") 高效框架互操作性第1部分:內存布局和內存池
高效框架互操作性第1部分:內存布局和內存池
介紹
高效的管道設計對數(shù)據(jù)科學家至關重要。在編寫復雜的端到端工作流時,您可以從各種構建塊中進行選擇,每種構建塊都專門用于特定任務。不幸的是,在數(shù)據(jù)格式之間重復轉換容易出錯,而且會降低性能。讓我們改變這一點!
在本系列文章中,我們將討論高效框架互操作性的不同方面:
我們從這篇文章開始討論不同內存布局的優(yōu)缺點,以及異步內存分配的內存池,以實現(xiàn)零拷貝功能。
在第二篇文章中,我們重點介紹了數(shù)據(jù)加載/傳輸過程中出現(xiàn)的瓶頸,以及如何使用遠程直接內存訪問( RDMA )技術緩解這些瓶頸。
在第三篇文章中,我們深入討論了端到端管道的實現(xiàn),展示了所討論的跨數(shù)據(jù)科學框架的最佳數(shù)據(jù)傳輸技術。
零拷貝功能是跨 GPU – 加速數(shù)據(jù)科學框架 TensorFlow 、 PyTorch 、 MXNet 、 cuDF 、 CuPy 、 Numba 和 JAX 高效拷貝數(shù)據(jù)的關鍵技術(見圖 2 )。在下文中,我們將向您展示如何以系統(tǒng)的方式實現(xiàn)這一目標。如果您只是在這里查找有關如何將數(shù)據(jù)從一個框架傳輸?shù)搅硪粋€框架的命令,那么 MIG ht 需要了解一下 換算表 。
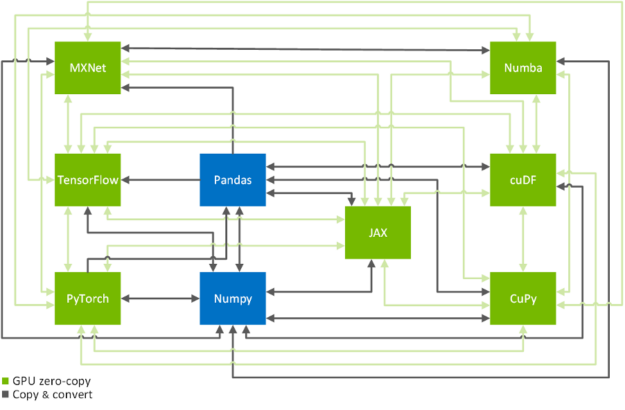
圖 2 數(shù)據(jù)科學和機器學習框架之間的轉換路徑。
內存布局、數(shù)據(jù)格式和內存池
內存布局
在開始討論如何高效地復制數(shù)據(jù)之前,讓我們先討論一下如何存儲表格數(shù)據(jù)。實際上,所有數(shù)據(jù)格式都繼承自計算機科學家已知的兩種主要內存布局之一(見圖 3 ):
結構數(shù)組( AO ):潛在不同類型的一個或多個數(shù)據(jù)點 x 、 y , z … 的序列表示為 structure S 。這些數(shù)據(jù)點的幾個實例被分配為新數(shù)據(jù)類型 S 的數(shù)組 s 。然后通過結構實例 s[k]。 的成員 s [k] x , s [k] y , s [k 。 z 。。。 訪問第 k- 個實例的原始點列表 x 、 y , z …
數(shù)組結構( SoA ):數(shù)據(jù)點 x 、 y , z … 的多個實例存儲在單獨的數(shù)組 s _ x , s _ y , s _ z … 中 k- 第個實例的原始點 x 、 y , z … 然后被 s _ x [k], s _ y [k], s _ z [k] 訪問。最后,這些數(shù)組可以解釋為一個(僅僅是虛擬存在的)結構的單個實例,因此命名為 SoA 。

圖 3 : AoS (左)和 SoA (右)內存布局的比較。白色箭頭表示線性內存中的讀取順序。注意, AoS 和 SoA 通過換位是同構的。
