") 利用NVIDIA TAO和NoNeTeSUS構(gòu)建對(duì)象檢測(cè)模型
利用NVIDIA TAO和NoNeTeSUS構(gòu)建對(duì)象檢測(cè)模型
人工智能應(yīng)用程序由機(jī)器學(xué)習(xí)模型提供動(dòng)力,這些模型經(jīng)過(guò)訓(xùn)練,能夠根據(jù)圖像、文本或音頻等輸入數(shù)據(jù)準(zhǔn)確預(yù)測(cè)結(jié)果。從頭開(kāi)始訓(xùn)練機(jī)器學(xué)習(xí)模型需要大量的數(shù)據(jù)和相當(dāng)多的人類(lèi)專(zhuān)業(yè)知識(shí),這往往使這個(gè)過(guò)程對(duì)大多數(shù)組織來(lái)說(shuō)過(guò)于昂貴和耗時(shí)。
遷移學(xué)習(xí)是從零開(kāi)始構(gòu)建定制模型和選擇現(xiàn)成的商業(yè)模型集成到 ML 應(yīng)用程序之間的一種愉快的媒介。通過(guò)遷移學(xué)習(xí),您可以選擇與您的解決方案相關(guān)的 pretrained model ,并根據(jù)反映您特定用例的數(shù)據(jù)對(duì)其進(jìn)行再培訓(xùn)。轉(zhuǎn)移學(xué)習(xí)在“定制一切”方法(通常過(guò)于昂貴)和“現(xiàn)成”方法(通常過(guò)于僵化)之間取得了正確的平衡,使您能夠用較少的資源構(gòu)建定制的解決方案。
這個(gè) NVIDIA TAO 工具包 使您能夠?qū)⑥D(zhuǎn)移學(xué)習(xí)應(yīng)用于預(yù)訓(xùn)練的模型,并創(chuàng)建定制的、可用于生產(chǎn)的模型,而無(wú)需人工智能框架的復(fù)雜性。要訓(xùn)練這些模型,必須有高質(zhì)量的數(shù)據(jù)。 TAO 專(zhuān)注于開(kāi)發(fā)過(guò)程中以模型為中心的步驟,而 Innotescus 專(zhuān)注于以數(shù)據(jù)為中心的步驟。
Innotescus 是一個(gè)基于網(wǎng)絡(luò)的平臺(tái),用于注釋、分析和管理基于計(jì)算機(jī)視覺(jué)的機(jī)器學(xué)習(xí)的健壯、無(wú)偏見(jiàn)的數(shù)據(jù)集。 Innotecus 幫助團(tuán)隊(duì)在不犧牲質(zhì)量的情況下擴(kuò)大運(yùn)營(yíng)規(guī)模。該平臺(tái)包括圖像和視頻的自動(dòng)和輔助注釋、 QA 流程的共識(shí)和審查功能,以及用于主動(dòng)數(shù)據(jù)集分析和平衡的交互式分析。 Innotecus 和 TAO 工具包使企業(yè)能夠在定制應(yīng)用程序中成功應(yīng)用遷移學(xué)習(xí),從而在短時(shí)間內(nèi)獲得高性能的解決方案,從而提高成本效益。
在這篇文章中,我們通過(guò)構(gòu)建NVIDIA TAO 工具包與 NoNeTeSUS 來(lái)解決構(gòu)建健壯的對(duì)象檢測(cè)模型的挑戰(zhàn)。此解決方案緩解了企業(yè)在構(gòu)建和部署商業(yè)解決方案時(shí)遇到的幾個(gè)常見(jiàn)問(wèn)題。
YOLO 目標(biāo)檢測(cè)模型
您在本項(xiàng)目中的目標(biāo)是使用 Innotecus 上整理的數(shù)據(jù),將轉(zhuǎn)移學(xué)習(xí)應(yīng)用于 TAO 工具包中的 YOLO 對(duì)象檢測(cè)模型。
目標(biāo)檢測(cè)是利用圖像或視頻中的邊界框?qū)δ繕?biāo)進(jìn)行定位和分類(lèi)的能力。它是計(jì)算機(jī)視覺(jué)技術(shù)最廣泛的應(yīng)用。目標(biāo)檢測(cè)解決了許多復(fù)雜的現(xiàn)實(shí)挑戰(zhàn),例如:
語(yǔ)境與場(chǎng)景理解
智能零售的自動(dòng)化解決方案
精準(zhǔn)農(nóng)業(yè)
