") 基于卷積神經(jīng)網(wǎng)絡(luò)的路面識(shí)別系統(tǒng)
基于卷積神經(jīng)網(wǎng)絡(luò)的路面識(shí)別系統(tǒng)
Q1文章提出的工程問題是什么?
有什么實(shí)際工程價(jià)值?
在交通負(fù)荷和氣候的影響下,路面系統(tǒng)會(huì)隨著時(shí)間的推移而惡化,每年需要花費(fèi)大量資金來修復(fù)和保持其性能在預(yù)期水平。可靠和準(zhǔn)確的路面狀況數(shù)據(jù)在路面管理系統(tǒng)(PMS)中發(fā)揮著關(guān)鍵作用,人工調(diào)查可能存在潛在的安全問題,需要交通控制,耗時(shí)且結(jié)果受主觀影響,這可能導(dǎo)致每年的路面狀況數(shù)據(jù)不一致。
因此,基于數(shù)字成像的調(diào)查技術(shù)以高速公路的速度捕獲路面圖像,并將其存儲(chǔ)在電子介質(zhì)上,用于進(jìn)行路面狀況的解釋的方法被大量研究。自動(dòng)化和半自動(dòng)化技術(shù)由于其在安全性和效率、數(shù)據(jù)一致性和可重復(fù)性以及全車道覆蓋的高分辨率路面圖像等方面的優(yōu)勢(shì),在路面條件數(shù)據(jù)收集領(lǐng)域獲得了廣泛的接受。
Q2文章提出的科學(xué)問題是什么?
有什么新的學(xué)術(shù)貢獻(xiàn)?
基于圖像的系統(tǒng)正在成為為路面管理活動(dòng)收集路面狀況數(shù)據(jù)的流行系統(tǒng),路面工程師會(huì)根據(jù)路面類型定義各種遇險(xiǎn)類別。然而,現(xiàn)在的軟件解決方案在自動(dòng)從收集到的圖像中正確識(shí)別路面類型方面存在局限性。
本文提出了一種基于卷積神經(jīng)網(wǎng)絡(luò)(CNN)的路面識(shí)別系統(tǒng)PvmtTPNet,具有可接受的一致性、準(zhǔn)確性并且高效自動(dòng)識(shí)別路面類型。
1. 通過使用統(tǒng)計(jì)學(xué)習(xí)方法分析近場(chǎng)的聲音輪廓和紋理,確定了不同類型的路面。
2. 利用最先進(jìn)的PaveVison3D系統(tǒng)(Wangetal.2015)在俄克拉何馬州不同條件下不同路面類型的路線上以1毫米分辨率的路面圖像。共隨機(jī)選取80%的準(zhǔn)備圖像用于對(duì)所提網(wǎng)絡(luò)的訓(xùn)練,其余20%的圖像用于測(cè)試。
3. 將獲得的網(wǎng)絡(luò)應(yīng)用于確定2019年另外兩個(gè)數(shù)據(jù)收集的圖像的路面類型,以評(píng)估性能。
Q3文章提出的技術(shù)路線是什么?
有什么改進(jìn)創(chuàng)新之處?
