 如何使用RAPIDS和CuPy時加速Gauss 秩變換
如何使用RAPIDS和CuPy時加速Gauss 秩變換
正如在 批量標準化紙 中所解釋的,如果神經網絡的輸入是高斯的,那么訓練它就變得容易多了。這很清楚。如果你的模型輸入不是高斯的, RAPIDS 會在眨眼間把它轉換成高斯的。
高斯秩變換 是一種新的標準化技術,用于轉換輸入數據以訓練深層神經網絡。最近,我們在 預測分子競爭性質 中使用了這種技術,它很容易將 m 消息傳遞神經網絡模型 的精度提高了一個顯著的幅度。這篇博文將展示如何使用 RAPIDS cuDF 和 Chainer CuPy 實現 GPU 加速的Gauss 秩變換,并使用 pandas 和 NumPy 替換來實現 100 倍加速 。
介紹
輸入歸一化是訓練神經網絡的關鍵。高斯秩變換的思想最早是由 邁克爾·賈勒。 在他的 塞古羅港的安全駕駛預測 挑戰的勝利解中提出的。他訓練去噪自動編碼器,并嘗試了幾種輸入標準化方法。最后,他得出這樣的結論:
我在過去發現的最棒的東西是 GaussRank ,它能直接發揮作用。這通常比標準的 mean / std 定標器或 min / max (標準化)好得多。
有三個步驟可以將任意分布下的連續值向量轉換為基于秩的高斯分布,如圖 1 所示。

圖 1 :高斯秩變換。
CuPy 實現非常簡單,非常類似于 NumPy 操作。實際上,只需更改導入的函數,就可以將整個進程從 CPU 移動到 GPU ,而無需任何其他代碼更改。
import cupy as cp
from cupyx.scipy.special import erfinv
import matplotlib.pyplot as plt
import numpy as np
from scipy.special import erfinv as sp_erfinv
x_gpu = cp.random.rand(20) # input array
x_cpu = cp.asnumpy(x_gpu)
x_gpu
array([0.55524998, 0.42394212, 0.01200076, 0.13974612, 0.74289723,
0.19072088, 0.47061846, 0.61921186, 0.96994115, 0.44076614,
0.04326316, 0.33698309, 0.47978816, 0.00819107, 0.63463167,
0.03370001, 0.0369827 , 0.84651929, 0.25335235, 0.75172228])
r_gpu = x_gpu.argsort().argsort() # compute the rank
print(r_gpu)
r_cpu = x_cpu.argsort().argsort()
print(r_cpu)
[13 9 1 5 16 6 11 14 19 10 4 8 12 0 15 2 3 18 7 17] [13 9 1 5 16 6 11 14 19 10 4 8 12 0 15 2 3 18 7 17]
r_gpu = (r_gpu/r_gpu.max()-0.5)*2 # scale to (-1,1)
epsilon = 1e-6
r_gpu = cp.clip(r_gpu,-1+epsilon,1-epsilon)
print(r_gpu)
r_cpu = (r_cpu/r_cpu.max()-0.5)*2 # scale to (-1,1)
r_cpu = cp.clip(r_cpu,-1+epsilon,1-epsilon)
print(r_cpu)
[ 0.36842105 -0.05263158 -0.89473684 -0.47368421 0.68421053 -0.36842105 0.15789474 0.47368421 0.999999 0.05263158 -0.57894737 -0.15789474 0.26315789 -0.999999 0.57894737 -0.78947368 -0.68421053 0.89473684 -0.26315789 0.78947368] [ 0.36842105 -0.05263158 -0.89473684 -0.47368421 0.68421053 -0.36842105 0.15789474 0.47368421 0.999999 0.05263158 -0.57894737 -0.15789474 0.26315789 -0.999999 0.57894737 -0.78947368 -0.68421053 0.89473684 -0.26315789 0.78947368]
r_gpu = erfinv(r_gpu) # map to gaussian
print(r_gpu)
r_cpu = sp_erfinv(r_cpu) # map to gaussian
print(r_cpu)
[ 0.3390617 -0.0466774 -1.14541135 -0.44805114 0.70933273 -0.3390617 0.14085661 0.44805114 3.45891074 0.0466774 -0.56893556 -0.14085661 0.23761485 -3.45891074 0.56893556 -0.8853822 -0.70933273 1.14541135 -0.23761485 0.8853822 ] [ 0.3390617 -0.0466774 -1.14541135 -0.44805114 0.70933273 -0.3390617 0.14085661 0.44805114 3.45891074 0.0466774 -0.56893556 -0.14085661 0.23761485 -3.45891074 0.56893556 -0.8853822 -0.70933273 1.14541135 -0.23761485 0.8853822 ]
n_bins = 5
fig, axs = plt.subplots(1, 2, sharey=True, tight_layout=True)
fig.set_figheight(5)
fig.set_figwidth(15)
axs[0].hist(cp.asnumpy(x_gpu), bins=n_bins)
axs[0].set_title('input',fontsize=15)
axs[1].hist(cp.asnumpy(r_gpu), bins=n_bins)
axs[1].set_title('transform',fontsize=15)
print('GaussRank transformation GPU')
GaussRank transformation
n_bins = 5
fig, axs = plt.subplots(1, 2, sharey=True, tight_layout=True)
fig.set_figheight(5)
fig.set_figwidth(15)
axs[0].hist(x_cpu, bins=n_bins)
