 關于C語言大坑你知道嘛?
關于C語言大坑你知道嘛?
uint16_trun_cnt, run_cnt_next;void function1(){dosomething;run_cnt++; // 自加,表示該函數已執行}int main(){while(1){function1();if(run_cnt!=run_cnt_next+1)//判斷兩個變量是否匹配{doerrorsome thing}run_cnt_next++;//這個位置也自加,表示這里已執行}}
類似流程如上,當時魚鷹為了減少變量空間,將計數器設計成了 uint16_t 類型,導致埋下了隱患。
這個流程乍一看沒有問題,因為 run_cnt比 run_cnt_next 先加,那么run_cnt_next + 1 應該等于run_cnt,如果不相等,作錯誤處理。
甚至短時間內運行不會有任何問題,除非 16 位溢出……
所以一個量產項目,任何一點改動,都可能需要長時間的穩定測試,只有這樣才能確保系統穩定性,不能認為自己能力強,寫的代碼不用測試就直接合并了。
原先魚鷹以為,這兩個變量都是 16 位,那么 + 1 的結果應該也是16 位,最后比較時,也是 16 位比較,這樣即使最終 16 位自加溢出了,結果也會是正確的。
if(run_cnt != run_cnt_next + 1) // 判斷兩個變量是否匹配{do error some thing}
但你以為,終究是你以為。
實際上,因為你和1自加了,最終比較是按照 32 位進行比較,而 run_cnt 受到變量位數限制,始終是16位的結果(但擴展成 32 位比較,即高 16 位全是 0)

這樣就會導致在溢出時,兩者是不相等的。
比如上一次run_cnt 為0xFFFF 時(受位數限制,最大只能是這個),run_cnt_next 為 0xFFFE,此次結果比較即使按 32 位比較,也是沒有問題的,都是 0xFFFF。
但下一次運行時,run_cnt 自加,溢出變成 0,而run_cnt_next是 0xFFFF,再和 1 相加,因為比較會使用 32 位比較,所以此時結果是0x10000,最終導致兩者不相等(0 != 0x10000)。
那么,為什么會導致上面的問題呢?這里涉及到兩個 C 語言基礎知識點,估計大家以前都了解過,但估計沒有當回事。
1、常量默認為 int 型(但不一定是 32 bit ,和內核和編譯器有關,上面的+1 就是 int 型)
2、整型提升(詳細可網上查找)
因為兩邊的結果類型不一致(+ 1 導致右邊結果成了 int 類型),所以最終按 int 型處理。最終導致溢出時,結果判斷失敗。
我們可以通過匯編看出一些端倪:
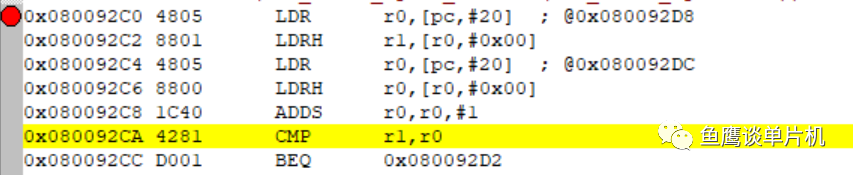
我們可以看到 r0+ 1 之后,直接和 r1 比較,也就是說,結果可能超過 0xFFFF,導致出錯。
那么,怎么樣才可以保證結果為 16 位呢?
我們可以這樣處理:
if((uint16_t)run_cnt!=(uint16_t)(run_cnt_next+1))//強制轉化為16位比較{do error some thing}
我們可通過匯編發現,多了一條 UXTH 指令,用于把 16 位結果擴展成 32 位(從這里我們也可以得出結論,結果比較總是 32 bit 比較)。
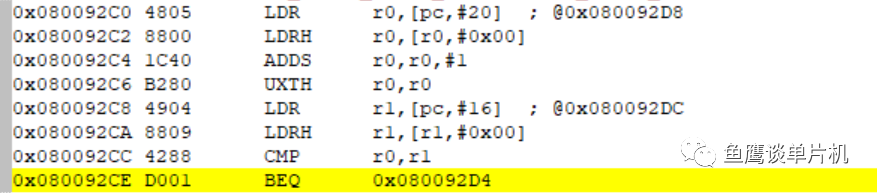
到此,分析結束!我們可以看到,為了解釋這么一條簡單的 C 語言語句,還是挺困難的事情。
END 審核編輯 :李倩-
C語言
+關注
關注
180文章
7630瀏覽量
140450 -
代碼
+關注
關注
30文章
4887瀏覽量
70266
原文標題:這個C語言大坑,你見過沒?
文章出處:【微信號:gh_c472c2199c88,微信公眾號:嵌入式微處理器】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
深入理解C語言:C語言循環控制

為什么學了C語言,卻寫不出像樣的項目?


C語言與Java語言的對比
C語言與其他編程語言的比較
hex文件如何查看原c語言代碼
技術干貨驛站 ▏深入理解C語言:掌握常量,讓你的代碼更加穩固高效!


關于定位系統技術你知道多少?





 工商網監
工商網監
評論