雖然從編程和抽象的角度來看, AoS 布局看起來比 SoA 更結構化(雙關語),但就可實現(xiàn)的性能而言,它往往不太適合大規(guī)模并行算法。這可以解釋為當一致地訪問結構成員的子集時(例如,在沿一個坐標軸減少值的過程中),緩存線的利用效率較低。您甚至可以在文獻中發(fā)現(xiàn),與 AOS 內存布局中的普通處理相比,動態(tài) AoS-to-SoA 轉換可以顯著提高性能。
在復制數(shù)據(jù)的坐標切片時, SoA 內存布局顯示出進一步的優(yōu)勢。假設您希望一次傳輸所有 x 坐標,那么就可以訪問相應的數(shù)組,而無需在 AoS 布局中對成員進行耗時的切片。更好的是,在傳輸數(shù)據(jù)時,只需在內存中公開數(shù)組地址而不復制單個字節(jié),就可以避免分配輔助內存。 阿帕奇箭頭 構建在這種方法的基礎上:出于討論的原因,將不同數(shù)據(jù)類型的數(shù)據(jù)存儲在不同的數(shù)組中(見圖 4 )。請注意,主流數(shù)據(jù)科學框架將 SoA 布局中的數(shù)組項視為存儲在列而不是行中,如圖 3 所示。然而,這只是一種慣例,因為我們都知道,幾乎所有內存都是線性排序的。
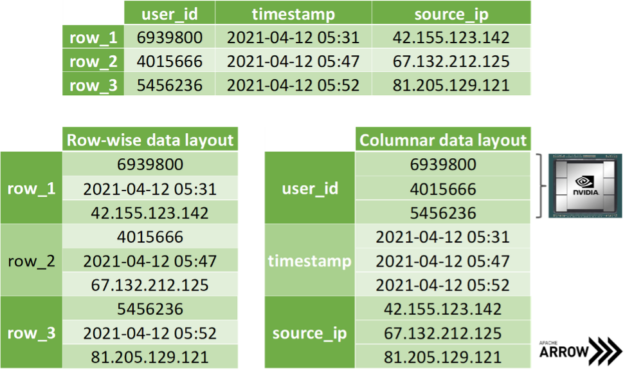
圖 4 :頂部顯示的同一個表的行( AoS ,左)和列( SoA ,右)內存布局的比較。 SoA 非常適合在 GPU 上進行大規(guī)模并行處理。
數(shù)據(jù)格式和零拷貝機制
近年來,為了滿足不同的需求,開發(fā)了不同的圖書館。與此同時,數(shù)據(jù)科學管道變得越來越復雜,需要使用多個庫來完成各種各樣的任務。不幸的是,在設計這些庫時,框架之間的互操作性并不是最優(yōu)先考慮的。因此,缺乏適合數(shù)據(jù)科學任務的標準化數(shù)據(jù)格式。當時有些人擔心數(shù)據(jù)標準,比如 pandas 項目的創(chuàng)建者 麥金尼 。 2011 年,他發(fā)表了 本帖 ,介紹了 Python 中豐富科學數(shù)據(jù)結構的未來路線圖。
由于每個庫都實現(xiàn)了其自定義的內存中數(shù)據(jù)布局和文件格式,因此當這些庫需要協(xié)作時,必須執(zhí)行昂貴的復制和轉換操作。總執(zhí)行時間的很大一部分被投入到無意義的復制和轉換操作中是很常見的。
2016 年 10 月, Apache 基金會發(fā)布了 Arrow ,這是一種獨立于語言的柱狀數(shù)據(jù)格式規(guī)范,旨在有效地處理 CPU S 和 GPU S 上的平坦和分層數(shù)據(jù)。從那時起,許多不同的框架都采用了它,促進了它們之間的零拷貝數(shù)據(jù)交換。 Apache Arrow 柱狀數(shù)據(jù)格式的其他 主要特征 包括:
O ( 1 )(恒定時間)隨機存取
SIMD 和矢量化友好
順序訪問(掃描)的數(shù)據(jù)鄰接
無需“指針旋轉”即可重新定位,允許在共享內存中進行真正的零拷貝訪問
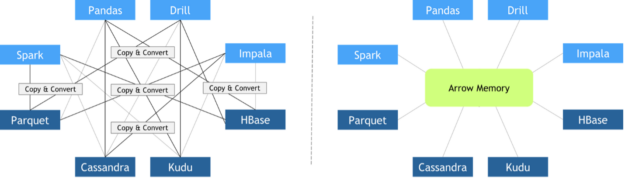
圖 5 :傳統(tǒng)框架互操作性與使用 ApacheArrow 的零拷貝方法的比較,其中所有框架都同意相同的內存布局。
