") NVIDIA TensorRT的命令行程序
NVIDIA TensorRT的命令行程序
A.3.1. trtexec
示例目錄中包含一個名為trtexec的命令行包裝工具。 trtexec是一種無需開發(fā)自己的應(yīng)用程序即可快速使用 TensorRT 的工具。
trtexec工具有三個主要用途:
它對于在隨機(jī)或用戶提供的輸入數(shù)據(jù)上對網(wǎng)絡(luò)進(jìn)行基準(zhǔn)測試很有用。
它對于從模型生成序列化引擎很有用。
它對于從構(gòu)建器生成序列化時序緩存很有用。
A.3.1.1. Benchmarking Network
如果您將模型保存為 ONNX 文件、UFF 文件,或者如果您有 Caffe prototxt 格式的網(wǎng)絡(luò)描述,則可以使用trtexec工具測試使用 TensorRT 在網(wǎng)絡(luò)上運(yùn)行推理的性能。 trtexec工具有許多選項用于指定輸入和輸出、性能計時的迭代、允許的精度和其他選項。
為了最大限度地提高 GPU 利用率, trtexec會提前將一個batch放入隊列。換句話說,它執(zhí)行以下操作:
enqueue batch 0
-》 enqueue batch 1
-》 enqueue batch 2
-》 wait until batch 1 is done
-》 enqueue batch 3
-》 wait until batch 2 is done
-》 enqueue batch 4
-》 。..
如果使用多流( --streams=N標(biāo)志),則trtexec在每個流上分別遵循此模式。
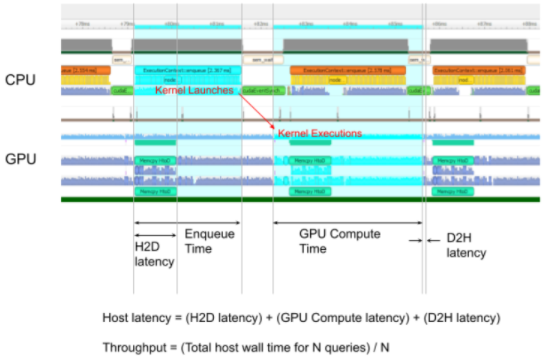
trtexec工具打印以下性能指標(biāo)。下圖顯示了trtexec運(yùn)行的示例 Nsight 系統(tǒng)配置文件,其中標(biāo)記顯示了每個性能指標(biāo)的含義。
Throughput
觀察到的吞吐量是通過將執(zhí)行數(shù)除以 Total Host Walltime 來計算的。如果這顯著低于 GPU 計算時間的倒數(shù),則 GPU 可能由于主機(jī)端開銷或數(shù)據(jù)傳輸而未被充分利用。使用 CUDA 圖(使用--useCudaGraph )或禁用 H2D/D2H 傳輸(使用--noDataTransfer )可以提高 GPU 利用率。當(dāng)trtexec檢測到 GPU 未充分利用時,輸出日志提供了有關(guān)使用哪個標(biāo)志的指導(dǎo)。
Host Latency
H2D 延遲、GPU 計算時間和 D2H 延遲的總和。這是推斷單個執(zhí)行的延遲。
Enqueue Time
將執(zhí)行排入隊列的主機(jī)延遲,包括調(diào)用 H2D/D2H CUDA API、運(yùn)行主機(jī)端方法和啟動 CUDA 內(nèi)核。如果這比 GPU 計算時間長,則 GPU 可能未被充分利用,并且吞吐量可能由主機(jī)端開銷支配。使用 CUDA 圖(帶有--useCudaGraph )可以減少排隊時間。
H2D Latency
單個執(zhí)行的輸入張量的主機(jī)到設(shè)備數(shù)據(jù)傳輸?shù)难舆t。添加--noDataTransfer以禁用 H2D/D2H 數(shù)據(jù)傳輸。
D2H Latency
單個執(zhí)行的輸出張量的設(shè)備到主機(jī)數(shù)據(jù)傳輸?shù)难舆t。添加--noDataTransfer以禁用 H2D/D2H 數(shù)據(jù)傳輸。
GPU Compute Time
為執(zhí)行 CUDA 內(nèi)核的 GPU 延遲。
Total Host Walltime
從第一個執(zhí)行(預(yù)熱后)入隊到最后一個執(zhí)行完成的主機(jī)時間。
Total GPU Compute Time
所有執(zhí)行的 GPU 計算時間的總和。如果這明顯短于 Total Host Walltime,則 GPU 可能由于主機(jī)端開銷或數(shù)據(jù)傳輸而未得到充分利用。
圖 1. 在 Nsight 系統(tǒng)下運(yùn)行的正常trtexec的性能指標(biāo)(ShuffleNet,BS=16,best,TitanRTX@1200MHz)
將--dumpProfile標(biāo)志添加到trtexec以顯示每層性能配置文件,這使用戶可以了解網(wǎng)絡(luò)中的哪些層在 GPU 執(zhí)行中花費(fèi)的時間最多。每層性能分析也適用于作為 CUDA 圖啟動推理(需要 CUDA 11.1 及更高版本)。此外,使用--profilingVerbosity=detailed標(biāo)志構(gòu)建引擎并添加--dumpLayerInfo標(biāo)志以顯示詳細(xì)的引擎信息,包括每層詳細(xì)信息和綁定信息。這可以讓你了解引擎中每一層對應(yīng)的操作及其參數(shù)。