你為什么要用 YOLO 來(lái)制作這個(gè)模型?傳統(tǒng)上,基于深度學(xué)習(xí)的對(duì)象檢測(cè)器通過(guò)兩個(gè)階段進(jìn)行操作。在第一階段,模型識(shí)別圖像中的感興趣區(qū)域。在第二階段,對(duì)每個(gè)區(qū)域進(jìn)行分類(lèi)。
通常,許多區(qū)域被發(fā)送到分類(lèi)階段,由于分類(lèi)是一項(xiàng)昂貴的操作,兩級(jí)目標(biāo)檢測(cè)器的速度非常慢。 YOLO 代表“你只看一次”顧名思義, YOLO 可以同時(shí)進(jìn)行本地化和分類(lèi),從而獲得高度準(zhǔn)確的實(shí)時(shí)性能,這對(duì)于大多數(shù)可部署解決方案至關(guān)重要。 2020 年 4 月, YOLO 的第四次迭代是 published 。它已經(jīng)在許多應(yīng)用程序和行業(yè)上進(jìn)行了測(cè)試,并被證明是健壯的。
圖 1 顯示了訓(xùn)練目標(biāo)檢測(cè)模型的通用管道。對(duì)于這個(gè)更傳統(tǒng)的開(kāi)發(fā)流程的每一步,我們都會(huì)討論人們遇到的典型挑戰(zhàn),以及 TAO 和 Innotecus 的結(jié)合如何解決這些問(wèn)題。
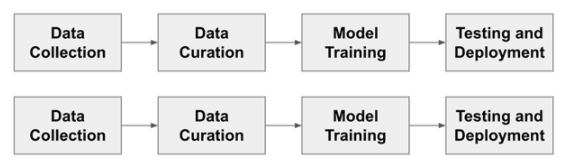
圖 1 。典型的人工智能開(kāi)發(fā)工作流程
在開(kāi)始之前,請(qǐng)安裝 TAO 工具包并驗(yàn)證 Innotescus API 的實(shí)例。
安裝 TAO 工具包
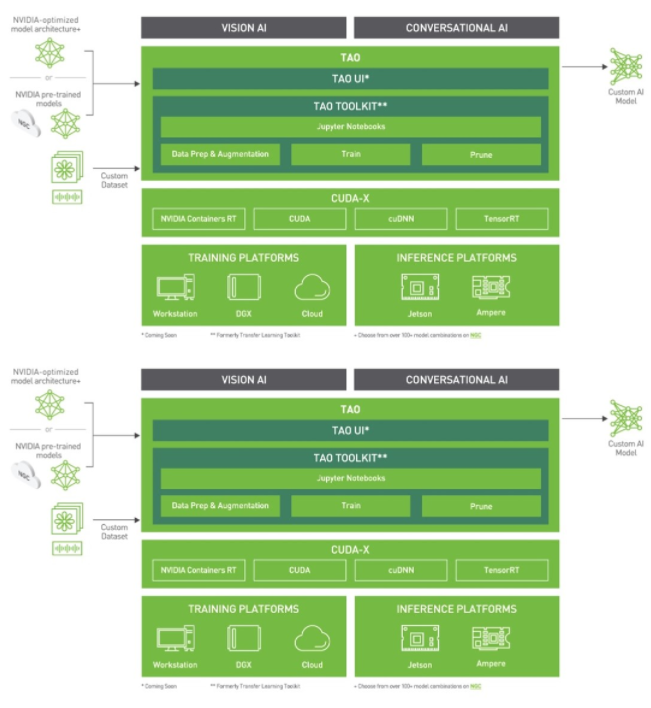
圖 2 。 TAO 工具包堆棧
TAO 工具包可以作為 CLI 或 Jupyter 筆記本運(yùn)行。它只與 Python3 ( 3.6.9 和 3.7 )兼容,所以首先安裝必備軟件。
Install docker-ce.
在 Linux 上,檢查 post-installation 步驟以確保 Docker 可以在沒(méi)有sudo的情況下運(yùn)行。
pip3 install nvidia-pyindex pip3 install nvidia-tao
通過(guò)運(yùn)行tao --help檢查您是否正確完成了安裝。
訪問(wèn) Innotecus API
Innotecus 可以作為基于 web 的應(yīng)用程序訪問(wèn),但您也可以使用其 API 演示如何以編程方式完成相同的任務(wù)。首先,安裝 Innotecus 庫(kù)。
pip install innotescus
通過(guò)運(yùn)行tao --help檢查您是否正確完成了安裝。
訪問(wèn) Innotecus API
Innotecus 可以作為基于 web 的應(yīng)用程序訪問(wèn),但您也可以使用其 API 演示如何以編程方式完成相同的任務(wù)。首先,安裝 Innotecus 庫(kù)。
pip install innotescus
接下來(lái),使用從平臺(tái)檢索的client_id和client_secret值對(duì) API 實(shí)例進(jìn)行身份驗(yàn)證。
圖 3 。生成和檢索 API 密鑰
from innotescus import client_factory
client = client_factory(client_id=’client_id’, client_secret=’client_secret’)現(xiàn)在,您已經(jīng)準(zhǔn)備好通過(guò) API 與平臺(tái)進(jìn)行交互,您將在接下來(lái)的管道中完成每一步。
數(shù)據(jù)收集
你需要數(shù)據(jù)來(lái)訓(xùn)練模型。盡管數(shù)據(jù)收集經(jīng)常被忽視,但可以說(shuō)是開(kāi)發(fā)過(guò)程中最重要的一步。收集數(shù)據(jù)時(shí),你應(yīng)該問(wèn)自己幾個(gè)問(wèn)題:
培訓(xùn)數(shù)據(jù)是否充分代表了每個(gè)感興趣的對(duì)象?