axs[0].set_title('input',fontsize=15)
axs[1].hist(r_cpu, bins=n_bins)
axs[1].set_title('transform',fontsize=15)
print('GaussRank transformation CPU')
GaussRank transformation CPU
反變換用于從高斯變換中恢復原始值。這是展示 cuDF 與 CuPy 的互操作性 的另一個很好的例子。就像您可以使用 NumPy 和 pandas 一樣,您可以在同一個工作流中將 cuDF 和 CuPy 編織在一起,同時將數據完全保存在 GPU 上。
import warnings
warnings.filterwarnings("ignore")
import cupy as cp
from cupyx.scipy.special import erfinv
import cudf as gd
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from scipy.special import erfinv as sp_erfinv
GaussRank transformation
x_gpu = cp.random.rand(20) # input array
x_cpu = cp.asnumpy(x_gpu)
r_gpu = x_gpu.argsort().argsort() # compute the rank
r_cpu = x_cpu.argsort().argsort()
r_gpu = (r_gpu/r_gpu.max()-0.5)*2 # scale to (-1,1)
epsilon = 1e-6
r_gpu = cp.clip(r_gpu,-1+epsilon,1-epsilon)
r_cpu = (r_cpu/r_cpu.max()-0.5)*2 # scale to (-1,1)
r_cpu = cp.clip(r_cpu,-1+epsilon,1-epsilon)
r_gpu = erfinv(r_gpu) # map to gaussian
r_cpu = sp_erfinv(r_cpu) # map to gaussian
Inverse transformation step by step
df_cpu = pd.DataFrame({'src':x_cpu,'tgt':r_cpu})
df_gpu = gd.DataFrame({'src':x_gpu,'tgt':r_gpu}) # pass cupy array to cudf dataframe
df_cpu = df_cpu.sort_values('src') # sort
df_gpu = df_gpu.sort_values('src')
pos_cpu = df_cpu['tgt'].searchsorted(r_cpu, side='left') # search
pos_gpu = df_gpu['tgt'].searchsorted(r_gpu, side='left')
def linear_inter_polate(df,x,pos):
N = df.shape[0]
pos[pos>=N] = N-1
pos[pos-1<=0] = 0
if isinstance(x,cp.ndarray):
pos = pos.values
x1 = df['tgt'].values[pos]
x2 = df['tgt'].values[pos-1]
y1 = df['src'].values[pos]
y2 = df['src'].values[pos-1]
relative = (x-x2) / (x1-x2)
return (1-relative)*y2 + relative*y1
x_inv_cpu = linear_inter_polate(df_cpu,r_cpu,pos_cpu) # linear inter polate
x_inv_gpu = linear_inter_polate(df_gpu,r_gpu,pos_gpu)
n_bins = 5
fig, axs = plt.subplots(1, 3, sharey=True, tight_layout=True)
fig.set_figheight(5)
fig.set_figwidth(15)
axs[0].hist(x_cpu, bins=n_bins)
axs[0].set_title('input',fontsize=15)
axs[1].hist(r_cpu, bins=n_bins)
axs[1].set_title('transform',fontsize=15)
_ = axs[2].hist(x_inv_cpu, bins=n_bins)
axs[2].set_title('inverse transform',fontsize=15)
print('GaussRank CPU')
GaussRank CPU
n_bins = 5
fig, axs = plt.subplots(1, 3, sharey=True, tight_layout=True)
fig.set_figheight(5)
fig.set_figwidth(15)
axs[0].hist(cp.asnumpy(x_gpu), bins=n_bins)
axs[0].set_title('input',fontsize=15)
axs[1].hist(cp.asnumpy(r_gpu), bins=n_bins)
axs[1].set_title('transform',fontsize=15)
_ = axs[2].hist(cp.asnumpy(x_inv_gpu), bins=n_bins)
axs[2].set_title('inverse transform',fontsize=15)
print('GaussRank GPU')
GaussRank GPU
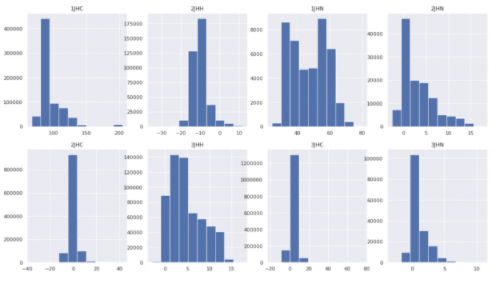
圖 2 :每種鍵合類型的基本事實分布。
因此,我們將高斯秩變換應用于訓練數據的基本事實,為所有鍵類型創建一個統一的干凈高斯分布。
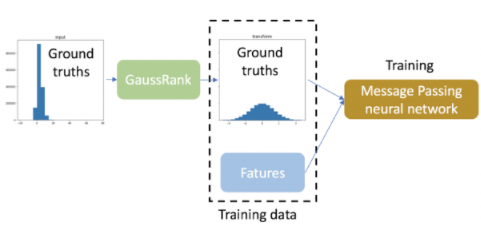
圖 3 :使用 GaussRank 轉換基本事實的工作流程。
在這個回歸任務中,使用 GaussRank 變換訓練數據的基本事實。
為了進行推斷,我們將反高斯秩變換應用于測試數據的預測,以便它們匹配每種鍵類型的原始不同分布。由于測試數據中目標的真實分布是未知的,因此根據訓練數據中目標變量的分布計算測試數據預測的逆變換。應該注意的是,這種逆變換只需要用于目標變量。
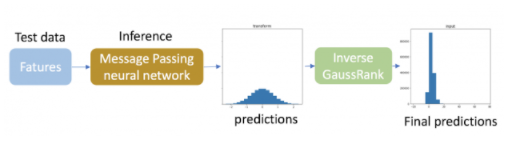
圖 4 :預測被反變換以匹配原始分布。
通過運用這一技巧 平均絕對誤差( LMAE )的對數 of our message passing neural network is improved by 18%!