零拷貝機制避免了不必要的數(shù)據(jù)傳輸,大大縮短了應用程序的執(zhí)行時間。數(shù)據(jù)科學框架增加了對以下一種或多種數(shù)據(jù)格式的支持: DLPack 、 CUDA 陣列接口 和 NumPy 陣列接口 。
DLPack 是一種開放式內存張量結構,用于在框架之間共享張量。 CUDA 數(shù)組接口和 NumPy 數(shù)組接口是交換 GPU 和 CPU 類數(shù)組對象的事實標準。
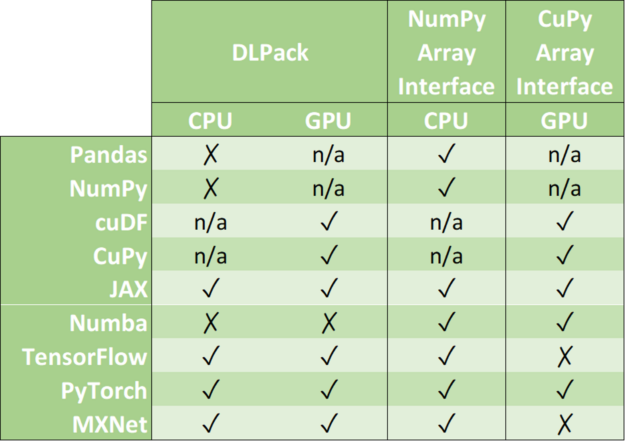
表 1 :數(shù)據(jù)格式支持矩陣。
請注意, cuDF 和 CuPy 等庫只在 GPU 設備上運行。雖然可以將 NumPy 數(shù)組轉換為 cuDF 或 CuPy 對象,但我們已將其支持標記為 n/a ,因為它請求主機內存( CPU )和設備內存( GPU )之間的數(shù)據(jù)移動。
在下文中,我們將討論各種框架中關聯(lián)數(shù)據(jù)對象的內存布局、使用零拷貝高效轉換數(shù)據(jù)對象,以及混合框架時使用聯(lián)合內存池。
內存池
內存分配很昂貴。它們通常會設置全球壁壘,在分配完成之前阻礙剩余的業(yè)務。因此,從性能的角度來看,在訓練神經網絡的過程中,重復分配緊循環(huán)的內存是禁止的。現(xiàn)代數(shù)據(jù)科學和深度學習框架通過專用內存池解決了這一問題。它要么在程序開始時預先分配一大塊內存(例如, TensorFlow ),要么使用一些不頻繁的分配(例如, PyTorch )來遞增池。然后,通過異步地將該內存范圍的子集分配給/從任何請求它的人收回,以智能的方式重用預先分配的內存。例如, RAPIDS 內存管理器( RMM ) 是最初為 RAPIDS 數(shù)據(jù)科學框架編寫的內存池。 RMM 促進了極快的主機和設備內存分配。 麥克哈里斯 量化了 本帖 中 RMM 的影響:“我們通過使用 RMM 分配替換對 %s :沒有足夠的空閑空間 和 %s :沒有足夠的空閑空間 的所有調用,在 cuDF 中集中了內存管理。這是一個很大的工作,但它得到了回報。 RMM 調用的速度大約是 馬洛克 和 cudaFree 的 1000 倍。結果是抵押貸款演示的速度提高了 10 倍。”
當組合不同的數(shù)據(jù)科學庫時,幾個特定于庫的內存池 MIG ht 競爭相同的視頻 RAM 。一個簡單的解決方法是將每個內存池的容量限制為可用內存的固定分區(qū)。更好的解決方案是對所有框架使用相同的內存池。請注意,這并不一定意味著所有框架都必須同意其普通版本中提供的相同內存池實現(xiàn)。所有供應商都同意使用外部分配器接口( EAI )來請求和釋放其框架中的內存就足夠了。
void* allocate(std::size_t bytes, cudaStream_t stream) void deallocate(void* p, std::size_t bytes, cudaStream_t stream)