①訓(xùn)練數(shù)據(jù)
本研究考慮了PMS中通常評(píng)定和測(cè)量的三種路面類型:瀝青混凝土路面(AC)、接縫素混凝土路面(JPCP)和連續(xù)鋼筋混凝土路面(CRCP)。總共收集了21,000張二維(2D)圖像,覆蓋了84,000米(52.20英里)的長(zhǎng)路面切片。隨機(jī)選取80%的準(zhǔn)備圖像用于對(duì)所提網(wǎng)絡(luò)的訓(xùn)練,其余20%的圖像用于測(cè)試。在訓(xùn)練過程中,將制備的二維圖像縮小到475×512 二維圖像,以提高計(jì)算效率。圖1是預(yù)先準(zhǔn)備的數(shù)據(jù)集的圖像樣例。

圖1 準(zhǔn)備的數(shù)據(jù)集的圖像樣例:(a)新;(b)有裂縫;(c)有密封裂縫;(d)有修補(bǔ);(e)有裂縫;(f)有PCC修補(bǔ);(g)有出口;(h)有交流修補(bǔ);(i)有DBR;(j)有DBR和修補(bǔ);(k)有裂縫;(l)有凹槽。
② 網(wǎng)絡(luò)開發(fā)
圖2顯示了PvmtTPNet的體系結(jié)構(gòu)。PvmtTPNet由六層組成:三個(gè)卷積層、兩個(gè)全連接層和一個(gè)輸出層。PvmtTPNet的輸入端是準(zhǔn)備好的二維路面圖像,輸出層計(jì)算出預(yù)測(cè)的路面類型的概率分布。在每個(gè)卷積層中,使用8個(gè)大小為13×13的核來提取輸入圖像的特征,如邊緣和形狀。對(duì)于這兩個(gè)完全連接的圖層,我們分別實(shí)現(xiàn)了32個(gè)節(jié)點(diǎn)和16個(gè)節(jié)點(diǎn),以保存最重要的路面圖像的特征。
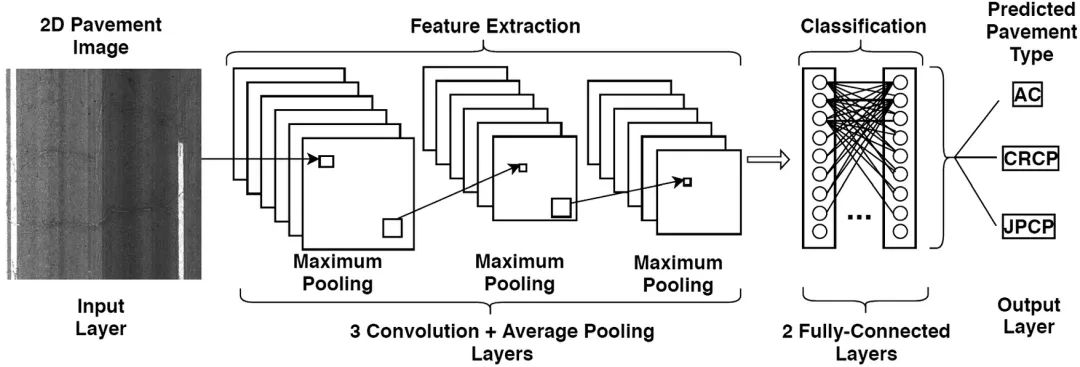
圖2 利用GA對(duì)HNN進(jìn)行優(yōu)化的流程圖
③訓(xùn)練技巧
在網(wǎng)絡(luò)訓(xùn)練過程中,采用了不同技術(shù)的組合,根據(jù)準(zhǔn)備好的二維圖像來調(diào)整PvmtTPNet內(nèi)的超參數(shù)。對(duì)網(wǎng)絡(luò)的參數(shù)進(jìn)行逐步調(diào)整,以減少輸出分?jǐn)?shù)與期望分?jǐn)?shù)模式之間的誤差,以減少訓(xùn)練損失,提高訓(xùn)練精度(LeCunetal.2015)。經(jīng)過廣泛的訓(xùn)練,PvmtTPNet能夠根據(jù)一個(gè)得分向量來預(yù)測(cè)給定的二維圖像的路面類型,其中所有類別的最高得分將對(duì)應(yīng)于路面類型。表1總結(jié)了PvmtTPNet的調(diào)優(yōu)超參數(shù),總數(shù)為992,979個(gè)。表1是訓(xùn)練參數(shù)的總結(jié)。