您是否考慮了預(yù)期部署模型的所有場(chǎng)景?
你有足夠的數(shù)據(jù)來(lái)訓(xùn)練模型嗎?
你不能總是完整地回答這些問(wèn)題,但是有一個(gè)全面的數(shù)據(jù)收集計(jì)劃可以幫助你在開(kāi)發(fā)過(guò)程的后續(xù)步驟中避免問(wèn)題。數(shù)據(jù)收集是一個(gè)耗時(shí)且昂貴的過(guò)程。由于 TAO 提供的模型是經(jīng)過(guò)預(yù)培訓(xùn)的,因此再培訓(xùn)的數(shù)據(jù)要求要小得多,為組織節(jié)省了這一階段的大量資源。
在本實(shí)驗(yàn)中,使用 MS COCO 驗(yàn)證 2017 數(shù)據(jù)集 中的圖像和注釋。這個(gè)數(shù)據(jù)集有 5000 張包含 80 個(gè)不同類(lèi)別的圖像,但您只使用包含至少一個(gè)人的 2685 張圖像。
%matplotlib inline from pycocotools.coco import COCO import matplotlib.pyplot as plt dataDir=’Your Data Directory’ dataType=’val2017’ annFile=’{}/annotations/instances_{}.json’.format(dataDir,dataType) coco=COCO(annFile) catIds = coco.getCatIds(catNms=[‘person’]) # only using ‘person’ category
imgIds = coco.getImgIds(catIds=catIds) for num_imgs in len(imgIds): img = coco.loadImgs(imgIds[num_imgs])[0] I = io.imread(img[‘coco_url’])使用 Innotescus 客戶端的已驗(yàn)證實(shí)例,開(kāi)始設(shè)置一個(gè)項(xiàng)目并上傳以人為中心的數(shù)據(jù)集。
#create a new project client.create_project(project_name) #upload data to the new project
client.upload_data(project_name, dataset_name, file_paths, data_type, storage_type)data_type:此數(shù)據(jù)集保存的數(shù)據(jù)類(lèi)型。接受值:
DataType.IMAGE
DataType.VIDEO
storage_type:數(shù)據(jù)的來(lái)源。接受值:
StorageType.FILE_SYSTEM
StorageType.URL
該數(shù)據(jù)集現(xiàn)在可以通過(guò) Innotescus 用戶界面訪問(wèn)
數(shù)據(jù)整理
既然你有了最初的數(shù)據(jù)集,開(kāi)始整理它以確保數(shù)據(jù)集的平衡。研究反復(fù)表明,這個(gè)過(guò)程的這一階段花費(fèi)了機(jī)器學(xué)習(xí)項(xiàng)目 80% 左右的時(shí)間。
使用 TAO 和 Innotescus ,我們重點(diǎn)介紹了預(yù)注釋和審閱等技術(shù),這些技術(shù)可以在不犧牲數(shù)據(jù)集大小或質(zhì)量的情況下節(jié)省時(shí)間。
預(yù)注釋
Pre annotation 使您能夠使用模型生成的注釋來(lái)刪除準(zhǔn)確標(biāo)記 2685 圖像子集所需的大量時(shí)間和手動(dòng)工作。您使用的 YOLOv4 與您正在重新培訓(xùn)的模型相同,以生成預(yù)注釋?zhuān)┳⑨屨哌M(jìn)行細(xì)化。