A.3.1.2. Serialized Engine Generation
如果您生成保存的序列化引擎文件,您可以將其拉入另一個運(yùn)行推理的應(yīng)用程序中。例如,您可以使用TensorRT 實驗室以完全流水線異步方式運(yùn)行具有來自多個線程的多個執(zhí)行上下文的引擎,以測試并行推理性能。有一些警告;例如,如果您使用 Caffe prototxt 文件并且未提供模型,則會生成隨機(jī)權(quán)重。此外,在 INT8 模式下,使用隨機(jī)權(quán)重,這意味著 trtexec 不提供校準(zhǔn)功能。
A.3.1.3. trtexec
如果您向--timingCacheFile選項提供時序緩存文件,則構(gòu)建器可以從中加載現(xiàn)有的分析數(shù)據(jù)并在層分析期間添加新的分析數(shù)據(jù)條目。計時緩存文件可以在其他構(gòu)建器實例中重用,以提高構(gòu)建器執(zhí)行時間。建議僅在相同的硬件/軟件配置(例如,CUDA/cuDNN/TensorRT 版本、設(shè)備型號和時鐘頻率)中重復(fù)使用此緩存;否則,可能會出現(xiàn)功能或性能問題。
A.3.1.4. 常用的命令行標(biāo)志
該部分列出了常用的trtexec命令行標(biāo)志。
構(gòu)建階段的標(biāo)志
--onnx=《model》 :指定輸入 ONNX 模型。
--deploy=《caffe_prototxt》 :指定輸入的 Caffe prototxt 模型。
--uff=《model》 :指定輸入 UFF 模型。
--output=《tensor》 :指定輸出張量名稱。僅當(dāng)輸入模型為 UFF 或 Caffe 格式時才需要。
--maxBatch=《BS》 :指定構(gòu)建引擎的最大批量大小。僅當(dāng)輸入模型為 UFF 或 Caffe 格式時才需要。如果輸入模型是 ONNX 格式,請使用--minShapes 、 --optShapes 、 --maxShapes標(biāo)志來控制輸入形狀的范圍,包括批量大小。
--minShapes=《shapes》 , --optShapes=《shapes》 , --maxShapes=《shapes》 :指定用于構(gòu)建引擎的輸入形狀的范圍。僅當(dāng)輸入模型為 ONNX 格式時才需要。
--workspace=《size in MB》 :指定策略允許使用的最大工作空間大小。該標(biāo)志已被棄用。您可以改用--memPoolSize=《pool_spec》標(biāo)志。
--memPoolSize=《pool_spec》 :指定策略允許使用的工作空間的最大大小,以及 DLA 將分配的每個可加載的內(nèi)存池的大小。
--saveEngine=《file》 :指定保存引擎的路徑。
--fp16 、 --int8 、 --noTF32 、 --best :指定網(wǎng)絡(luò)級精度。
--sparsity=[disable|enable|force] :指定是否使用支持結(jié)構(gòu)化稀疏的策略。
disable :使用結(jié)構(gòu)化稀疏禁用所有策略。這是默認(rèn)設(shè)置。
enable :使用結(jié)構(gòu)化稀疏啟用策略。只有當(dāng) ONNX 文件中的權(quán)重滿足結(jié)構(gòu)化稀疏性的要求時,才會使用策略。
force :使用結(jié)構(gòu)化稀疏啟用策略,并允許 trtexec 覆蓋 ONNX 文件中的權(quán)重,以強(qiáng)制它們具有結(jié)構(gòu)化稀疏模式。請注意,不會保留準(zhǔn)確性,因此這只是為了獲得推理性能。
--timingCacheFile=《file》 :指定要從中加載和保存的時序緩存。
--verbose :打開詳細(xì)日志記錄。
--buildOnly :在不運(yùn)行推理的情況下構(gòu)建并保存引擎。
--profilingVerbosity=[layer_names_only|detailed|none] :指定用于構(gòu)建引擎的分析詳細(xì)程度。
--dumpLayerInfo , --exportLayerInfo=《file》 :打印/保存引擎的層信息。
--precisionConstraints=spec :控制精度約束設(shè)置。
none :沒有限制。
prefer :如果可能,滿足--layerPrecisions / --layerOutputTypes設(shè)置的精度約束。
obey:滿足由--layerPrecisions / --layerOutputTypes設(shè)置的精度約束,否則失敗。
--layerPrecisions=spec :控制每層精度約束。僅當(dāng)PrecisionConstraints設(shè)置為服從或首選時才有效。規(guī)范是從左到右閱讀的,后面的會覆蓋前面的。 “ * ”可以用作layerName來指定所有未指定層的默認(rèn)精度。