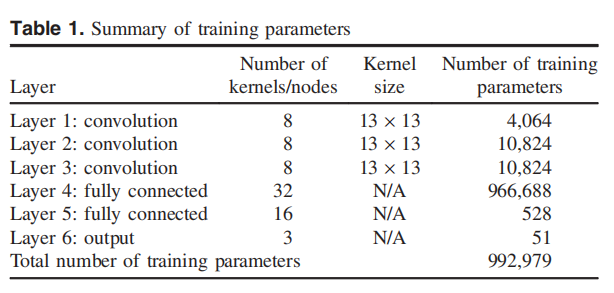
表1 訓(xùn)練參數(shù)總結(jié)
④ 訓(xùn)練結(jié)果
網(wǎng)絡(luò)訓(xùn)練和測(cè)試的分類精度和交叉熵?fù)p失如圖3所示。隨著訓(xùn)練周期數(shù)的增加,分類精度增加,交叉熵?fù)p失減小。PvmtTPNet在100個(gè)時(shí)代的準(zhǔn)備數(shù)據(jù)集上的訓(xùn)練需要28小時(shí)才能在NVIDIAtitanVGPU卡上完成。通過對(duì)訓(xùn)練技術(shù)的選擇組合,測(cè)試數(shù)據(jù)的分類精度仍然接近于訓(xùn)練數(shù)據(jù)的分類精度,這表明該網(wǎng)絡(luò)中很少存在過擬合問題。特別是,PvmtTPNet的最高測(cè)試精度為98.48%,這是在第96時(shí)代觀察到的。同時(shí),訓(xùn)練數(shù)據(jù)和測(cè)試數(shù)據(jù)的交叉熵?fù)p失分別為0.0067和0.054。因此,在第96階段導(dǎo)出的參數(shù)被認(rèn)為是PvmtTPNet的最優(yōu)參數(shù)。訓(xùn)練數(shù)據(jù)在最優(yōu)時(shí)期的分類精度達(dá)到99.83%。
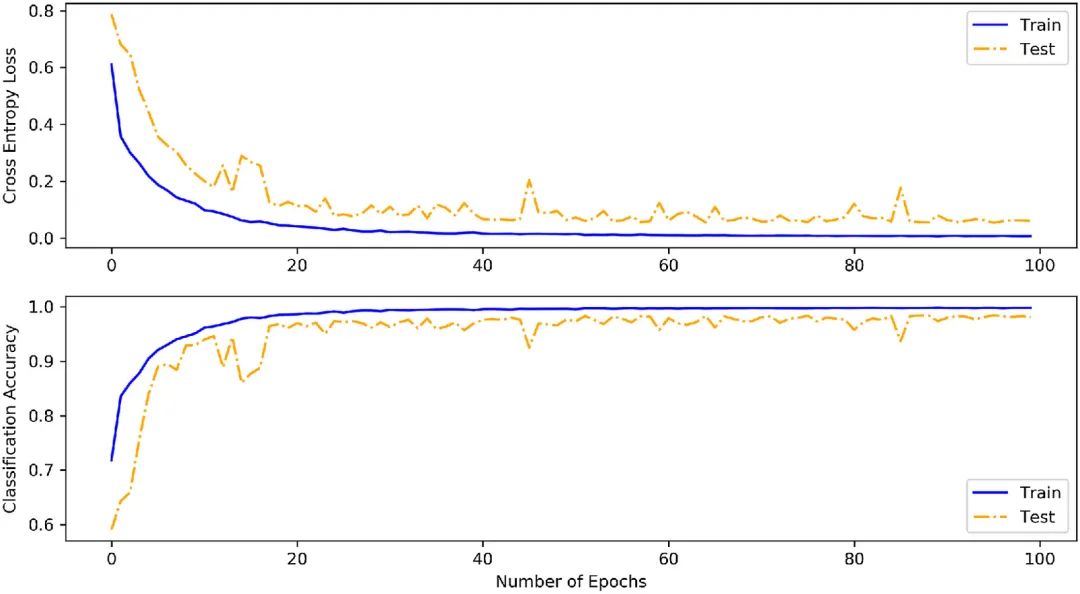
圖3 分類精度和交叉熵?fù)p失的總結(jié)
基于上述內(nèi)容,本文有以下創(chuàng)新點(diǎn):
1.本研究開發(fā)了一種基于深度學(xué)習(xí)(DL)的網(wǎng)絡(luò),稱為PvmtTPNet,可以從圖像中自動(dòng)識(shí)別路面類型,以促進(jìn)全自動(dòng)的路面狀況調(diào)查。PvmtTPNet實(shí)現(xiàn)了一個(gè)基于卷積神經(jīng)網(wǎng)絡(luò)的體系結(jié)構(gòu)來學(xué)習(xí)來自路面類別的圖像的特征。
2.采用校流線性單元(ReLUs)作為卷積層和全連通層的激活函數(shù),可以進(jìn)行快速有效的訓(xùn)練,已成為現(xiàn)代深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)的默認(rèn)激活函數(shù)。
Q4
文章是如何驗(yàn)證和解決問題的?