因?yàn)轭A(yù)注釋可以在注釋任務(wù)的簡(jiǎn)單部分上節(jié)省大量時(shí)間,所以可以將注意力集中在模型尚無(wú)法處理的更難的示例上。
YOLOv4 包含在 TAO 工具包中,支持 k 均值聚類(lèi)、訓(xùn)練、評(píng)估、推理、修剪和導(dǎo)出。要使用該模型,必須首先創(chuàng)建一個(gè) YOLOv4 spec 文件,該文件包含以下主要組件:
yolov4_config
training_config
eval_config
nms_config
augmentation_config
dataset_config
spec 文件是protobuf文本(prototxt)消息,其每個(gè)字段可以是基本數(shù)據(jù)類(lèi)型,也可以是嵌套消息。
接下來(lái),下載帶有預(yù)訓(xùn)練權(quán)重的模型。 TAO 工具箱 Docker 容器提供了對(duì)預(yù)訓(xùn)練模型庫(kù)的訪問(wèn),這些模型是訓(xùn)練深層神經(jīng)網(wǎng)絡(luò)的一個(gè)很好的起點(diǎn)。由于這些模型托管在 NGC 目錄中,因此必須首先下載并安裝 NGC CLI 。
安裝 CLI 后,可以在 NGC repo 上查看預(yù)訓(xùn)練計(jì)算機(jī)視覺(jué)模型列表,并下載預(yù)訓(xùn)練模型。
ngc registry model list nvidia/tao/pretrained_* ngc registry model download-version /path/to/model_on_NGC_repo/ -dest /path/to/model_download_dir/
下載模型并更新規(guī)范文件后,現(xiàn)在可以通過(guò)運(yùn)行推斷子任務(wù)來(lái)生成預(yù)注釋。
tao yolo_v4 inference [-h] -i /path/to/imgFolder/ -l /path/to/annotatedOutput/ -e /path/to/specFile.txt -m /path/to/model/ -k $KEY
推理子任務(wù)的輸出是一系列 KITTI 格式的注釋?zhuān)4嬖谥付ǖ妮敵瞿夸浿小?/p>
通過(guò)基于 web 的用戶界面或使用 API 手動(dòng)將預(yù)先說(shuō)明上傳到 Innotescus 平臺(tái)。由于 KITTI 格式是 Innotecus 接受的眾多格式之一,因此不需要預(yù)處理。
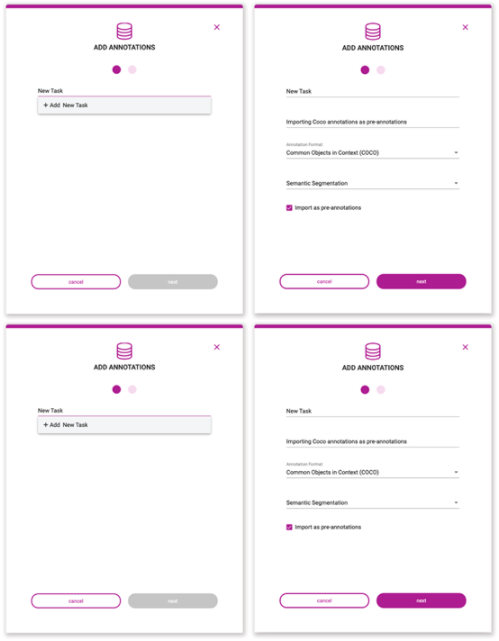
圖 7 。預(yù)注釋上載過(guò)程
#upload pre-annotations generated by YOLOv4
-
project_name:包含受影響數(shù)據(jù)集和任務(wù)的項(xiàng)目的名稱(chēng)。 -
dataset_name:要應(yīng)用這些注釋的數(shù)據(jù)集的名稱(chēng)。 -
task_type:使用這些注釋創(chuàng)建的注釋任務(wù)的類(lèi)型。TaskType類(lèi)的可接受值:-
CLASSIFICATION -
OBJECT_DETECTION -
SEGMENTATION -
INSTANCE_SEGMENTATION
-
-
data_type:注釋對(duì)應(yīng)的數(shù)據(jù)類(lèi)型。接受值:-
DataType.IMAGE -
DataType.VIDEO
-
-
annotation_format:存儲(chǔ)這些注釋的格式。AnnotationFormat類(lèi)中接受的值: -
