") 使用NVIDIA CUDA-Pointpillars檢測(cè)點(diǎn)云中的對(duì)象
使用NVIDIA CUDA-Pointpillars檢測(cè)點(diǎn)云中的對(duì)象
點(diǎn)云是坐標(biāo)系中的點(diǎn)數(shù)據(jù)集。點(diǎn)包含豐富的信息,包括三維坐標(biāo)(X、Y、Z)、顏色、分類(lèi)值、強(qiáng)度值和時(shí)間等。點(diǎn)云主要來(lái)自于各種NVIDIA Jetson用例中常用的激光雷達(dá),如自主機(jī)器、感知模塊和3D建模。
其中一個(gè)關(guān)鍵應(yīng)用是利用遠(yuǎn)程和高精度的數(shù)據(jù)集來(lái)實(shí)現(xiàn)3D對(duì)象的感知、映射和定位算法。
PointPillars是最常用于點(diǎn)云推理的模型之一。本文將探討為Jetson開(kāi)發(fā)者提供的NVIDIA CUDA加速PointPillars模型。馬上下載CUDA-PointPillars模型。
什么是CUDA-Pointpillars
本文所介紹的CUDA-Pointpillars可以檢測(cè)點(diǎn)云中的對(duì)象。其流程如下:
基本預(yù)處理:生成柱體。
預(yù)處理:生成BEV特征圖(10個(gè)通道)。
用于TensorRT的ONNX模型:通過(guò)TensorRT實(shí)現(xiàn)的ONNX模式。
后處理:通過(guò)解析TensorRT引擎輸出生成邊界框。