為了評(píng)估獲得的PvmtTPNet在路面類型識(shí)別最佳時(shí)期的性能,2019年通過PaveVision3D系統(tǒng)對(duì)1號(hào)站點(diǎn)(靠近俄克拉荷馬城)和2號(hào)站點(diǎn)(靠近阿肯色州史密斯堡的I-540)進(jìn)行了另外兩次現(xiàn)場(chǎng)數(shù)據(jù)收集。兩種數(shù)據(jù)采集的路徑如圖4所示。
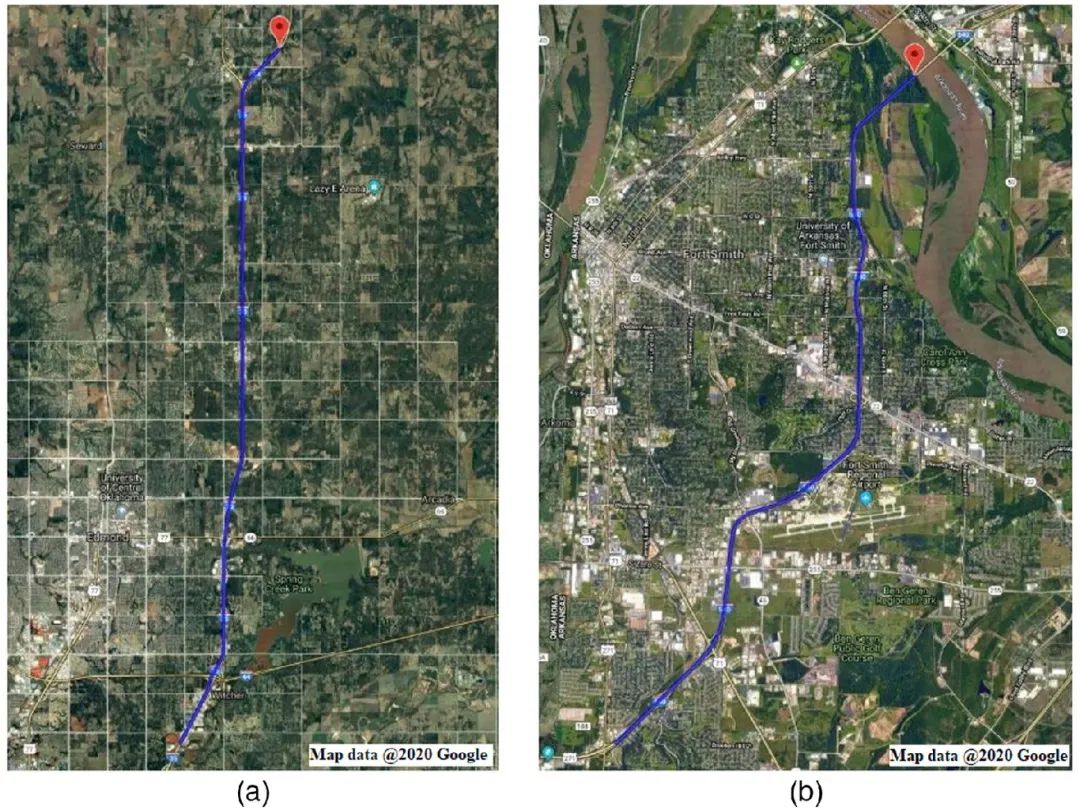
圖4 模型評(píng)估的數(shù)據(jù)收集:
(a)Site1-I-35;(b)Site2-I-540
表2總結(jié)了PvmtTPNet對(duì)這兩個(gè)數(shù)據(jù)收集的實(shí)際和預(yù)測(cè)路面類型的詳細(xì)數(shù)量,并提供了每個(gè)站點(diǎn)的混淆矩陣。
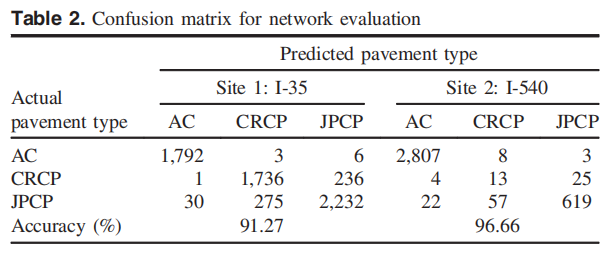
表2 網(wǎng)絡(luò)評(píng)價(jià)中的混淆矩陣
在每個(gè)混淆矩陣中,沿對(duì)角線上的數(shù)字代表正確的預(yù)測(cè),而其他數(shù)字表示對(duì)每個(gè)路面類別的準(zhǔn)確預(yù)測(cè)。