COCO -
KITTI -
MASKS_PER_CLASS -
PASCAL -
CSV -
MASKS_SEMANTIC -
-
MASKS_INSTANCE -
INNOTESCUS_JSON -
YOLO_DARKNET -
YOLO_KERAS
-
-
file_paths:包含要上載的注釋文件的文件路徑列表。 -
task_name:這些注釋所屬任務(wù)的名稱(chēng);如果該任務(wù)不存在,則會(huì)創(chuàng)建該任務(wù)并使用這些注釋填充它。 -
task_description:正在創(chuàng)建的任務(wù)的描述,如果該任務(wù)尚不存在。 -
overwrite_existing_annotations:如果任務(wù)已經(jīng)存在,則此標(biāo)志允許您覆蓋現(xiàn)有批注。 -
pre_annotate:允許您將批注作為預(yù)批注導(dǎo)入。
將預(yù)注釋導(dǎo)入平臺(tái)并節(jié)省大量初始注釋工作后,進(jìn)入 Innotecus 以進(jìn)一步更正、細(xì)化和分析數(shù)據(jù)。
審查和糾正
成功導(dǎo)入預(yù)注釋后,前往平臺(tái)對(duì)預(yù)注釋進(jìn)行檢查和更正。雖然預(yù)訓(xùn)練模型節(jié)省了大量的注釋時(shí)間,但它仍然不夠完美,需要一些人在回路中的交互來(lái)確保高質(zhì)量的訓(xùn)練數(shù)據(jù)。圖 8 顯示了您可能進(jìn)行的典型更正的示例。
除了第一次修復(fù)和提交預(yù)注釋外, Innotecus 還可以對(duì)圖像和注釋進(jìn)行更集中的采樣,以便進(jìn)行多階段審查。這使大型團(tuán)隊(duì)能夠系統(tǒng)高效地確保整個(gè)數(shù)據(jù)集的高質(zhì)量。
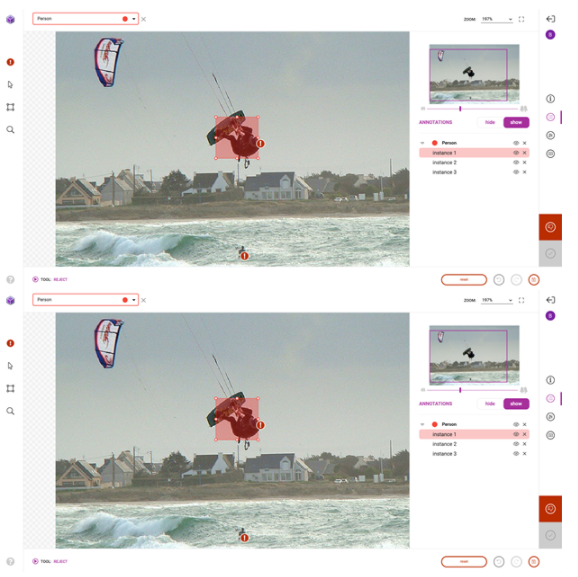
圖 9 。無(wú)害化過(guò)程
探索性數(shù)據(jù)分析
探索性數(shù)據(jù)分析( EDA )是從多個(gè)統(tǒng)計(jì)角度調(diào)查和可視化數(shù)據(jù)集的過(guò)程,以全面了解數(shù)據(jù)中存在的潛在模式、異常和偏差。在深思熟慮地解決數(shù)據(jù)集包含的統(tǒng)計(jì)不平衡之前,這是一個(gè)有效且必要的步驟。
Innotecus 提供預(yù)先計(jì)算的指標(biāo),用于理解數(shù)據(jù)和注釋的類(lèi)別、顏色、空間和復(fù)雜性分布,并使您能夠在圖像和注釋元數(shù)據(jù)中添加自己的信息層,以將特定于應(yīng)用程序的信息納入分析。
以下是如何使用 Innotecus 的潛水可視化來(lái)理解數(shù)據(jù)集中存在的一些模式和偏差。下面的散點(diǎn)圖顯示了圖像熵在數(shù)據(jù)集中沿 x 軸的分布,圖像熵是圖像中的平均信息或隨機(jī)程度。你可以看到一個(gè)清晰的模式,但你也可以發(fā)現(xiàn)異常,比如低熵或信息含量的圖像。
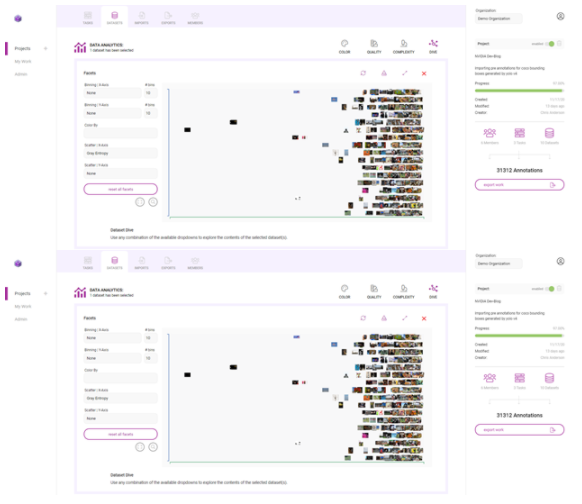
圖 10 。 Innotescus 上的數(shù)據(jù)集圖
這樣的異常值引發(fā)了如何處理數(shù)據(jù)集中異常的問(wèn)題。識(shí)別異常可以讓你提出一些關(guān)鍵問(wèn)題:
您是否希望模型在部署時(shí)會(huì)遇到低熵輸入?
如果是這樣,您是否需要在培訓(xùn)數(shù)據(jù)集中添加更多此類(lèi)示例?
如果不是,這些示例是否會(huì)對(duì)培訓(xùn)有害,是否應(yīng)該將其從培訓(xùn)數(shù)據(jù)集中刪除?