圖 1 。 CUDA 點(diǎn)柱管道。
基本預(yù)處理
基本預(yù)處理步驟將點(diǎn)云轉(zhuǎn)換為基本特征圖。基本特征圖包含以下組成部分:
基本特征圖。
柱體坐標(biāo):每根柱體的坐標(biāo)。
參數(shù):柱體數(shù)量。
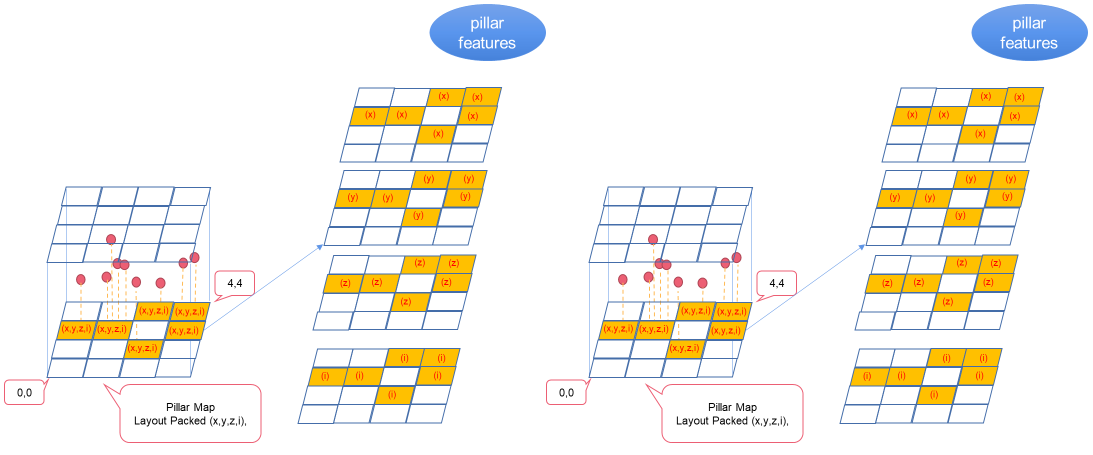
圖 2 。將點(diǎn)云轉(zhuǎn)換為基礎(chǔ)要素地圖
預(yù)處理
預(yù)處理步驟將基本特征圖(4個(gè)通道)轉(zhuǎn)換為 BEV 特征圖(10個(gè)通道)。
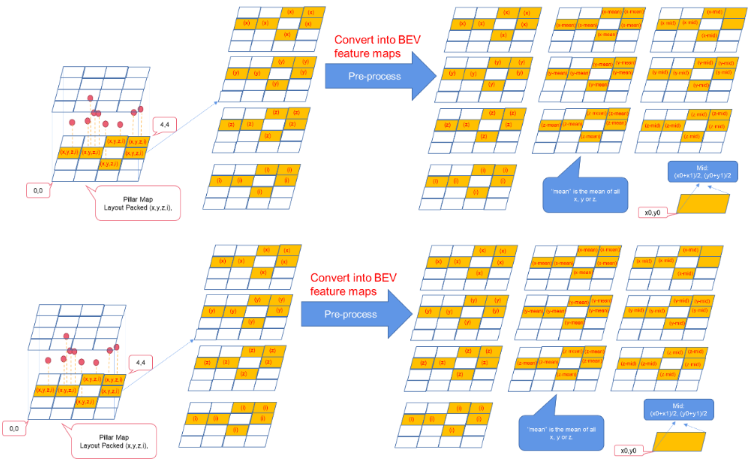
圖 3 。將基本要素地圖轉(zhuǎn)換為 BEV 要素地圖
用于TensorRT的ONNX模型
出于以下原因修改OpenPCDet的原生點(diǎn)柱:
小型操作過(guò)多,并且內(nèi)存帶寬低。
NonZero等一些TensorRT不支持的操作。
ScatterND等一些性能較低的操作。
使用“dict”作為輸入和輸出,因此無(wú)法導(dǎo)出ONNX文件。
為了從原生OpenPCDet導(dǎo)出ONNX,我們修改了該模型(圖4)。
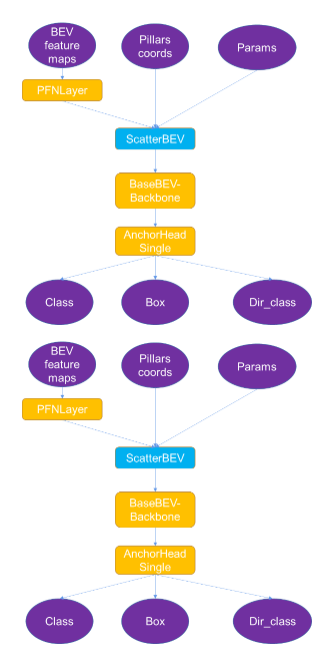
圖 4 。 CUDA Pointpillars 中 ONNX 模型概述。
您可把整個(gè)ONNX文件分為以下幾個(gè)部分:
輸入:BEV特征圖、柱體坐標(biāo)、參數(shù),均在預(yù)處理中生成。
輸出:類(lèi)、框、Dir_class,在后處理步驟中解析后生成一個(gè)邊界框。
ScatterBEV:將點(diǎn)柱(一維)轉(zhuǎn)換為二維圖像,可作為T(mén)ensorRT的插件。
其他:TensorRT支持的其他部分。
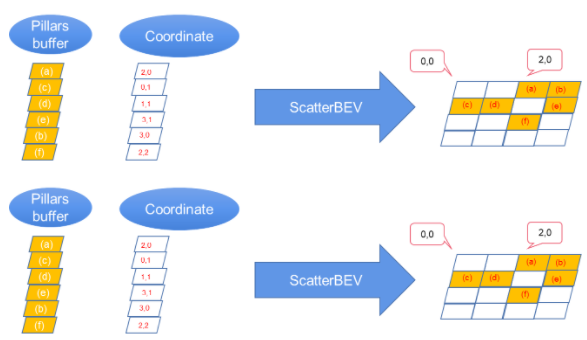
圖 5 。將點(diǎn)支柱數(shù)據(jù)散射到二維主干的二維圖像中。
后處理
在后處理步驟中解析TensorRT引擎的輸出(class、box和dir_class)和輸出邊界框。圖6所示的是示例參數(shù)。
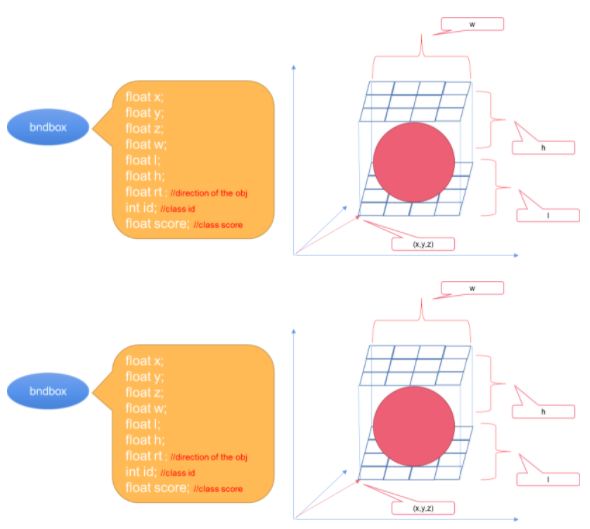
圖 6 。邊界框的參數(shù)。
使用 CUDA PointPillars
若要使用CUDA-PointPillars,需要提供點(diǎn)云的ONNX模式文件和數(shù)據(jù)緩存:
std::vectornms_pred; PointPillar pointpillar(ONNXModel_File, cuda_stream); pointpillar.doinfer(points_data, points_count, nms_pred);
將OpenPCDet訓(xùn)練的原生模型轉(zhuǎn)換為CUDA-Pointpillars的ONNX文件
我們?cè)陧?xiàng)目中提供了一個(gè)Python腳本,可以將OpenPCDet訓(xùn)練的原生模型轉(zhuǎn)換成CUDA-Pointpillars的ONNX文件。可在CUDA-Pointpillars的/tool 目錄下找到exporter.py 腳本。
可在當(dāng)前目錄下運(yùn)行以下命令獲得pointpillar.onnx文件:
$ python exporter.py --ckpt ./*.pth
性能
下表顯示了測(cè)試環(huán)境和性能。在測(cè)試之前提升CPU和GPU的性能。