如表2所示,PvmtTPNet從準(zhǔn)備的Site1的6311張圖像中獲得了5760個(gè)正確的預(yù)測(cè),準(zhǔn)確率為91.27%。對(duì)于Site2,PvmtTPNet做出了3,439個(gè)正確的預(yù)測(cè),并達(dá)到了96.66%的準(zhǔn)確率。此外,PvmtTPNet使用一個(gè)NVIDIAtitanVGPU卡對(duì)站點(diǎn)1和站點(diǎn)2的圖像進(jìn)行預(yù)測(cè)需要16.33min和4.59min。因此,每幅圖像的平均處理時(shí)間為站點(diǎn)1的平均處理時(shí)間為155,212μs,站點(diǎn)2為77,452μs。如果野外數(shù)據(jù)采集速度為96.56km/h(60mi/h),則需要18.55min和10.46min才能完成對(duì)這兩個(gè)地點(diǎn)的調(diào)查。因此,處理時(shí)間小于數(shù)據(jù)采集時(shí)間(站點(diǎn)1為16.33<18.55,站點(diǎn)2為4.59<10.46)。PvmtTPNet顯然有潛力使用最新的GPU從實(shí)時(shí)收集的2D圖像中預(yù)測(cè)路面類型,這將比研究中使用的GPU快幾倍。
Q5文章有什么可取和不足之處?