在另一個(gè)例子中,查看每個(gè)注釋的區(qū)域,相對(duì)于它所在的圖像。
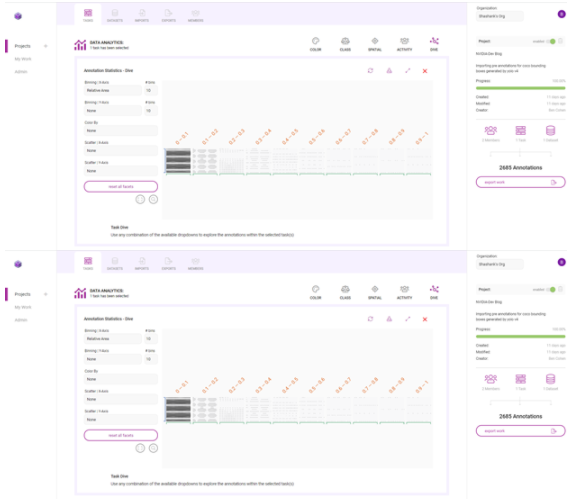
圖 12 。使用俯沖圖調(diào)查 Innotecus 計(jì)算的許多指標(biāo)
在圖 13 中,這兩幅圖像顯示了數(shù)據(jù)集中注釋大小的變化。雖然一些注釋捕捉了占據(jù)大量圖像的人,但大多數(shù)注釋顯示的是遠(yuǎn)離相機(jī)的人。
在這里,很大一部分注釋在各自圖像大小的 0% 到 10% 之間。這意味著數(shù)據(jù)集偏向于小對(duì)象,或遠(yuǎn)離相機(jī)的人。那么,您是否需要在訓(xùn)練數(shù)據(jù)中添加更多具有更大注釋的示例,以表示離攝像機(jī)更近的人?以這種方式理解數(shù)據(jù)分布有助于您開(kāi)始考慮數(shù)據(jù)擴(kuò)充計(jì)劃。
通過(guò) Innotescus , EDA 變得直觀。它為您提供了所需的信息,以便對(duì)數(shù)據(jù)集進(jìn)行強(qiáng)大的擴(kuò)充,并在開(kāi)發(fā)過(guò)程的早期消除偏見(jiàn)。
利用數(shù)據(jù)集擴(kuò)充實(shí)現(xiàn)集群再平衡
集群再平衡的增強(qiáng)背后的想法是強(qiáng)大的。 這方法顯示了在最近的數(shù)據(jù)中心 AI 競(jìng)賽由 Andrew Ng 和深入學(xué)習(xí)的 21% 的性能提升。人工智能。
為每個(gè)數(shù)據(jù)點(diǎn)(每個(gè)邊界框注釋?zhuān)┥?N 維特征向量,并將所有數(shù)據(jù)點(diǎn)聚集在更高維空間中。當(dāng)使用相似的特征對(duì)對(duì)象進(jìn)行聚類(lèi)時(shí),可以擴(kuò)充數(shù)據(jù)集,使每個(gè)聚類(lèi)具有相同的表示形式。
我們選擇使用[red channel mean, green channel mean, blue channel mean, gray image std, gray image entropy, relative area]作為 N 維特征向量。這些指標(biāo)是從 Innotecus 導(dǎo)出的, Innotecus 會(huì)自動(dòng)計(jì)算這些指標(biāo)。您還可以使用預(yù)訓(xùn)練模型生成的嵌入來(lái)填充特征向量,這可能會(huì)更健壯。
您使用 k – 均值聚類(lèi), k = 4 作為聚類(lèi)算法,使用 UMAP 將維度減少到兩個(gè),以便可視化。下面的代碼示例生成顯示 UMAP 圖的圖形,用這四個(gè)簇進(jìn)行顏色編碼。
import umap from sklearn.decomposition import PCA from sklearn.cluster import KMeans # k-means on the feature vector kmeans = KMeans(n_clusters=4, random_state=0).fit(featureVector) # UMAP for dim reduction and visualization fit = umap.UMAP(n_neighbors=5, min_dist=0.2, n_components=2, metric=’manhattan’) u = fit.fit_transform(featureVector) # Plot UMAP components plt.scatter(u[:,0], u[:,1], c=(kmeans.labels_)) plt.title(‘UMAP embedding of kmeans colours’)
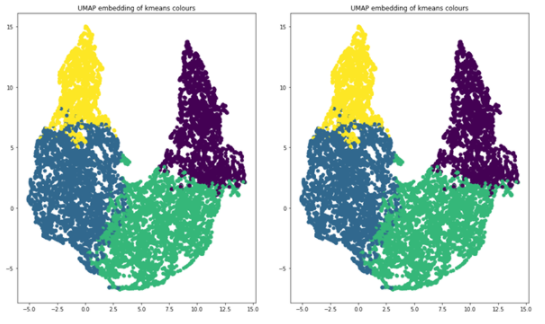
圖 14 。四個(gè)簇,在二維上繪制
當(dāng)您查看每個(gè)集群中對(duì)象的數(shù)量時(shí),您可以清楚地看到不平衡,這將告訴您應(yīng)該如何增加數(shù)據(jù)以進(jìn)行再培訓(xùn)。這四個(gè)簇分別代表 854 、 1523 、 1481 和 830 幅圖像。如果一個(gè)圖像的對(duì)象位于多個(gè)簇中,請(qǐng)將該圖像與其大多數(shù)對(duì)象分組以進(jìn)行增強(qiáng)。
