劃分和拼接背后的目的是將HLS設計分割成小塊,交付給現代服務器中的多個核心。這種策略已經有悠久的歷史,現在被用于加速FPGA的開發。
這個過程有三個主要的HLS級約束:
1、非重疊分區——并行化不同island的物理實現;
2、流水線化的island間連接——每個island間連接都流水線化,以滿足時序要求;
3、直接連接——每個island只能與相鄰的island直接連接。當并行化設計布局布線時,這個約束是至關重要的。
(注意:這些約束與用于控制邏輯綜合的各種約束完全不同,它處于一個更高的層次。)
RapidStream的開發者將數據流設計定義為一組并行處理元素(processing element,簡稱PE)和一組根據設計的數據流需求將PE連接起來的FIFO。PE內部可以很復雜,但只能通過FIFO接口與其他PE進行數據通信。
如上所述,RapidStream將FPGA fabric劃分為兩種region:大小相同的region和在相鄰region之間以窄列和行放置的anchor region。有趣的是,RapidStream似乎是專門為AMD-Xilinx Virtex UltraScale+ FPGA構建的,這是由FPGA chiplet(AMD-Xilinx語言中的超級邏輯區域,簡稱SLR)制成的2.5D器件。
這篇論文包含了幾個描述RapidStream工作性能的圖表。下圖顯示了在分區后,六種不同的數據流設計與沒有分區的流水線/非流水線版本時鐘速率的比較。
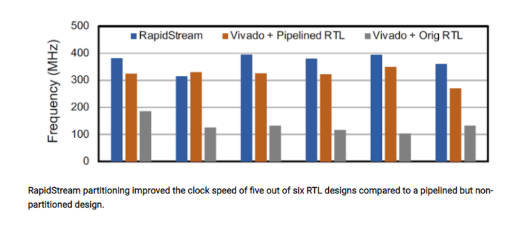
從上圖可以看出,RapidStream比所有非流水線版本的時鐘速率更高。這是意料之中的,因為流水線是FPGA時鐘速度改進的核心。然而,六種情況中,有五種情況RapidStream的結果比相同設計的流水線RTL版本要好,這個結果要引起我們的注意。
下面是布局布線的時間結果對比:
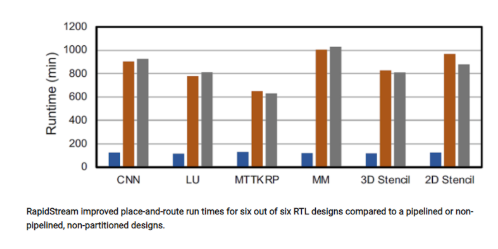
RapidStream的布局布線運行時間比未分區設計的結果要好得多。這是因為RapidStream可以將每個分區送給不同的處理器核心來布局布線。
雖然FPGA供應商試圖讓布局布線算法在多核處理器上工作得更快,但RapidStream的開發人員根據經驗發現,如果FPGA設計沒有分區,在超過兩個處理器核心上運行AMD-Xilinx Vivado設計工具時并沒有太大改善。
如果有讀者正在用FPGA開發HLS設計——特別是AMD-Xilinx FPGA,那么應該會對RapidStream感興趣。更細節的內容可以在GitHub上找到。
-
FPGA
+關注
關注
1645文章
22036瀏覽量
618095 -
數據
+關注
關注
8文章
7255瀏覽量
91806 -
多核處理器
+關注
關注
0文章
109瀏覽量
20308
發布評論請先 登錄
基于外極線分區的動態立體匹配算法
最佳集水分區模擬之研究

基于迭代填充的內存計算框架分區映射算法
基于場景分區的隨機潮流解析算法
基于區分對象集的啟發式屬性約簡算法
Spark漸進填充分區映射算法
硬盤為什么要分區 怎么分區
HIGHT算法的積分攻擊
基于RC模型的多分區權值約簡微博社區檢測算法
LICi算法抵抗積分攻擊的相關實驗及分析






 工商網監
工商網監
評論