EAI 的進一步優(yōu)勢是直觀的日志記錄功能、內存泄漏檢查以及速率或資源限制功能。例如, RAPIDS 內存管理器利用統(tǒng)一內存透明地超額訂閱 GPU 內存。前者意味著在處理不適合 GPU 內存的大型數(shù)據(jù)集時,顯著降低了內存不足錯誤的幾率。
好消息是,在導入其他所有內容之前,只需導入 RAPIDS cuDF ,就可以將 RMM 與 CuPy 和 Numba 一起使用。
import cudf # <= now RMM is the global memory pool import cupy import numba
或者,您可以在不使用 RAPIDS cuDF 的情況下組合使用 Numba 和 RMM 。
import rmm from numba import cuda cuda.set_memory_manager(rmm.RMMNumbaManager)
結論
在我們的框架互操作性系列的這篇文章中,您了解了不同的內存布局,以及 Apache Arrow 格式如何顯著加快跨不同數(shù)據(jù)科學和機器學習框架(如 TensorFlow 、 PyTorch 、 MXNet 、 cuDF 、 丘比。 、 麻木 和 JAX 的數(shù)據(jù)傳輸。我們還討論了由內存池促進的異步內存分配對于避免高達管道總運行時間 90% 的開銷至關重要。
在本系列的第二部分中,您將了解如何利用遠程直接內存訪問( RDMA )在多 GPU 設置中進一步加速數(shù)據(jù)加載和數(shù)據(jù)傳輸。
關于作者
Christian Hundt 在德國美因茨的 Johannes Gutenberg 大學( JGU )獲得了理論物理的文憑學位。在他的博士論文中,他研究了時間序列數(shù)據(jù)挖掘算法在大規(guī)模并行架構上的并行化。作為并行和分布式體系結構組的博士后研究員,他專注于各種生物醫(yī)學應用的高效并行化,如上下文感知的元基因組分類、基因集富集分析和胸部 mri 的深層語義圖像分割。他目前的職位是深度學習解決方案架構師,負責協(xié)調盧森堡的 NVIDIA 人工智能技術中心( NVAITC )的技術合作。
Miguel Martinez 是 NVIDIA 的高級深度學習數(shù)據(jù)科學家,他專注于 RAPIDS 和 Merlin 。此前,他曾指導過 Udacity 人工智能納米學位的學生。他有很強的金融服務背景,主要專注于支付和渠道。作為一個持續(xù)而堅定的學習者, Miguel 總是在迎接新的挑戰(zhàn)。
審核編輯:郭婷
-
cpu
+關注
關注
68文章
11051瀏覽量
216196 -
gpu
+關注
關注
28文章
4917瀏覽量
130760 -
內存
+關注
關注
8文章
3111瀏覽量
75039
發(fā)布評論請先 登錄
樂鑫 ESP32-C6 通過 Thread 1.4 互操作性認證

智能網聯(lián)汽車云控系統(tǒng)第1部分:系統(tǒng)組成及基礎平臺架構

邏輯內存和物理內存的區(qū)別
互操作性對智能家居的重要性

操作系統(tǒng)的內存布局介紹





 工商網監(jiān)
工商網監(jiān)
評論