clusters = {} for file, cluster in zip(filename, kmeans.labels_): if cluster not in clusters.keys(): clusters[cluster] = [] clusters[cluster].append(file) else: clusters[cluster].append(file) for numCls in range(0, len(clusters)): print(‘Cluster {}: {} objects, {} images’.format(numCls+1, len(clusters[numCls]), len(list(set(clusters[numCls])))))
輸出:
Cluster 1: 2234 objects, 854 images Cluster 2: 3490 objects, 1523 images Cluster 3: 3629 objects, 1481 images Cluster 4: 1588 objects, 830 images
定義好集群后,可以使用imgaugPython 庫(kù)引入增強(qiáng)技術(shù)來(lái)增強(qiáng)訓(xùn)練數(shù)據(jù):平移、圖像亮度調(diào)整和縮放增強(qiáng)。您可以進(jìn)行擴(kuò)展,使每個(gè)集群包含 2000 個(gè)圖像,總計(jì) 8000 個(gè)。在增強(qiáng)圖像時(shí),imgaug確保注釋坐標(biāo)也得到適當(dāng)更改。
import imgaug as ia
import imgaug.augmenters as iaa # augment images
seq = iaa.Sequential([ iaa.Multiply([1.1, 1.5]), # change brightness, doesn’t affect BBs iaa.Affine( translate_px={“x”:60, “y”:60}, scale=(0.5, 0.8) ) # translate by 60px on x/y axes & scale to 50-80%, includes BBs
]) # augment BBs and images
image_aug, bbs_aug = seq(image=I, bounding_boxes=boundingBoxes)
使用相同的 UMAP 可視化技術(shù),增加的數(shù)據(jù)點(diǎn)現(xiàn)在為紅色,您可以看到數(shù)據(jù)集現(xiàn)在更加平衡,因?yàn)樗窀咚狗植肌?/p>
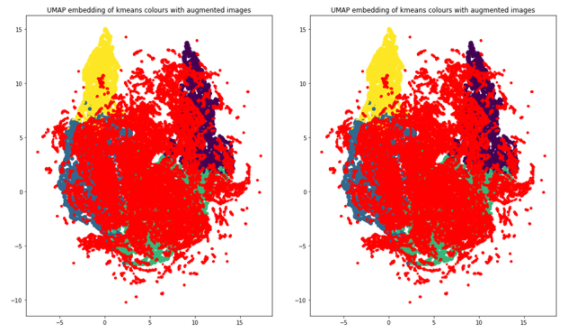
圖 15 。重新平衡的集群
模特訓(xùn)練
利用平衡良好、高質(zhì)量的訓(xùn)練數(shù)據(jù),最后一步是訓(xùn)練模型。
YOLOv4 TAO 工具包再培訓(xùn)
要開(kāi)始重新訓(xùn)練模型,首先確保 spec 文件包含感興趣的類(lèi),以及預(yù)訓(xùn)練模型和訓(xùn)練數(shù)據(jù)的正確目錄路徑。在training_config部分更改訓(xùn)練參數(shù)。保留 30% 的擴(kuò)充數(shù)據(jù)集作為測(cè)試數(shù)據(jù)集,以比較預(yù)訓(xùn)練模型和再訓(xùn)練模型的性能。
ttraining_config { batch_size_per_gpu: 8 num_epochs: 80 enable_qat: false checkpoint_interval: 10 learning_rate { soft_start_cosine_annealing_schedule { min_learning_rate: 1e-7 max_learning_rate: 1e-4 soft_start: 0.3 } } regularizer { type: L1 weight: 3e-5 } optimizer { adam { epsilon: 1e-7 beta1: 0.9 beta2: 0.999 amsgrad: false } } pretrain_model_path: “path/to/model/model.hdf5”