表 1 測(cè)試平臺(tái)與性能
開(kāi)始使用 CUDA PointPillars
本文介紹了什么是CUDA-PointPillars以及如何使用它來(lái)檢測(cè)點(diǎn)云中的對(duì)象。
由于原生OpenPCDet無(wú)法導(dǎo)出ONNX,而且對(duì)于TensorRT來(lái)說(shuō),性能較低的小型操作數(shù)量過(guò)多,因此我們開(kāi)發(fā)了CUDA-PointPillars。該應(yīng)用可以將OpenPCDet訓(xùn)練的原生模型導(dǎo)出為特殊的ONNX模型,并通過(guò)TensorRT推斷ONNX模型。
關(guān)于作者
Lei Fan 是 NVIDIA 的高級(jí) CUDA 軟件工程師。他目前正與 TSE 中國(guó)團(tuán)隊(duì)合作,開(kāi)發(fā)由 CUDA 優(yōu)化軟件性能的解決方案。
Lily Li 正在為 NVIDIA 的機(jī)器人團(tuán)隊(duì)處理開(kāi)發(fā)人員關(guān)系。她目前正在 Jetson 生態(tài)系統(tǒng)中開(kāi)發(fā)機(jī)器人技術(shù)解決方案,以幫助創(chuàng)建最佳實(shí)踐。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5246瀏覽量
105774 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1223瀏覽量
25278
發(fā)布評(píng)論請(qǐng)先 登錄
借助NVIDIA技術(shù)加速半導(dǎo)體芯片制造
使用NVIDIA CUDA-X庫(kù)加速科學(xué)和工程發(fā)展
為什么無(wú)法使用圖像文件夾執(zhí)行對(duì)象檢測(cè)Python演示?
如何使用OpenVINO?運(yùn)行對(duì)象檢測(cè)模型?
使用Yolo-v3-TF運(yùn)行OpenVINO?對(duì)象檢測(cè)Python演示時(shí)的結(jié)果不準(zhǔn)確的原因?
NVIDIA推出DRIVE AI安全檢測(cè)實(shí)驗(yàn)室
NVIDIA加速全球大多數(shù)超級(jí)計(jì)算機(jī)推動(dòng)科技進(jìn)步

NVIDIA與谷歌量子AI部門(mén)達(dá)成合作
NVIDIA 助力谷歌量子 AI 通過(guò)量子器件物理學(xué)模擬加快處理器設(shè)計(jì)

有沒(méi)有大佬知道NI vision 有沒(méi)有辦法通過(guò)gpu和cuda來(lái)加速圖像處理
怎么在TMDSEVM6678: 6678自帶的FFT接口和CUDA提供CUFFT函數(shù)庫(kù)選擇?
IB Verbs和NVIDIA DOCA GPUNetIO性能測(cè)試





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論