請記住 GaussRank 確實有一些限制:
它只適用于連續變量,并且
如果輸入已經接近高斯分布,或者非常不對稱,則性能 MIG ht 不會得到改善,甚至變得更差。
高斯秩變換與各種神經網絡的相互作用是一個非常活躍的研究課題。
加速
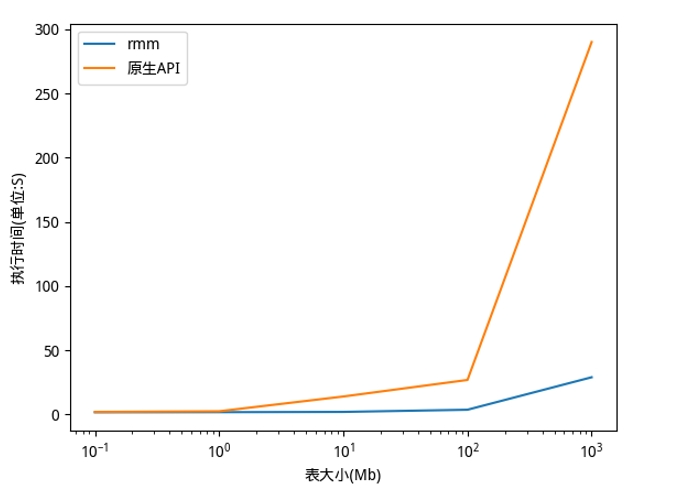
我們測量變換和反變換的總時間。對于正在進行的 CHAMPS 數據集, cuDF + CuPy 在單個 NVIDIA V100 GPU 上的實現在 Intel Xeon CPU 上實現了 比 pandas + NumPy 快 25 倍 。我們生成 合成隨機數據 以進行更全面的比較。對于 10M 及以上的數據點,我們的 RAPIDS 實現比 快 100 倍。 多
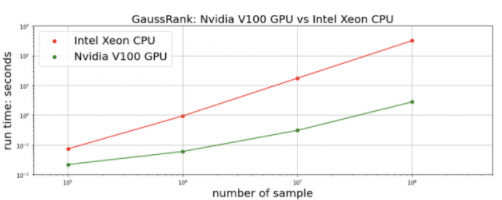
圖 5 : GaussRank 變換+反變換對合成隨機數據的加速比較。
結論
RAPIDS 在提供驚人的性能方面取得了長足的進步,代碼幾乎沒有變化。這篇博文展示了使用 RAPIDS cuDF 和 CuPy 作為 pandas 和 NumPy 的替代品來實現 gpu 性能改進是多么容易。如中所示 完整的筆記本 ,通過 只添加兩行代碼 ,高斯秩變換檢測到輸入張量在 GPU 上,并自動從 pandas + NumPy 切換到 cuDF + CuPy 。再簡單不過了。
關于作者
Jiwei Liu 是 NVIDIA 的數據科學家,致力于 NVIDIA 人工智能基礎設施,包括 RAPIDS 數據科學框架。
審核編輯:郭婷
-
神經網絡
+關注
關注
42文章
4806瀏覽量
102721 -
gpu
+關注
關注
28文章
4908瀏覽量
130622
發布評論請先 登錄
克拉克變換&帕克變換:電機界的“變形金剛”雙人組
NVIDIA助力FinCatch開發智能投資輔助系統
傅立葉變換與拉普拉斯變換的區別
傅立葉變換的基本概念 傅立葉變換在信號處理中的應用
RAPIDS cuDF將pandas提速近150倍

經典傅里葉變換與快速傅里葉變換的區別
dcdc變換器有幾種變換形式
利用NVIDIA RAPIDS加速DolphinDB Shark平臺提升計算性能
數據中心應用中適用于Intel Xeon Sapphire Rapids可擴展處理器的負載點解決方案

負阻抗變換器如何實現負阻變換
數據中心應用中適用于Intel? Xeon? Sapphire Rapids可擴展處理器的負載點解決方案





 工商網監
工商網監
評論