}
運(yùn)行訓(xùn)練命令。
tao yolo_v4 train -e /path/to/specFile.txt -r /path/to/result -k $KEY
后果
如您所見(jiàn),平均精度提高了 14.93% ,比預(yù)訓(xùn)練模型的地圖提高了 21.37% :

表 1 。利用策展數(shù)據(jù)集對(duì)遷移學(xué)習(xí)前后的績(jī)效進(jìn)行建模
總結(jié)
使用 NVIDIA TAO 工具包進(jìn)行預(yù)注釋和模型培訓(xùn),使用 Innotecus 進(jìn)行數(shù)據(jù)細(xì)化、分析和整理,您將 YOLOv4 在 person 類(lèi)上的平均精度提高了 20% 以上。你不僅提高了所選課程的成績(jī),而且比沒(méi)有遷移學(xué)習(xí)的顯著好處時(shí),你所用的時(shí)間和數(shù)據(jù)更少。
遷移學(xué)習(xí)是在資源有限的環(huán)境中生成高性能、特定于應(yīng)用程序的模型的一種好方法。使用 TAO 工具包和 Innotecus 等工具,可以讓各種規(guī)模和背景的團(tuán)隊(duì)都能使用。
關(guān)于作者
Shashank Deshpande 是位于賓夕法尼亞州匹茲堡的 Innotescus 的聯(lián)合創(chuàng)始人和主要 ML 開(kāi)發(fā)人員。 Shashank 擁有歐洲經(jīng)委會(huì)卡內(nèi)基梅隆大學(xué)的碩士學(xué)位,擁有 9 年以上的計(jì)算機(jī)視覺(jué)和機(jī)器學(xué)習(xí)經(jīng)驗(yàn)。 Shashank 的研究興趣主要是目標(biāo)檢測(cè)和跟蹤、圖像分割和探索性數(shù)據(jù)分析。他最近在安得烈 NG 的以數(shù)據(jù)為中心的人工智能競(jìng)爭(zhēng)中排名第二。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5238瀏覽量
105740 -
數(shù)據(jù)中心
+關(guān)注
關(guān)注
16文章
5130瀏覽量
73181 -
AI
+關(guān)注
關(guān)注
87文章
34146瀏覽量
275276
發(fā)布評(píng)論請(qǐng)先 登錄
利用NVIDIA技術(shù)構(gòu)建從數(shù)據(jù)中心到邊緣的智慧醫(yī)院解決方案
ServiceNow攜手NVIDIA構(gòu)建150億參數(shù)超級(jí)助手
企業(yè)使用NVIDIA NeMo微服務(wù)構(gòu)建AI智能體平臺(tái)
NVIDIA 推出開(kāi)放推理 AI 模型系列,助力開(kāi)發(fā)者和企業(yè)構(gòu)建代理式 AI 平臺(tái)

如何使用OpenVINO?運(yùn)行對(duì)象檢測(cè)模型?
使用Yolo-v3-TF運(yùn)行OpenVINO?對(duì)象檢測(cè)Python演示時(shí)的結(jié)果不準(zhǔn)確的原因?
Evo 2 AI模型可通過(guò)NVIDIA BioNeMo平臺(tái)使用
NVIDIA推出面向RTX AI PC的AI基礎(chǔ)模型
NVIDIA Cosmos世界基礎(chǔ)模型平臺(tái)發(fā)布
NVIDIA推出全新生成式AI模型Fugatto
NVIDIA助力提供多樣、靈活的模型選擇
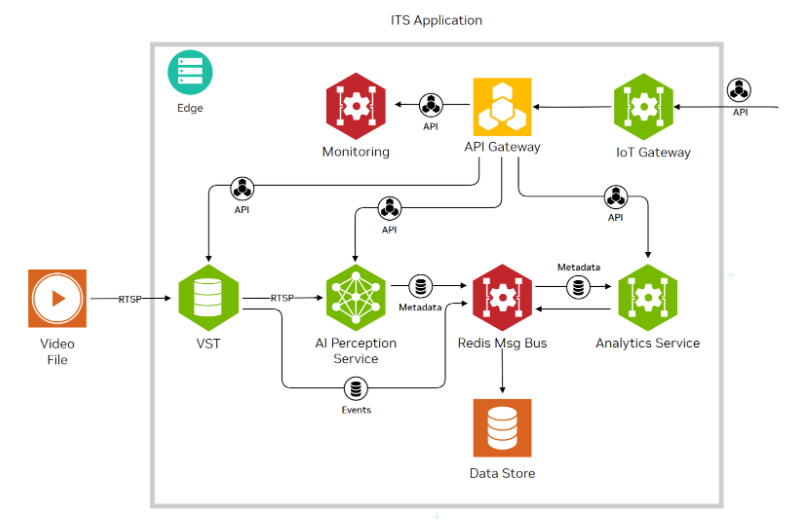
使用NVIDIA JetPack 6.0和YOLOv8構(gòu)建智能交通應(yīng)用
NVIDIA AI Foundry 為全球企業(yè)打造自定義 Llama 3.1 生成式 AI 模型

NVIDIA Omniverse 將為全新 OpenPBR 材質(zhì)模型提供原生支持





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論