例如: --layerPrecisions=*:fp16,layer_1:fp32將所有層的精度設(shè)置為FP16 ,除了 layer_1 將設(shè)置為 FP32。
--layerOutputTypes=spec :控制每層輸出類型約束。僅當(dāng)PrecisionConstraints設(shè)置為服從或首選時才有效。規(guī)范是從左到右閱讀的,后面的會覆蓋前面的。 “ * ”可以用作layerName來指定所有未指定層的默認(rèn)精度。如果一個層有多個輸出,則可以為該層提供用“ + ”分隔的多種類型。
例如: --layerOutputTypes=*:fp16,layer_1:fp32+fp16將所有層輸出的精度設(shè)置為FP16 ,但 layer_1 除外,其第一個輸出將設(shè)置為 FP32,其第二個輸出將設(shè)置為 FP16。
推理階段的標(biāo)志
--loadEngine=《file》 :從序列化計劃文件加載引擎,而不是從輸入 ONNX、UFF 或 Caffe 模型構(gòu)建引擎。
--batch=《N》 :指定運(yùn)行推理的批次大小。僅當(dāng)輸入模型為 UFF 或 Caffe 格式時才需要。如果輸入模型是 ONNX 格式,或者引擎是使用顯式批量維度構(gòu)建的,請改用--shapes 。
--shapes=《shapes》 :指定要運(yùn)行推理的輸入形狀。
--warmUp=《duration in ms》 , --duration=《duration in seconds》 , --iterations=《N》 : 指定預(yù)熱運(yùn)行的最短持續(xù)時間、推理運(yùn)行的最短持續(xù)時間和推理運(yùn)行的迭代。例如,設(shè)置--warmUp=0 --duration=0 --iterations允許用戶準(zhǔn)確控制運(yùn)行推理的迭代次數(shù)。
--useCudaGraph :將推理捕獲到 CUDA 圖并通過啟動圖來運(yùn)行推理。當(dāng)構(gòu)建的 TensorRT 引擎包含 CUDA 圖捕獲模式下不允許的操作時,可以忽略此參數(shù)。
--noDataTransfers :關(guān)閉主機(jī)到設(shè)備和設(shè)備到主機(jī)的數(shù)據(jù)傳輸。
--streams=《N》 :并行運(yùn)行多個流的推理。
--verbose :打開詳細(xì)日志記錄。
--dumpProfile, --exportProfile=《file》 :打印/保存每層性能配置文件。
關(guān)于作者
Ken He 是 NVIDIA 企業(yè)級開發(fā)者社區(qū)經(jīng)理 & 高級講師,擁有多年的 GPU 和人工智能開發(fā)經(jīng)驗。自 2017 年加入 NVIDIA 開發(fā)者社區(qū)以來,完成過上百場培訓(xùn),幫助上萬個開發(fā)者了解人工智能和 GPU 編程開發(fā)。在計算機(jī)視覺,高性能計算領(lǐng)域完成過多個獨立項目。并且,在機(jī)器人和無人機(jī)領(lǐng)域,有過豐富的研發(fā)經(jīng)驗。對于圖像識別,目標(biāo)的檢測與跟蹤完成過多種解決方案。曾經(jīng)參與 GPU 版氣象模式GRAPES,是其主要研發(fā)者。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5267瀏覽量
105895 -
gpu
+關(guān)注
關(guān)注
28文章
4919瀏覽量
130770 -
人工智能
+關(guān)注
關(guān)注
1804文章
48807瀏覽量
247196
發(fā)布評論請先 登錄
使用NVIDIA Triton和TensorRT-LLM部署TTS應(yīng)用的最佳實踐

請問如何通過S32K312命令行構(gòu)建代碼?
使用NXP MCX-N板卡新增命令控制
如何用幾條命令搞定Ubuntu系統(tǒng)的網(wǎng)絡(luò)配置
Linux常用命令行總結(jié)

curl wget bond:深入解析命令行工具的差異與應(yīng)用場景
在NVIDIA TensorRT-LLM中啟用ReDrafter的一些變化

解鎖NVIDIA TensorRT-LLM的卓越性能
NVIDIA TensorRT-LLM Roadmap現(xiàn)已在GitHub上公開發(fā)布

圖形用戶界面與命令行接口的比較
Mobaxterm 的命令行使用方法
APM32F411板的python+pyocd命令行操作

Windows操作系統(tǒng)中的常用命令





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論