邏輯結(jié)構(gòu):本文的outline呈現(xiàn)在下文:
1. Introduction
說明了通過人工獲得路面狀況數(shù)據(jù)存在缺陷,因此,基于卷積神經(jīng)網(wǎng)絡(luò)的圖像路面類型自動(dòng)識(shí)別研究具有必要性。
2. Data preparation
介紹了本研究中使用的所有路面圖像來源,以及本文對(duì)PvmtTPNet進(jìn)行訓(xùn)練的對(duì)象。
3. Network Development
本研究開發(fā)了一種基于深度學(xué)習(xí)(DL)的網(wǎng)絡(luò),稱為PvmtTPNet,可以從圖像中自動(dòng)識(shí)別路面類型,以促進(jìn)全自動(dòng)的路面狀況調(diào)查。PvmtTPNet實(shí)現(xiàn)了一個(gè)基于卷積神經(jīng)網(wǎng)絡(luò)的體系結(jié)構(gòu)來學(xué)習(xí)來自路面類別的圖像的特征。
3.1 Methodology
介紹本研究采用CNN體系結(jié)構(gòu)訓(xùn)練所提出的PvmtTPNet的方法論。
3.2 Network Architecture
介紹PvmtTPNet的網(wǎng)絡(luò)體系結(jié)構(gòu)。
3.3 Training Techniques
介紹PvmtTPNet網(wǎng)絡(luò)訓(xùn)練的數(shù)據(jù)來源及訓(xùn)練方法。
3.4 Training Results
展示網(wǎng)絡(luò)訓(xùn)練和測(cè)試的分類精度和交叉熵?fù)p失。通過對(duì)訓(xùn)練技術(shù)的選擇組合,測(cè)試數(shù)據(jù)的分類精度仍然接近于訓(xùn)練數(shù)據(jù)的分類精度,表明該網(wǎng)絡(luò)中很少存在過擬合問題。
4. Network Evaluation
通過PaveVision3D系統(tǒng)對(duì)俄克拉荷馬城及靠近阿肯色州史密斯堡的I-540兩地進(jìn)行數(shù)據(jù)采集,并且通過PvmtTPNet在路面類型識(shí)別的結(jié)果評(píng)估其在路面類型識(shí)別最佳時(shí)期的性能。
5. Discussion
目前,在數(shù)據(jù)收集過程中在橋上添加事件標(biāo)記是從收集的圖像數(shù)據(jù)中排除橋段的常用方法。然而,這是對(duì)現(xiàn)場(chǎng)工作人員的估計(jì),考慮到數(shù)據(jù)收集的高速速度,這可能會(huì)產(chǎn)生不準(zhǔn)確的記錄。因此,在下一階段的工作中根據(jù)獲得的圖像判斷PvmtTPTet在橋面圖像的訓(xùn)練效果。但是存在以下幾個(gè)方面的局限性:首先,從橋面上收集到的圖像還不夠多。眾所周知,DL訓(xùn)練需要大量的訓(xùn)練數(shù)據(jù)來達(dá)到所需的性能。其次,橋面的二維圖像并不總是包含該網(wǎng)絡(luò)學(xué)習(xí)的區(qū)別特征。
6. Conclusions
在這項(xiàng)研究中,一個(gè)基于卷積神經(jīng)網(wǎng)絡(luò)的DL網(wǎng)絡(luò),名為PvmtTPNet,通過訓(xùn)練來識(shí)別人類的路面類型。2018年,利用PaveVision3D系統(tǒng)對(duì)俄克拉何馬州三種路面類型的瀝青混凝土路面、連接普通混凝土路面和不同條件和壓力的連續(xù)鋼筋混凝土路面進(jìn)行了調(diào)查,編制了培訓(xùn)數(shù)據(jù)庫。最后,總共制作了21000張2D路面圖像,而三種路面類型都有大約7000張圖像。每個(gè)2D圖像覆蓋了一個(gè)約4米寬和4米長(zhǎng)的路面部分。通過所選擇的訓(xùn)練技術(shù),成功地訓(xùn)練了網(wǎng)絡(luò),沒有過擬合問題。在最優(yōu)時(shí)期,網(wǎng)絡(luò)對(duì)路面類型識(shí)別的訓(xùn)練和測(cè)試圖像的預(yù)測(cè)精度分別達(dá)到99.85%和98.37%。
應(yīng)該注意的是,橋面的圖像沒有包括作為PvmtTPNet的一種路面類型。因此,未來的研究希望使用更多的數(shù)據(jù)集和可能更新的DL方法來識(shí)別橋梁。最后,還需要改進(jìn)PvmtTPNet,以對(duì)剛性路面上的圖像產(chǎn)生更準(zhǔn)確的預(yù)測(cè)。最終目標(biāo)是達(dá)到接近100%的精度,以自動(dòng)和高速識(shí)別瀝青和混凝土路面類型,以及其他表面類型,如橋面和復(fù)合材料。
從上述內(nèi)容可以看出,本文主要采用縱式結(jié)構(gòu),以研究展開的順序先后介紹了數(shù)據(jù)處理,神經(jīng)網(wǎng)絡(luò)開發(fā),網(wǎng)絡(luò)訓(xùn)練結(jié)果評(píng)估以及關(guān)于卷積神經(jīng)網(wǎng)絡(luò)圖像路面類型自動(dòng)識(shí)別的進(jìn)一步發(fā)展。
研究方法:本文在研究的過程中,評(píng)估卷積神經(jīng)網(wǎng)絡(luò)PvmtTPNet在收集的路面類型時(shí)的性能的方法非常詳細(xì),并從多個(gè)角度驗(yàn)證PvmtTPNet在預(yù)測(cè)這兩種數(shù)據(jù)時(shí)的收集效果。

圖5 PvmtTPNet在預(yù)測(cè)數(shù)據(jù)準(zhǔn)確性評(píng)估公式
圖表形式:本文的圖表形式簡(jiǎn)潔明了,沒有使用復(fù)雜的圖形表格,但是卻直觀展現(xiàn)了實(shí)驗(yàn)結(jié)果。
分類精度和交叉熵?fù)p失的總結(jié)
網(wǎng)絡(luò)評(píng)估的混淆矩陣
文字表達(dá):
表2總結(jié)了PvmtTPNet對(duì)這兩個(gè)數(shù)據(jù)收集的實(shí)際和預(yù)測(cè)路面類型的詳細(xì)數(shù)量,并為每個(gè)站點(diǎn)提供了混淆矩陣。
在圖像精度評(píng)價(jià)中,混淆矩陣主要用于比較分類結(jié)果和實(shí)際測(cè)得值,可以把分類結(jié)果的精度顯示在一個(gè)混淆矩陣?yán)锩妗;煜仃囀峭ㄟ^將每個(gè)實(shí)測(cè)像元的位置和分類與分類圖像中的相應(yīng)位置和分類像比較計(jì)算的。混淆矩陣的每一列代表了實(shí)際測(cè)得信息,每一列中的數(shù)值等于實(shí)際測(cè)得像元在分類圖象中對(duì)應(yīng)于相應(yīng)類別的數(shù)量;混淆矩陣的每一行代表了遙感數(shù)據(jù)的分類信息,每一行中的數(shù)值等于遙感分類像元在實(shí)測(cè)像元相應(yīng)類別中的數(shù)量。

圖6 作者在文中使用混淆矩陣的前后文
Q6文章對(duì)自身的研究有什么啟發(fā)?
本文主要研究通過卷積神經(jīng)網(wǎng)絡(luò)對(duì)路面圖像類型自動(dòng)識(shí)別。在使用充分的樣本驗(yàn)證PvmtTPNet后,延伸探討了橋面的圖像沒有包括作為PvmtTPNet的一種路面類型,希望使用更多的數(shù)據(jù)集和可能更新的DL方法來識(shí)別橋梁。并且對(duì)PvmtTPNet進(jìn)行改進(jìn),以對(duì)剛性路面上的圖像產(chǎn)生更準(zhǔn)確的預(yù)測(cè)。延伸出在自動(dòng)和高速識(shí)別瀝青和混凝土路面類型及復(fù)合材料方面的應(yīng)用。
我們做科研也應(yīng)該舉一反三,將自己的研究結(jié)果進(jìn)行延伸,不要僅僅局限在當(dāng)下的專業(yè)框架下,而是要去積極探索更多的可能性。
原文標(biāo)題:基于卷積神經(jīng)網(wǎng)絡(luò)的圖像路面類型自動(dòng)識(shí)別
文章出處:【微信公眾號(hào):機(jī)器視覺智能檢測(cè)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
審核編輯:湯梓紅
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4806瀏覽量
102688 -
識(shí)別系統(tǒng)
+關(guān)注
關(guān)注
1文章
147瀏覽量
19034
原文標(biāo)題:基于卷積神經(jīng)網(wǎng)絡(luò)的圖像路面類型自動(dòng)識(shí)別
文章出處:【微信號(hào):vision263com,微信公眾號(hào):新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論